
- 1KNeighborsClassifier与KNeighborsRegressor的实现_kneighborsregressor predict()
- 2Spark大数据分析与实战笔记(第二章 Spark基础-06)_spark实战项目
- 3php上传文件的目录,上传文件先创建目录 再上传到目录里面去
- 4文本聚类算法介绍
- 5JavaSE基础笔记(全)_java se学习笔记
- 6ubuntu 20.04 使用 webrtc-streamer自动退出,报错GLIBC 问题解决方法_ubuntu webrtcstreamer
- 7Qt/C++编写全能播放组件(支持ffmpeg2/3/4/5/6/Qt4/5/6)_qt ffmpeg 播放器
- 8Flink stream load 方式写入doris_在 flink 中写入数据到 doris 后,数据怎么提交
- 9Java程序设计入门教程--学习目录(带链接跳转)_java教程目录
- 10【TensorFlow基础】TensorFlow中函数conv2d参数stride,padding的理解以及padding模式SAME,VALID的详细说明_tensorflow中conv2d可以使用stride=2和padding='same
大模型助力国际术语专业化,前后联动实现所见即所得
赞
踩
一、现状问题
国际系统当前的多语言是国际业务的普遍特点,仅仅仓储管理系统,当前系统语言种类已经达到了九种,并且随着业务的开展还在不断的扩展,现有的国际系统支持的语言有中文、英语、日语、韩语、葡萄牙语、西班牙语、法语、德语、越南语。其中每个语言包的词条都有上万条,且随着新需求的开发迭代也在不断的新增,语言包的不断扩展和词条的不断增加,词条翻译的简洁性、专业性和时效性就直接影响了业务的开展和需求的交付速度,迭代的完成效率。更多完整的系统多语言解决方案参见: 系统国际化之多语言解决方案
国际的系统不仅仅是语言多、词条多,而且基本涵盖了供应链体系的所有核心系统,在这些系统的词条翻译也缺少统一的国际专业术语,相同的业务释义在不同的业务条线就存在各种名字,内部沟通不仅费时费力,在客户使用京东系统时也会造成一些困惑。
二、分析原因
在新语言的不断新增过程中,每次新增一种语言,一般的流程是研发提供全套的待翻译词条,业务找到对口的翻译公司按照词条和我们提供的语境、场景翻译成对应的语言,研发根据翻译公司提供的词条生成新的语言包添加到系统中。但是标准和专业的工作流程往往实现起来存在困难,从“成本、效率、体验”的角度出发,总不能研发每次做一个需求都要找一遍翻译公司吧?随着语言包的不断新增和各种需求的不断迭代,所有的翻译都需要专业翻译公司介入基本是不太现实的,这种工作流程方式既增加了成本,又影响了交付效率。在以前没有大模型的时候,一些简单的翻译基本都是借助各类翻译平台实现词语的直译。随着GPT的出现,我们开始使用GPT替换了人工翻译和翻译平台的直译,翻译的准确性对比其他翻译工具更加准确,对比人工翻译成本降低了,效率提高了,且准确性也能得到一定的保障。
不论是人工翻译还是GPT的AI智能翻译,都不能达到国外专业业务系统的简洁和准确,但是想要做的特别专业就需要请专业的外部翻译公司,无疑又增加了成本的支出,有没有一种既能让系统逐步迭代的越来越完美又能降低成本的办法呢?
其实,在多语言方面,“用户”就是最专业的专家。他们对系统熟悉以后,在特定的场景和语境下,是最专业的人。如果他们能够在线修订系统中的各种词汇,是不是就可以解决这个问题?
