
- 1绘制箱线图 与 异常值的输出 - 基于Python matplotlib库(1)_箱线图的异常值输出
- 2自然语言处理(NLP)—— 神经网络自然语言处理(Neural NLP)基础知识
- 3深入理解机器学习:概念、步骤、分类与实现_列举出两种以上机器学习什么什么过程
- 4一个初级运维工程师对于运维工作的一些浅显认知_设备运维工程师算不算研发岗
- 5数据结构(五)----特殊矩阵的压缩存储_压缩存储结构
- 6粤港澳青少年信息学创新大赛 Python 编程竞赛(初中部分知识点整理)_粤港澳青少年信息大赛初中python题目及答案
- 7深度学习图像处理04:图像分类模型训练实战——动物分类_动物分类数据集
- 8【VirtualBox】--- 从零开始搭建 Ubuntu系统 超详细
- 9MySql个人学习资料_mysql学习资料
- 10AI 大模型 | LLM 大型语言模型 VS 多模态模型_大语言模型和多模态模型
Go最全情感分析——深入snownlp原理和实践(3),2024-2024历年网易跳动Golang面试真题解析_snownlp公式
赞
踩
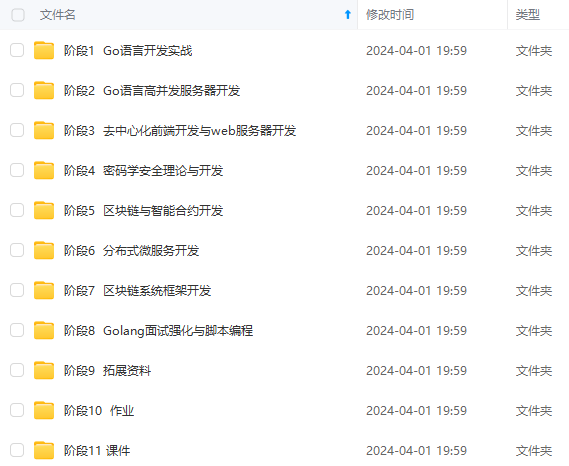

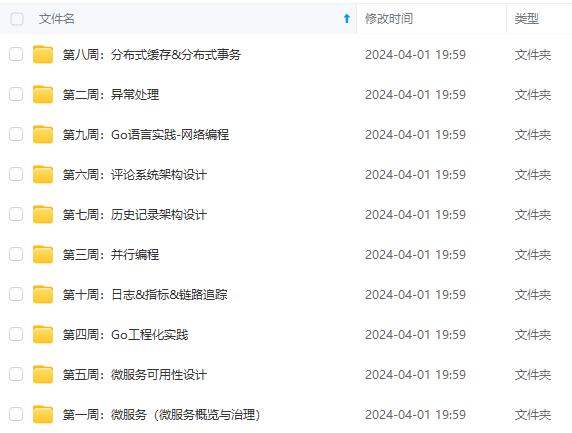
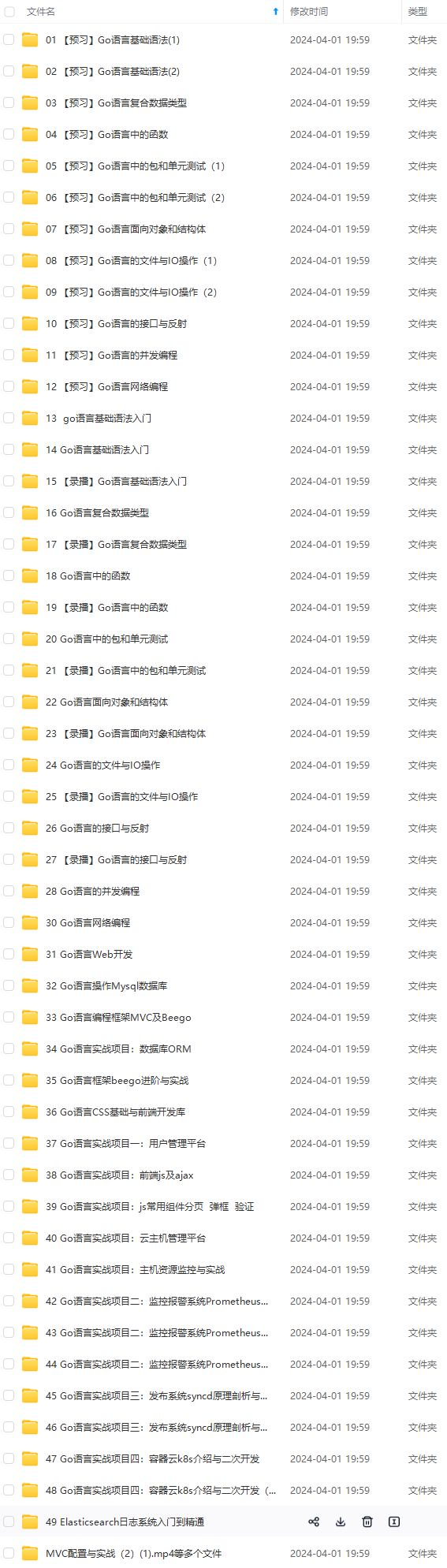
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
一、snownlp简介
snownlp是什么?
