
- 1通用大模型VS垂直大模型
- 2[大模型]Qwen2-7B-Instruct Lora 微调_qwen2 微调训练
- 3Python基础入门自学——10_def init(self, output: callable = print) -> bool:
- 4git解决合并冲突_git pull合并冲突
- 5python编写小游戏详细教程,用python做简单的小游戏_怎么编程小游戏
- 6反无人机技术详解
- 7vscode 无法导入自己写的模块文件(.py)问题_vscode中import无法导入
- 8类ChatGPT人工智能技术嵌入数字政府治理:价值、风险及其防控
- 92023年Android社招找工作需要掌握到什么程度?_2023android 简历 相关技能
- 10深度学习之Softmax回归_softmax回归 matlab csdn
通过Whisper模型将YouTube播放列表中的视频转换成高质量文字稿的项目_视频转文字 whisper
赞
踩
项目简介
一个通过Whisper模型将YouTube播放列表中的视频转换成高质量文字稿的项目。
这个基于 Python 的工具旨在将 YouTube 视频和播放列表转录为文本。它集成了多种技术,例如用于转录的 Fast-Whisper、用于自然语言处理的 SpaCy 以及用于 GPU 加速的 CUDA,旨在高效处理视频内容。该脚本能够处理单个视频和整个播放列表,输出准确的文字记录和元数据。项目核心内容:
1、YouTube下载:使用pytube下载YouTube视频或播放列表的音频。
2、音频转录:利用faster_whisper.WhisperModel将音频转换成文字。
3、NLP处理:可选地整合SpaCy,用于改进句子分割,提高文字稿的可读性和结构。
4、CUDA加速:实现CUDA支持,用于兼容硬件的处理速度提升。
这个工具适用于内容分析、辅助创建视频字幕和封闭字幕、教育目的以及视频内容的存档和检索。
功能概述
核心组件
-
YouTube 下载:使用 pytube 从 YouTube 视频或播放列表下载音频。
-
音频转录:利用 faster_whisper.WhisperModel 将音频转换为文本。该模型是 OpenAI 的 Whisper 的变体,旨在提高速度和准确性。
-
NLP 处理:可以选择集成 SpaCy 以进行复杂的句子分割,从而增强转录本的可读性和结构。
-
CUDA 加速:实现对 GPU 利用率的 CUDA 支持,提高兼容硬件的处理速度。
详细工作流程
-
初始化:
-
该脚本首先根据 convert_single_video 标志确定是处理单个视频还是播放列表。
-
它设置必要的目录来存储下载的音频、文字记录和元数据。
-
-
环境配置:
-
将 CUDA Toolkit 路径添加到系统环境以供 GPU 使用。
-
根据 CPU 核心数配置用于转录的工作线程数量。
-
-
视频处理:
-
对于播放列表中的每个视频或单个视频,脚本都会下载音频。
-
它确保每个音频文件的唯一命名以避免覆盖。
-
-
转录:
-
音频文件被传递到 WhisperModel 进行转录。
-
如果可用,该脚本会处理 GPU 加速,否则默认为 CPU。
-
使用 SpaCy 或基于自定义正则表达式的拆分器将转录结果拆分为句子。
-
-
元数据生成:
-
除了脚本之外,脚本还会生成元数据,包括每个片段的时间戳和置信度分数。
-
-
输出:
-
记录以纯文本、CSV 和 JSON 格式保存,提供原始记录和结构化元数据。
-
-
显示/读取:
-
为了使文字记录更易于阅读,提供了一个 html 文件 transcript_reader.html ,它可以进一步清理并提供“阅读器模式”,您可以在其中选择字体、文本大小、文本宽度和切换深色模式。只需在浏览器中打开此 html 文件,然后粘贴 generated_transcript_combined_texts 文件夹中生成的文件之一的转录文本即可。
-
|
|
|---|
| 实际操作的屏幕截图 |
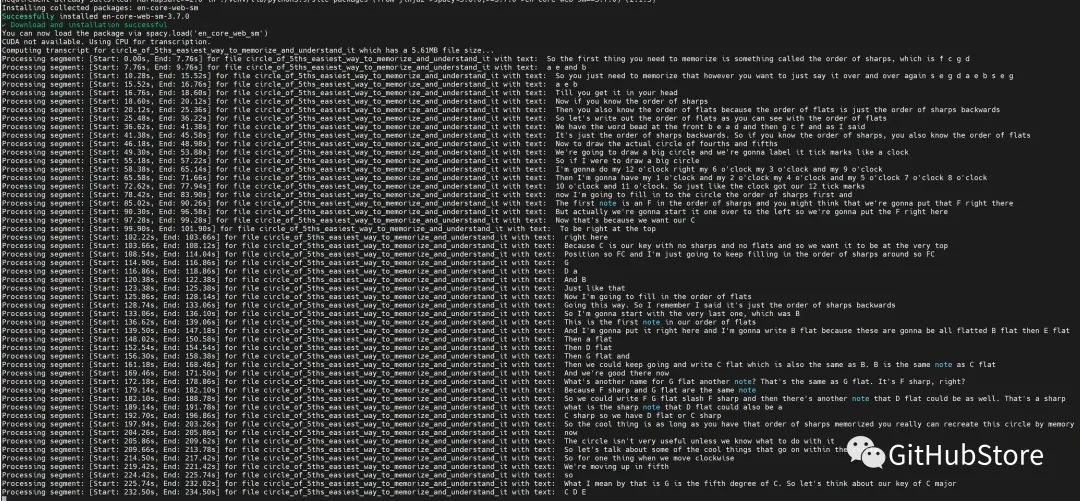
|
|
|
|---|---|
| 将成绩单文本粘贴到成绩单阅读器 HTML 文件中 | 使用深色模式和 Cambria 字体的阅读器 |
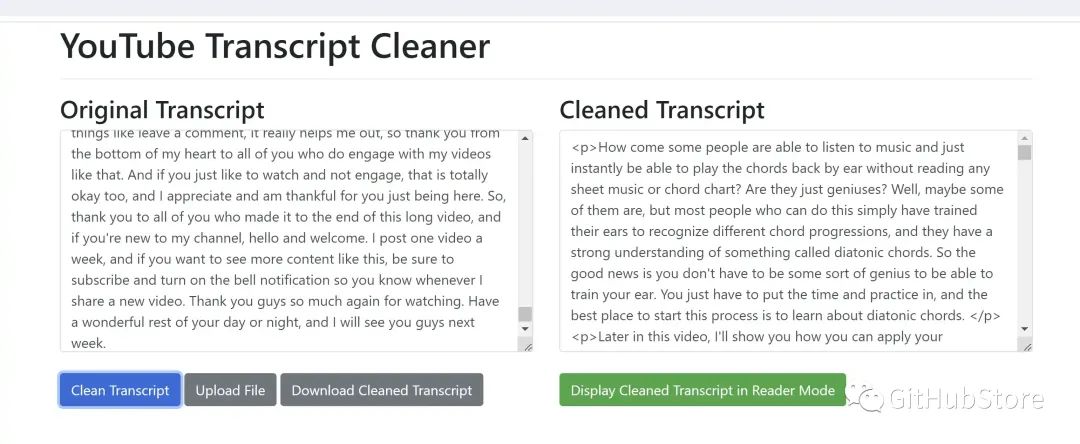

项目链接
https://github.com/Dicklesworthstone/bulk_transcribe_youtube_videos_from_playlist

