
- 12年功能测试月薪9.5K,100多天自学自动化,跳槽涨薪4k后我的路还很长..._功能测试干两年跳槽,薪资待遇
- 2趋动VAICP技术认证全球考试正式上线
- 3Java学习笔记21——使用JDBC访问MySQL数据库_java mysql 访问
- 4测试工具Hercules_hercules setup utility
- 5GitHub入门教程_如何将文件添加到版本库
- 6Leetcode Top100题目和答案(面试必备)_leetcode题库
- 7java springboot 生成pdf 的方式有哪些_springboot生成pdf
- 8KGQA知识图谱问答资料整理(持续更新...)
- 9RocketMQ 死信消息_rocketmq如何消费异常写入死信队列
- 10kali系统卸载Docker容器_kali卸载docker
ICWS 2024 _ 基于生成长度预测的大语言模型推理请求调度
赞
踩
随着技术的快速迭代,大语言模型(Larage Langugage Model, LLM )在各种场景下都展示出强大的文本处理能力,越来越多的业务期待通过接入大模型服务,提升业务效果。区别于传统RPC请求服务时间相近,大模型请求服务时间受输出长度影响差异明显,同时每个请求所需的推理资源以及推理时间都无法事先感知,导致传统请求调度方案面临以下两个问题:(1) 当一个批次中请求的生成长度不同时,生成长度较短的请求需要等待生成长度较长的请求完成后才能一起返回,造成了计算浪费,影响了推理速度。(2)由于具有较长的生成长度的请求会产生更多的键值缓存,会占用更多的 GPU 显存。在不知道请求生成长度的情况下,静态批处理总是使用一个较小的批次规模(Batch Size)来避免显存溢出(Out of Memory, OOM)错误,无法充分利用GPU的计算能力。
本文尝试从请求调度的的角度提高 LLM 的推理性能,提出面向 LLM 推理的请求调度系统Magnus 。它通过对请求的生成长度进行预测,将生成长度相似的请求放在同一个批次(Batch)中进行处理,来降低计算浪费并增大批次规模,从而降低请求响应时间并提高大模型推理的吞吐量。实验表明,Magnus 可以将响应时间降低 89.7%,请求吞吐量提高 234%。在这项工作中,我们显著提高了静态批处理(Static Batching)的吞吐量,在未来,我们将进一步探索基于生成长度预测的请求调度方案在持续批处理(Continuous Batching)中的应用。
该工作目前已经被服务计算领域会议 IEEE International Conference on Web Services (ICWS) 录用,技术细节可以查看预印版: https://arxiv.org/abs/2406.04785

研究背景

随着参数规模的增加,基于 transformer 的语言模型在各种自然语言处理(NLP)任务上都表现出强大的能力,这可以使许多应用程序受益。然而,由于成本过高,大多数应用程序开发人员无法负担训练和部署 LLM 的高昂费用。因此,诸如 OpenAI、谷歌和阿里巴巴等人工智能领域的科技公司将他们的 LLM 作为服务发布,并允许开发人员通过 API 访问,即语言模型即服务(Language Mode as a Service, LMaaS)。