三、计划目标
1.实时多语言支持:
◦利用大模型的翻译能力,实现对新增语言的快速响应和实时翻译,从而加速国际系统对新语言的支持。
2.提升翻译质量:
◦通过大模型对历史翻译数据的学习,提高翻译的专业性和准确性,减少人工干预,提升整体翻译质量。
3.提高词条更新效率:
◦通过“词条管家”功能,允许用户在线即时修改词条,利用大模型提供智能建议和自动更正,大幅提升词条更新的速度。
4.优化用户参与流程:
◦鼓励用户参与词条的修订,利用大模型分析用户反馈,快速响应用户需求,提升用户参与度和满意度。
5.降低成本:
◦减少对专业翻译公司的依赖,通过大模型辅助的自动化翻译和用户社区的参与,有效降低翻译和更新的成本。
6.增强系统的智能化:
◦利用大模型对用户行为和词条使用模式的分析,实现智能化的词条推荐和预测性更新,进一步提升系统的智能化水平。
7.持续学习和优化:
◦大模型将持续从用户修订、审批流程和系统反馈中学习,不断优化翻译和更新流程,实现持续的性能提升
充分利用大模型的强大计算和学习能力,实现多语言支持的自动化、智能化,从而显著提升整个系统的效率和性能。
四、实现步骤
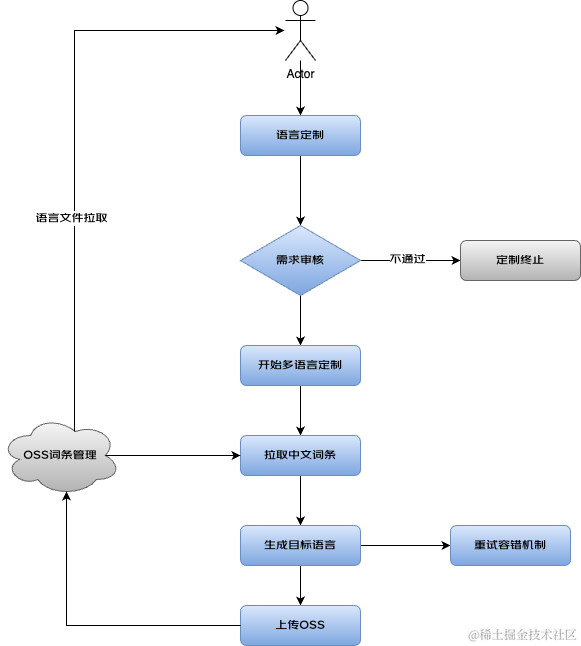
4.1 建设国际物流术语词条库
建设国际系统统一使用的国际专业术语词条库,这个词条库将现有各个系统已有词汇汇集整理以后形成一套大家都在使用的标准国际专业术语词条,后续新增的需求将优先从词条库中选择现有词条,没有的词条需要产品新增,产品新增完成以后前端研发就会引用该词条到各自的系统中。
