
- 1neo4j-索引_neo4j索引原理
- 2锅炉引风机控制系统总体设计_ai 引风机 控制
- 3Hessian和Java反序列化问题小结_hessian 序列化 字段一致类名不同
- 4全新的自动化脚本编写工具Aqua_idea aqua
- 5python 使用reportlab打造29页图文并茂pdf(全网reportlab最强pdf自动化生成代码)_python reportlab
- 6数据库管理-第156期 Oracle Vector DB & AI-07(20240227)
- 7重磅发布|腾讯云容器安全服务网络隔离功能已上线_腾讯云服务器 安全隔离中
- 8本地电脑大模型系列之 13 Cherry AI:ollama 的桌面应用程序_大模型客户端 ai cherry studio
- 9java实现上传文件后数据库保存图片地址
- 10现在人手必备Java面试八股文,从起跑线开始冲刺
KDD2024 | GCOPE:港科广联合港中文提出首个跨域图预训练框架
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
点击阅读原文观看作者赵海宏直播讲解回放!
今天介绍香港科技大学(广州)数据科学与分析学域李佳教授团队发表的一篇关于图预训练(Graph Pretraining)的文章" All in One and One for All: A Simple yet Effective Method towards Cross-domain Graph Pretraining",本文被KDD2024接收,代码已开源。

论文地址:https://arxiv.org/abs/2402.09834
项目地址:https://github.com/cshhzhao/GCOPE
背景
大型基座模型在自然语言处理(NLP)和计算机视觉(CV)领域都获得了瞩目的成就。其最显著的特点是能够在大规模的多样化的跨域数据集上进行预训练(称之为“All in One”),并将学习到的多样化知识迁移到各种跨域跨任务的下游数据集中(称之为“One for All”),展现出卓越的泛化能力和适应能力。然而,将这个想法应用到图领域仍然是一个巨大的挑战,跨域预训练往往会导致负迁移(如图1)。具体而言,首先,不同领域图数据之间多样化的结构模式会直接影响跨域预训练中学习到一种通用的结构模式用于下游的迁移,尤其是当结构模式差异很大的时候(比如,同配和异配图数据集)。其次,不同领域图数据之间的语义(特征)不对齐会导致跨域训练过程中难以找到一个统一的空间对图数据进行表示。这激发了本文的核心问题:相比传统的单域图预训练框架,如何进一步提出一种跨域图预训练框架?核心的两个难点是如何处理多样化的结构模式以及保证语义(特征)空间上的对齐。
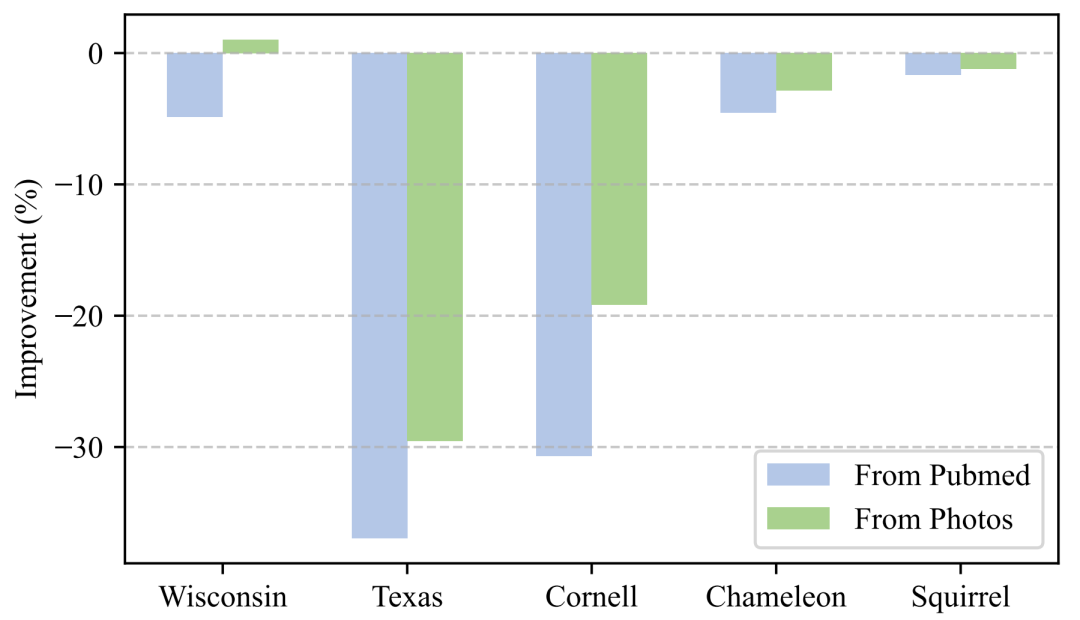
