
- 1【qml】Tab的用法_qml tab
- 2基于B/S的WEB应用体系结构_基于bs的web应用程序
- 3ffmpeg ffplay.c 源码分析
- 4连接HDMI闪黑屏_hdptx phy pll locked!
- 5《成功的资本》笔记_贫穷不仅是一种物质状态,更是一种精神状态、生活状态。
- 6如何优雅地利用C++编程实现1至20的乘积计算?——探索高效与简洁之美_c++利用代码完成1到20内所有整数的乘法求积运算,输出结果
- 7什么是PCB流锡槽焊盘/C型焊盘,如何设计?-捷配笔记
- 82024年鸿蒙HarmonyOS实战-ArkUI组件(Tabs)_harmonyos tabs(5),flutter跳转原生页面后,页面高度被拉伸_鸿蒙tab tabbar 高度
- 9面试官发难,如何用 SQL 来查询 Elasticsearch 中的数据?
- 10[Linux] linux系统安装git_linux安装git,Linux运维端简单易用的SPI框架_linux安装git命令
X2Paddle:手把手教你迁移代码——论文复现方法论_模型代码迁移后性能不好
赞
踩
使用飞桨复现论文的基本方法以及基本步骤。本文是飞桨论文复现打卡营第3期课程第二天《飞桨论文复现方法论》的笔记,以AlexNet为例进行复现。
一、通读论文
要想复现论文,首先需要看懂这篇论文做了什么,他的创新点是什么。
以AlexNet为例,其对应论文:《ImageNet Classification with Deep Convolutional Neural Networks》
通过阅读论文,可以知道AlexNet网络结构在整体上类似于LeNet,都是先卷积然后在全连接。但在细节上有很大不同。AlexNet更为复杂,有6000万个参数和65000个神经元,五层卷积,三层全连接网络,最终的输出层是1000通道的softmax。AlexNet利用了两块GPU进行计算,大大提高了运算效率,其架构如下图所示:

它的创新点主要有以下几点:
- 首次引入ReLU激活函数
- 之前都是tanh和sigmoid激活函数,收敛慢且效果不好,用ReLU可以保证很多权重梯度不消失,且计算量更少,效果更好
- 首次使用多个GPU并行训练
- 由于当时的GPU设备显存较小, AlexNet使用了两个GPU并行计算
- overlapping pooling
- 滑动窗口大于滑动步长,可以避免过拟合,进一步提升精度
- 使用Dropout
- 该技术可以减少神经元之间的相互依赖性。因此,模型被强制学习更加稳健的特征
二、原始代码解析
论文发表以后,论文作者一般都会在GitHub上开源自己的代码,我们可以先去看看论文作者的代码,并将其跑通。
以AlexNet为例,其用Pytorch实现的对应代码:https://github.com/littletomatodonkey/AlexNet-Prod/tree/master/AlexNet-torch,其核心是train.py这个文件。
!git clone https://gitee.com/AI-Mart/AlexNet-Prod.git
- 1
Cloning into 'AlexNet-Prod'...
remote: Enumerating objects: 62, done.[K
remote: Counting objects: 100% (62/62), done.[K
remote: Compressing objects: 100% (40/40), done.[K
remote: Total 62 (delta 20), reused 62 (delta 20), pack-reused 0[K
Unpacking objects: 100% (62/62), done.
Checking connectivity... done.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
!tree AlexNet-Prod/AlexNet-torch
- 1
AlexNet-Prod/AlexNet-torch ├── presets.py ├── torchvision │ ├── datasets │ │ ├── folder.py │ │ ├── __init__.py │ │ └── vision.py │ ├── _internally_replaced_utils.py │ ├── models │ │ ├── alexnet.py │ │ └── __init__.py │ └── transforms │ ├── autoaugment.py │ ├── functional_pil.py │ ├── functional.py │ ├── functional_tensor.py │ ├── __init__.py │ └── transforms.py ├── train.py ├── train.sh └── utils.py 4 directories, 16 files

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
directories, 16 files
原始代码中会定义一些数据加载的方式,以及数据预处理的代码,在跑之前需要根据作者提供的说明(README.md)来配置环境。
需要注意的是!!!
如果作者使用的是多卡训练,而你没有这么多显卡,那么你需要对你的超参数做相应的改变
举个例子:作者用8张卡去跑,batchsize是256,学习率是0.1;而你用单卡跑,batchsize一样的情况下你需要将学习率减小为原来的八分之一,即0.0125。
- 1
跑通原始代码后,我们的脑海里就有一定的概念了,这样方便我们确定需要转换的代码,需要转换的代码主要分为下面几个部分:
- 数据读取和数据预处理
- 模型组网
- 优化器和学习率
- 损失函数和评估指标
- 训练迭代
三、代码转换
这里将针对上面提到的转换代码进行详细介绍。
1.模型前向对齐
模型部分需要一些工具能够让你更方便地完成基础API的转换:

网络结构代码转换
根据API映射表做代码转换:

基础API除了一些命名上的差异外,其它地方基本上是保持一致的。
权重转换
代码全部转换完后,需要验证网络,不光要验证是否可以跑通,还需要验证网络的输出是否一致。
验证网络的输出是否一致可进行权重转换,流程如下:
- 准备Pytorch的权重,下载官方的权重或者手动存储一个权重。
- 寻找Pytorch代码中的各层的权重的名字,寻找方式可以直接通过代码来确定。
- 权重转换。
这里需要注意的是
Pytorch中的全连接层权重和paddle中的全连接层权重是互为转置的。因此代码中所有的nn.linear()涉及的权重都需要转置。
对应代码如下所示:
def transfer(): input_fp = "model.pth" output_fp = "model.pdparams" torch_dict = torch.load(input_fp) print(torch_dict) paddle_dict = {} fc_names = [ "classifier.1.weight", "classifier.4.weight", "classifier.6.weight" ] for key in torch_dict: weight = torch_dict[key].cpu().detach().numpy() flag = [i in key for i in fc_names] if any(flag): print("weight {} need to be trans".format(key)) weight = weight.transpose() paddle_dict[key] = weight paddle.save(paddle_dict, output_fp)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
验证模型正确性
生成tensor验证模型前向传播的正确性,检查输出结果是否一致可使用如下代码:
assert np.allclose(out_torch, out_paddle, atol = 1e-5)
- 1
具体验证代码如下所示:
model_torch = alexnet_torch() model_paddle = alexnet_paddle() model_torch.eval() model_paddle.eval() torch_checkpoint = torch.load('model.pth') model_torch.load_state_dict(torch_checkpoint) paddle_checkpoint = paddle.load('model.pdparams') model_paddle.set_state_dict(paddle_checkpoint) x = np.random.randn(1, 3, 224, 224) input_torch = torch.tensor(x, dtype=torch.float32) out_torch = model_torch(input_torch) input_paddle = paddle.to_tensor(x, dtype='float32') out_paddle = model_paddle(input_paddle) print('paddle result:\n{}'.format(out_paddle[0][:5])) print('torch result:\n{}'.format(out_torch[0][:5]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出结果如下:

可以明显地看出来输出是基本一致的。
2.数据IO转写
数据处理这部分,对于不涉及Pytorch与Paddle转换的代码部分,可以直接复用。
对于数据集定义,也只是API有一些变化,但基本都是差不多的,简单改一改就能使用。

