
- 1ubuntu22.04安装Ros2(每步都有图)(20221124)
- 2用kithara驱动控制IS620N伺服电机简单实例_kithara不支持千兆网卡
- 3机器学习各大模型原理的深度剖析!进来学习!!_机器学习模型
- 4ESLint 的一些理解_eslint explicit
- 5ThreadPoolExecutor和ThreadPoolTaskExecutor区别_executorthreadpool 和 executorthreadtaskpool
- 6腾讯云函数 python_腾讯云函数SCF使用心得
- 7linux mysql8离线升级_mysql 8.0升级8.4
- 8人工智能 | 通俗讲解AI基础概念_人工智能 通俗讲义
- 9计算机常用英语词汇_s expected. if you encounter any issues, please re
- 10Django | 从中间件的角度来认识Django发送邮件功能
更多嵌入模型和向量存储选择,来 Amazon Bedrock 知识库体验!
赞
踩

本文作者 Antje Barth
亚马逊云科技首席开发者布道师
在 2023 年的亚马逊云科技 re:Invent 期间,亚马逊云科技宣布 Amazon Bedrock 知识库正式上线。借助知识库,您可以将 Amazon Bedrock 中的基础模型(FM)安全连接到贵公司的数据,以实现检索式增强生成(RAG)。
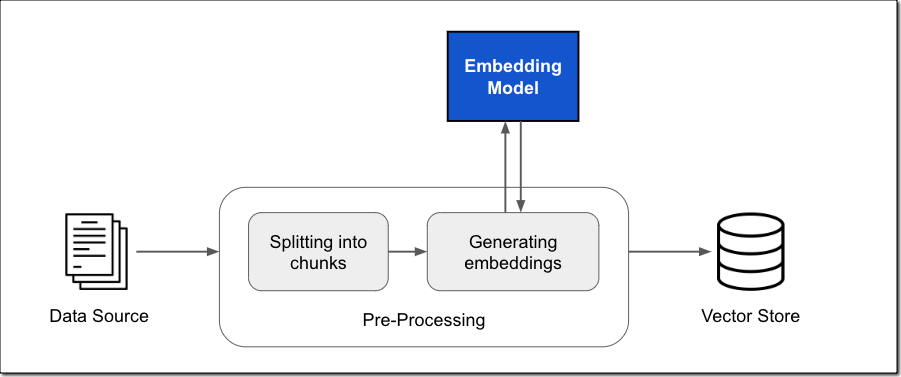
在过去,我介绍了 Amazon Bedrock 知识库如何为您管理端到端的 RAG 工作流。您只需指定数据位置,选择嵌入模型以将数据转换为向量嵌入,然后让 Amazon Bedrock 在您的亚马逊云科技账户中创建一个向量存储,来存储向量数据,如下图所示。您还可以自定义 RAG 工作流,例如指定自己的自定义向量存储库。

Amazon re:Invent
扫码了解更多

Amazon Bedrock 知识库
扫码了解更多

Amazon Bedrock
扫码了解更多
左右滑动查看更多
从过去到现在,知识库已经进行了多次更新,包括可将 Amazon Aurora PostgreSQL - 兼容版作为除 Amazon OpenSearch 无服务器的向量引擎、Pinecone 和 Redis Enterprise Cloud 之外的又一个自定义向量存储选项。但不止如此,下面我将简单介绍新增的功能。