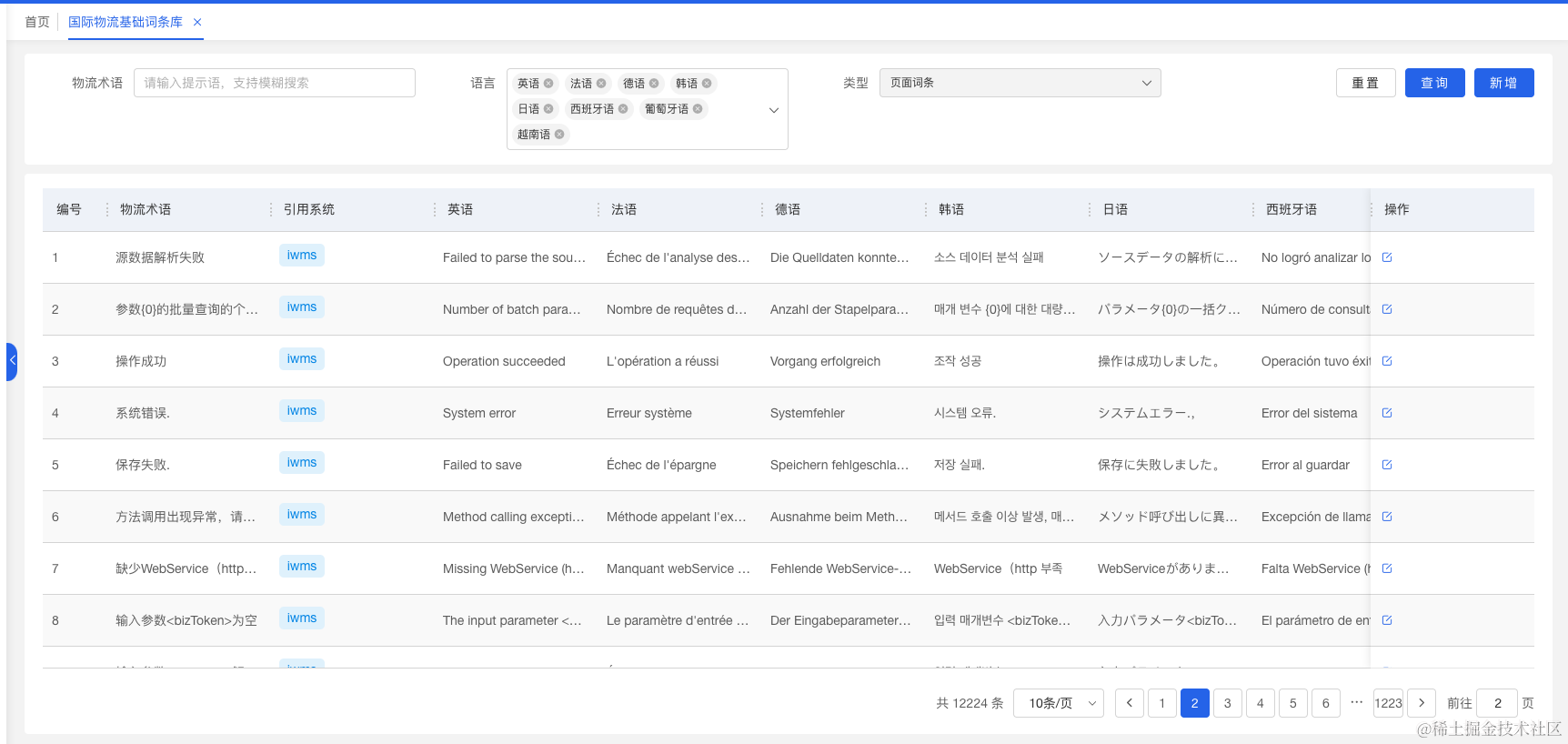
使用技术手段,让用户能够在线修订系统中的各种词条和提示语,经过审批流程以后,词条、提示语就能够生效并最终应用于系统中。
4.2 哪里不对改哪里,词条管家秒更新
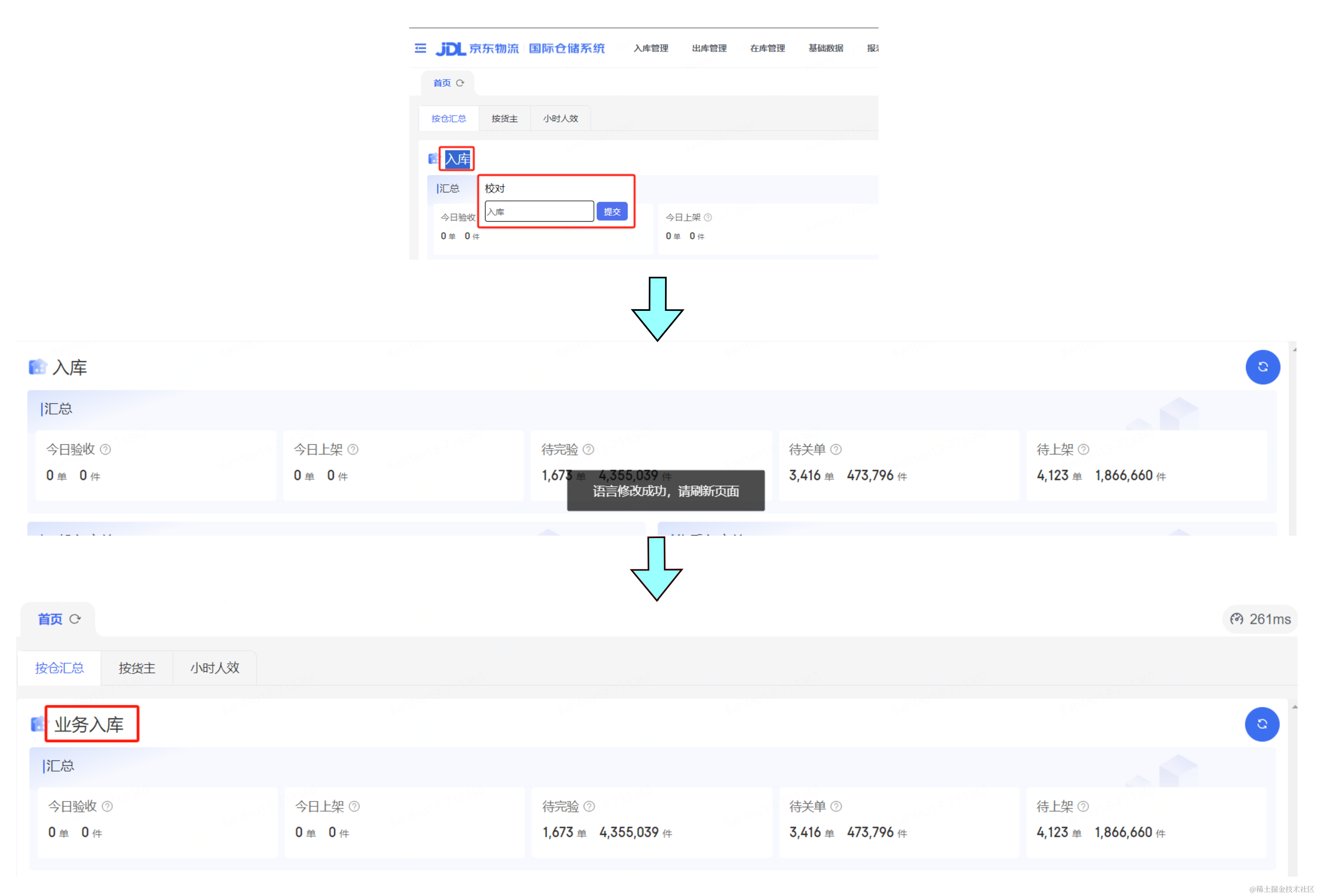
在系统中集成了自动划词修改功能,该功能允许用户在浏览前端页面时,对识别出的不恰当或过时的词条进行即时修改。
1.划词选中:用户在前端页面中发现需要修订的词条后,可以通过划词操作快速选中该词条。
2.弹出更正窗口:选中词条后,系统会自动弹出一个更正窗口,引导用户输入修订后的词条内容。
3.审批流程:用户输入新词条并提交后,系统将启动审批流程。这一流程确保了词条修改的专业性和准确性。
4.自动生效:一旦新词条通过审批,修改将被自动应用并即时生效,从而保证了词条库的时效性和可靠性。
通过这一流程,我们不仅提高了词条更新的效率,还通过审批机制确保了词条内容的质量和权威性。
4.3 架构实现
整体架构设计
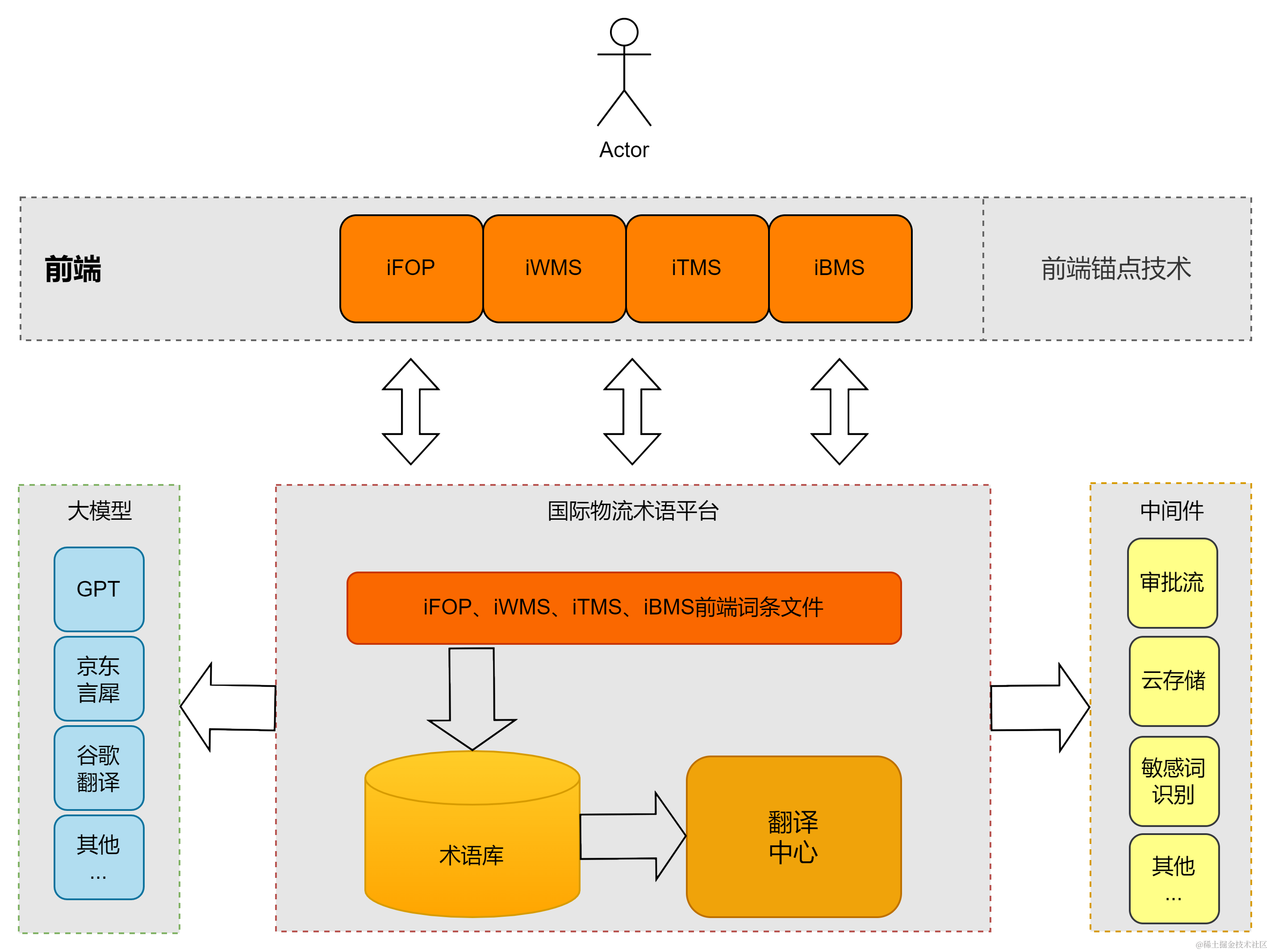
4.3.1 大模型翻译
使用集团提供的大模型平台GPT、言犀等,对需要翻译的语言包或者新增词条部分进行定制化翻译,方便系统很快速的扩展新的语言包。对国际术语词条库的内容进行实时在线翻译,新增词条时自动根据母语(中文)翻译出其他语言的结果供产品参考。