3.优化器与学习率
在Pytorch与Paddle中,学习率与优化器的设置顺序正好是相反的。

- 在Paddle中,先设置学习率,然后将学习率传入优化器中;
- 而在Pytorch中,先设置优化器,然后再把优化器传给学习率
四、训练对齐
训练对齐的一般步骤如下:
- 固定随机因素,保证Paddle和torch的读入数据,模型权重,学习策略,超参数一致。训练几次后,对比Paddle和torch的训练loss是否一致。若不-致,打印中间参数与梯度,输出并对比差异,定位差异点,并分析问题所在。
- 用相同数据集,学习策略,超参数分别训练Paddle和torch模型,对比训练log与可视化效果是否一致。
如下图所示,验证训练时的训练集的准确性与loss:
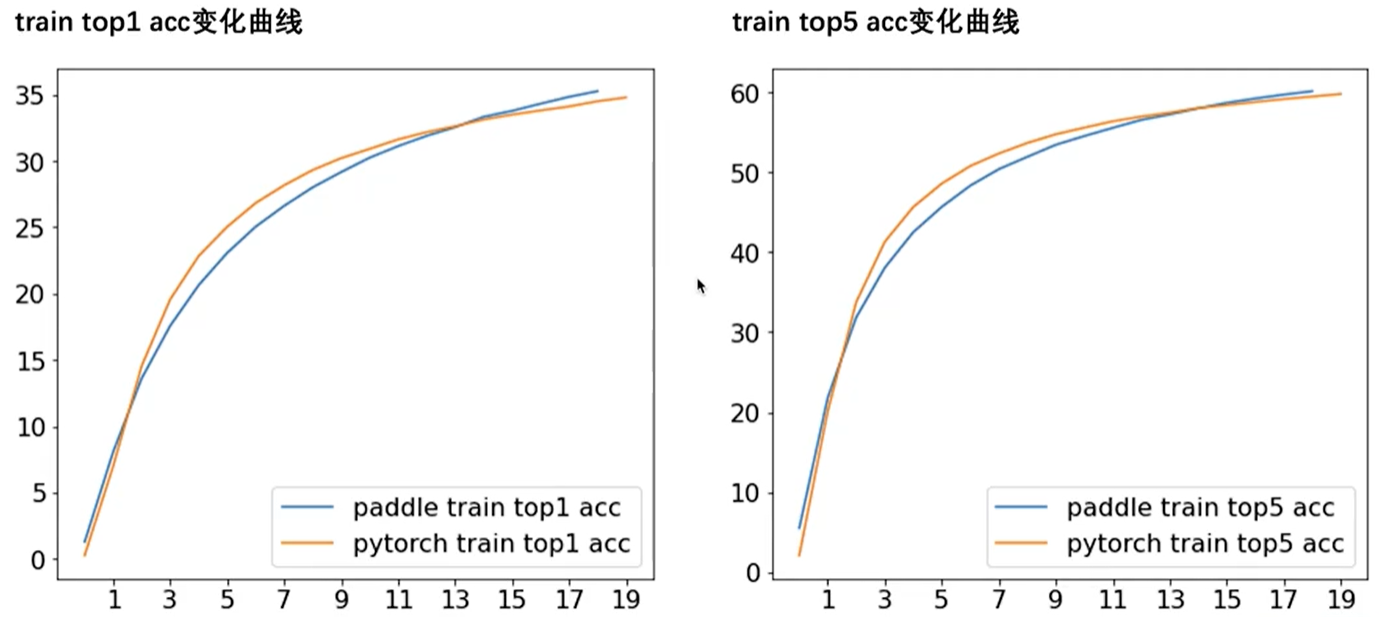
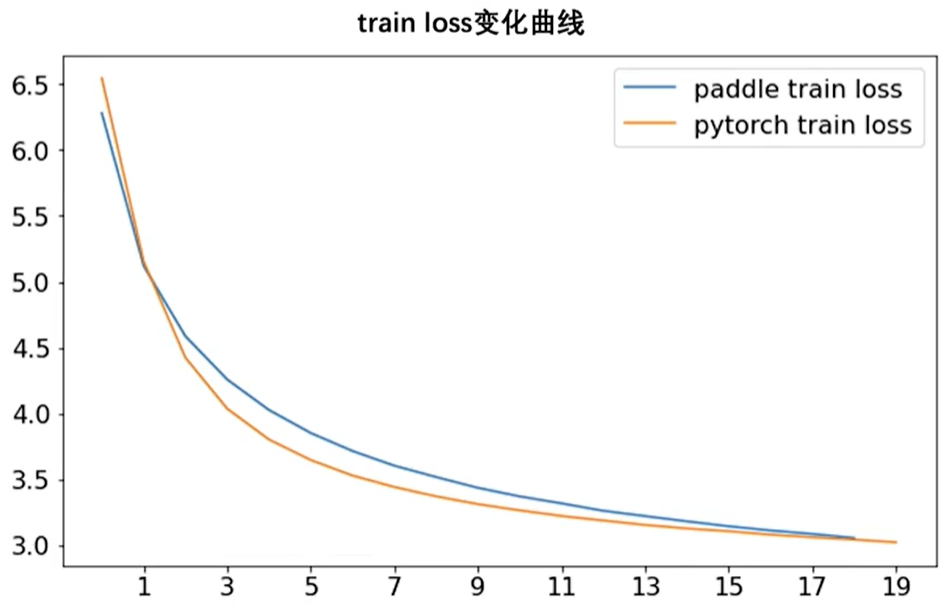
最后模型在验证集上也能有较好的效果,并且性能差异不大:

五、排查问题
在真正复现的过程中,多多少少都有可能会遇到一些问题,这时候我们可以进一步仔细检查前面的步骤,包括:
- 数据:预处理、后处理
- 模型:模型结构、dropout等训练预测行为不一 致的api
- 优化器:学习率、优化器选择
- 训练超参数:batch size、weight decay等
如果相差还是很大,可以使用Pytorch随机初始化一个模型,保存,然后转化为Paddle,再使用Paddle加载,二者使用完全相同的假数据进行训练,看下loss的变化情况
另外,排查的时候,建议先基于单卡排查,基本没问题之后使用多卡进行训练
六、基于X2Paddle快速实现代码转换
X2Paddle支持将PyTorch代码及预训练模型转换为PaddlePaddle代码及预训练模型。在使用前请先安装X2Paddle:
pip install x2paddle
- 1
具体使用方法如下:
第一步:转换前代码预处理
由于部分PyTorch操作是目前PaddlePaddle暂不支持的操作(例如:不支持TensorBoard、自动下载模型等),因此我们需要手动将这部分操作去除或者修改。
-
去除TensorBoard相关的操作。
-
将PyTorch中Tensor逐位逻辑与、或、异或运算操作符替换为对应的API的操作:
| 替换为 torch.bitwise_or
& 替换为 torch.bitwise_and
^ 替换为 torch.bitwise_xor
# 原始代码:
pos_mask | neg_mask
# 替换后代码
torch.bitwise_or(pos_mask, neg_mask)
- 1
- 2
- 3
- 4
- 若自定义的
DataSet(用于加载数据模块,作为torch.utils.data.DataLoader的参数)未继承torch.utils.data.Dataset,则需要添加该继承关系。
# 原始代码
class VocDataset:
# 替换后代码
import torch
class VocDataset(torch.utils.data.Dataset):
- 1
- 2
- 3
- 4
- 5
-
若预训练模型需要下载,去除下载预训练模型相关代码,在转换前将预训练模型下载至本地,并修改加载预训练模型参数相关代码的路径为预训练模型本地保存路径。
-
若在数据预处理中出现Tensor与float型/int型对比大小,则需要将float型/int型修改为Tensor,例如下面代码为一段未数据预处理中一段代码,修改如下:
# 原始代码:
mask = best_target_per_prior < 0.5
# 替换后代码
threshold_tensor = torch.full_like(best_target_per_prior, 0.5)
mask = best_target_per_prior < threshold_tensor
- 1
- 2
- 3
- 4
- 5
第二步:转换
x2paddle --convert_torch_project --project_dir=torch_project --save_dir=paddle_project --pretrain_model=model.pth
- 1
| 参数 | 作用 |
|---|---|
| –convert_torch_project | 当前方式为对PyTorch Project进行转换 |
| –project_dir | PyTorch的项目路径 |
| –save_dir | 指定转换后项目的保存路径 |
| –pretrain_model | **[可选]**需要转换的预训练模型的路径(文件后缀名为“.pth”、“.pt”、“.ckpt”)或者包含预训练模型的文件夹路径,转换后的模型将将保在当前路径,后缀名为“.pdiparams” |
第三步:转换后代码后处理
PaddlePaddle在使用上有部分限制(例如:自定义Dataset必须继承自paddle.io.Dataset、部分情况下DataLoader的num_worker只能为0等),用户需要手动修改代码,使代码运行。
-
若需要使用GPU,且预处理中使用了Tensor,
x2paddle.torch2paddle.DataLoader中的num_workers必须设置为0。 -
修改自定义Dataset(继承自
paddle.io.Dataset)中的__getitem__的返回值,若返回值中存在Tensor,需添加相应代码将Tensor修改为numpy。
# 原始代码 class VocDataset(paddle.io.Dataset): ... def __getitem__(self): ... return out1, out2 ... # 替换后代码 class VocDataset(paddle.io.Dataset): ... def __getitem__(self): ... if isinstance(out1, paddle.Tensor): out1 = out1.numpy() if isinstance(out2, paddle.Tensor): out2 = out2.numpy() return out1, out2 ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 若存在Tensor对比操作(包含==、!=、<、<=、>、>=操作符),在对比操作符前添加对Tensor类型的判断,如果为非bool型强转为bool型,并在对比后转换回bool型。
# 原始代码(其中c_trg是非bool型的Tensor)
c_trg = c_trg == 0
# 替换后代码
c_trg = c_trg.cast("int32")
c_trg_tmp = paddle.zeros_like(c_trg)
paddle.assign(c_trg, c_trg_tmp)
c_trg_tmp = c_trg_tmp.cast("bool")
c_trg_tmp[:, i] = c_trg[:, i] == 0
c_trg = c_trg_tmp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 如若转换后的运行代码的入口为sh脚本文件,且其中有预训练模型路径,应将其中的预训练模型的路径字符串中的“.pth”、“.pt”、“.ckpt”替换为“.pdiparams”。
七、总结与升华
论文复现最最关键的一点主要还是先把论文读懂,然后把作者给的代码跑通,了解了基本思想后,再去做复现才会比较简单,否则直接上手转换代码可能会非常吃力。
最后,如果你想快速转换训练代码,也可以尝试使用X2Paddle这一套件,他能极大地减少你的工作量,感兴趣的开发者们快来试一试吧~
作者简介
北京联合大学 机器人学院 自动化专业 2018级 本科生 郑博培
中国科学院自动化研究所复杂系统管理与控制国家重点实验室实习生
百度飞桨开发者技术专家 PPDE
百度飞桨官方帮帮团、答疑团成员
深圳柴火创客空间 认证会员
百度大脑 智能对话训练师
阿里云人工智能、DevOps助理工程师
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378


