
- 1io等待为什么引发cpu过高_一文搞懂,网络IO模型
- 2將IP地址改成自動獲取的詳細步驟
- 3python最简单的游戏代码,python最简单游戏代码_python20行贪吃蛇代码
- 4gitbook与Typora的使用_typora 与gitbook的高级用法
- 5扩散模型与生成模型详解_扩散生成模型
- 6如何使用git(同一账号)在多台电脑协同做工_git一个账号在两台电脑登录
- 7如何赚钱?聊聊程序员的副业与生意
- 8手机termux免root安装kali:一步到位+图形界面_termux安装kali-_termux手机版安装
- 9网络工程师——2024自学_网络工程师学习路线
- 10git设置查看清除账户信息_git清空store中的账号
YOLOV5实现印刷体数字识别_yolov5数字识别
赞
踩
一、安装pytorch GPU版
准备工作:确定下载的pytorch、cuda、cudnn版本,它们之间有一定版本要求的关系。就是pytorch确定了规定cuda最低的版本,cuda又确定者cudnn的版本。先确定好版本之后下载,记住不要急的安装。
pytorch官网选择版本,又对应的安装教程。下面图一是最新版本,想下载历史版本查看图二。
pytorch最新版本
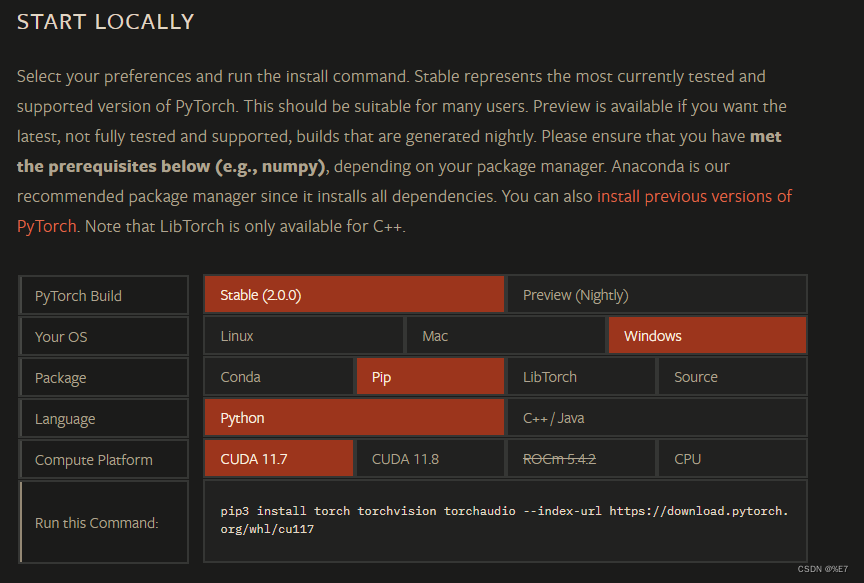
***pytorch历史版本 ***
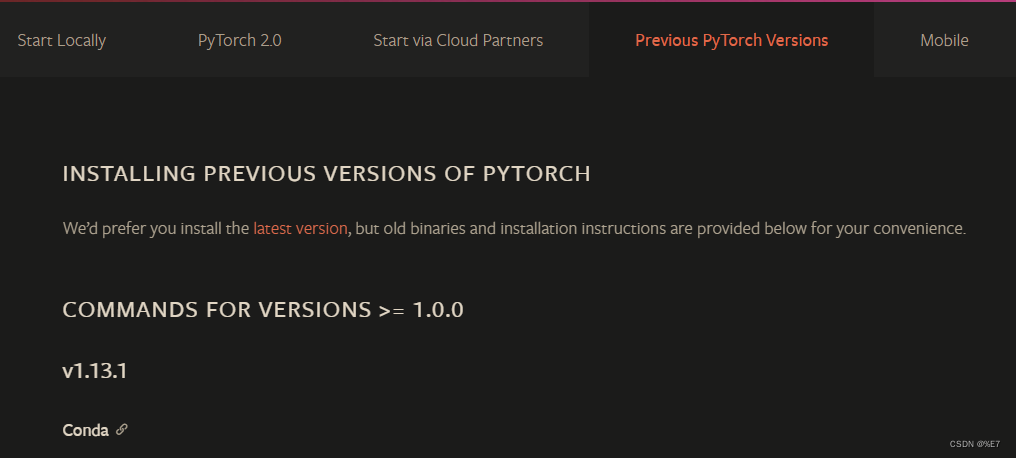
这里我现在的是CUDA 10.1版本的pytorch

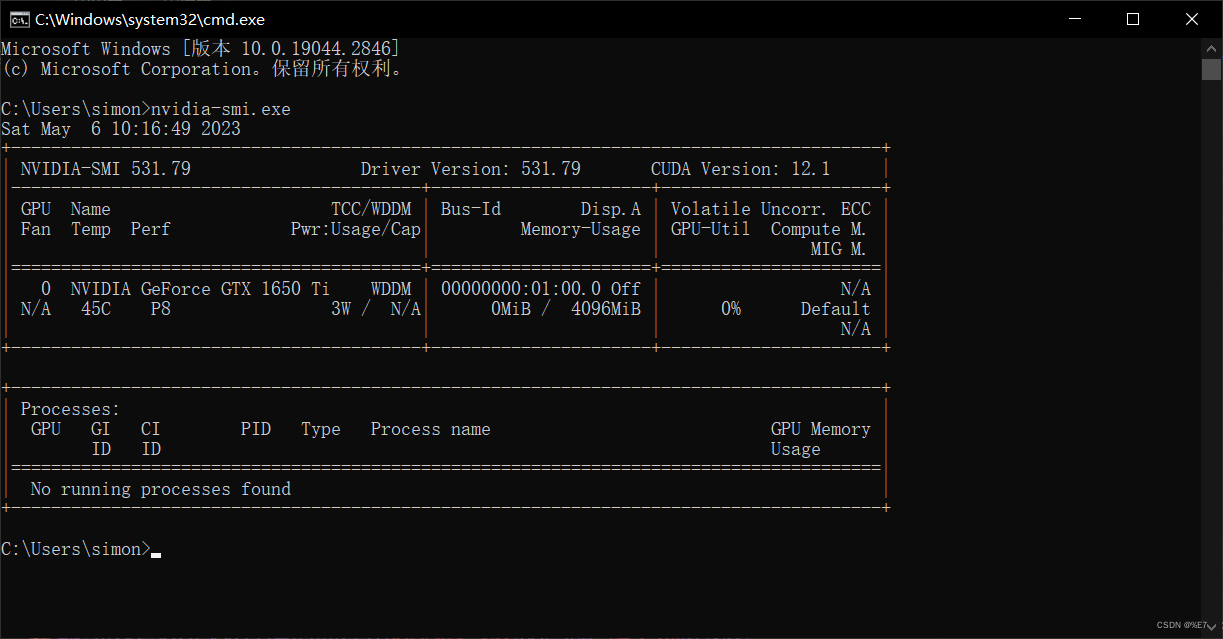
先确定好pytorch的版本,我们需要先安装cuda和cudnn才能安装pytorch。接下来安装CUDA,先查看自己win10电脑上的显卡驱动,在cmd命令窗口输入。可以看到我的显卡最高可支持CUDA 12.1的版本,还要注意一下我的驱动编码:531.79