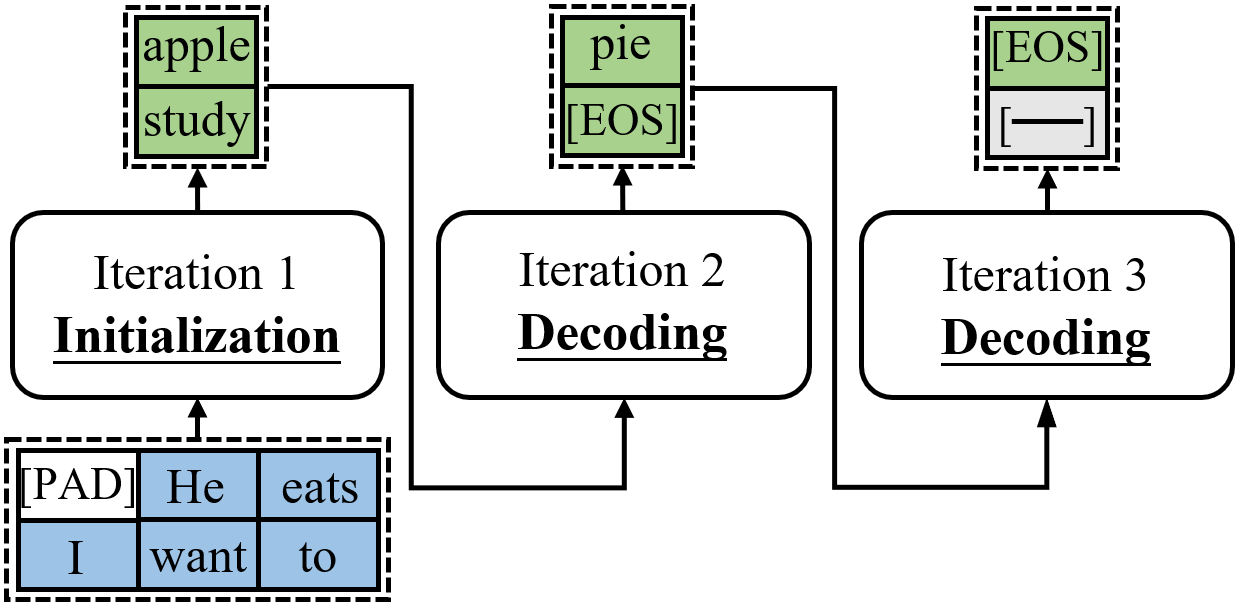
如图 1 所示,在 LMaaS 场景中,应用程序将用户输入的文本附上指令作为请求,发送给 LLM 进行处理。例如,VSCode上的代码助手插件可以通过在用户的代码前加上指令“Fix bugs in the following code:”作为请求发送给 LLM 服务从而实现程序漏洞修复功能。在服务端,来自不同应用程序的提示被混合在一起然后分批,并由部署在图形处理器(Graphics Processing Unit, GPU)等加速硬件上的 LLM 实例进行批处理。
由于 LMaaS 场景中的应用,如机器翻译和程序修复,更多地关注生成质量而不是多样性。因此,通常采用贪婪采样和波束搜索(Beam Search)[1]。考虑到波束搜索的计算开销很大, LLM 往往采用贪婪采样方式生成文本,因此相同的请求的生成结果总是相同的。
现有的深度神经网络推理系统,如Tensorflow serving [2] 和Triton Inference Server [3] 利用先到先服务的方式以固定的批次规模处理请求,在本文中我们将这种调度策略称为朴素调度(Vanilla Scheduling),当使用静态批处理(如图2所示)时,朴素调度会导致两个严重影响批处理效率的问题。首先,当一个批次中请求的生成长度不同时,生成长度较短的请求需要等待生成长度较长的请求完成后才能一起返回,造成了计算浪费,影响了推理速度。其次,由于具有较长的生成长度的请求会产生更多的键值缓存,会占用更多的 GPU 显存。在不知道请求生成长度的情况下,静态批处理总是使用一个较小的批次规模来避免显存溢出 (Out of Memory, OOM)错误。因此,GPU 强大的并行计算能力无法得到充分利用,降低了系统总体吞吐量。
研究动机
很多应用的请求生成长度和用户输入呈现强正相关性

我们发现在 LMaaS 场景下,有许多流行应用,其请求生成长度与原始用户输入文本长度呈正相关。例如机器翻译(Machine Translation, MT)、语法纠错(Grammar Correction, GC)、文本去毒(Text Detoxification, TD)、代码翻译(Code Translation, CT)、漏洞修复(Bug Fixing, BF)和代码注释(Code Comment, CC)。为了证实这一结论,我们从现有数据集中为每个应用构造了 2000 个请求,并将这些请求使用 ChatGLM-6B[4]、Qwen-7B-Chat[5] 和 Baichuan2-7B-Chat[6] 三个 LLM 进行处理。我们将请求生成长度和用户输入长度进行可视化展示(如图 3)。可以发现,在这些应用中用户输入文本的长度与生成文本的长度具有显著的正相关性。

表I中展示了用户输入长度和请求生成长度的皮尔逊系数。从中我们可以看出,对于三种大型语言模型 ChatGLM-6B, Qwen-7B-Chat 和 Baichuan2-7B-Chat,大多数应用请求的用户输入长度和请求输出长度的皮尔逊系数都大于0.8,表明存在强烈的正相关性。因此,对于这些应用,用户输入长度可以极大地帮助预测请求的生成长度。
