
热门标签
热门文章
- 1NLP project: Task 2_nlp-project2
- 2nginx basic认证以及重复提示账号密码问题处理_nginx 密码认证
- 3C++数组实现队列_数组实现队列c++
- 4python图形界面设计工具,python的图形界面gui编程_python ui设计器
- 5毕业设计:基于实时车流的智能交通灯系统 人工智能 机器学习 算法 python_智能交通灯背景和意义
- 6Anaconda安装在D盘,配置环境也想在D盘文件夹
- 78段数码管译码表_动态段选译码表
- 8uni-app 微信小程序之好看的ui登录页面(三)_小程序登录页
- 9CSDN创始人蒋涛事迹_csdn的老板是谁
- 10将有序数组转换为二叉搜索树(c语言版)_有序数组转二叉搜索树代码c语言
当前位置: article > 正文
大数据关联规则算法
作者:煮酒与君饮 | 2024-06-22 20:54:42
赞
踩
大数据关联规则算法
-
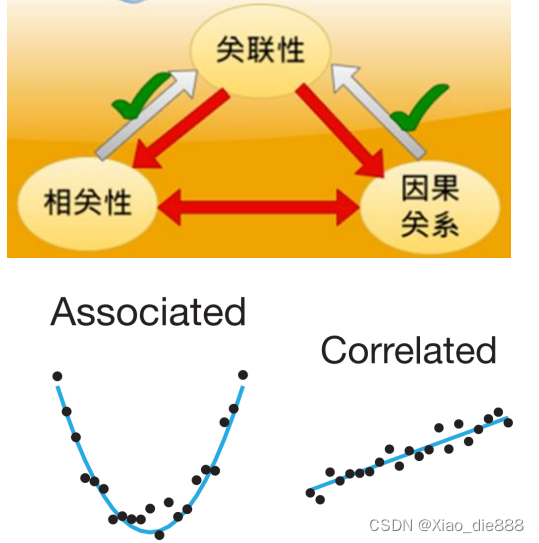
关联性(Association)
- 定义:指一个变量能够提供有关另一个变量的信息。
- 特点:关联性是一个广泛的概念,它可以包括直接的、间接的、强的或弱的联系。
-
相关性(Correlation)
- 定义:指两个变量同时上升或下降的趋势。
- 特点:相关性通常用相关系数来量化,如皮尔逊相关系数,它可以测量变量之间的线性关系强度和方向。
- 误区:相关性意味着关联性,而不是因果关系;
-
因果关系(Causality)
- 定义:指一个变量(原因)直接影响另一个变量(结果)。
- 特点:因果关系需要通过实验或统计方法来验证,例如随机对照试验(RCT)或使用因果推断模型。