nvidia-smi.exe
如果nvidia-smi.exe命令用不了解决方法
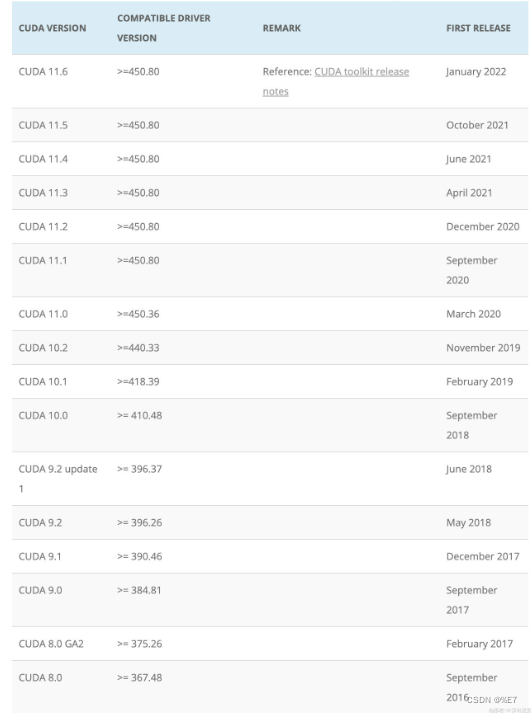
这里可以看到安装CUDA 10.1 需要的驱动编号最低450.80。这里我的显卡完全满足要求……
接下来去NVIDIA下载CUDA 下载链接
三选一,我选择的是10.1 update2的版本。然后下载下来了,

文件容量较大,下载速度可能较慢。耐心等待……
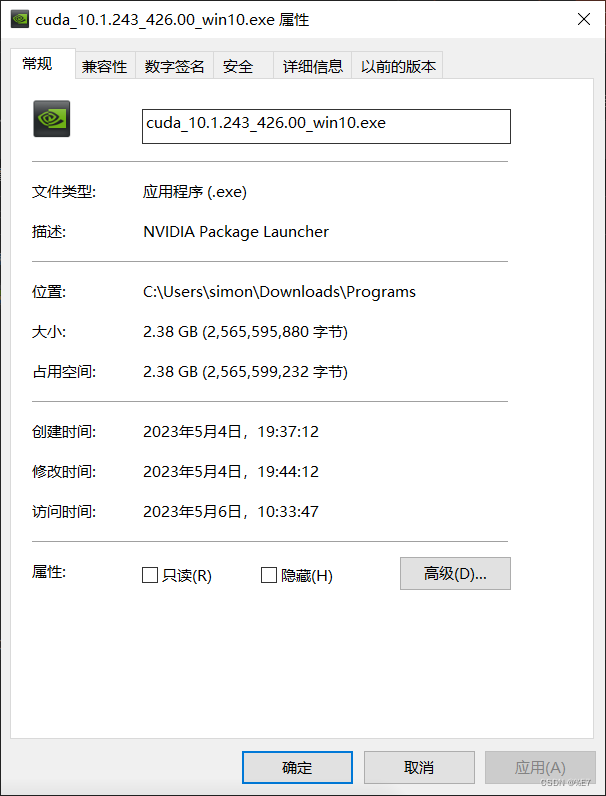
接下来安装CUDNN 下载链接
下载CUDNN需要注册并登录NVIDIA账号
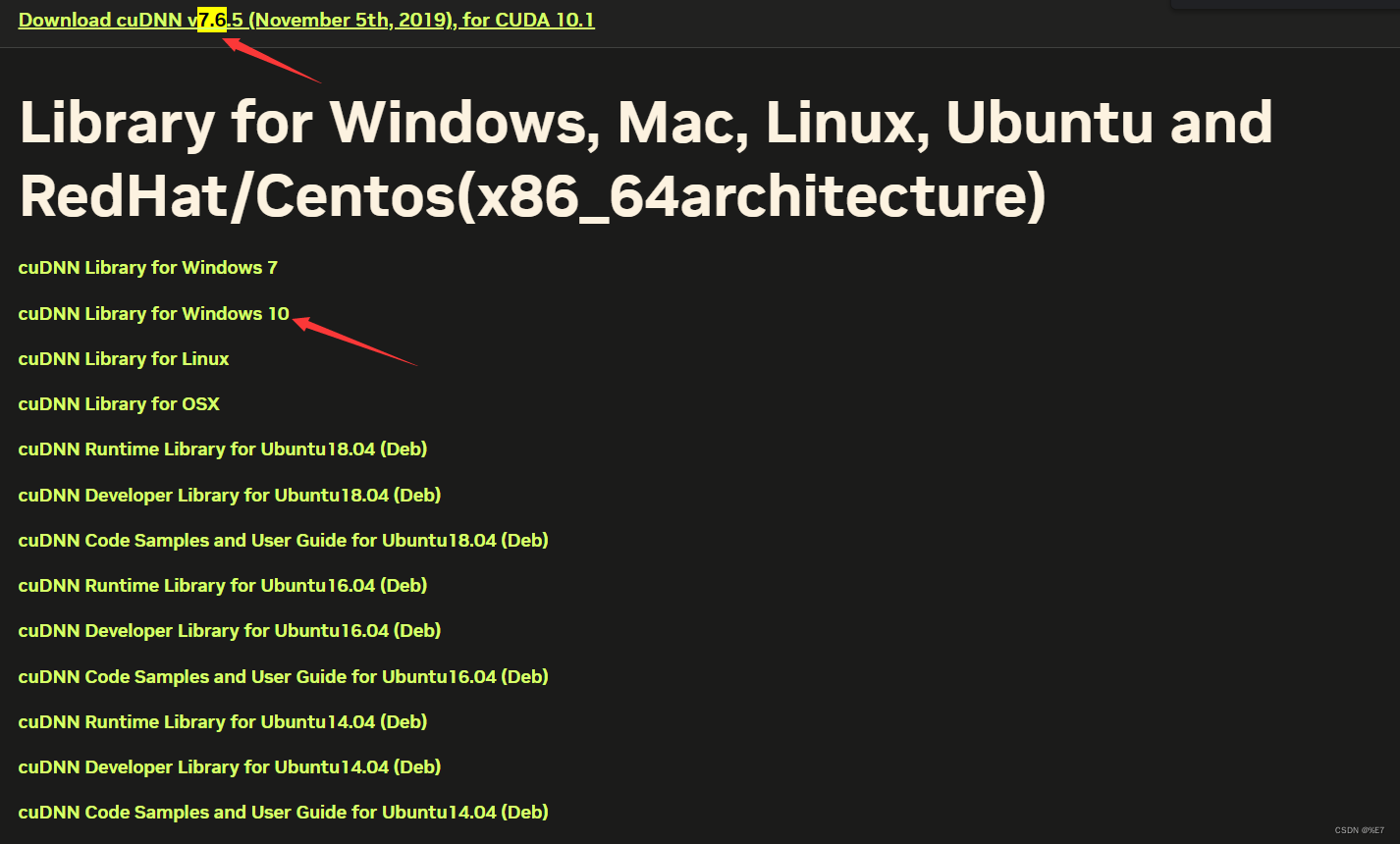
开始安装