内容沉淀:在翻译过程中内置了多种专业词条库,包括敏感词、商品名称、报关地址、各个国家的地址信息等,在翻译的同时还会沉淀下来,形成专业的术语库,为后续其他业务提供模块化的支撑。
规则约束:在翻译时,会在系统中内置一系列的逻辑,确保翻译出来的结果符合各个语境下的习惯,例如英语的词汇翻译结果一般都是首字母大写,在进行英语简拼时,一般后面都会带个英文的“.”来标识。日本的地址信息一般是按照都道府县、市、区一级级,类似于中国的省市县,在翻译日本地址信息也会严格遵照日本的地址规范,这些都是系统内置的能力。
话术集成:对不同的翻译场景,在使用时会使用已经培训好的话术,根据需要的不同场景自动翻译提炼。
结果纠错:大语言模型对于翻译的结果不是稳定可靠的,经常会因为需要翻译的话术存在歧义导致整体翻译的结果不对,或者翻译出来的内容不是纯粹的翻译结果而失败,在进行翻译时,根据多种规则判断翻译的结果是否是正常的翻译内容,包括翻译结果的长度是否和预期差异较大,包括翻译的结果是否是纯粹的结果而不是带了一些其他的干扰词汇等等最终实现翻译结果与预期一致。
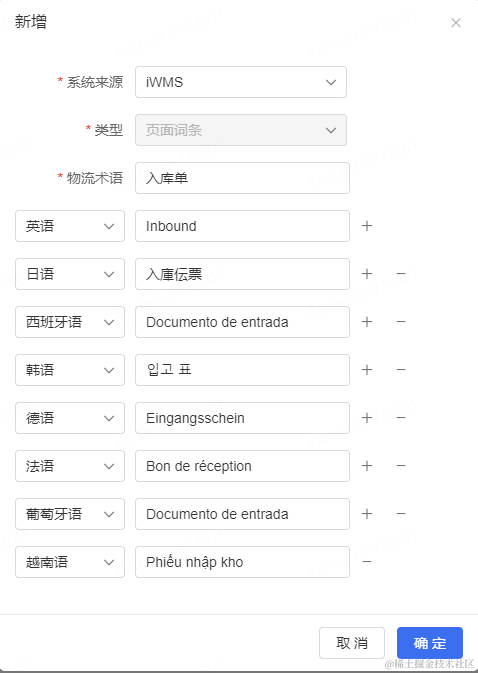
大模型自动化辅助翻译:在新增加词条时,用户选择语言后,利用大模型得到相对应的翻译辅助用户,可直接使用或在此基础上进行调整,大大降低翻译成本。
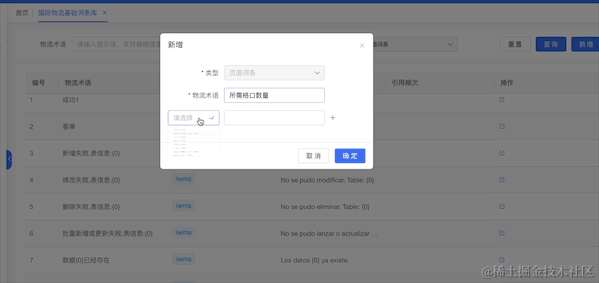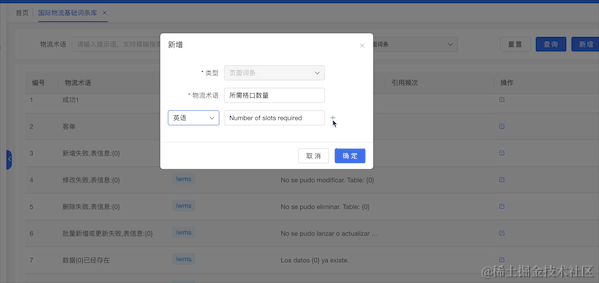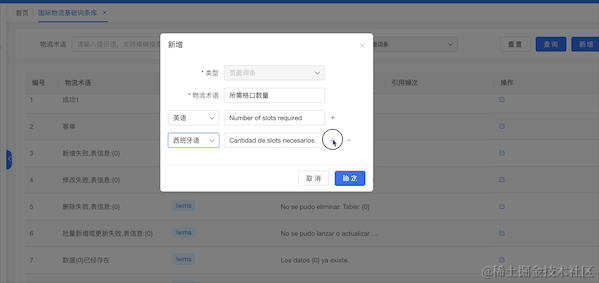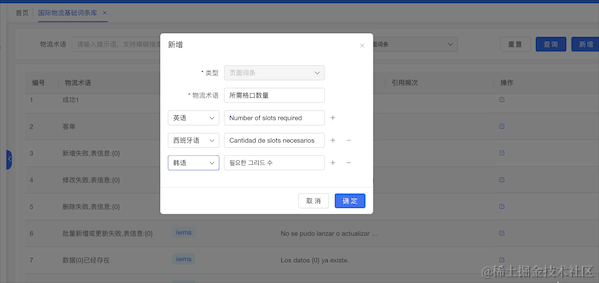