- 误区:因果关系意味着关联,而不是相关性
关联
- 定义:关联是两个或者多个变量之间存在着的某种规律,这种规律是可被发现的并且是有意义的。
关联规则(Association Rules)挖掘
- 定义:挖掘负责找出给定数据集中数据项之间隐藏的关联关系,描述数据之间的密切度是关联分析的主要目的。
- 用途:关联规则用于描述相关联的事物之间同时有规律发生的知识模式。
应用场景
- 优化货架商品摆放:根据商品之间的关联性,优化超市或商场的商品摆放。
- 交叉销售或捆绑销售:利用商品之间的关联性,进行捆绑销售或交叉销售。
- 搜索词推荐:根据用户的搜索习惯,推荐相关搜索词。
- 识别异常:发现数据中的异常模式,如信用卡欺诈检测。
相关概念
- 项目(Item):交易数据库中的一个字段,对超市的交易来说一般是指一次交易中的一个物品,如:牛奶
- 事务(Transaction):某个客户在一次交易中,发生的所有项目的集合:如{牛奶,面包,啤酒}
- 项集(Item Set):包含若干个项目的集合(一次事务中的),一般会大于0个
- 支持度(Support):项集{X,Y}在总项集中出现的概率
- 频繁项集(Frequent Itemset):某个项集的支持度大于设定阈值(人为设定或者根据数据分布和经验来设定),即称这个项集为频繁项集。
- 置信度(Confidence):在先决条件X发生的条件下,由关联规则{X->Y }推出Y的概率
(给定X发生的条件下,Y发生的概率。) - 提升度(Lift):表示含有X的条件下同时含有Y的概率,与无论含不含X含有Y的概率之比,用于衡量关联规则的强度。


Apriori算法
