
热门标签
热门文章
- 1PyQt5快速开发与实战 3.2 布局管理入门 and 3.3 Qt Designer实战应用
- 213 个Python开发者必知的Python GUI库(1)_python 界面库
- 3【人工智能】数据分析与机器学习——泰坦尼克号(更新中)_机器学习实战泰坦尼克号
- 4CentOS yum安装redis_centos yum redis
- 5从three.js旋转动画,我了解了requestAnimationFrame_three.js requestanimationframe
- 6LVGL ArchLinux VSCode环境运行
- 7elementui 上传请求头_element-ui el-upload http-request自定义上传方法
- 8计算机Java项目|超市进销存管理系统_java超市管理系统
- 9前端技术岗,阿里 P7、百度 T6、腾讯 T3.1 的要求是怎样的?_t3前端啥水平
- 10tiup与prometheus迁移
当前位置: article > 正文
Hive SQL-DML-insert插入数据_hivesql insert
作者:正经夜光杯 | 2024-07-11 13:09:23
赞
踩
hivesql insert
Hive SQL-DML-insert插入数据


1. 插入静态数据
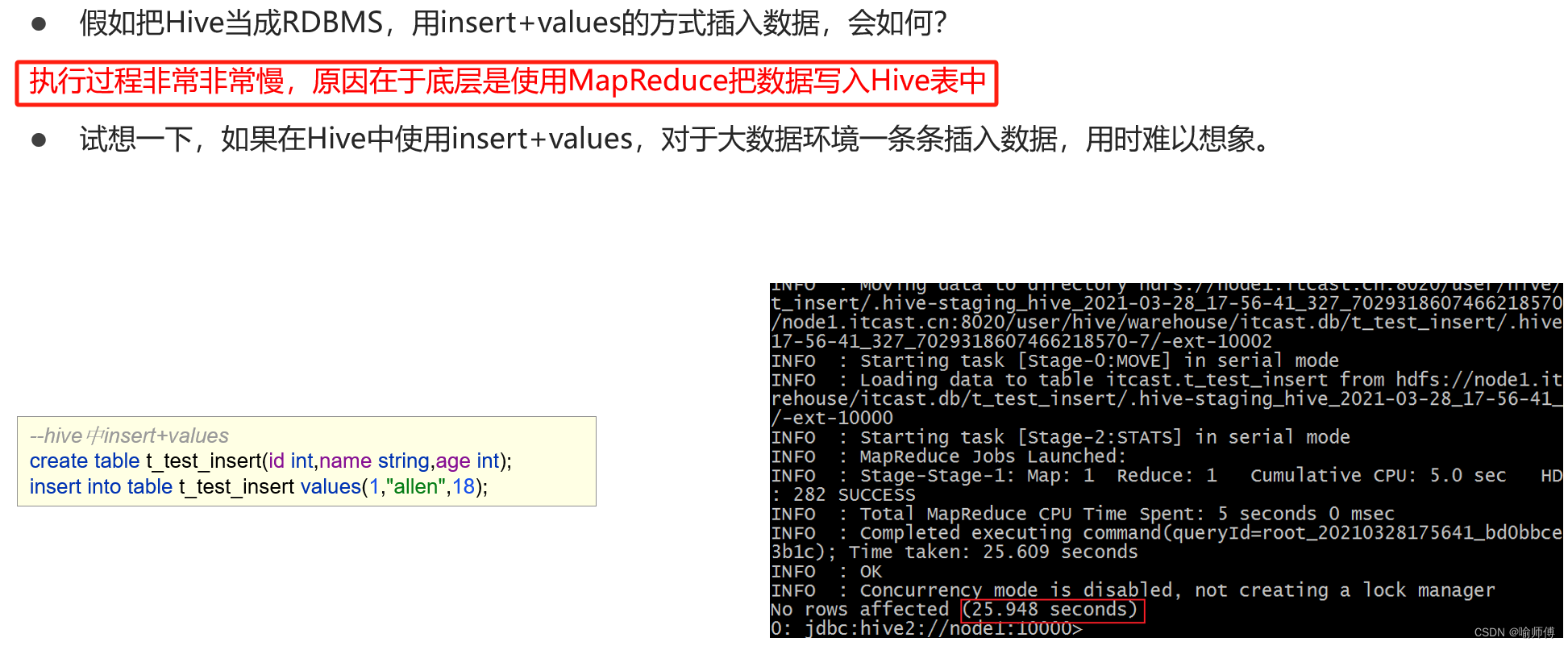
可以直接插入具体的值到Hive表中:
INSERT INTO TABLE tablename (column1, column2, column3)
VALUES (value1, value2, value3),
(value4, value5, value6),
...;
- 1
- 2
- 3
- 4
2. 插入查询结果