前面我们确定了pytorch的版本,下载了cuda 10.1和cudnn 7.6.5
安装CUDA:双击exe安装包,按照流程安装即可。默认选择即可,不用选择其它
安装CUDNN:先解压cudnn7.6.5压缩包
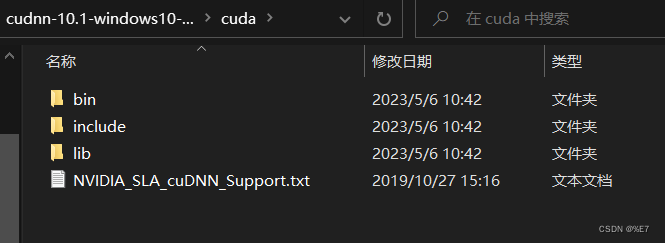
将cuda下的所有文件复制到本机的CUDA目录并进行替换,我的路径如下所示:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
最后添加环境变量
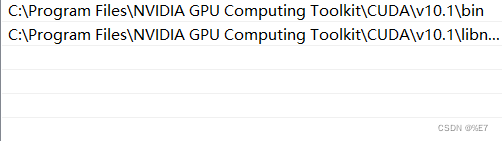
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp
验证cuda是否安装成功:
在cmd命令窗口中输入:NVCC -V 命令
如果显示有CUDA的信息则说明安装成功!