4.3.2 多语言线上化
将多语言包上传至云存储,在每次更新翻译内容并审批通过时自动更新云存储的文件。
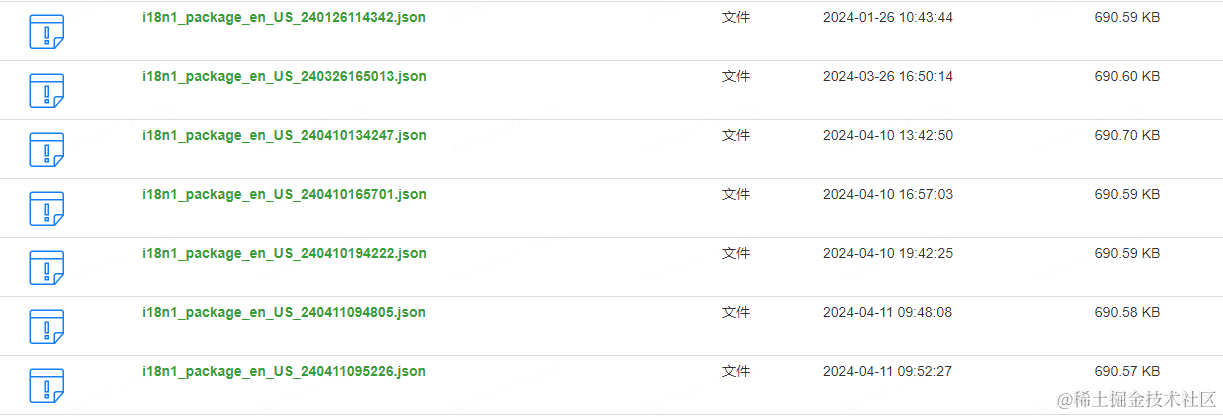
4.3.3 自动版本更新
审批通过以后自动生成新的版本,在前端拉取语言版本时自动拉取的就是最新版本的语言包。系统底层存储了各个语言的版本号,和云存储的文件对应在一起。
4.3.4 自动化词条更新技术
自动化词条更新技术,旨在提升词条更新的效率和专业性。
效率:具体而言,当用户在前端界面启用锚点编辑功能并选中特定词条时,系统将自动触发并展示更新界面。该界面引导用户输入新的词条内容,随后前端将这些更改实时转化为一个待审批的词条替换任务。
专业性:此任务随后被送至管理员端,由具备相应权限的管理员进行审核。审批流程不仅确保了词条更新的合法性和准确性,同时也维护了内容的质量和一致性。
一旦管理员批准了该词条替换任务,所提议的词条更改将被自动应用并立即生效,从而实现了对语言库的快速而审慎的更新。
4.3.5 异常兼容降级
在用户访问应用时,优先拉取最新的语言包,同时存储该版本到本地,下次进入获取各语言包版本,和本地缓存的对应语言包版本进行对比,如果对应语言的版本有更新,则获取新资源同时对本地资源更新。
同时在每次构建时自动拉取最新的语言包并更新,同时该版本作为base(基础)版本,当自动更新词条服务不可用时进行降级处理,继续引用编译构建时的语言包,不影响系统的正常使用。
