
- 1洛谷 P1379 八数码难题_洛谷 八数码
- 2【Python】使用matplotlib绘制图形(曲线图、条形图、饼图等)_matplotlib曲线图
- 3【K8S系列】深入解析k8s网络插件—Weave Net_解析插件
- 4数据结构:插入排序和希尔排序
- 5libevent设置超时后取消超时(bufferevent_set_timeouts取消超时无效问题)_libevent 不使用bufferevent
- 6Matlab之BP神经网络学习------ Day 1_matalab中bp神经网络的隐含层神经元单元怎样找
- 7Docker命令---查看运行中的容器_docker 查看运行的容器
- 8记第一次写微信小程序(先不写了,不看算法和C++心慌)_做小程序需要算法吗
- 9数字信号处理基础----xilinx除法器IP使用_xilinx ip
- 10DevOps搭建(1)- GitLab的安装-CentOS7_centos 安装devops
保姆级教程之VMD-CNN-BILSTM轴承故障诊断,MATLAB代码_轴承故障诊断 代码
赞
踩
本期为大家带来VMD-CNN-BILSTM的轴承故障诊断。
和前几期一样,依旧是包含了数据处理,优化VMD参数,特征提取,再到CNN-BiLSTM的故障诊断,其他类型的故障诊断均可参考此流程。数据替换十分简单!
其中优化VMD参数部分,采用的是最新推出的,效率非常高的融合鱼鹰和柯西变异的麻雀优化算法(OCSSA),文件中也包含了该算法与其他算法的对比的代码。
故障诊断部分,本期作者将CNN-LSTM,CNN-BiLSTM,VMD-CNN-LSTM,VMD-CNN-BiLSTM四种故障诊断模型进行了对比。突出了本期提出的VMD-CNN-BILSTM模型的优越性。
友情提示:对于刚接触故障诊断的新手来说,这篇文章信息量可能有点大,大家可以收藏反复阅读。即便有些内容本篇文章没讲出来,但其中的一些跳转链接,也完全把故障诊断这个故事讲清楚了。
与上一期文章相似,先给大家看看文件夹目录,都是作者精心整理过的。
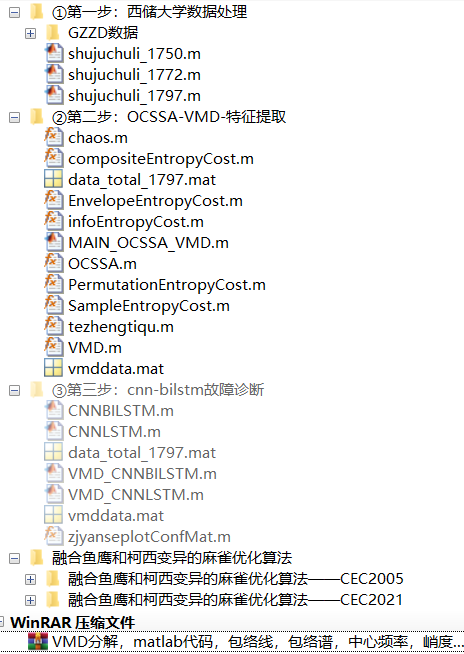
最后一个压缩包是有关VMD画图的程序。考虑到大家可能会用到VMD的相关作图,包络谱,频谱图等,作者在这里也一并附在代码中了。这部分大家需要自行更改数据!也就是作者比较火的文章之一,这里边提到的所有代码:VMD分解,matlab代码,包络线,包络谱,中心频率,峭度值,能量熵,样本熵,模糊熵,排列熵,多尺度排列熵,西储大学数据集为例
如图所示,本期内容一共做了三件事情:
一,对官方下载的西储大学数据进行处理,步骤如下:
1.一共加载10种数据,然后取每个数据的DE_time(%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行)
2.设置滑动窗口w,每个数据的故障样本点个数s,每个故障类型的样本量m
3.将所有的数据滑窗完毕之后,综合到一个data变量中
有关西储大学数据的处理之前有文章也讲过,大家可以看这篇文章:西储大学轴承诊断数据处理,matlab免费代码获取
图中的1750,1772,1790是西储大学轴承的转速,大家做诊断的时候,选择其中一个即可,即选同一转速下的不同故障进行诊断更有意义!