最后在conda创建python虚拟环境,建议python == 3.8 然后进行安装pytorch
这里是引用# CUDA 10.1
pip install torch1.8.1+cu101 torchvision0.9.1+cu101 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
=======================================================================
验证pytorch是否安装成功:
在python中输入 import touch 查看是否报错,未报错则说明安装成功。
二、下载yolov5
克隆地址:
git clone https://github.com/ultralytics/yolov5.git
下载速度较慢,建议通过镜像网站上下载或者科网。
下载之后进入目录
cd yolov5
- 1
安装依赖
pip3 install -r requirements.txt
- 1
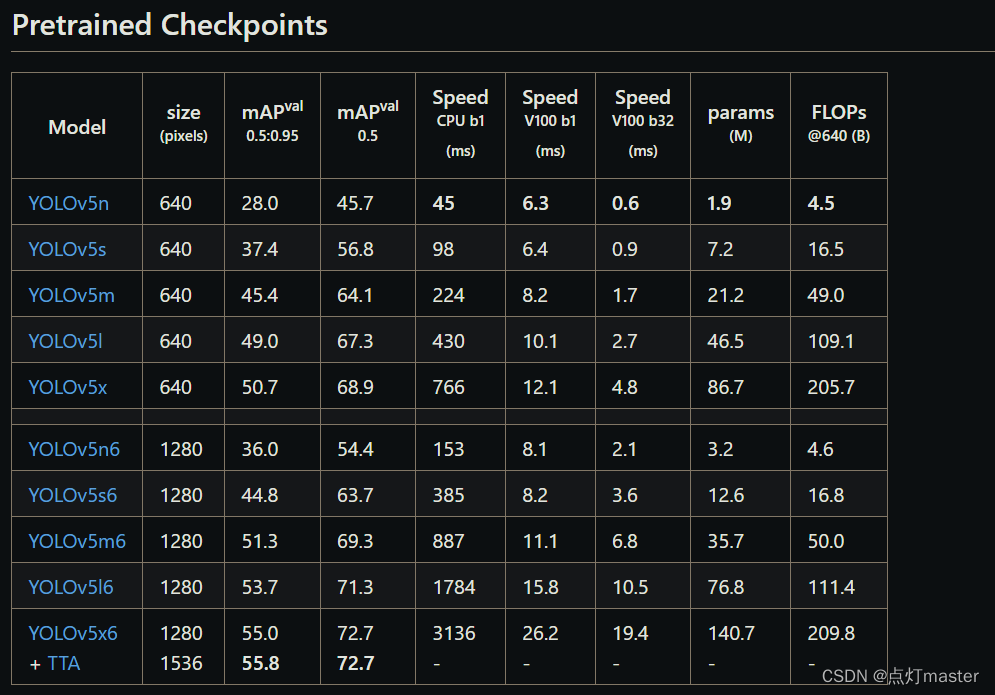
下载yolov5预训练模型,我们在预训练模型的基础上重新训练出新的模型。可快速的训练完成精度还高,简单的说就是站在巨人的肩膀上作为起跑点。
预训练模型下载链接
下载好的模型,放到yolov5下的weights文件夹。yolov5中没有weights文件夹则进行创建。
预训练模型精度越高,需要运算的时间也就越多
我们选择yolov5n、yolov5s、yolov5m三个模型进行训练,选三个是为了进行对比速度和精度。
测试:
