
大数据 MapReduce_mapreduce计算总数为5000蓝色球
赞
踩
只要一个生命的精神世界足够丰富,他是不会感到孤独的。因为他能从不同生命中,感受到存在的意义。
前言
- 大数据 基础概念
- 大数据 Centos基础
- 大数据 Shell基础
- 大数据 ZooKeeper
- 大数据 Hadoop介绍、配置与使用
- 大数据 Hadoop之HDFS
- 大数据 MapReduce
- 大数据 Hive
- 大数据 Yarn
- 大数据 MapReduce使用
- 大数据 Hadoop高可用HA
介绍
摘录自:MapReduce
Hadoop的思想来源于Google的几篇论文,Google的那篇MapReduce论文里说:Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages。这句话提到了MapReduce思想的渊源,大致意思是,MapReduce的灵感来源于函数式语言(比如Lisp)中的内置函数map和reduce。函数式语言也算是阳春白雪了,离我们普通开发者总是很远。简单来说,在函数式语言里,map表示对一个列表(List)中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。它们具体的计算是通过传入的函数来实现的,map和reduce提供的是计算的框架。不过从这样的解释到现实中的MapReduce还太远,仍然需要一个跳跃。再仔细看,reduce既然能做迭代计算,那就表示列表中的元素是相关的,比如我想对列表中的所有元素做相加求和,那么列表中至少都应该是数值吧。而map是对列表中每个元素做单独处理的,这表示列表中可以是杂乱无章的数据。这样看来,就有点联系了。在MapReduce里,Map处理的是原始数据,自然是杂乱无章的,每条数据之间互相没有关系;到了Reduce阶段,数据是以key后面跟着若干个value来组织的,这些value有相关性,至少它们都在一个key下面,于是就符合函数式语言里map和reduce的基本思想了。
这样我们就可以把MapReduce理解为,把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。这就回到了最初,终于知道MapReduce为何要这样设计。
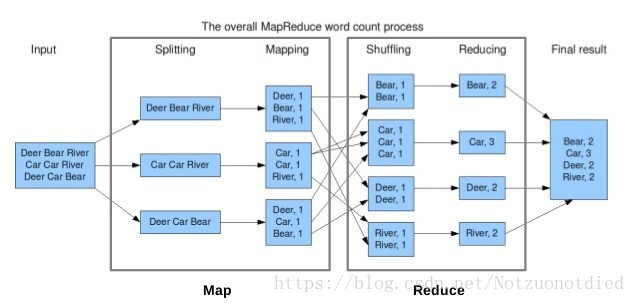
MapReduce分析
MapReduce是Hadoop的一个核心部分,今天看了之后,觉得需要仔细学习分析下,O(∩_∩)O哈哈~
概要