Amazon Aurora PostgreSQL
兼容版
扫码了解更多

Amazon OpenSearch
无服务器的向量引擎
扫码了解更多

Pinecone
扫码了解更多

Redis Enterprise Cloud
扫码了解更多
左右滑动查看更多
更多嵌入模型选择
嵌入模型可将数据(例如文档)转换为向量嵌入。向量嵌入包括将文档中的文本数据表现为数字形式。每个嵌入都旨在捕获数据的语义或上下文含义。
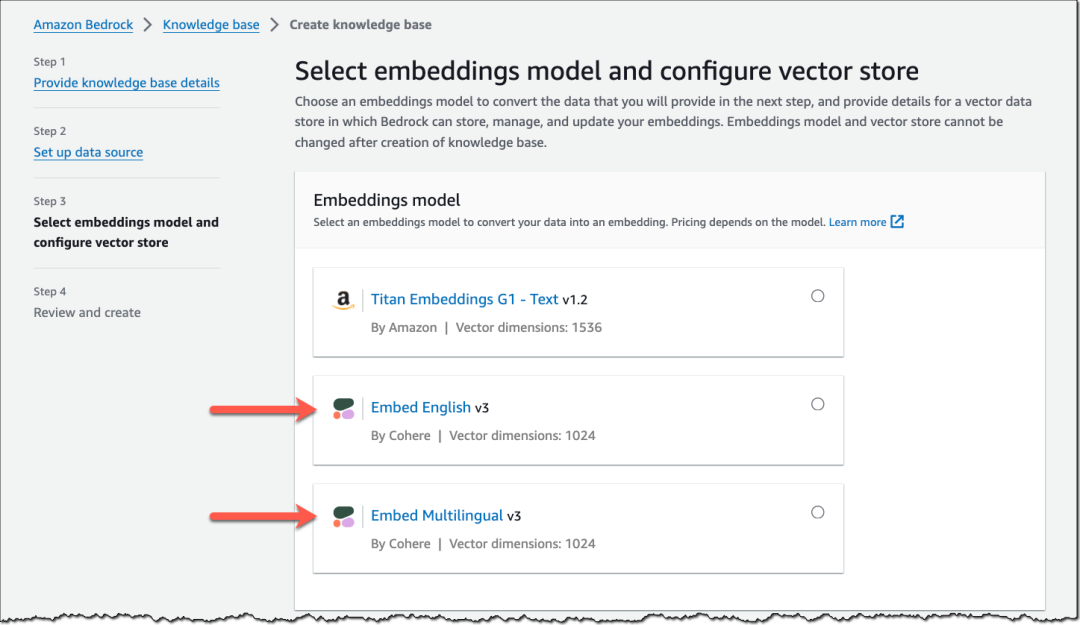
Cohere Embed v3 – 除 Amazon Titan 文本嵌入之外,您现在还有另外两种嵌入模型可以选择,即 Cohere Embed 英语 和 Cohere Embed 多语言,每种模型都支持 1,024 个维度。