python detect.py --source ./data/images/ --weights weights/yolov5s.pt --conf-thres 0.4
如果没报错,则说明环境配置成功。
三、训练自定义数据
准备自己需要训练的图片
data是数据集文件夹
+====================================================
images是存放训练的图片
train是存放训练集图片
val是存放测试集图片
+====================================================
labels是存放yolo格式的标注文件
train是存放训练集标注文件
val是存放测试集标注文件
+====================================================

标注图片
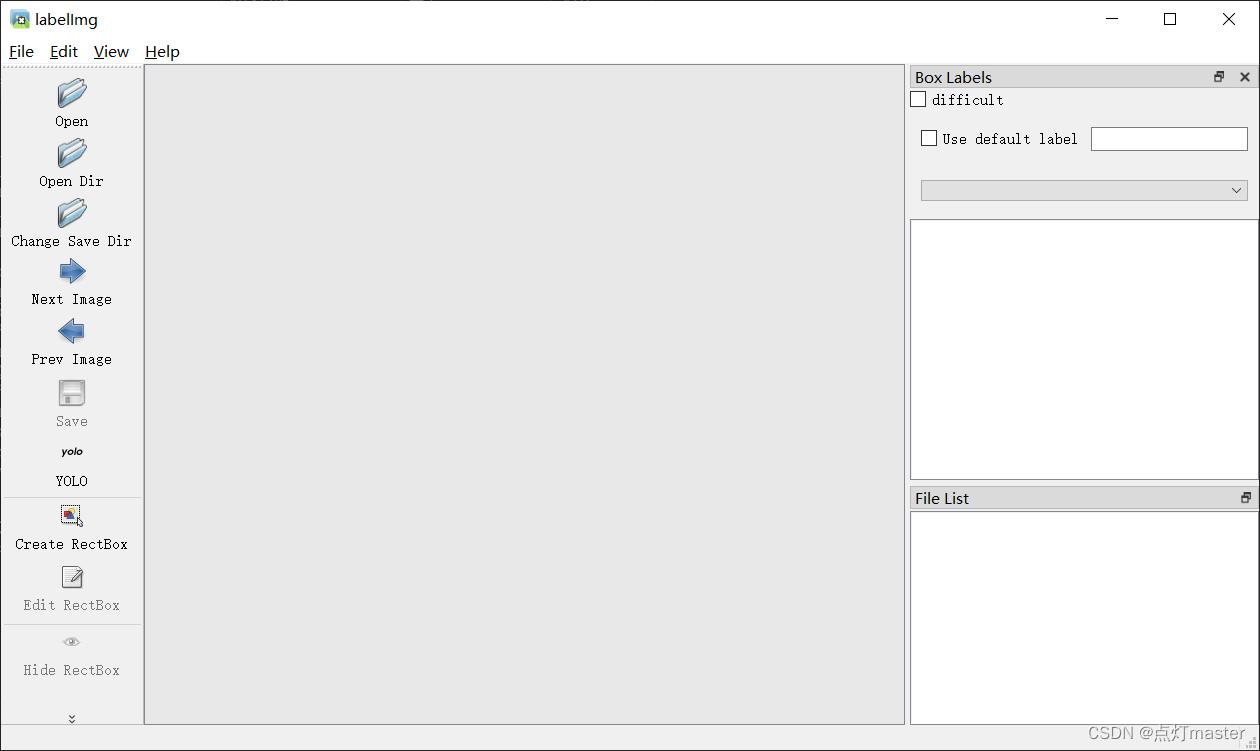
使用Labelimg等标注工具,工具需要支持YOLO格式
# 安装
pip install labelimg
# 使用
在conda虚拟环境中输入命令:
labelimg
- 1
- 2
- 3
- 4
- 5
open dir 是打开我们需要标注的图片文件夹,我选择的是 data/images/train
change save dir 是我们标注文件存放文件夹,我选择的是 data/labels/train
注意:
1、训练集和测试集都需要标注,标注文件需要存放至指定的路径下。
2、注意选择YOLO格式进行标注
训练图片数据集
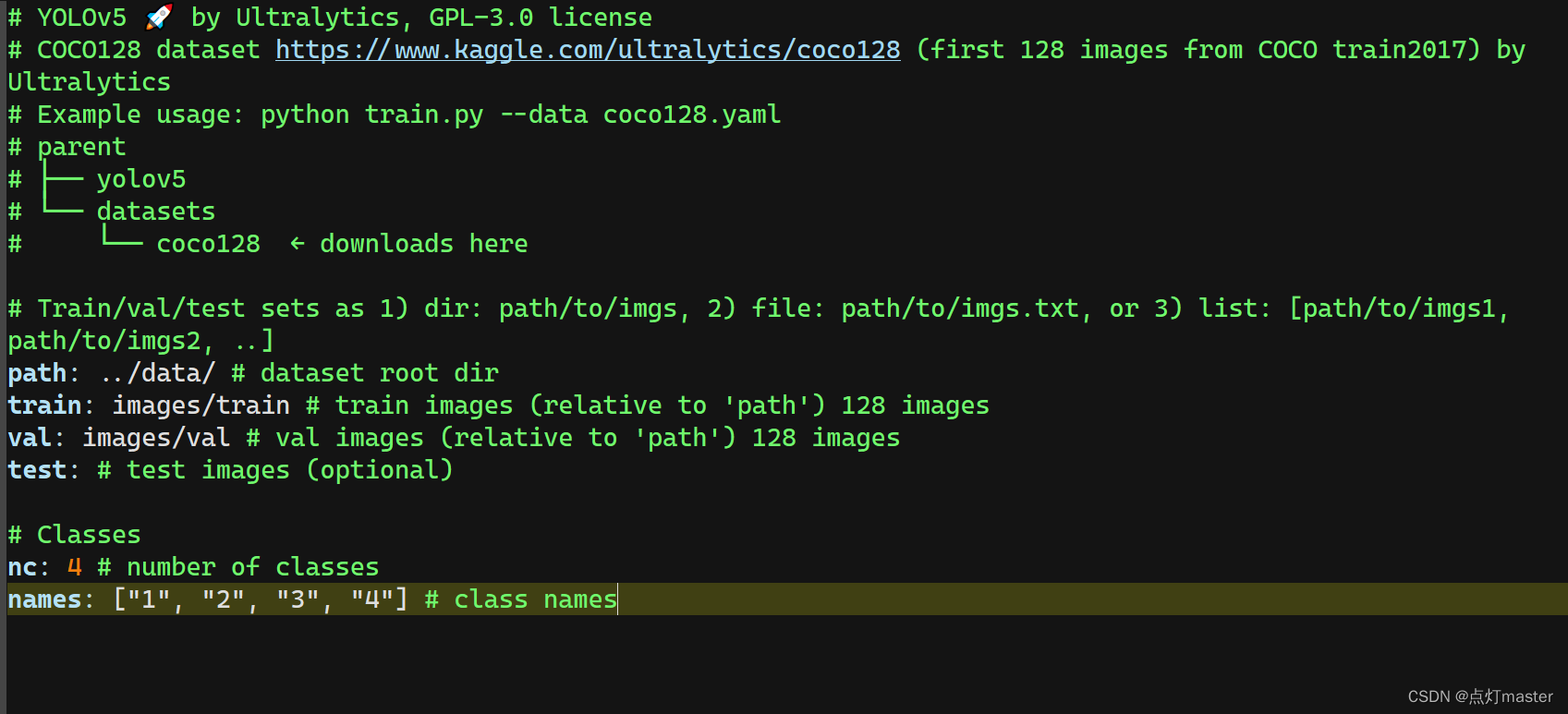
先在yolov5/data下的coco128.yaml文件复制一份副本,命名为coco_num.yaml文件。
