
热门标签
热门文章
- 1微软Edge浏览器搜索引擎切换全攻略_微软默认浏览器怎么切换搜索引擎模式
- 2java中接收java.util.Date类型的参数,报错Can not deserialize value of type java.util.Date from String_cannot deserialize value of type `java.util.date`
- 3“打造智能售货机系统,基于ruoyi微服务版本开源项目“_自动售卖机 开源项目
- 4用Dify构建本地知识库(下)_dify 文档
- 5【群晖】NASTOOL-自动化处理影音视频工具
- 6linux 常用软件_linux常用软件
- 7Windows10(家庭版)中DockerDesktop(docker)的配置、安装、修改镜像源、使用_docker desktop
- 8Oracle修改当前序列的值(修改流水号从当前最大值开始)_oracle修改序列当前值
- 9【Flutter】Flutter 混合开发 ( 关联 Android 工程与 Flutter 工程 | 安卓页面中嵌入 Flutter 页面 | 安卓中启动 Flutter 页面 )_lanplay-flutter 安卓
- 10github 访问速度太慢怎么办_github 登录慢
当前位置: article > 正文
如何快速的将Excel定义的表结构变成MySQL的建表语句_excel mysql 建表
作者:正经夜光杯 | 2024-07-14 19:17:06
赞
踩
excel mysql 建表
如何快速的将Excel定义的表结构变成MySQL的建表语句
最近需求有点多啊,做一个小需求就有一堆表结构,一个一个实行CV大法,实在太伤身体了,有没有能够快速便捷的方法将一大堆Excel表转换成MySQL的表结构建表语句呢,网上张罗找了半天发现毛也没有,找到了也没有用,也就是换个地方CV而已,手敲键盘的数量依旧没有减少,怎么办?只能自己手敲一个工具了,将20张Excel定义的表转换成SQL建表语句了。
此处我的技术选型为python,别问为什么,问就是我只会python,其它的我啥也不会。
下面使在Excel中定义好的表结构,其中第一行最后一列tb_user为当前表结构的名称。
| 序号 | 字段名称 | 字段类型 | 描述 | 是否为空 | 索引类型 | tb_user |
|---|---|---|---|---|---|---|
| 1 | id | int | 主键 | NO | PRI | |
| 2 | username | varchar(20) | 用户名 | NO | ||
| 3 | password | varchar(20) | 密码 | NO | ||
| 4 | age | int | 年龄 | NO | ||
| 5 | gender | int | 性别:0-女 1-男 | NO | ||
| 6 | birthday | date | 生日 | NO | ||
| 7 | create_time | datetime | 创建时间 | NO | ||
| 8 | creator | varchar(20) | 创建人 | NO | ||
| 9 | update_time | datetime | 修改时间 | NO | ||
| 10 | updater | varchar(20) | 修改人 | NO | ||
| 11 | remark | datetime | 备注 | NO |
为了方便编程,我将这些表结构从Excel中复制到了CSV文件,新建一个user.csv文件,放到当前pycharm工程目录下,其中内容如下,在CV的时候,需要每个数据中间的空格替换成,。别问为什么,问就是方便我写的程序好识别。
序号,字段名称,字段类型,描述,是否为空,索引类型,tb_user
1,id,int,主键,NO,PRI
2,username,varchar(20),用户名,NO
3,password,varchar(20),密码,NO
4,age,int,年龄,NO
5,gender,int,性别:0-女 1-男,NO
6,birthday,date,生日,NO
7,create_time,datetime,创建时间 ,NO
8,creator,varchar(20),创建人,NO
9,update_time,datetime,修改时间,NO
10,updater,varchar(20),修改人,NO
11,remark,datetime,备注,NO
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
接下来就是将这个文件在程序中修改一下,将这个self.source_table_name=user修改一下就可以了,只要文件名,不要后缀。
import csv from datetime import datetime class CreateTable: def __init__(self): self.source_table_name = "user" self.csv_post_fix = '.csv' self.sql_post_fix = '.sql' self.table_name_prefix = 'create_' def read_csv_standard(self, file_path): data = [] with open(file_path, encoding="utf-8", mode='r') as file: reader = csv.reader(file) for row in reader: data.append(row) return data def handle(self, rows): tables = [] last_index = 0 for index, row in enumerate(rows): if len(row) == 0: table = rows[last_index:index] tables.append(table) last_index = index + 1 # print(table) elif index == (len(rows) - 