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。
以上是官方对snownlp的描述,简单地说,snownlp是一个中文的自然语言处理的Python库,支持的中文自然语言操作包括:
- 中文分词
- 词性标注
- 情感分析
- 文本分类
- 转换成拼音
- 繁体转简体
- 提取文本关键词
- 提取文本摘要
- tf,idf
- Tokenization
- 文本相似
在本文中,将重点介绍snownlp中的情感分析(Sentiment Analysis)。
二、snownlp情感分析模块的使用
2.1、snownlp库的安装
snownlp的安装方法如下:
pip install snownlp
- 1
2.2、使用snownlp情感分析
利用snownlp进行情感分析的代码如下所示:
#coding:UTF-8 import sys from snownlp import SnowNLP def read\_and\_analysis(input\_file, output\_file): f = open(input_file) fw = open(output_file, "w") while True: line = f.readline() if not line: break lines = line.strip().split("\t") if len(lines) < 2: continue s = SnowNLP(lines[1].decode('utf-8')) # s.words 查询分词结果 seg_words = "" for x in s.words: seg_words += "\_" seg_words += x # s.sentiments 查询最终的情感分析的得分 fw.write(lines[0] + "\t" + lines[1] + "\t" + seg_words.encode('utf-8') + "\t" + str(s.sentiments) + "\n") fw.close() f.close() if __name__ == "\_\_main\_\_": input_file = sys.argv[1] output_file = sys.argv[2] read_and_analysis(input_file, output_file)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
上述代码会从文件中读取每一行的文本,并对其进行情感分析并输出最终的结果。
注:库中已经训练好的模型是基于商品的评论数据,因此,在实际使用的过程中,需要根据自己的情况,重新训练模型。
2.3、利用新的数据训练情感分析模型
在实际的项目中,需要根据实际的数据重新训练情感分析的模型,大致分为如下的几个步骤:
- 准备正负样本,并分别保存,如正样本保存到
pos.txt,负样本保存到neg.txt; - 利用snownlp训练新的模型
- 保存好新的模型
重新训练情感分析的代码如下所示:
#coding:UTF-8
from snownlp import sentiment
if __name__ == "\_\_main\_\_":
# 重新训练模型
sentiment.train('./neg.txt', './pos.txt')
# 保存好新训练的模型
sentiment.save('sentiment.marshal')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:若是想要利用新训练的模型进行情感分析,需要修改代码中的调用模型的位置。
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'sentiment.marshal')
- 1
三、snownlp情感分析的源码解析
snownlp中支持情感分析的模块在sentiment文件夹中,其核心代码为__init__.py
如下是Sentiment类的代码:
class Sentiment(object): def \_\_init\_\_(self): self.classifier = Bayes() # 使用的是Bayes的模型 def save(self, fname, iszip=True): self.classifier.save(fname, iszip) # 保存最终的模型 def load(self, fname=data\_path, iszip=True): self.classifier.load(fname, iszip) # 加载贝叶斯模型 # 分词以及去停用词的操作 def handle(self, doc): words = seg.seg(doc) # 分词 words = normal.filter_stop(words) # 去停用词 return words # 返回分词后的结果 def train(self, neg\_docs, pos\_docs): data = [] # 读入负样本 for sent in neg_docs: data.append([self.handle(sent), 'neg']) # 读入正样本 for sent in pos_docs: data.append([self.handle(sent), 'pos']) # 调用的是Bayes模型的训练方法 self.classifier.train(data) def classify(self, sent): # 1、调用sentiment类中的handle方法 # 2、调用Bayes类中的classify方法 ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法 if ret == 'pos': return prob return 1-probclass Sentiment(object): def \_\_init\_\_(self): self.classifier = Bayes() # 使用的是Bayes的模型 def save(self, fname, iszip=True): self.classifier.save(fname, iszip) # 保存最终的模型 def load(self, fname=data\_path, iszip=True): self.classifier.load(fname, iszip) # 加载贝叶斯模型 # 分词以及去停用词的操作 def handle(self, doc): words = seg.seg(doc) # 分词 words = normal.filter_stop(words) # 去停用词 return words # 返回分词后的结果 def train(self, neg\_docs, pos\_docs): data = [] # 读入负样本 for sent in neg_docs: data.append([self.handle(sent), 'neg']) # 读入正样本 for sent in pos_docs: data.append([self.handle(sent), 'pos']) # 调用的是Bayes模型的训练方法 self.classifier.train(data) def classify(self, sent): # 1、调用sentiment类中的handle方法 # 2、调用Bayes类中的classify方法 ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法 if ret == 'pos': return prob return 1-prob