- 提出者:Rakesh Agrawal 和 Ramakrishnan Srikant。
- 提出时间:1994年。
- 基本思想:基于支持度的连接与剪枝技术,有效控制候选项集的增长。
关联规则挖掘目的
- 目的:找出数据集中项与项之间的关系,用于市场分析、商品推荐等。
- 别称:购物篮分析,主要用于零售业中分析顾客的购买模式。
应用案例:啤酒和尿布
- 故事背景:美国妇女让丈夫下班后购买尿布,丈夫往往会同时购买啤酒。
- 商业应用:将啤酒和尿布摆放在一起,增加顾客同时购买这两种商品的机会。
- 结果:提高了啤酒和尿布的销量,成为商家推崇的营销策略。
Apriori 算法利用了一个层次顺序搜索的循环方法来完成频繁项集的挖掘工作。在这个算法中 Agrawal 给出了一个关于频繁模式的著名性质-Apriori 性质。
Apriori性质
- Apriori性质:频繁项集的所有非空子集也必须是频繁的。
- 推论1:非频繁项集的超集一定是非频繁项集。
- 推论2:强关联规则的子规则也是强关联规则。
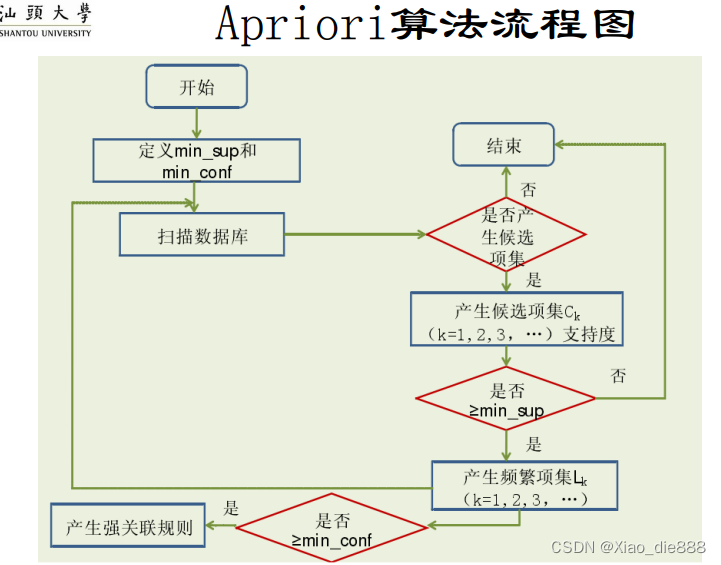
Apriori算法步骤
-
产生频繁项集
- 第一阶段:
- 所有单独的项作为候选项集 ( C1 )。
- 剔除支持度小于最小支持度阈值的项,形成频繁1-项集 ( L1 )。
- 第二阶段:
- ( L1 ) 通过自连接形成候选项集 ( C2 )。
- 扫描数据库,剔除支持度小于阈值的项,形成频繁2-项集 ( L2 )。
- 后续阶段:
- 重复自连接和剔除过程,形成更高阶的候选项集 ( C3, C4, \ldots ) 直到无法找到新的频繁项集。
- 第一阶段:
-
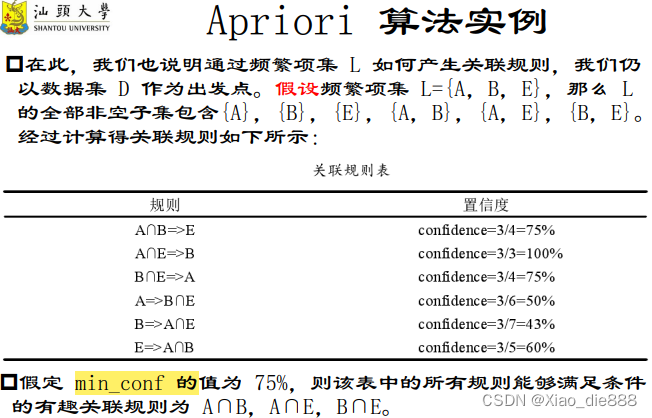