MapReduce其实是分治算法的一种实现,所谓分治算法就是“就是分而治之 ,将大的问题分解为相同类型的子问题(最好具有相同的规模),对子问题进行求解,然后合并成大问题的解。
MapReduce就是分治法的一种,将输入进行分片,然后交给不同的Task进行处理,然后合并成最终的解。
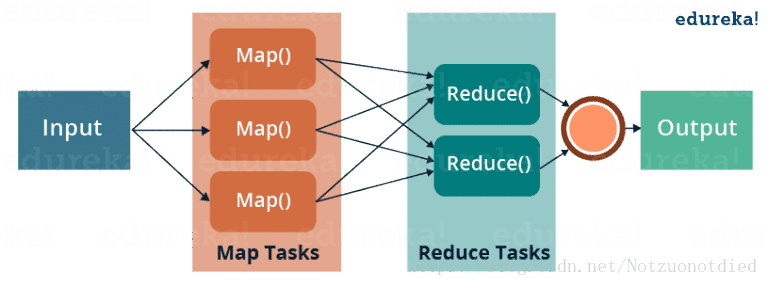
MapReduce可以分为两个主要的部分Map和Reduce。Map从Input获取数据,将数据转换为<key, value>形式的数据,传给Reduce进行处理,再由Reduce合并处理数据后输出用户需要的结果。
以下图为例,Splitting过程将数据拆分交由Mapping,Mapping将数据处理为<key, value>的形式,而Shuffling则将数据进行合并,由Reduce进行统计,最后将结果输出。
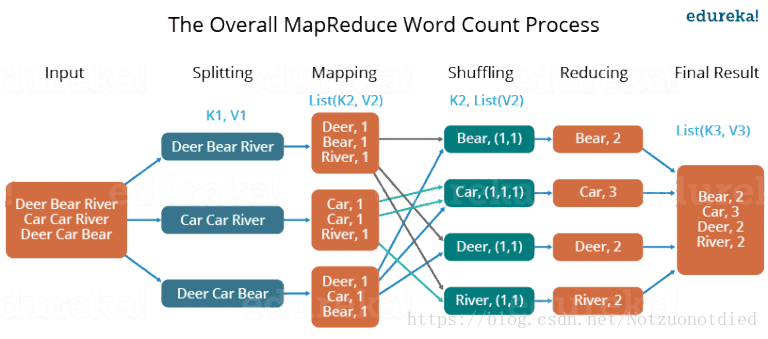
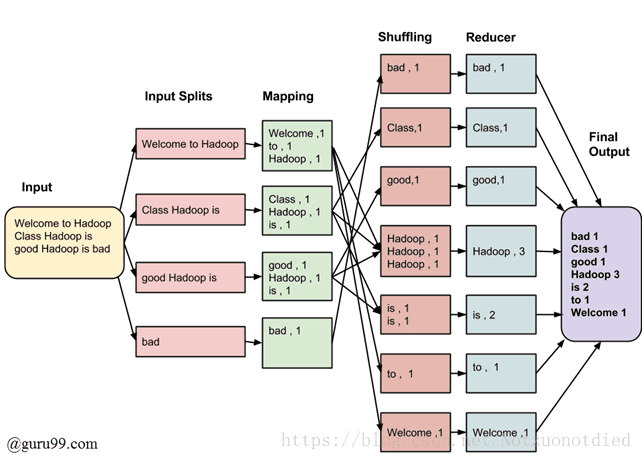
如果细分的话,还可以将MapReduce的过程细分为——Input、Split、Map、Shuffle、Reduce,分别代表了输入,数据分块,Map,Shuffle,Reduce。后面几个是我要仔细分析的部分,详细的内容请见后半部分。
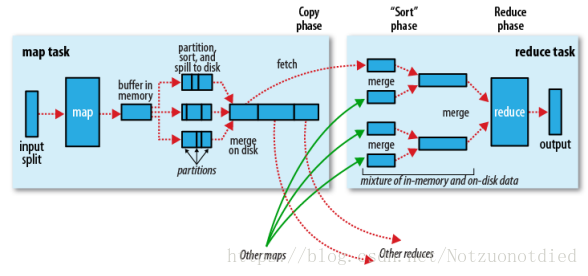
上图中分为Map任务和Reduce任务两个阶段,从Map端输出到Reduce端的红色和绿色的线表示数据流的一个过程,也就是Shuffle的过程。
| 流程 | 说明 |
|---|---|
| Map | 数据输入,做初步的处理,输出形式的中间结果。 |
| Shuffle | 按照partition、key对中间结果进行排序合并,输出给Reducer线程。 |
| Reduce | 对相同key的输入进行最终的处理,并将结果写入到文件中。 |
其中Shuffle可以分为Map端部分和Reduce端部分。Map端实际包含了输入(input)过程、切分(partition)过程、溢写spill过程(sort和combine过程)、合并(merge)过程。Reduce端实际包括了复制(copy)、合并(merge)的过程。
Shuffle过程的期望
对于Hadoop集群,当我们在运行作业时,大部分的情况下,MapTask与ReduceTask的执行是分布在不同的节点上的,因此,很多情况下,Reduce执行时需要跨节点去拉取其他节点上的MapTask结果,这样造成了集群内部的网络资源消耗很严重,而且在节点的内部,相比于内存,磁盘IO对性能的影响是非常严重的。如果集群中运行的作业有很多,那么task的执行对于集群内部网络的资源消费非常大。因此,我们对于MapRedue作业Shuffle过程的期望是:
- 完整地从
MapTask端拉取数据到Reduce端; - 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗;
- 减少磁盘IO对
Task执行的影响。
Shuffle-Map
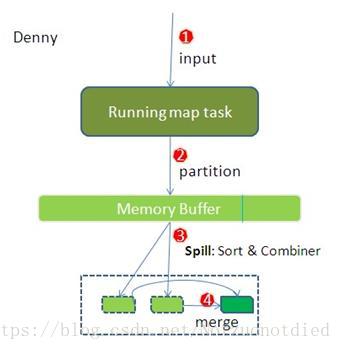
Input
在MapTask执行的时候,其输入来源HDFS的Block,MapTask只读取Split。Spilt与Block的对应关系可能是多对一,默认是一对一。
Partition
MapReduce提供了Partitioner接口,其作用是根据Key或Value及Reduce的数量来决定当前这对输出数据最终应该交由哪个ReduceTask处理。默认对Key进行哈希运算后,再以ReduceTask数量取模。接下来需要将数据写入内存缓冲区中。缓冲区的作用就是批量收集Map结果,减少磁盘I/O影响。
Spilt
内存缓冲区的大小默认是
100
M
100M
100M,是一个环状的缓存数组。当MapTask输出结果很多的时候,内存缓冲区可能会不足,所以需要在超过默认阈值
0.8
0.8
0.8(io.sort.spil l.percent)的时候,就会发生Spill溢写的过程,将缓冲区中的数据临时写入到本地磁盘中,循环利用这个内存缓冲区。如果Spill溢写的过程有多次,则会有多个缓存文件。
这个Spill溢写是由单独线程来完成,不影响往缓冲区写Map结果的线程。溢写线程启动时不应该阻止Map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是
0.8
0.8
0.8,也就是当缓冲区的数据已经达到阈值(
b
u
f
f
e
r
S
i
z
e
∗
s
p
i
l
l
P
e
r
c
e
n
t
=
100
M
B
∗
0.8
=
80
M
B
bufferSize * spillPercent = 100MB * 0.8 = 80MB
bufferSize∗spillPercent=100MB∗0.8=80MB),溢写线程启动,锁定这
80
M
B
80MB
80MB的内存,执行溢写过程。MapTask的输出结果还可以往剩下的
20
M
B
20MB
20MB内存中写,互不影响。
Sort
在将数据写入磁盘之前,先要对要写入磁盘的数据进行一次排序操作(在内存中完成排序,这里使用的排序方法是快排),先按<key,value,partition>中的partition分区号排序,然后再按key排序,这个就是sort操作,最后溢出的小文件是分区的,且同一个分区内是保证key有序的。