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
从上述的代码中,classify函数和train函数是两个核心的函数,其中,train函数用于训练一个情感分类器,classify函数用于预测。在这两个函数中,都同时使用到的handle函数,handle函数的主要工作为:
- 对输入文本分词
- 去停用词
情感分类的基本模型是贝叶斯模型Bayes,对于贝叶斯模型,可以参见文章简单易学的机器学习算法——朴素贝叶斯。对于有两个类别
c1
c
1
c_1和
c2
c
2
c_2的分类问题来说,其特征为
w1,⋯,wn
w
1
,
⋯
,
w
n
w_1,\cdots ,w_n,特征之间是相互独立的,属于类别
c1
c
1
c_1的贝叶斯模型的基本过程为:
P(c1∣w1,⋯,wn)=P(w1,⋯,wn∣c1)⋅P(c1)P(w1,⋯,wn)
P
(
c
1
∣
w
1
,
⋯
,
w
n
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
)
P\left ( c_1\mid w_1,\cdots ,w_n \right )=\frac{P\left ( w_1,\cdots , w_n\mid c_1 \right )\cdot P(c_1)}{P\left ( w_1,\cdots ,w_n \right )}
其中:
P(w1,⋯,wn)=P(w1,⋯,wn∣c1)⋅P(c1)+P(w1,⋯,wn∣c2)⋅P(c2)
P
(
w
1
,
⋯
,
w
n
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
P\left ( w_1,\cdots ,w_n \right )=P\left ( w_1,\cdots ,w_n\mid c_1 \right )\cdot P\left ( c_1 \right )+P\left ( w_1,\cdots ,w_n\mid c_2\right )\cdot P\left ( c_2\right )
3.1、贝叶斯模型的训练
贝叶斯模型的训练过程实质上是在统计每一个特征出现的频次,其核心代码如下:
def train(self, data):
# data 中既包含正样本,也包含负样本
for d in data: # data中是list
# d[0]:分词的结果,list
# d[1]:正/负样本的标记
c = d[1]
if c not in self.d:
self.d[c] = AddOneProb() # 类的初始化
for word in d[0]: # 分词结果中的每一个词
self.d[c].add(word, 1)
# 返回的是正类和负类之和
self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys())) # 取得所有的d中的sum之和
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这使用到了AddOneProb类,AddOneProb类如下所示:
class AddOneProb(BaseProb):
def \_\_init\_\_(self):
self.d = {}
self.total = 0.0
self.none = 1 # 默认所有的none为1
# 这里如果value也等于1,则当key不存在时,累加的是2
def add(self, key, value):
self.total += value
# 不存在该key时,需新建key
if not self.exists(key):
self.d[key] = 1
self.total += 1
self.d[key] += value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意:
- none的默认值为1
- 当key不存在时,total和对应的d[key]累加的是1+value,这在后面预测时需要用到
AddOneProb类中的total表示的是正类或者负类中的所有值;train函数中的total表示的是正负类的total之和。
当统计好了训练样本中的total和每一个特征key的d[key]后,训练过程就构建完成了。
3.2、贝叶斯模型的预测
预测的过程使用到了上述的公式,即:
P(c1∣w1,⋯,wn)=P(w1,⋯,wn∣c1)⋅P(c1)P(w1,⋯,wn∣c1)⋅P(c1)+P(w1,⋯,wn∣c2)⋅P(c2)
P
(
c
1
∣
w
1
,
⋯
,
w
n
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
P\left ( c_1\mid w_1,\cdots ,w_n \right )=\frac{P\left ( w_1,\cdots , w_n\mid c_1 \right )\cdot P(c_1)}{P\left ( w_1,\cdots ,w_n\mid c_1 \right )\cdot P\left ( c_1 \right )+P\left ( w_1,\cdots ,w_n\mid c_2\right )\cdot P\left ( c_2\right )}
对上述的公式简化:
P(c1∣w1,⋯,wn)=P(w1,⋯,wn∣c1)⋅P(c1)P(w1,⋯,wn∣c1)⋅P(c1)+P(w1,⋯,wn∣c2)⋅P(c2)=11+P(w1,⋯,wn∣c2)⋅P(c2)P(w1,⋯,wn∣c1)⋅P(c1)=11+exp[log(P(w1,⋯,wn∣c2)⋅P(c2)P(w1,⋯,wn∣c1)⋅P(c1))]=11+exp[log(P(w1,⋯,wn∣c2)⋅P(c2))−log(P(w1,⋯,wn∣c1)⋅P(c1))]
P
(
c
1
∣
w
1
,
⋯
,
w
n
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
=
1
1
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
=
1
1
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
[外链图片转存中…(img-0GYLBisP-1715827426560)]
[外链图片转存中…(img-u0oJz1lP-1715827426560)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