生成长度预测可以显著提高 LLM 推理性能
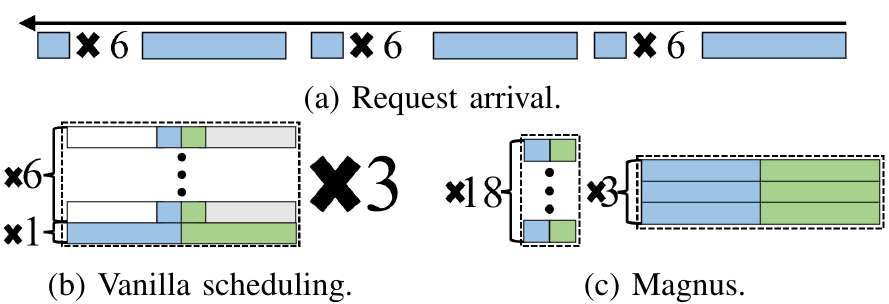
图4:朴素调度 vs. 基于生成长度预测的调度方案Magnus
为了初步验证基于长度预测方案的可行性,我们在 NVIDIA V100 32GB GPU 上部署了一个 ChatGLM-6B LLM 实例进行实验。在实验中,请求长度和生成长度均为 1000 左右的 "大 "请求和请求长度和生成长度均为 10 左右的 "小 "请求按 图 4(a) 所示的顺序到达。在实验中,我们利用 huggingface-transformers 作为推理引擎来加载和运行 LLM 。如图 4(b)所示,朴素调度按照达到的顺序对请求进行批处理,批次规模固定为 7,总处理时间为 242 秒。然而,基于生成长度预测的调度方案 Magnus ,将小请求和大请求分别分为两个批次。由于小请求占用的显存少,因此可以使用更大的批次规模,从而充分发挥 GPU 的计算能力。如图 4(c) 所示,大请求和小请求的批次规模分别为 18 和 3,总处理仅仅时间为 60s,大大优于朴素调度。这说明生成长度预测可以显著提高 LLM 推理性能。
系统设计
基于上述的初步数据分析和实验探索,我们提出了一种基于生成长度预测的请求调度系统。Magnus 包含四个核心组件:(1)请求生成长度预测器;(2)适应性批次组装器根据请求长度预测的结果将请求分为不同批次;(3)批处理时间估计器(4)最高响应比优先批调度器根据估计的批处理时间为多个批次确定处理顺序。通过这四个核心组件相互配合,Magnus 可以提升 LLM 批处理的请求吞吐量,并降低请求的响应时延。
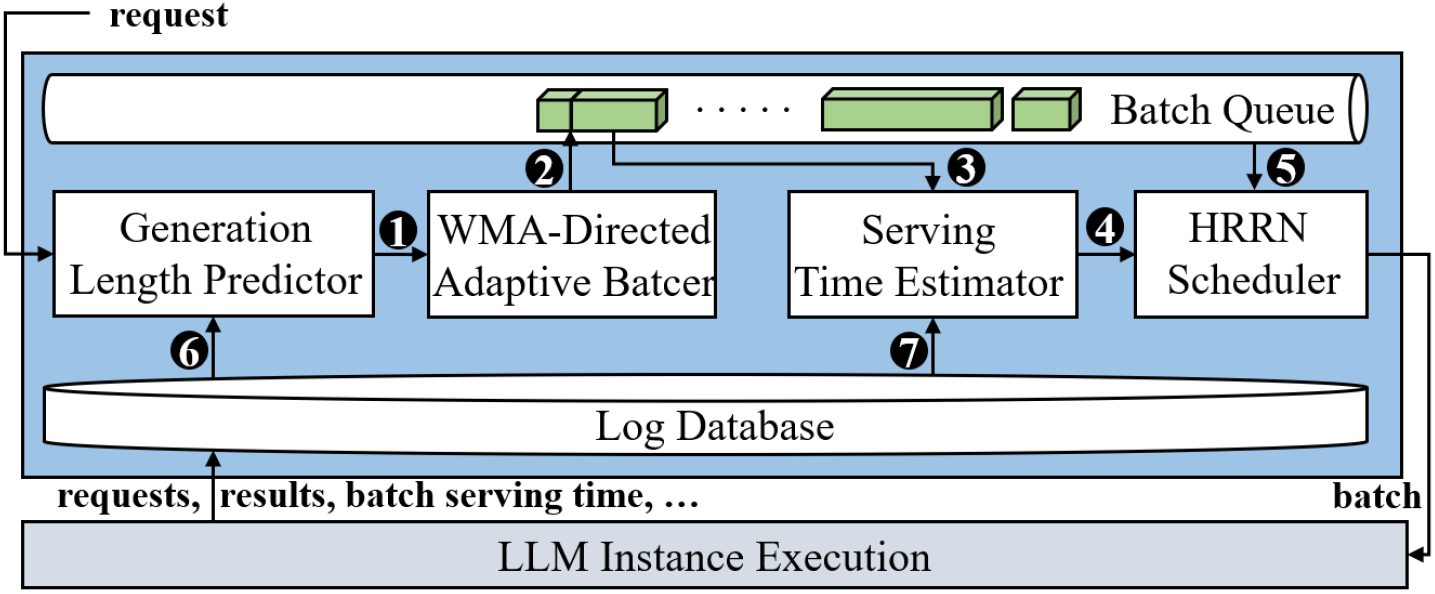
Magnus 的工作流程如图5所示。当请求到达时,生成长度预测器预测它的生成长度,并将①请求及其预测结果发送给适应性批次组装器,适应性批次组装器将②该请求插入到具有相似长度和生成长度的批次中,以减少计算浪费。之后,批处理时间估计器将根据③批次的批次规模,长度、预测的生成长度来预测其推理时间。当一个 LLM 实例完成处理,变得空闲时,批次调度器将使用最高响应比优先算法,根据④估计的批处理时间从队列中选择一个⑤批次调度到 LLM 实例进行处理。除此之外,Magnus 周期性地利用新收集的⑥请求信息(如请求及其实际生成长度),以及从日志数据库中收集的⑦批次信息(如批次规模、批次中请求的长度、批次中请求的生成长度,和批处理时间),通过持续学习技术来不断提高生成长度预测器和批处理时间估计器的精度。接下来,我们针对每个核心组件详细介绍对应的设计细节。
生成长度预测器
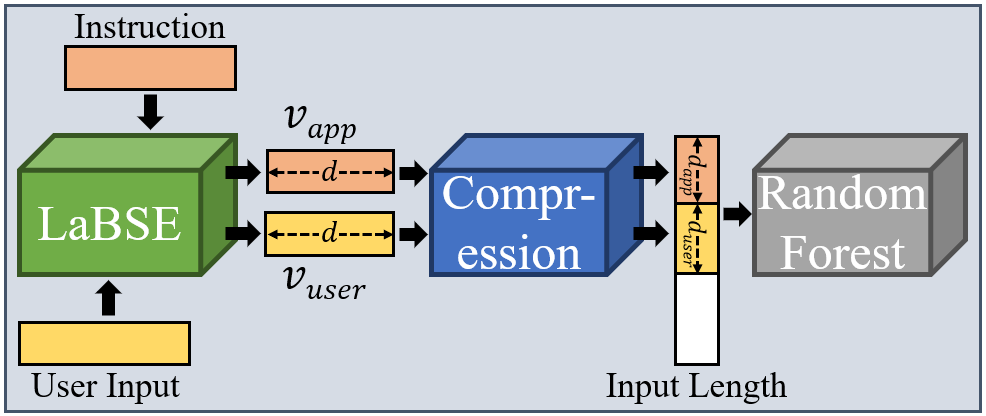
生成长度预测器由一个基于 LaBSE [7] 的语义特征提取模块、一个压缩模块和一个随机森林回归器组成。图6展示了生成长度预测器的架构图,首先,语义特征提取模块将用户输入和指令作为输入,分别提取用户级和应用级语义特征,并生成两个嵌入向量
v
u
s
e
r
,
v
a
p
p
∈
R
d
v_{user}, v_{app}\in \mathbb{R}^{d}
vuser,vapp∈Rd,其中