将一条查询的结果直接插入到另一个表中。这是一种很常见的操作,用于数据转移和转换:
INSERT INTO TABLE tablename
SELECT column1, column2, column3
FROM othertable
WHERE condition;
- 1
- 2
- 3
- 4
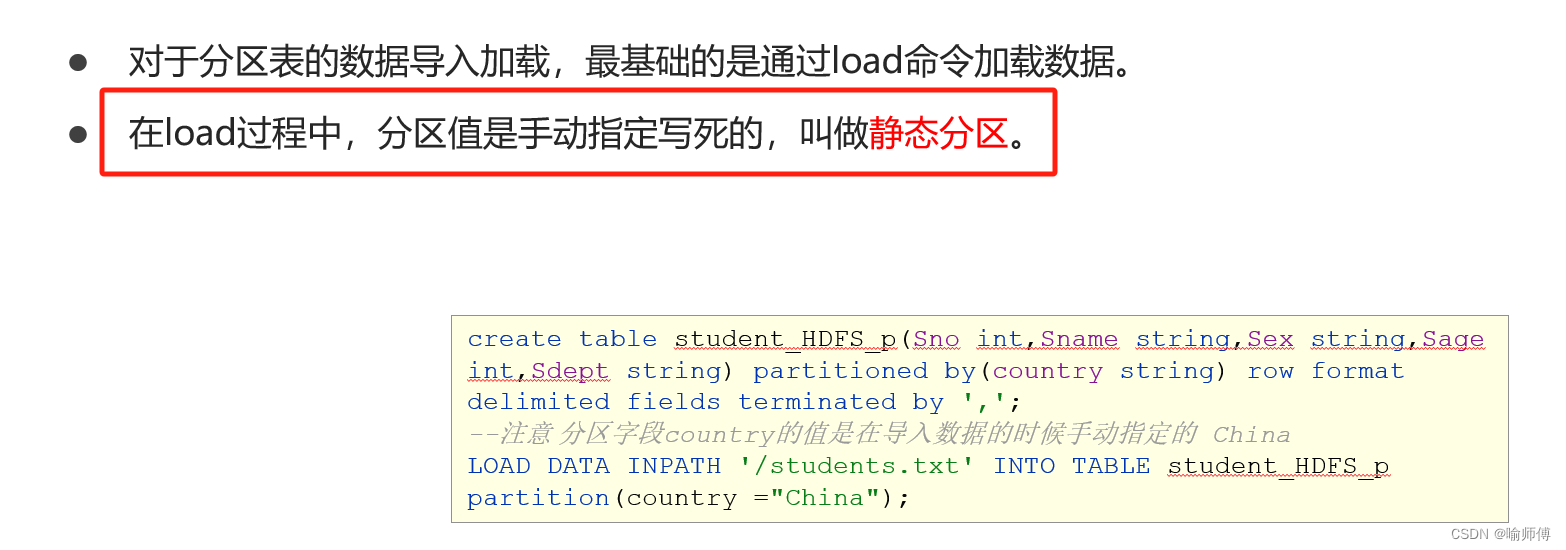
3. 多重插入和静态分区插入