图 1 单源跨域图迁移场景下的负迁移现象
方法
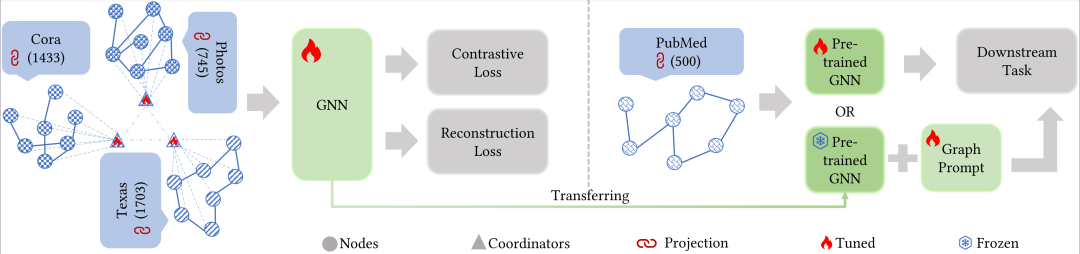
本文提出了一种名为GCOPE的跨域图预训练方法,旨在解决不同图数据集在结构和特征对齐方面的挑战。该方法通过引入可学习的图协调器(Graph Coordinators)模块来增强图之间的互联性,并促进它们的特征和结构对齐,从而实现跨域预训练。
具体而言,GCOPE框架分为以下几个步骤:
特征投影:在预训练阶段,首先通过特征投影模块将不同图的特征维度统一。具体操作包括奇异值分解(SVD)和注意力机制等方法,用于将特征投影到一个共同的低维空间中。这样,所有图的特征都可以在同一维度下进行处理。
引入图协调器:为了进一步解决结构和语义对齐的问题,本文提出了虚拟节点(即图协调器)的概念。这些协调器通过以下两种方式来增强图的互联性:
图内连接:为每个图分配一个协调器节点,该节点与图中每个节点形成全连接子网络,确保协调器能够高效地传递信息并协调图内的交互。
跨图连接:不同图的协调器之间通过边进行连接,构建跨图的通信基础,实现信息流通和知识共享。这些跨图连接的协调器节点通过相互连接,形成一个综合的跨域交互网络,促进不同图数据集之间的协作和知识共享。
生成图批次进行训练:通过协调器节点的互联,本文实现了跨图节点的联合采样。这种创新策略使得训练过程能够在单次学习迭代中处理来自不同图的数据,从而在统一的表示空间中进行学习。这不仅提高了模型捕捉数据底层结构的能力,还促进了跨域的鲁棒性和泛化能力。
预训练与迁移:本文采用应用广泛的图预训练策略(比如,GraphCL和SimGRACE)对联合采样后的跨域子图进行预训练。在预训练阶段,通过图协调器模块,使得不同领域的图数据在统一的表示空间中进行对齐和学习,从而保留各自的结构信息和语义特征。在迁移阶段,GCOPE展示了出色的泛化能力,能够灵活适应不同领域的下游任务,兼容传统微调和图提示框架。
通过上述方法,GCOPE不仅实现了跨域图数据的有效预训练,还通过图协调器模块解决了特征和结构对齐的问题,显著提升了模型在不同跨域下游任务中的表现。这样,GCOPE方法实现了“All in One”和“One for All”的目标,在图领域展现出卓越的泛化能力和适应能力。
实验
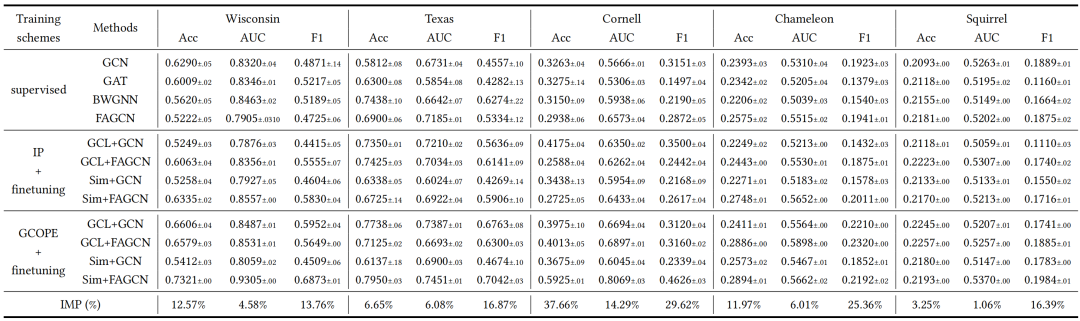
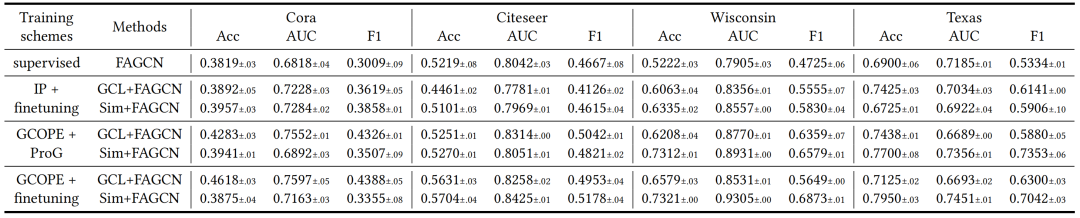
1.小样本下的跨域迁移
作者在同配和异配图数据集上对有监督方法(supervised)、预训练微调方法(IP + finetuning)和图协调器预训练微调框架(GCOPE + finetuning)进行了评估。下表展示了各种方法在小样本场景下跨同配异配数据集的迁移效果。结果表明,GCOPE方法对比传统单域预训练策略具有卓越的迁移能力。