Amazon Titan 文本嵌入
扫码了解更多

Cohere Embed 英语
扫码了解更多
左右滑动查看更多
您可扫码查看 Cohere 博客,了解有关 Cohere Embed v3 模型的更多信息。

Cohere Embed v3 模型
扫码了解更多
更多向量存储选择
每个向量嵌入都放入向量存储中,通常还带有其他元数据,例如对从中创建嵌入的原始内容的引用。向量存储为存储的向量嵌入建立索引,从而可以快速检索相关数据。
知识库可为您提供完全托管式的 RAG 体验,包括在您的账户中创建向量存储来存储向量数据。您还可以从支持的选项列表中创建自定义向量存储,并且提供向量数据库索引名称以及索引字段和元数据字段映射。
对于向量存储的更新,我想重点介绍一下这三次更新:在支持的自定义向量存储列表中增加了 Amazon Aurora PostgreSQL 兼容版和 Pinecone 无服务器,以及对现有 Amazon OpenSearch 无服务器集成的更新,有着有助于降低开发和测试工作负载的成本。
Amazon Aurora PostgreSQL – 除 Amazon OpenSearch 无服务器的向量引擎、Pinecone 和 Redis Enterprise Cloud 外,您现在还可以选择将 Amazon Aurora PostgreSQL 作为知识库的向量数据库。
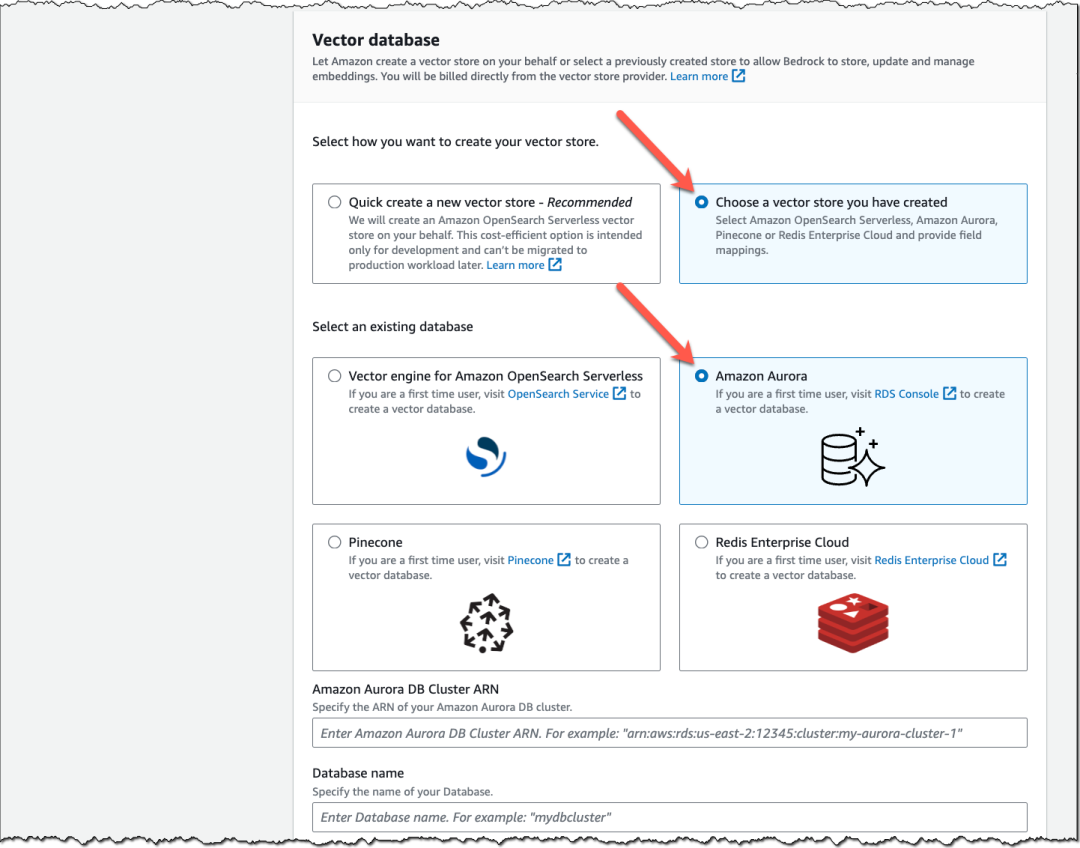
Amazon Aurora 是一种关系数据库服务,与 MySQL 和 PostgreSQL 完全兼容。因此现有的应用程序和工具无需修改即可运行。Amazon Aurora PostgreSQL 支持开源 pgvector 扩展,从而可以存储、索引和查询向量嵌入。
针对常规数据库工作负载的许多 Amazon Aurora 功能也同样适用于向量嵌入工作负载:
与开源 PostgreSQL 相比,Amazon Aurora 提供的数据库吞吐量高达前者的 3 倍,并且支持 Amazon Bedrock 中的向量操作。
Amazon Aurora Serverless v2 可根据来自 Amazon Bedrock 的实时查询负载弹性扩缩存储和计算容量,从而确保最优预置。
Amazon Aurora 全球数据库提供跨多个亚马逊云科技区域的全球低延迟读取和灾难恢复能力。
蓝绿部署在同步的暂存环境中复制生产数据库,从而可在不影响生产环境的情况下进行修改。
Amazon EC2 R6gd 和 R6id 实例上的 Amazon Aurora 优化读取功能使用本地存储,来增强复杂查询和索引重新生成操作的读取性能和吞吐量。对于不适合放入内存的向量工作负载,与相同大小的 Amazon Aurora 实例相比,Amazon Aurora 优化读取功能可将查询性能提升高达 9 倍。
Amazon Aurora 与 Secrets Manager、IAM 和 Amazon RDS 数据 API 等亚马逊云科技服务无缝集成,确保能够安全地从 Amazon Bedrock 连接到数据库,并支持使用 SQL 进行向量操作。
要详细了解如何为知识库配置 Amazon Aurora,请扫码参阅相关亚马逊云科技数据库博客文章和 Amazon Aurora 用户指南。
Pinecone 无服务器 – Pinecone 最近推出了 Pinecone 无服务器。如果您在知识库中选择将 Pinecone 作为自定义向量存储,则提供 Pinecone 或 Pinecone 无服务器配置的详细信息均可。这两个选项都受支持。