对于分区表,可以在插入时指定分区。这不仅可以提高查询效率,而且还能更好地管理数据:
-- 插入到指定分区
INSERT INTO TABLE tablename PARTITION (partition_column='partition_value')
SELECT column1, column2, column3
FROM othertable
WHERE condition;
- 1
- 2
- 3
- 4
- 5
-- 插入不同分区的数据
FROM from_table
INSERT INTO TABLE tablename PARTITION (partition1)
SELECT column1, column2 WHERE condition1
INSERT INTO TABLE tablename PARTITION (partition2)
SELECT column1, column2 WHERE condition2;
- 1
- 2
- 3
- 4
- 5
- 6
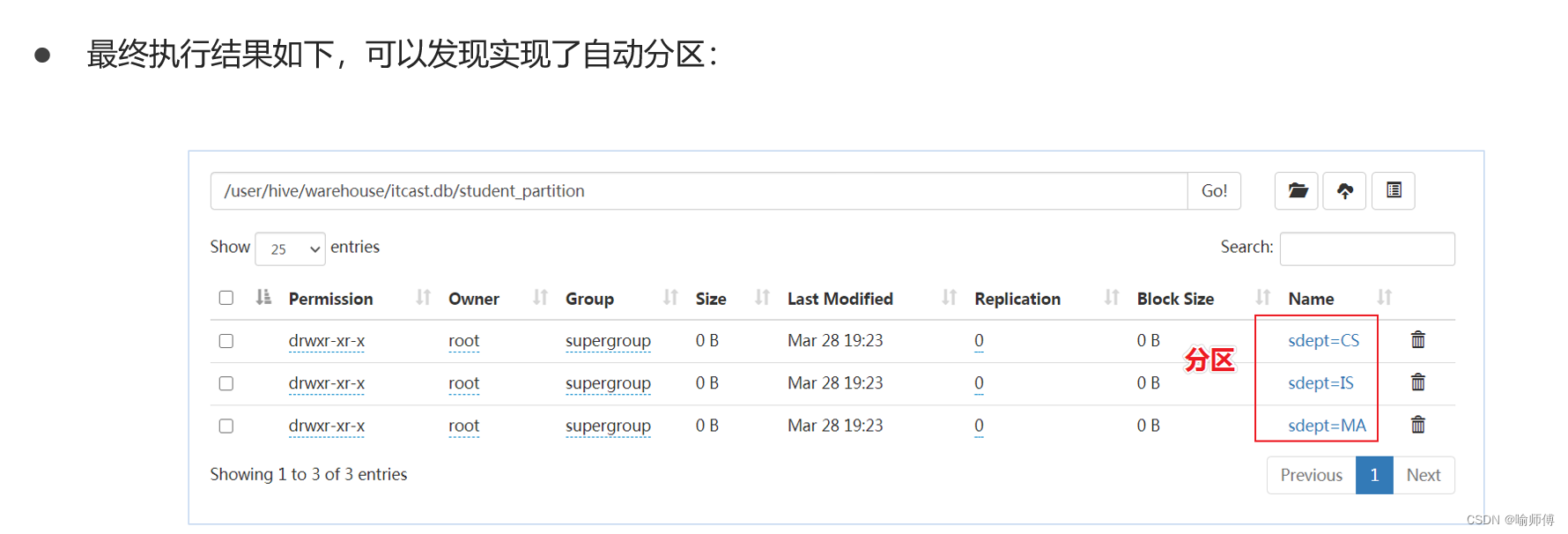
4. 动态分区插入



Hive还支持在执行INSERT操作时动态创建分区。这需要设置一些配置参数,如启用动态分区:

SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO TABLE tablename PARTITION (partition_column)
SELECT column1, column2, partition_column
FROM othertable;
- 1
- 2
- 3
- 4
- 5
- 6