二,对第一步数据处理得到的数据进行特征提取
选取五种适应度函数进行优化,这里大家可以自行决定选哪一个!以此确定VMD的最佳k和α参数。五种适应度函数分别是:最小包络熵,最小样本熵,最小信息熵,最小排列熵,排列熵/互信息熵,代码中可以一键切换。至于应该选择哪种作为自己的适应度函数,大家可以看这篇文章。VMD为什么需要进行参数优化,最小包络熵/样本熵/排列熵/信息熵,适应度函数到底该选哪个
老粉应该知道,之前也推过一篇文章,就是关于西储大学特征提取的,但当时作者懒,没有写一个大循环,需要大家针对每种类型的数据依次提取。这次,作者把特征提取写了一个大循环,方便一键特征提取,大家也可以很简单的更换自己的数据!
至于特征提取的具体原理,也在这篇文章进行过详细介绍,大家可以跳转阅读。简单来说,就是利用包络熵最小的准则把每个样本的最佳IMF分量提取出来,然后对其9个指标进行计算,分别是:均值,方差,峰值,峭度,有效值,峰值因子,脉冲因子,波形因子,裕度因子。然后用这9个指标构建每个样本的特征向量。
另外本期文章采用了一个新颖的效率较高的智能算法---效率非常高的融合鱼鹰和柯西变异的麻雀优化算法(OCSSA)对VMD参数进行了优化,该算法是由作者自行改进。找到了每个故障类型的最佳IMF分量,并利用包络熵最小的准则,提取出了最佳的IMF分量。
提取特征后,每种状态是120个样本,一共十个状态,得到一个1200*9列的矩阵,然后对每行数据打上标签。1-10代表不同的故障类型。划分每种状态的前90组为训练集,后30组为测试集。
三,采用CNN-BILSTM实现故障分类
本期作者将CNN-LSTM,CNN-BiLSTM,VMD-CNN-LSTM,VMD-CNN-BiLSTM四种故障诊断模型进行了对比。
结果展示
为了突出VMD-CNN-BiLSTM优越性,将四个模型的训练次数都设置为150,学习率为0.01,正则化参数为0.001,训练100次后开始调整学习率,学习率调整因子为0.01。统计结果如下:
| 算法 | 准确率 | 训练时间 |
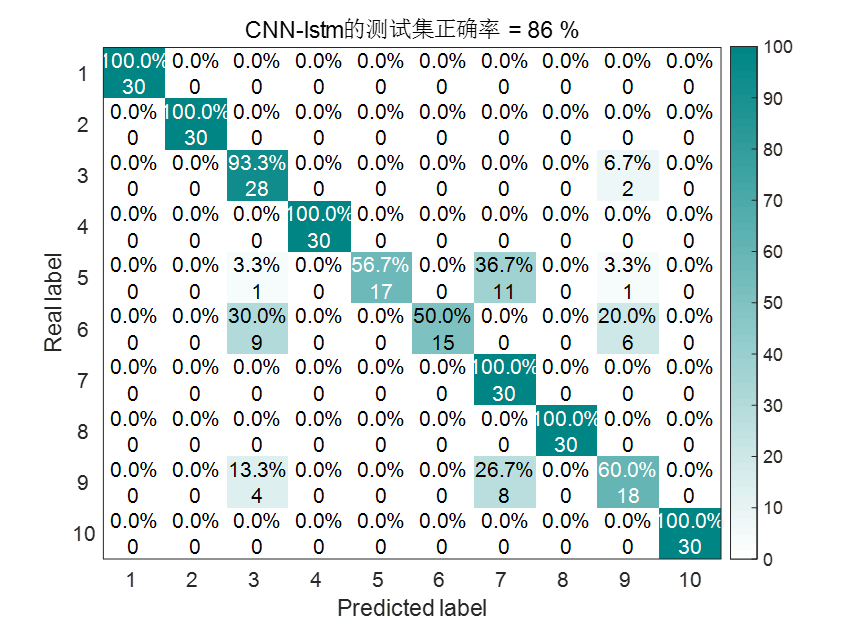