Combine
执行combine操作要求开发者必须在程序中设置了combine(程序中通过job.setCombinerClass(myCombine.class)自定义combine操作)。
- 程序中有两个阶段可能会执行
combine操作:Map输出数据根据分区排序完成后,在写入文件之前会执行一次Combine操作(前提是Job中设置了这个操作);- 如果
Map输出比较大,溢出文件个数大于3(此值可以通过属性min.num.spills.for.combine配置)时,在merge的过程(多个spill文件合并为一个大文件)中还会执行combine操作;
combine主要是把形如<test, 1> <test, 1> <test, 2>这样的key值相同的Value进行相进行简单的统计工作,将相同的Value值进行相加,如上例的结果为<test, 4>。
merge
在最终结果输出之前会对多个溢写文件进行合并,保证最终输出结果有且仅有一个中间数据文件,该过程称为merge。
- 如果生成的文件太多,可能会执行多次合并,每次最多能合并的文件数默认为
10
10
10,可以通过属性
min.num.spills.for.combine配置; - 多个溢出文件合并时,会进行一次排序,排序算法是多路归并排序;
- 是否还需要做
combine操作,一是看是否设置了combine,二是看溢出的文件数是否大于等于3; - 最终生成的文件格式与单个溢出文件一致,也是按分区顺序存储,并且输出文件会有一个对应的索引文件,记录每个分区数据的起始位置,长度以及压缩长度,这个索引文件名叫做
file.out.index。
说明
Map过程的输出是写入本地磁盘而不是HDFS,因为写入到HDFS必然带来不必要的网络开销。
输出数据先存放在缓存数组中而不是直接写入到本地,好处在于可以减少磁盘I/O的开销,提高合并和排序的速度。
Shuffle-Reduce
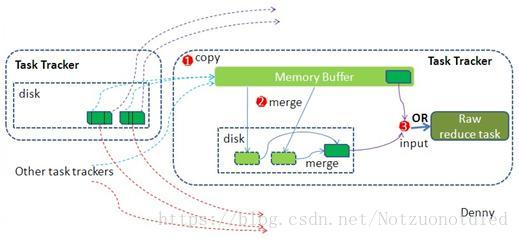
Copy
Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求MapTask所在的TaskTracker获取MapTask的输出文件。因为这时MapTask早已结束,这些文件就归TaskTracker管理在本地磁盘中。
默认情况下,当整个MapReduce作业的所有已执行完成的MapTask任务数超过MapTask总数的
5