d
=
768
d=768
d=768。其中应用级别的语义特征用于帮助回归器识别不同应用任务,从而为每个任务学习请求输入和输出的相关性。除此之外,由于语义相似的请求往往有相似的输出,因此具有相似的生成长度,我们利用用户级的语义特征来帮助回归器利用用户请求的语义相似性来提高预测精度。为了控制回归器的复杂性,压缩模块将
v
u
s
e
r
v_{user}
vuser和
v
a
p
p
v_{app}
vapp通过分组压缩的方式进行压缩,首先将它们平均分为
d
u
s
e
r
d_{user}
duser和
d
a
p
p
d_{app}
dapp组,其中每组的维度大小为
d
d
a
p
p
\frac{d}{d_{app}}
dappd 和
d
d
u
s
e
r
\frac{d}{d_{user}}
duserd,通过对组内值求和,就将每个组压缩为一个值。然后,为了保障数值稳定性,每个压缩后的值需要除以组大小的平方根。最后,将压缩后的嵌入向量与用户输入长度连接起来,输入到随机森林回归器来预测生成长度。其中
d
u
s
e
r
d_{user}
duser和
d
a
p
p
d_{app}
dapp分别设置为 16 和 4。
适应性批次组装器

适应性批次组装器根据排队批次中请求的长度和预测的生成长度向批次中插入请求,目的是减少批推理期间的计算浪费。 由于 LLM 批推理的主要开销来自 GPU 显存访问,因此我们提出浪费的显存访问 (Wasted Memory Access, WMA) 来建模批推理期间的计算浪费,该指标主要度量读取对生成的结果没有任何贡献的token的键值缓存的次数。 给定一个批次 B \mathcal{B} B,其长度定义为 L ( B ) = max p ∈ B L ( p ) L(\mathcal{B}) = \max_{p\in \mathcal{B}} L(p) L(B)=maxp∈BL(p),其生成长度定义为 G ( B ) = max p ∈ B G ( p ) G(\mathcal{B}) = \max_{p\in \mathcal{B}} G(p) G(B)=maxp∈BG(p),其中 L ( p ) L(p) L(p)和 G ( p ) G(p) G(p)分别表示表示请求 p p p的长度和生成长度。图7给出了不同变量对应的含义。
对于提示 p ∈ B p\in \mathcal{B} p∈B,它的填充符数量是 L ( B ) − L ( p ) L(\mathcal{B})-L(p) L(B)−L(p)。在每次迭代中这些填充符的键值缓存都被读取并参与计算,但它们对生成的结果没有任何贡献。因此,这些显存访问都被浪费了。在生成"[EOS]" token之前,这些填充符的键值缓存总共被读取 G ( p ) G(p) G(p)次,因此这个过程中的 WMA 可以由 W M A g e n ( p ) = G ( p ) ∗ ( L ( B ) − L ( p ) ) WMA_{gen}(p) = G(p) * (L(\mathcal{B})-L(p)) WMAgen(p)=G(p)∗(L(B)−L(p))来计算。
此外,在 “[EOS]” token 生成后,
p
p