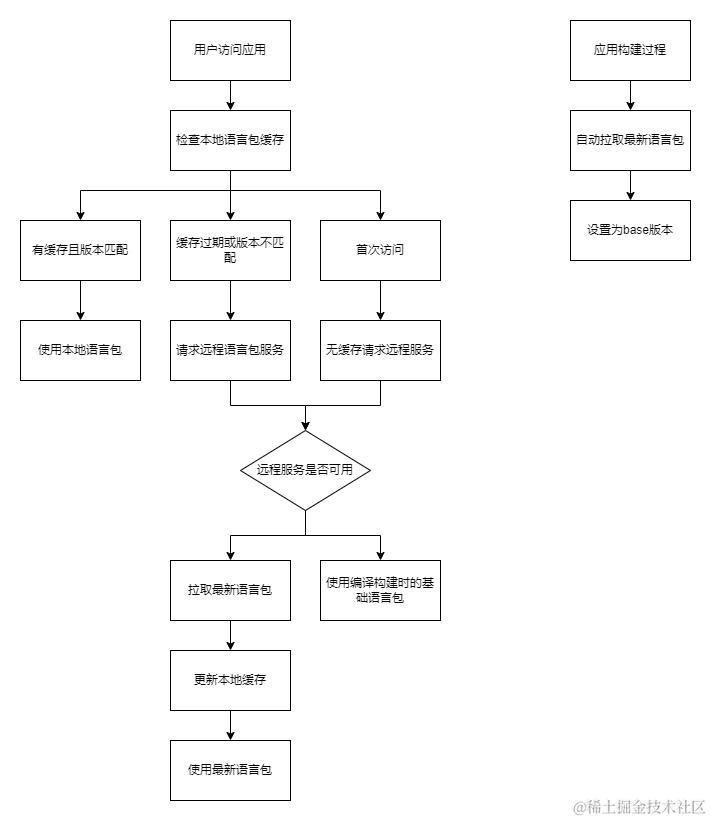
本地缓存的语言包:
通过这种降级方案,我们可以实现:
1.无缝更新:用户可以自动获取最新的语言包,无需手动干预,提升了用户体验。
2.离线支持:即使远程服务不可用,应用也能通过本地缓存的语言包继续运行,保证了应用的可用性。
3.版本兼容性:通过版本检查确保用户总是使用与应用兼容的语言包,避免因版本不匹配导致的潜在问题。
4.构建时更新:在构建应用时自动更新语言包,确保部署的应用总是使用最新的语言资源。
5.资源效率:通过本地缓存减少了重复从远程服务器拉取相同资源的次数,节省了网络带宽和服务器负载。
6.容错性:即使在更新过程中出现问题,系统也可以回退到稳定的base版本,保持系统的稳定性。
7.易于维护:清晰的版本管理和更新逻辑简化了维护工作,便于开发者管理和部署语言资源。
五、实现效果
5.1 人效提升
每个迭代周期按照经验更正20个不规范词条左右,并且每个迭代周期上线1.5次,那么每个月可以节省大约2人日的工作量。这种效率的提升,不仅提高了国际化产品的专业力,还提高了团队的整体生产力。
5.1.1 系统国际化快速复用
在传统的国际化流程中,每当系统需要支持新的语言,通常需要进行繁琐的翻译和本地化工作。然而,通过引入大型模型的翻译能力,我们能够实现快速的语言版本定制和更新。例如,当系统需要支持一种新的语言时,可以利用大模型快速翻译系统代码中的词条,然后通过自动化工具将这些词条集成到系统中,无需进行复杂的手动操作。
