
- 1最全linux企业版火绒(火绒终端安全管理系统V2,2024年最新Linux运维开发自学教程
- 2论文阅读——ApeGNN- Node-Wise Adaptive Aggregation in GNNs for Recommendation
- 3【数据结构与算法】常用算法 前缀和
- 4制作原型工具_15种顶级原型制作工具齐头并进
- 5invalidate()和requestLayout()方法调用过程_requestlayout()没有调用 layout()
- 6VirtualBox虚拟机网络设置(四种方式)_virtualbox的ip地址
- 7AI金融投资:批量下载巨潮资讯基金招募说明书
- 8python使用pip安装包报错的解决办法(ERROR: Could not find a version that satisfies the requirement XXX)
- 9论文疑似AI辅写度高?专家教你如何化解危机_网上降algc哪个可靠一点
- 10Simulink Embeded Coder生成的C代码解析
【手把手教学】最新ChatTTS语音合成项目使用指南AI变声器chatTTS教程来了!5S夺走你的卧槽【附windows本地一键运行包】_chat tts
赞
踩
像这种充满语气充满感情色彩的人声,再搭配一段自拍图,是由最近大火的AI项目chatTTS生成的,ChatTTS是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且为SFT的版本.
那么https://pan.quark.cn/s/7596b606e69b可领取本地一键整合包
对话式 TTS: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
细粒度控制: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
更好的韵律: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究
废话少说怎么来用呢?
先说下显卡限制:对于30s的音频, 至少需要4G的显存.也就是说只要你是一个AI绘画玩家,你基本就完全可用,那么https://pan.quark.cn/s/7596b606e69b可领取本地一键整合包
语法支持
音频生成速度:使用4090技术,大约每秒钟可以生成7个字的音频。
响应时间:音频生成的实时因子(RTF)大约是0.3秒。
模型支持:目前,开源版本的语气词仅支持三种基本类型。
模型稳定性:自回归模型普遍存在的问题是稳定性不足。可能会出现声音突然变成其他人的声音,或者音质变得非常差。这种情况通常难以完全避免,但可以通过多次尝试来寻找更好的音频效果。
情感控制:目前发布的模型版本中,可以控制的只有笑声([laugh])以及一些声音中断([uv_break], [lbreak])作为字级别的控制单元。我们计划在未来的版本中开源更多情感控制的功能。
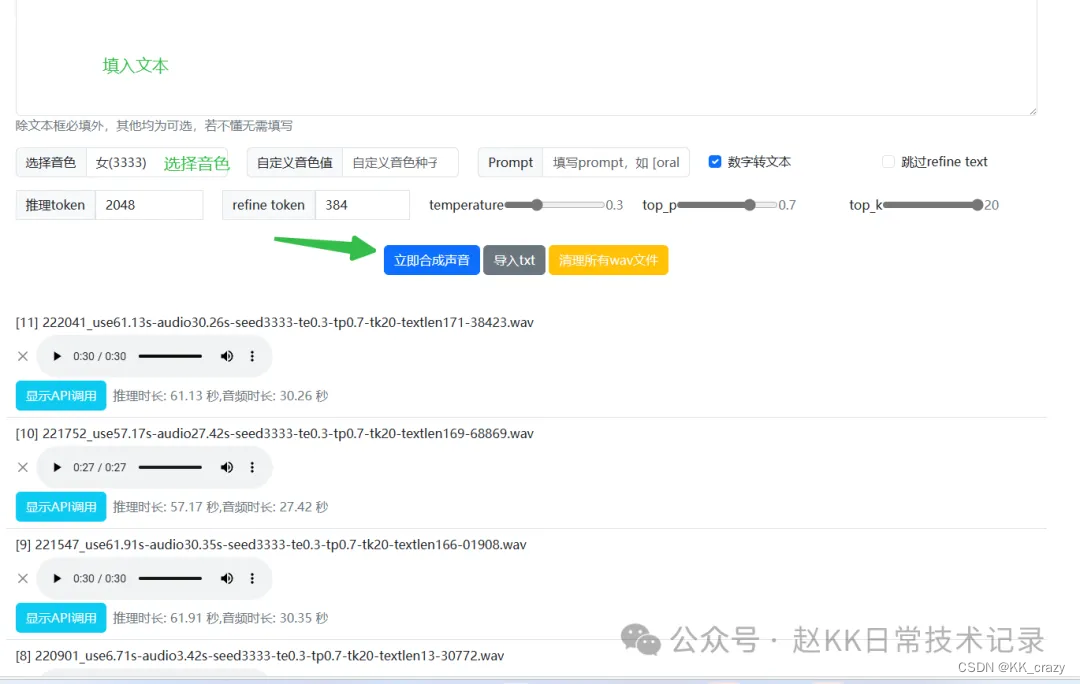
填入文本,我测试发现含有语气词,停顿,能够更好的表达语音感情,如果是长文本则需要测试其停顿性效果,比如加入了[uv_break],或者[lbreak]我觉得非常不错
选择音色
立即合成即可
-
ChatTTS是什么?
ChatTTS是一个开源的文本到语音(Text-to-Speech, TTS)模型,特别为对话场景设计。它适用于大语言模型(Large Language Models, LLMs)助手的对话任务,以及对话式音频和视频介绍等应用。ChatTTS支持中文和英文,并且能够实现自然流畅的语音合成,同时支持多说话人。它通过使用大约100,000小时的中文和英文数据进行训练,实现了高质量和自然度的语音合成。 -
ChatTTS的功能特色
- 对话式TTS:针对对话式任务进行了优化,实现了自然流畅的语音合成效果,并支持多说话人模式。
- 细粒度控制:能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
- 更好的韵律:在韵律方面超越了大部分开源TTS模型,同时提供预训练模型,支持进一步的研究。
- 多语言支持:支持中文和英文,满足不同语言用户的需求。
- 大规模数据训练:使用了大量数据进行训练,确保了声音合成的质量高,听起来自然。
- 对话任务兼容性:适合处理通常分配给大型语言模型LLMs的对话任务,提供更自然流畅的互动体验。
- 开源计划:项目团队计划开源一个经过训练的基础模型,促进学术研究和社区发展。
- 控制和安全性:致力于提高模型的可控性,添加水印,并将其与LLMs集成,确保模型的安全性和可靠性。
- 易用性:为用户提供了易于使用的体验,只需要文本信息作为输入,就可以生成相应的语音文件。
-
如何运行?
本地启动app.exe即可 -
应用场景
- 大型语言模型助手的对话任务:为LLM助手提供自然流畅的语音响应。
- 生成对话语音:适用于需要生成自然对话声音的场景,如虚拟助手、客服系统等。
- 视频介绍:为视频内容提供语音介绍,增强视频的吸引力和互动性。
- 教育和培训内容语音合成:为在线教育和培训材料提供语音,提高学习体验。
- 任何需要文本到语音功能的应用或服务:适用于需要将文本转换为语音的各种应用或服务。
综上所述,ChatTTS是一个功能强大的文本到语音模型,适用于多种场景,能够提供高质量的语音输出,支持多语言,并且易于集成到各种应用中。