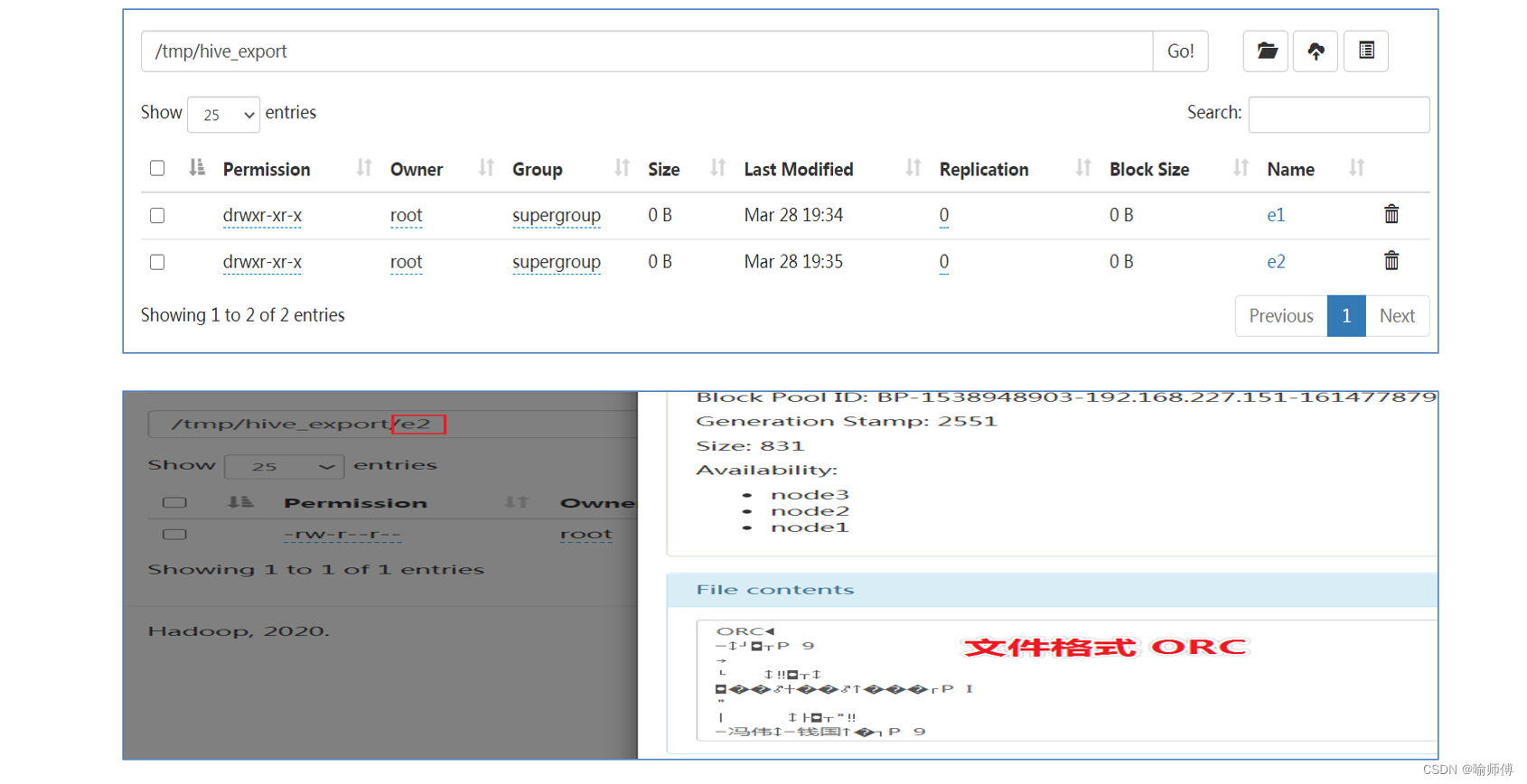
5.导出数据
导出数据是从 Hive 中提取数据的过程,通常用于将数据转移到本地文件系统、HDFS 或其他数据存储中。
INSERT OVERWRITE 用于将查询结果或表数据写入到特定的输出位置。可以将数据导出到 HDFS 或本地文件系统。这个方法支持多种文件格式,如 Text、Parquet、ORC 等。
-
导出到 HDFS:
INSERT OVERWRITE DIRECTORY '/path/to/hdfs/directory' SELECT * FROM my_table;- 1
- 2
-
导出到本地文件系统:
INSERT OVERWRITE LOCAL DIRECTORY '/path/to/local/directory' SELECT * FROM my_table;- 1
- 2
在这两个示例中,数据将被导出到指定的 HDFS 或本地路径。默认情况下,数据以文本格式输出,但可以通过 STORED AS 选项指定不同的文件格式。


示例:

6.注意事项
- Hive中的
INSERT操作本质上是对文件的写操作。特别是在HDFS中,这意味着每次INSERT都会生成新文件。这可能会影响性能,特别是在大量小批量插入时。 - 建议在执行大批量数据插入前调优Hive配置和考虑合适的文件格式和压缩机制。
- 在执行大数据量的插入时,需要注意Hive服务器和Hadoop集群的资源配置,以避免过载。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/810414
推荐阅读
相关标签