此外,通过建立国际物流术语词条库,我们可以确保不同系统之间的术语统一,避免了重复翻译和不一致的问题。这种方法不仅提高了翻译的准确性,还大大减少了研发在多语言支持上的工作量,使得国际化过程更加高效。
5.1.2 词条校准快速高效
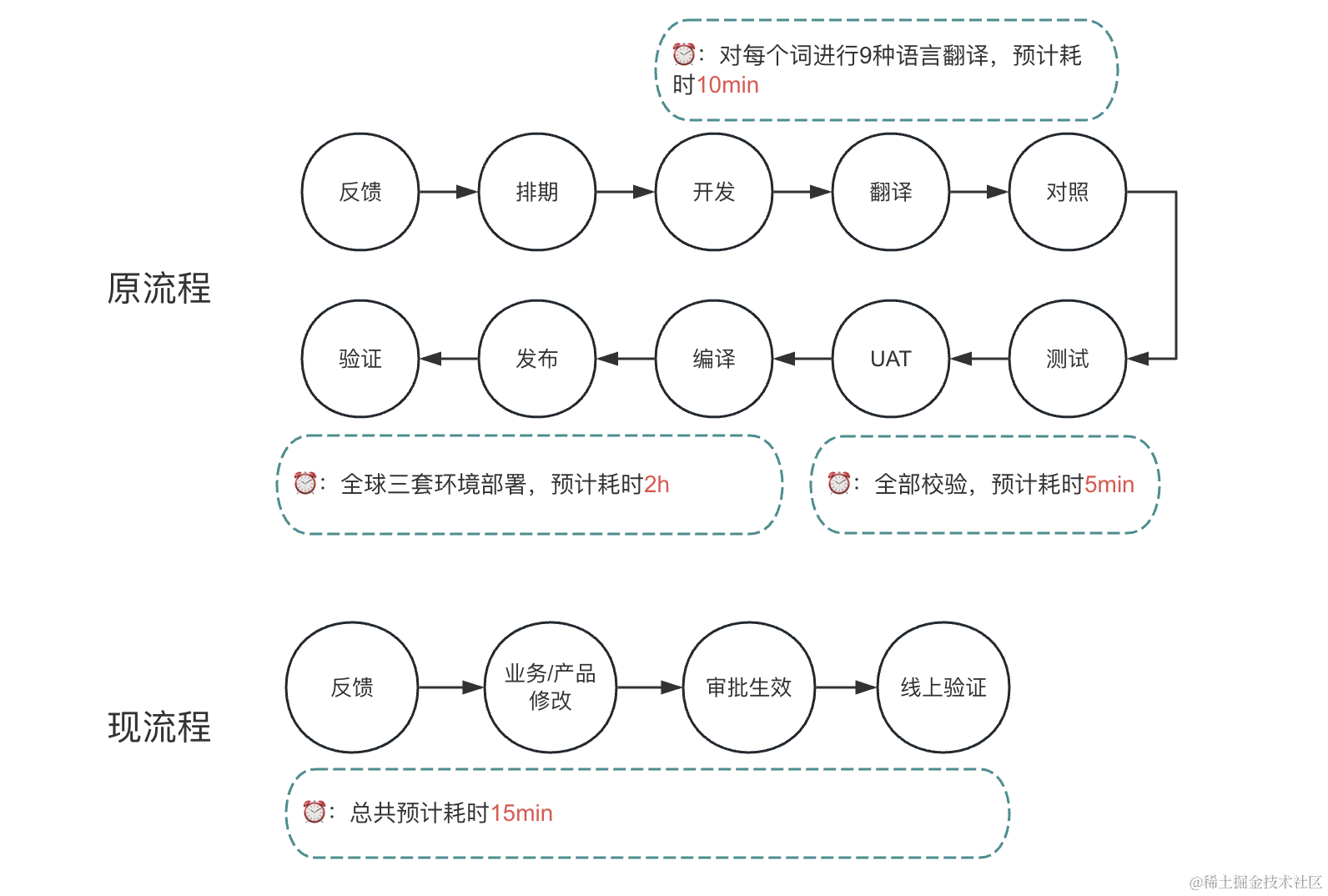
在每个迭代的需求开发时,不再因为词条的更新需要研发不断的发版,每次发版发布多套环境,而是系统自动更新自动生效。只需要在词条管家中修改以后等待审批人审批以后即可生效,极大的缩短词条的生效时间,助力敏捷提效。快速更正不合适的词条,省去各个中间环节。
原有流程完成一次术语修改需要经过10个流程节点才能完成一次术语的修改和生效,每次修改需要2个多小时,主要花费在部署多套环境上。增加了术语库的能力以后,每次修改术语需要4个流程节点,生效时间只需要15分钟左右,真正实现了即改即生效,生效即可见的效果。
5.2 质量提升
5.2.1 物流术语专业统一
为了解决翻译本土化的难题,我们尝试了多种方案。最直接的方法是依赖第三方翻译服务商,但这种做法存在多个问题。首先,成本较高;其次,翻译的准确性无法保证。主要问题是,我们的每个系统都具有专业性,日常使用中看似简单的词汇,翻译公司可能无法准确理解其含义,从而导致翻译结果无法准确表达原意。因此,这种方法产生的结果并不理想。随着越来越多的系统在做国际化,我们发现同行业系统之间有很多词汇是相同的,但是不同系统的翻译结果可能有差异,无法做到术语统一,这会给用户带来困扰,对外体验不好,因此我们孕育出想做一个行业词条库的想法。