p进入等待阶段,在此阶段中,填充后的请求和所有之前生成的token的键值缓存都会被读取并参与计算,并在每次迭代中缓存新生成的键值张量。由于在等待阶段生成的token在最终的生成结果中会被忽略,因此这些显存访问也会被浪费,从而导致
W
M
A
w
a
i
t
(
p
)
=
∑
g
=
G
(
p
)
G
(
B
)
(
g
+
L
(
B
)
)
WMA_{wait}(p)=\sum\limits_{g=G(p)}^{G(\mathcal{B})}(g + L(\mathcal{B}))
WMAwait(p)=g=G(p)∑G(B)(g+L(B))。
我们将批次
B
\mathcal{B}
B的 WMA 定义为其所有请求中的最大 WMA,表示为
W
M
A
(
B
)
=
max
p
∈
B
(
W
M
A
g
e
n
(
p
)
+
W
M
A
w
a
i
t
(
p
)
)
WMA(\mathcal{B})=\max\limits_{p\in\mathcal{B}} (WMA_{gen}(p) + WMA_{wait}(p))
WMA(B)=p∈Bmax(WMAgen(p)+WMAwait(p))。当适应性批次组装器收到请求
p
p
p时,它在等待队列中迭代各个批次,用预测的生成长度
G
′
(
p
)
G'(p)
G′(p)替换
G
(
p
)
G(p)
G(p),计算在插入
p
p
p后每个批次的WMA,并记录最小的WMA
ϕ
\phi
ϕ以及相应的批
B
ϕ
\mathcal{B}_{\phi}
Bϕ。为了减少批处理期间的计算浪费,如果
ϕ
\phi
ϕ小于给定阈值
Φ
\Phi
Φ,则将请求插入到
B
ϕ
\mathcal{B}_{\phi}
Bϕ,否则,使用这个请求创建一个新的批次并插入到等待队列中。 由于键值缓存会在批处理过程中消耗大量显存,因此防止批次大小过大以避免OOM错误非常重要。对于批次
B
\mathcal{B}
B,键值缓存消耗的显存由
M
E
M
(
B
)
=
β
⋅
(
L
(
B
)
+
G
(
B
)
)
⋅
Δ
MEM(\mathcal{B})=\beta\cdot (L(\mathcal{B}) + G(\mathcal{B})) \cdot \Delta
MEM(B)=β⋅(L(B)+G(B))⋅Δ 计算,其中
β
\beta
β是
B
\mathcal{B}
B的批次规模,
Δ
\Delta
Δ表示单个token的键张量和值张量的显存占用。根据
B
\mathcal{B}
B中预测的请求生成长度,可以在批处理之前就估计出
B
\mathcal{B}
B的显存消耗。 如果批次组装器发现,在将
q
q
q插入
B
\mathcal{B}
B后,批处理
B
\mathcal{B}
B的显存使用超过可用显存大小
Θ
\Theta
Θ,则它认为插入后的WMA是无限的,从而防止
p
p
p被插入
B
\mathcal{B}
B。 因此,长度和生成长度较小的批次可以具有较大的批次规模,以充分利用gpu强大的并行计算能力,而长度和生成长度较大的批次可以具有适当的批次大小,以尽可能地利用GPU,同时避免显存溢出。总体而言,我们在以下算法中报告了基于WMA的自适应批次组装算法的伪代码。