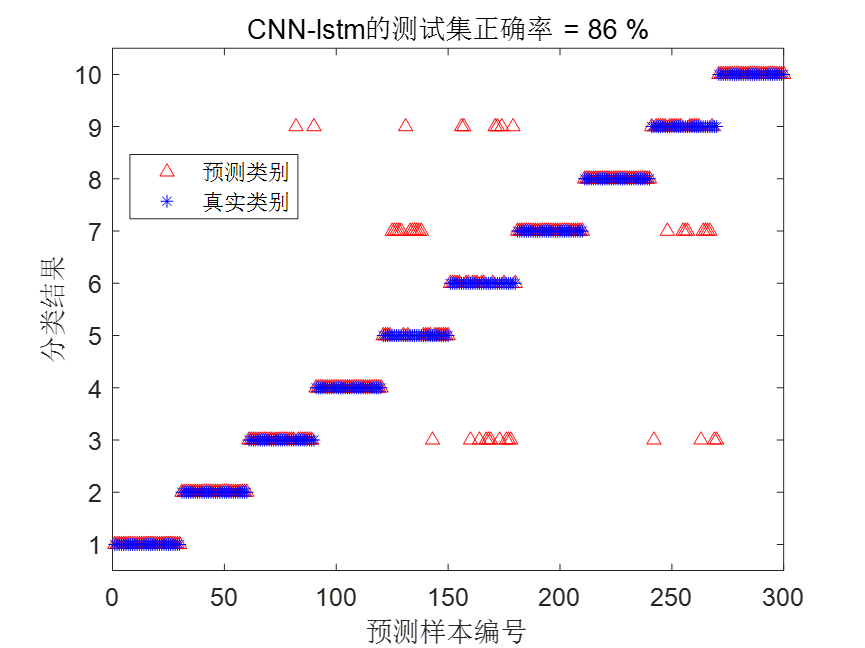
| CNN-LSTM | 86% | 165.003936秒 |
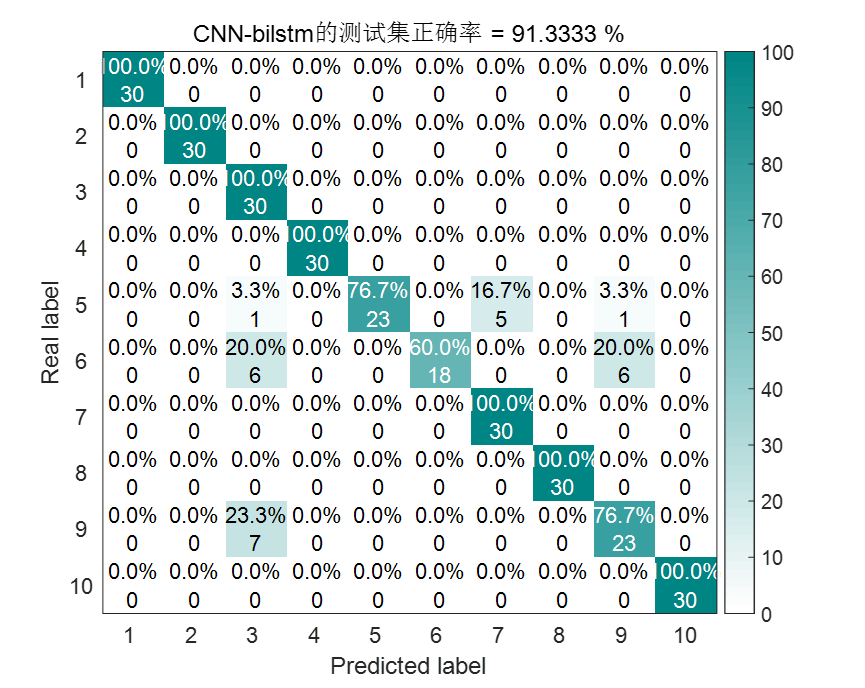
| CNN-BiLSTM | 91.33% | 236.622348秒 |
| VMD-CNN-LSTM | 95.667% | 8.148243秒 |
| VMD-CNN-BiLSTM | 99.33% | 8.905423 秒 |
根据统计结果可以看到,VMD-CNN-BiLSTM诊断模型不仅大大缩减了训练时间,而且诊断精度也是最高的。
CNN-LSTM结果图
CNN-BiLSTM结果图
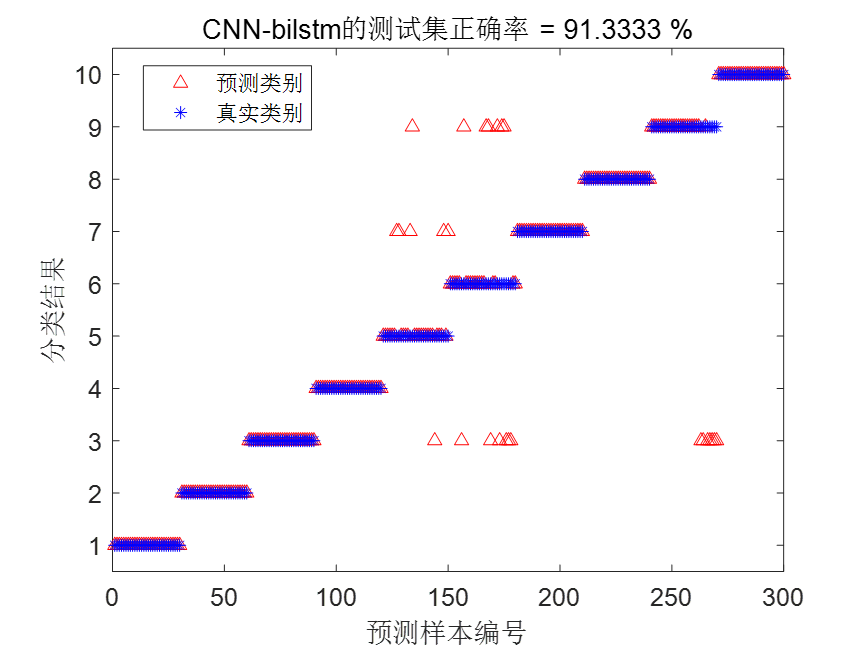
VMD-CNN-LSTM结果图
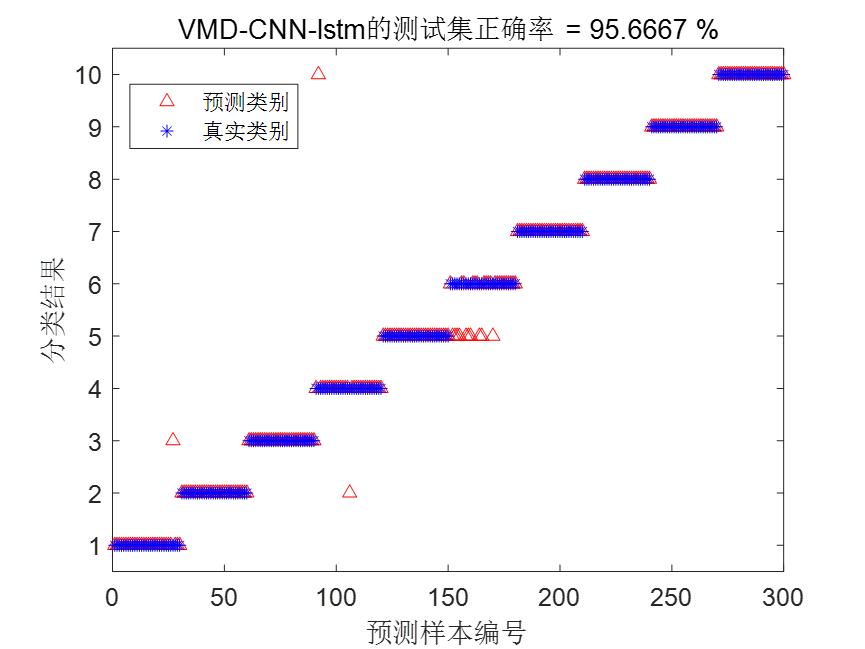

VMD-CNN-BiLSTM结果图

部分代码
数据处理代码:
OCSSA优化VMD参数并特征提取的代码:
CNNBILSTM诊断的代码:
- %% 初始化
- clear
- close all
- clc
- warning off
- % 数据读取
- addpath(genpath(pwd));
- load data_total_1797.mat %加载处理好的特征数据
- % 数据载入
- bv = 120; %每种状态数据有120组
- % 加标签值
- hhh = size(data,2);
- for i=1:size(data,1)/bv
- data(1+bv*(i-1):bv*i,hhh+1)=i;
- end
- input=data(:,1:hhh);
- output =data(:,end);
-
-
- jg = bv; %每组120个样本
- tn = 90; %选前tn个样本进行训练
- input_train = []; output_train = [];
- input_test = []; output_test = [];
- for i = 1:max(data(:,end))
- input_train=[input_train;input(1+jg*(i-1):jg*(i-1)+tn,:)];
- output_train=[output_train;output(1+jg*(i-1):jg*(i-1)+tn,:)];
- input_test=[input_test;input(jg*(i-1)+tn+1:i*jg,:)];
- output_test=[output_test;output(jg*(i-1)+tn+1:i*jg,:)];
- end
- input_train = input_train';
- input_test = input_test';
- %归一化
- [inputn_train,inputps]=mapminmax(input_train);
- [inputn_test,inputtestps]=mapminmax('apply',input_test,inputps);
- output_train = categorical(output_train);
- output_test = categorical(output_test);
-
-
- for i = 1:size(input_train,2)
- Train_xNorm{i,:} = reshape(inputn_train(:,i),hhh,1,1);
- end
-
-
- for i = 1:size(input_test,2)
- Test_xNorm{i,:} = reshape(inputn_test(:,i),hhh,1,1);
- end
-
-
- numFeatures = size(input,2);
- numHiddens = 120;
- numClasses = 10;

代码获取
每一步代码都有非常详细的注释,数据替换也十分简单!
完整代码获取,点击下方卡片后台回复关键词:
tgdm826