产生关联规则
- 利用频繁项集 ( L ) 产生关联规则。
- 满足可信度大于min_conf 的频繁项集产生强关联规则。
- 由于规则基于频繁项集产生,自动满足最小支持度 ( min_sup )。
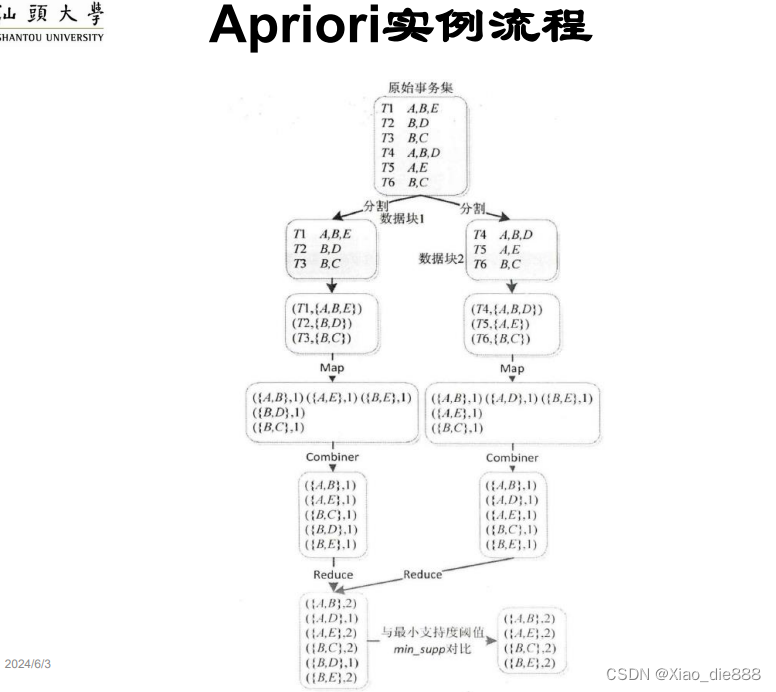
Apriori算法实例


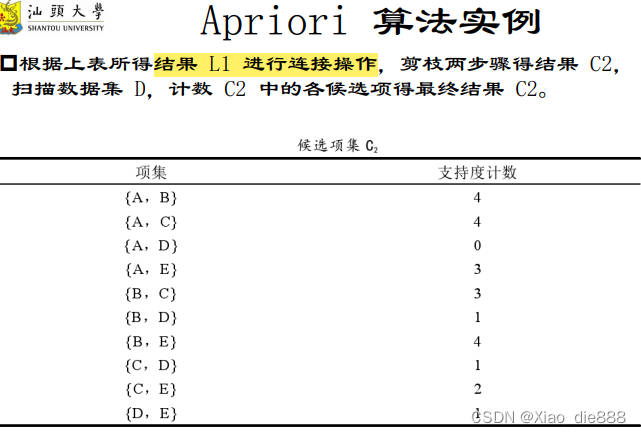
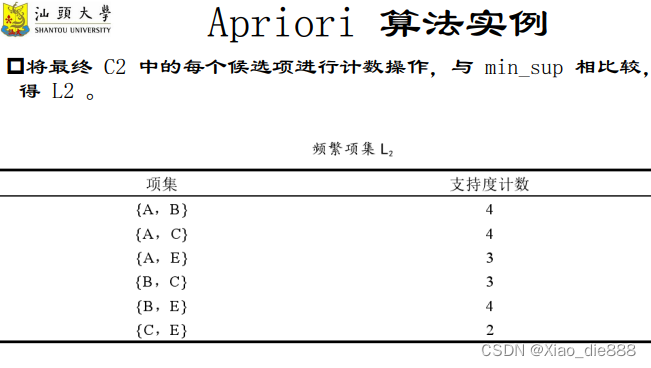


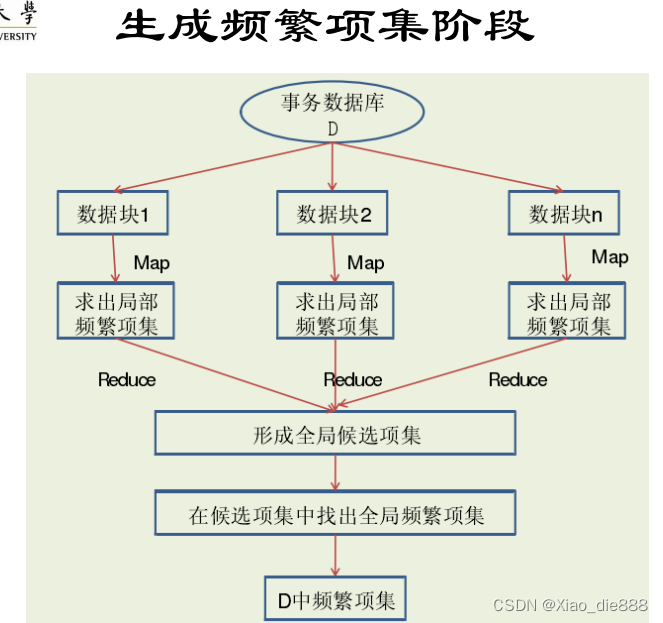
生成频繁项集阶段
-
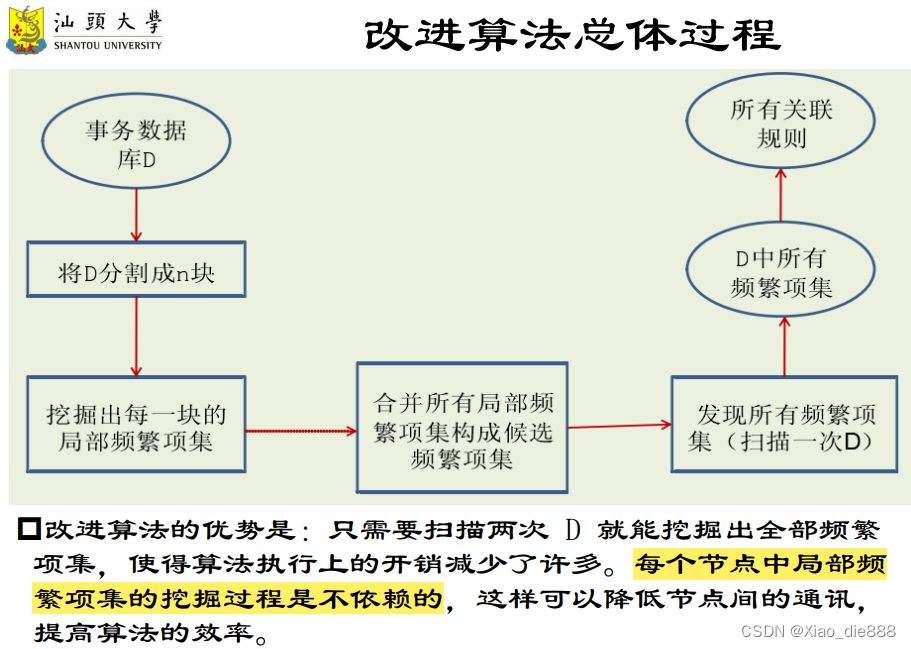
分割与分布数据
- MapReduce库将数据集D水平划分为n个数据块,然后发送到m个节点。
-
格式化数据块
- 数据块格式化为
<Tid, list>对,其中Tid是事务标识符,list是事务中的项目列表。
- 数据块格式化为
-
执行Map任务
- Map函数扫描每条记录,生成局部频繁1-项集和局部频繁k-项集。
-
运行Combiner函数
- 可选的Combiner函数在Map任务后执行,合并Map输出,减少网络传输。
-
执行Reduce任务
- Reduce任务接收Map端输出,合并局部频繁项集,生成全局候选频繁项集。
-
再次扫描D
- Map方法读取D中的记录,验证是否存在于全局候选频繁项集中,使用Combiner函数进行局部汇总。
-
合并Reduce函数输出
- 合并Reduce输出,与最小支持度阈值比较,输出满足条件的频繁项集。
- MapReduce框架:通过分布式计算,优化了频繁项集的生成过程。