为了适应用户输入的变化,生成长度预测器通过持续学习持续提高精度。每隔 3 分钟,Magnus 就会收集预测误差大于 10 个 token 且超过实际请求生成长度 10%的请求的日志数据,把这些数据补充到训练集中,并重新训练随机森林回归器。该持续学习过程与在线预测是异步的,不会影响预测效率。
批处理时间估计器
当一个 LLM 实例空闲时,服务时间估算器会估算出队列中等待的批次的批处理时间,这样最高响应比优先(Highest Response Ratio Next, HRRN)批次调度器就可以利用估算结果来确定批次的执行顺序,从而缩短请求响应时间。由于请求长度、生成长度和批次规模相似的批次具有相似的迭代次数以及每次迭代中相似的显存访问和计算量,因此具有相似的批处理时间。基于这个事实,批处理时间估计器采用KNN回归模型,以批次规模、批次长度和生成长度作为特征输入,为每个批次请求估计处理时间。需要注意的是,在估计时,每个批次请求的生成长度为该批次请求里最大的预测生成长度。
与生成长度预测器类似,批处理时间估算器也通过持续学习不断提高精度。 每隔 2 分钟,Magnus 就会收集新处理完的批次的日志数据,并根据实际生成长度重新估计其批处理时间。预测误差大于 2 秒且超过实际批处理时间 20% 的批次数据会持续添加到训练集,以重新训练 KNN 回归模型。为了不影响在线估计的效率,持续学习的重新训练过程是离线进行的,与在线估计解耦。
最高响应比优先批调度器
当有 LLM 实例空闲时,需要有调度新的批次给它处理。我们采用HRRN算法对队列中的批次进行调度。具体来讲,最高响应比优先算法根据请求的排队时间 T w T_w Tw 和批处理时间 T p T_p Tp来确定请求被处理的优先级,每次从队列中选择响应比 T w T p \frac{T_w}{T_p} TpTw最高的批次进行处理。这种调度算法有两个好处:(1)短服务时间的请求会被优先调度,降低总体的请求排队时间;(2)防止某些请求长期在队列等待,降低请求响应时间,提升服务质量 。根据大语言模型的自回归式生成过程,我们可以得出处理时间 T p T_p Tp由三个因素决定,即批次的最长请求长度,最长请求生成长度,和批次规模。然而,由于请求的生成长度在推理之前是未知的,因此在调度时,使用批处理时间估计器的预测值作为 T p T_p Tp真实值的近似。
显存溢出恢复机制
在真实业务场景中,服务的稳定性尤其重要。虽然我们可以根据预测的生成长度估计批处理的显存开销,但是生成长度预测算法存在误差,估计的显存使用可能超过实际情况,引起显存溢出而导致的服务不可用。为了解决这个问题,我们设计了容错机制,将导致显存溢出错误的批次均匀拆分为两个相同批次大小的小批次,并将它们放回等待队列。由于批次规模减半,这两个批次再次导致显存溢出的概率会大大降低。
实验结果
实验设置