1): table = rows[last_index:index] tables.append(table) last_index = index + 1 # print(table) return tables def create_table_sql(self, table_rows): table_sql = "" id_col_sql = "`{}` {} NOT NULL AUTO_INCREMENT COMMENT '{}'" str_col_sql = "`{}` {} DEFAULT NULL COMMENT '{}'" time_col_sql = "`{}` {} DEFAULT current_timestamp() COMMENT '{}'" update_time_col_sql = "`{}` {} DEFAULT current_timestamp() ON UPDATE current_timestamp() COMMENT '{}'" last_sql = '\tPRIMARY KEY (`id`) \n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;' for index, table_row in enumerate(table_rows): current_sql = "" # print(table_row) if index == 0: current_sql += "DROP TABLE IF EXISTS {};\n".format(table_row[-1]) current_sql += "CREATE TABLE `{}` (".format(table_row[-1]) table_sql += current_sql + "\n" continue if table_row[1] == 'id': current_sql = id_col_sql.format(table_row[1], table_row[2], table_row[3]) elif 'update_time' in table_row[1]: current_sql = update_time_col_sql.format(table_row[1], table_row[2], table_row[3]) elif 'time' in table_row[1]: current_sql = time_col_sql.format(table_row[1], table_row[2], table_row[3]) else: current_sql = str_col_sql.format(table_row[1], table_row[2], table_row[3]) table_sql += "\t" + current_sql + ",\n" table_sql += last_sql + "\n\n" return table_sql def do_work(self): date = str(datetime.now().strftime('%Y-%m-%d')) with open(self.table_name_prefix + self.source_table_name + "_" + date + self.csv_post_fix, "w", encoding="utf-8") as f: rows = self.read_csv_standard(self.source_table_name + self.csv_post_fix) tables = self.handle(rows) for table in tables: table_sql = self.create_table_sql(table) print(table_sql) f.write(table_sql) if __name__ == '__main__': createTable = CreateTable() createTable.do_work()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
整完了上面的步骤之后,就可以直接运行输出建表语句了,此时工程目录会多一个create_user_2024-05-30.csv文件,下面为建表语句。
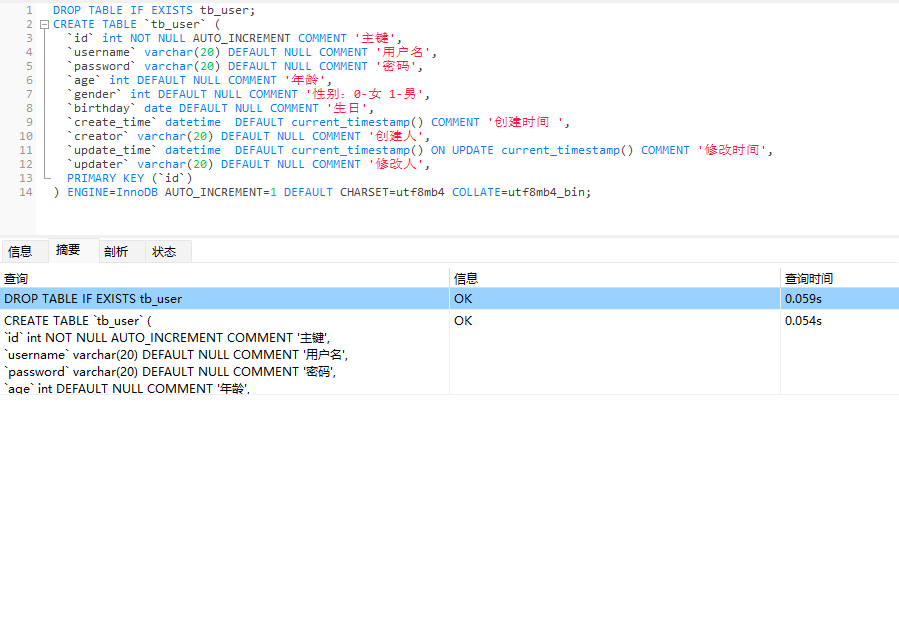
DROP TABLE IF EXISTS tb_user;
CREATE TABLE `tb_user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`username` varchar(20) DEFAULT NULL COMMENT '用户名',
`password` varchar(20) DEFAULT NULL COMMENT '密码',
`age` int DEFAULT NULL COMMENT '年龄',
`gender` int DEFAULT NULL COMMENT '性别:0-女 1-男',
`birthday` date DEFAULT NULL COMMENT '生日',
`create_time` datetime DEFAULT current_timestamp() COMMENT '创建时间 ',
`creator` varchar(20) DEFAULT NULL COMMENT '创建人',
`update_time` datetime DEFAULT current_timestamp() ON UPDATE current_timestamp() COMMENT '修改时间',
`updater` varchar(20) DEFAULT NULL COMMENT '修改人',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
将这个文件拖入到navicat中一键运行,不出问题的话麦克阿瑟表示非常nice!!!下面为运行结果
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