pgvector
扫码了解更多

Aurora Serverless v2
扫码了解更多

Aurora 全球数据库
扫码了解更多

蓝绿部署
扫码了解更多

Amazon EC2 R6gd
扫码了解更多

Amazon EC2 R6id
扫码了解更多

亚马逊云科技数据库博客文章
扫码了解更多

Aurora 优化读取
扫码了解更多

Aurora 用户指南
扫码了解更多
左右滑动查看更多
降低 Amazon OpenSearch 无服务器
中的开发和测试工作负载成本
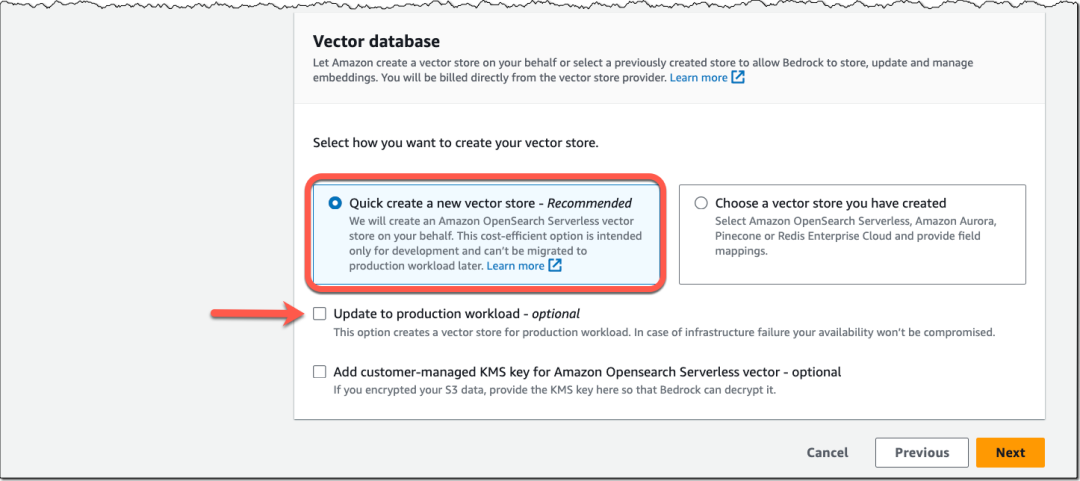
当您选择此选项来快速创建新的向量存储时,Amazon Bedrock 会在您账户的 Amazon OpenSearch 无服务器中创建一个向量索引,因此无需自行管理任何内容。
自 11 月上线以来,Amazon OpenSearch 无服务器的向量引擎让您可以选择为开发和测试工作负载禁用冗余副本,从而降低成本。您最初可以使用两个 OpenSearch 计算单元 (OCU),一个用于索引,另一个用于搜索,与使用冗余副本相比,这样操作的成本可减少一半。此外,OCU 支持小数计费,可首先使用 0.5 个 OCU,然后根据需要扩展,从而可以进一步降低成本。对于开发和测试工作负载,最低 1 个 OCU(在索引和搜索负载之间拆分)现在就足够了,与生产工作负载需要的 4 个 OCU 相比,成本可降低高达 75%。
易用性改进 – 现在,当您在 Amazon Bedrock 知识库中选择快速创建工作流时,系统会默认禁用冗余副本。您也可以通过选择更新到生产工作负载来创建具有冗余副本的集合。
有关 Amazon OpenSearch 无服务器的向量引擎的更多详情,请扫码参阅相关文章。

相关文章
扫码了解更多
更多 FM 选择
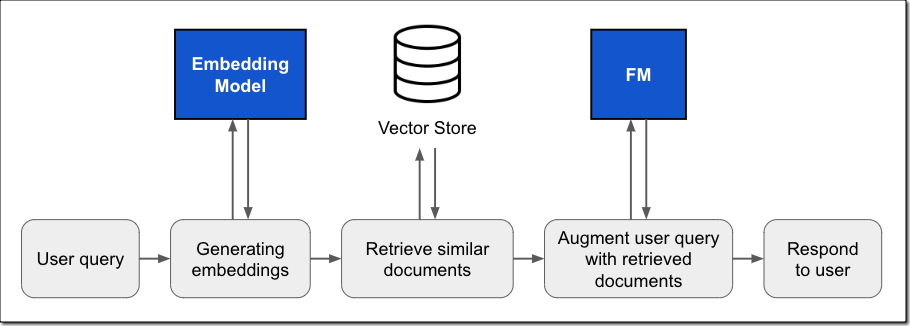
在运行时,RAG 工作流会从用户查询开始。使用嵌入模型,可以创建输入提示的向量嵌入表示。然后使用此嵌入在数据库中查询相似的向量嵌入,以检索最相关的文本作为查询结果。接下来,将查询结果添加到原始提示中,并将增强的提示传递给 FM。模型使用提示中的附加上下文来生成完成内容,如下图所示:

了解详情

Amazon Bedrock
知识库产品页面
扫码了解更多

社区上的
Amazon Bedrock 知识库
扫码了解更多
左右滑动查看更多
阅读有关 Amazon Bedrock 知识库的更多信息

博客文章 1
扫码了解更多

博客文章 2
扫码了解更多
左右滑动查看更多


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容