我们在 8 张 NVIDIA V100 32B 显卡上进行实验,数据集是基于现有的主流公开数据集 [8-12] 合成的综合性评测数据集,包含MT、GC、TD、CT、BF和CC六个应用。其中MT和CT应用都有两个任务,分别是英文翻译到中文、中文翻译到英文,C# 翻译到Java、Java翻译到 C#。因此总共有 8 个任务。对于每个任务,我们从数据集中随机选择 10,000 条数据来构建请求,其中 7,500 个请求用于生成工作负载,其余 2,500 个请求用于训练Magnus 的生成长度预测器和批处理时间估计器。我们使用 ChatGLM-6B 作为实验使用的大语言模型,并且在不同的请求率下将 Magnus 和朴素调度(Vanilla Scheduling, VS),量化+朴素调度 (Vanilla Scheduling with 4-bit Quantization, VSQ),以及保守的连续批处理(Conservative Continuous Batching, CCB)进行性能对比。
实验结果

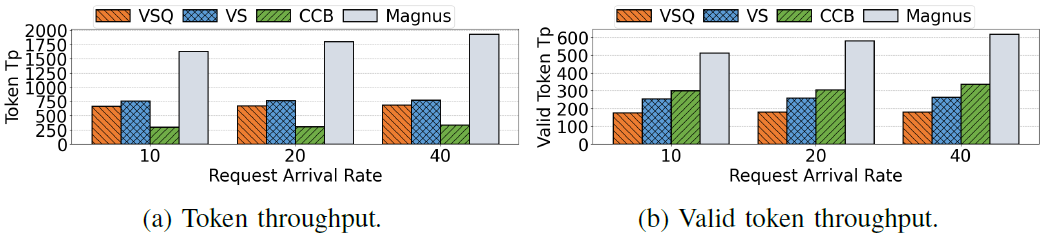
图9:token级性能
图8展示了在各种请求率下,Magnus 和三种基线在请求吞吐量、平均请求响应时间和尾部响应时间方面的性能。可以发现Magnus 的性能始终优于所有基线,在各种请求到达率下,请求吞吐量可以提高66%到234%,平均响应时间和尾部响应时间分别可以缩短 60.3% 到 89.7%,以及 53.2% 到 91.7%。此外,如图 9 所示,Magnus 在 token 级性能方面也优于三种基线,有效 token 的吞吐量和总 token 的吞吐量分别可以提高 70% 到 240%,以及 115% 到 489%。
消融实验


我们逐步验证 Magnus 各个组件在不同请求率下带来的性能增益。首先,我们在朴素调度(VS)策略中添加了生成长度预测器,从而得到了GLP。GLP 利用基于 WMA 的自适应性批次组合算法,但它使用一个固定的批次规模。接下来,我们取消了 GLP 的批次规模限制,实现了完全的自适应批处理算法,我们称这种新策略为 ABP。最后,在 ABP 上继续增加批处理时间预测器和 HRRN 批次调度器得到完整的 Magnus 。通过图 10 和图 11,我们可以看到 Magnus 的每个组件都能带来性能增益。
总结
在本文中,我们提出了Magnus 来实现 LMaaS 场景下的高效 LLM 批处理,它可以根据指令和用户输入的语义特征以及用户输入长度来预测请求生成长度。Magnus 会根据预测的请求生成长度自适应地调整批次大小,以充分利用 GPU 的并行计算能力,从而提高请求吞吐量。此外,Magnus 还通过基于批处理时间估计的 HRRN 调度来缩短请求响应时间。大量的实验证明,Magnu 可以有效降低请求响应时间并提高 LLM 批处理的吞吐量。在本文中,我们基于生成长度预测来优化静态批处理的推理效率,在未来,我们将进一步探索基于生成长度预测的请求调度方案在持续批处理中的应用。
Reference
[1] M. Freitag and Y. Al-Onaizan, “Beam search strategies for neural machine translation,” in Proceedings of the First Workshop on Neural Machine Translation. Association for Computational Linguistics, 2017.
[2]“Tensorflow serving,” https://github.com/tensorflow/serving, 2023.