通过国际供应链各个系统词条汇总,统计出高频词条,通过GPT智能翻译加人工校对,确保词条翻译的准确性和本土化,有了公共词库作为基础,所有系统多语言翻译优先查询公共词库,确保不同系统术语统一,其次才是复杂文本GPT智能翻译。
国际公共词库成型示意图:
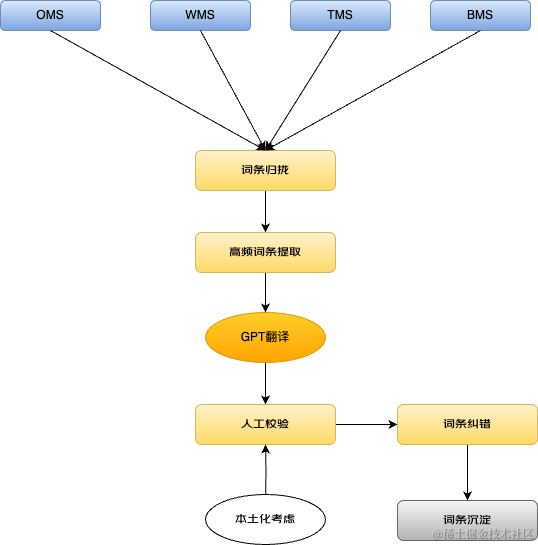
通过现有国际物流系统的词条,我们通过使用频率筛选出高频词条,通过GPT翻译加人工校验的方式进行词条沉淀,考虑到不同位置展示的词条书写格式的差异,词条类型根据不同的用途进行分类管理。比如考虑到菜单类词条可能很多英语写法喜欢缩写,会将页面菜单词条和异常提示词条分类存放,使用的时候同样的词汇会根据具体的类型进行翻译。

通过公共词库的实践,我们避免了很多词汇的二次翻译,同时翻译结果的准确性和本土化程度大幅提高,随着词条沉淀的增多,发挥的作用将会越大,所以,如果你的系统正在做国际化,强烈推荐沉淀一份公共词库,可以让系统翻译更加统一,更加精确。
六、总结规划
当前国际物流术语词条库已经开始建设,但是不同语言在系统层面如何精简的体现且能被用户清晰的知晓还需要不断的摸索和提炼,也希望大家献言献策,不断完善。
国际在多语言的开发过程中不断总结归纳,创新性的将国际的多语言整理成了国际术语词条库,为国际的专业术语统一打下了良好的基础。利用技术优势,将语言包放置到了线上,在打包时自动更新拉取,同时提供线上所见即所得的词条修改能力,不断提高多语言的专业性。
附录: 系统国际化技术解决方案系列—— 系统国际化之多语言解决方案