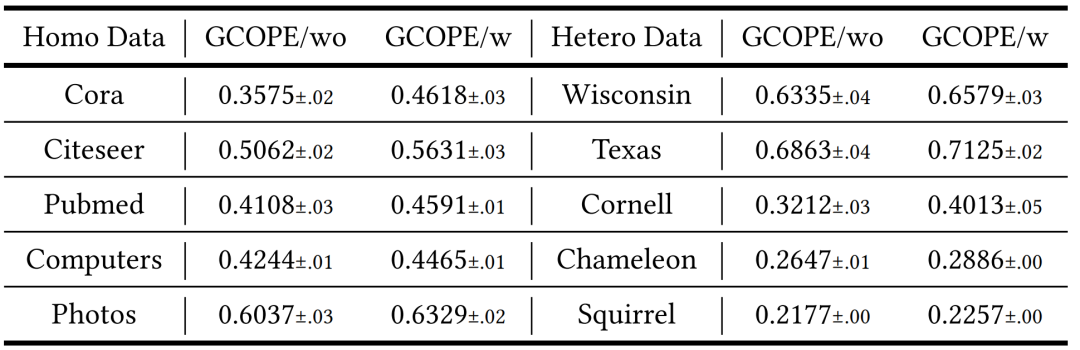
2.跨图连接分析
跨图连接作为跨域图数据集在预训练期间信息交互的重要结构。作者研究了不同协调器之间的跨图连接的边对GCOPE有效性的影响。具体来说,作者比较了两种变体:GCOPE/w(包括跨图连接)和 GCOPE/wo(取消跨图连接)。结果显示,GCOPE/w的效果远远好于GCOPE/wo的效果,进一步验证了跨图连接的必要性和有效性。
3.GCOPE+图提示
图提示作为一种重要的下游迁移技术。作者在4个常见的同配异配图数据集上测试了图提示的迁移效果(GCOPE + ProG)。实验结果表明,与监督方法和传统的预训练微调方法相比,GCOPE + finetuning和 GCOPE + ProG都表现出更优越的性能。值得注意的是,尽管GCOPE + ProG的性能略低于GCOPE + finetuning,但在下游节点分类任务中,GCOPE + ProG通过最少的可调参数实现了正迁移效果。与有监督方法相比,GCOPE + ProG的表现显著提升,缩小了性能差距。
结论
在这项研究中,作者深入探讨了跨域图学习中负迁移现象的复杂性。为解决这一问题,作者提出了一种名为GCOPE的创新跨域图预训练框架,有效地减轻了负迁移的影响。具体而言,GCOPE利用可学习的协调器对不同领域的图进行无缝融合,建立相互连接并对齐其特征。实验结果表明,GCOPE在各种同配、异配数据集上均表现出色,不仅提高了模型的跨领域迁移能力,还在少样本学习场景中展现出显著的优势。通过成功利用多样化跨域图数据集的协同潜力,GCOPE将成为图基础模型领域中一项开创性的工作,为实现通用人工智能的目标迈出了重要一步。未来的研究将继续优化该方法,探索其在更多实际应用中的潜力。
教授介绍
Prof. Jia Li

李佳博士,数据科学与分析学域助理教授,港科大广州-创邻图数据实验室联合主任。博士毕业于香港中文大学。他在工业界有多年的数据挖掘工作经历,曾供职于Google和腾讯。其研究目前主要为图数据的大模型,异常检测,图神经网络以及基于图数据的药物发现和医疗健康。他以第一作者或者通讯作者在人工智能与数据挖掘领域顶级会议与期刊发表三十多篇CCF-A论文,如Nature Communications, NeurIPS, SIGKDD, ICML, TPAMI等。获得2023年数据挖掘顶会SIGKDD Best Research Paper Award.

点击 阅读原文 查看作者直播讲解回放!
往期精彩文章推荐
KDD 2024 | HiGPT: 迈向下一代生成式图模型新范式
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看作者直播讲解回放!
- 机器学习 常见层 ...
赞
踩