[3]“Triton inference server,” https://github.com/triton-inference-server/server, 2023.
[4] Z. Du, Y. Qian, X. Liu et al., “Glm: General language model pretrainingwith autoregressive blank infilling,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 320–335.
[5] J. Bai, S. Bai, Y. Chu et al., “Qwen technical report,” 2023.
[6] “Baichuan2-7b-chat,” https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat, 2024.
[7] F. Feng, Y. Yang, D. Cer et al., “Language-agnostic bert sentence embedding,”in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 878–891.
[8] “Wmt18,” https://huggingface.co/datasets/wmt18, 2023
[9] V. Logacheva, D. Dementieva, S. Ustyantsev et al., “Paradetox: Detoxification with parallel data,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 6804–6818.
[10] F. Stahlberg and S. Kumar, “Synthetic data generation for grammatical error correction with tagged corruption models,” in Proceedings of the 16th Workshop on Innovative Use of NLP for Building Educational Applications, 2021, pp. 37–47.
[11] S. Lu, D. Guo, S. Ren et al., “Codexglue: A machine learning benchmark dataset for code understanding and generation,” in Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021.
[12] M. Yasunaga and P. Liang, “Break-it-fix-it: Unsupervised learning for program repair,” in International Conference on Machine Learning. PMLR, 2021, pp. 11 941–11 952.