- Map任务:生成局部频繁项集,类似于词频统计。
- Combiner函数:减少网络传输,提高效率,本地合并Map输出。
- Reduce任务:合并全局候选频繁项集,生成最终频繁项集。
- 两次扫描:第一次用于生成候选频繁项集,第二次用于验证和汇总。
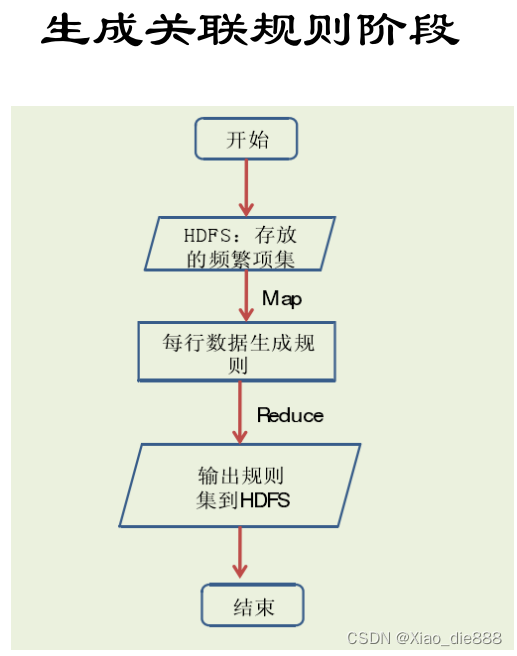
生成关联规则阶段
-
文本文件切分
- 将文本文件的每一行作为单独的切分处理。
- 形成键值对
<key1, value1>,其中key1 代表该行的偏移量,value1 代表一行文本(频繁项集中的一项)
-
Map函数处理
- Map函数扫描每对
<key1, value1>。 - 对每个频繁项集调用规则生成函数,产生所有可能的规则。
- 规则包括支持度和置信度,输出为
<key2, value2>,其中key2是频繁项集中的一项,value2是该项对应的所有规则(包括支持度和可信度)。。
- Map函数扫描每对
-
Reduce函数规约
- Reduce函数接收Map函数的所有输出。
- 对每个频繁项集的规则进行规约,筛选出满足最小置信度阈值的强关联规则。
- 将最终的关联规则
<rule, conf>对存储到HDFS(Hadoop分布式文件系统)。
- Map任务:处理文本文件,为每个频繁项集生成候选规则。
- Reduce任务:筛选有效规则,存储最终结果。
- 规则评估:评估规则的支持度和置信度,确保规则的有意义性和实用性。
- 存储结果:将生成的关联规则存储在分布式文件系统中,便于后续的访问和分析。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/747600
推荐阅读
相关标签