5%
5后,JobTracker便会开始调度执行ReduceTask任务。然后ReduceTask任务默认启动mapred.reduce.parallel.copies(默认为
5
5
5)个MapOutputCopier线程到已完成的MapTask任务节点上分别copy一份属于自己的数据。这些copy的数据会首先保存的内存缓冲区中,当内冲缓冲区的使用率达到一定阀值后,则写到磁盘上。
Merge
从Map端复制来的数据首先写到Reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、sort等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为Reduce的输入而不是写入到磁盘中。
Reduce
Merge的最后会生成一个文件,大多数情况下存在于磁盘中,但是需要将其放入内存中。当Reducer输入文件已定,整个Shuffle阶段才算结束。然后就是Reducer执行,把结果放到HDFS上。
完整图例
点击查看原图:查看
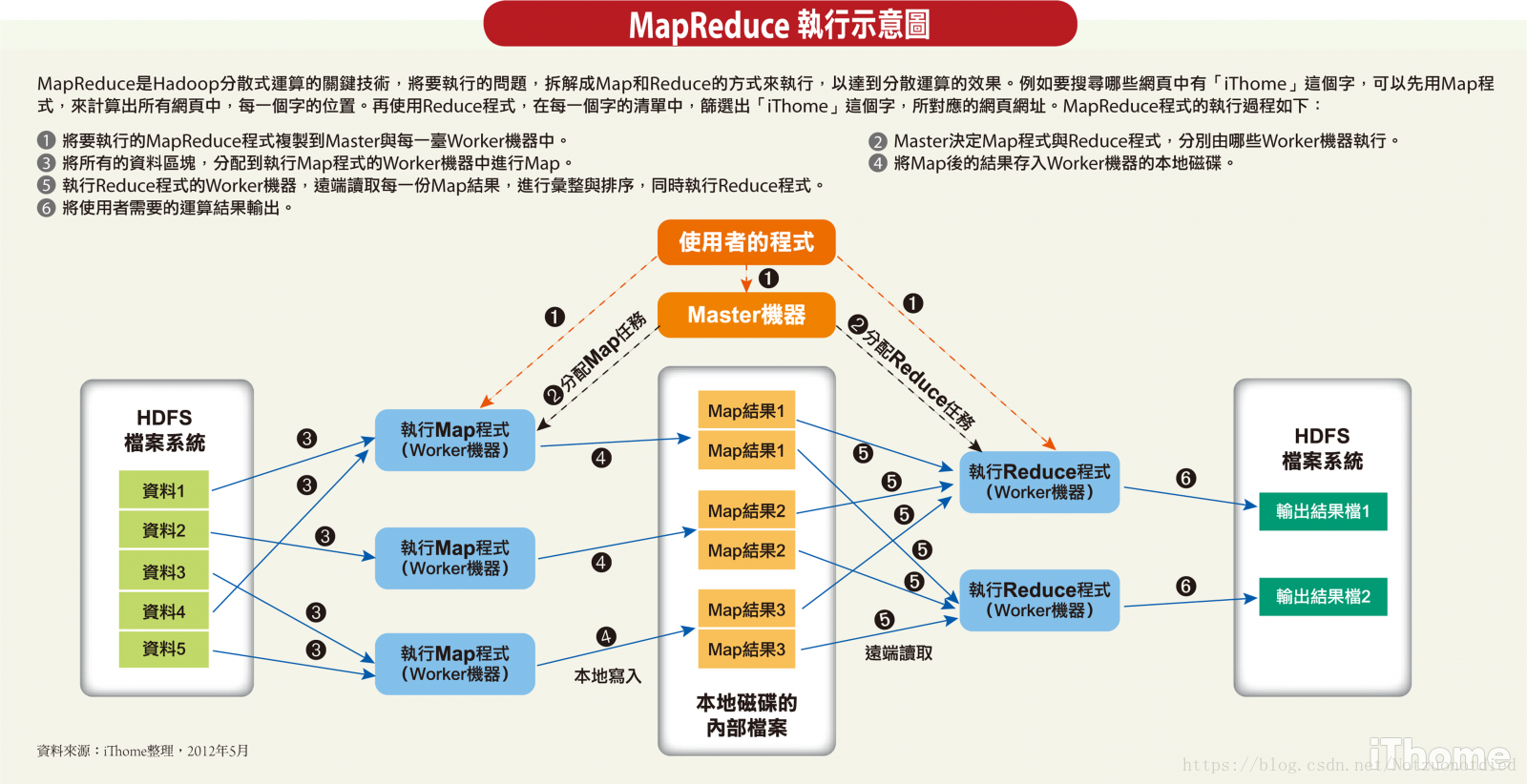
总结
Map每次从split后的分块中一行一行的读取数据,然后将处理后的形为<key, value>的数据放在buffer缓冲区中,并对数据分区partition、排序sort。当缓冲区达到默认阈值
0.8
0.8
0.8后,会发生spill溢写操作,将数据写入到本地磁盘中。磁盘中可能会由于多次溢写生成很多个溢写小文件,而这些小文件内部是有序的,但小文件和小文件之间是无序的,所以需要进行多次归并,合并成一个全盘有序的文件。
由于一个split对应一个Map,Reduce端是从多个Map中拉取数据,所以也需要进行归并为一个有序的文件,最终每个相同的key分为一组执行一次Reduce方法,并将结果写入到HDFS中。
Hadoop中的压缩
附录
论文
教程
- Hadoop MapReduce Tutorial
- MapReduce Tutorial: Introduction
- MapReduce之Shuffle过程详述
- 详细的介绍了
Shuffle的流程。
- 详细的介绍了
- Hadoop学习笔记—10.Shuffle过程那点事儿
- Hadoop学习之一: MapReduce简介
- 【Hadoop】MapReduce笔记(三):MapReduce的Shuffle和Sort阶段详解
- MapReduce:详解Shuffle过程
- MapReduce过程详解
另辟蹊径的分析
系列文章
很赞的几篇文章


{kind=link}