用编辑工具打开,并进行编辑。
path:是数据集的文件夹路径,相对于yolov5下的train.py而言的路径
tain:是训练集路径,表示在path下的images/train路径下
val:是测试集路径,表示在path下的images/val路径下
++++++++++++++++++++++++++++++++++++++++++++++++++++++++
nc:是标注的数量
names:是标注的名称
关于标注文件,只要严格按照上述的文件存放格式。训练时会自动找到这个标志文件,如果存放不对,训练时可能会出错。
接下来在yolov5/models下的yolov5n.yaml拷贝一份,命名为yolov5n_num.yaml。我们使用编辑器打开yolov5n_num.yaml,然后将nc修改为训练集类型数量。

开始训练:
在yolov5的主目录下运行:
python .\train.py --data .\data\coco_num.yaml --cfg .\models\yolov5n_num.yaml --weights .\weights\yolov5n.pt --batch-size 20 --epochs 120 --workers 4 --name base_n --project yolo_test
- 1
注意运行不成功可能有numpy版本过高,内存分配过大等原因组成。numpy建议使用版本 1.20.3
内存过大将–batch-size 20中的参数20降低一点。
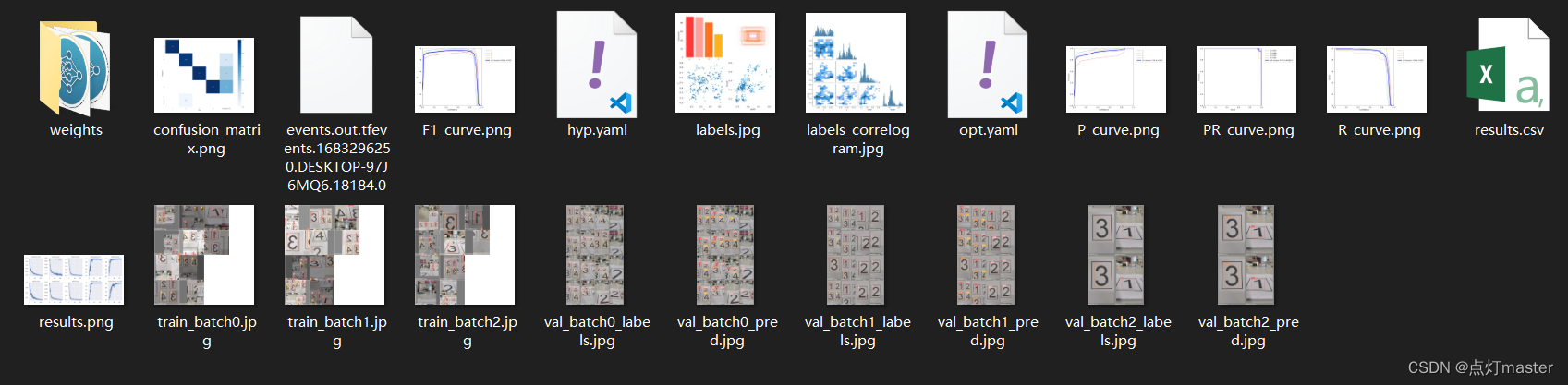
训练结束后会在yolov5/yolo_test文件夹下生成weights文件,和训练结果产生的数据。
四、python部署运行
import cv2 import numpy as np import torch import time class PPE_detector: def __init__(self): # 构造函数 # 加载模型 self.model = torch.hub.load('./yolov', 'custom', path='./weights/best.pt', source='local') self.model.conf = 0.4 # 置信度 # 获取视频流 self.cap = cv2.VideoCapture(0) # 识别 def detect(self): while True: # 获取视频流每一帧 ret, frame = self.cap.read() # 画面翻转 frame = cv2.flip(frame, 1) # 推理前,需要将画面转为RGB格式 frame_rgb = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB) # 执行推理过程 results = self.model(frame_rgb) results_np = results.pandas().xyxy[0].to_numpy() print(results_np) # 绘制边界框 for box in results_np: l,t,r,b = box[:4].astype('int') num = box[5]+1 # 绘制矩形框 cv2.rectangle(frame,(l,t),(r,b),(0,255,0),5) # 绘制文字 cv2.putText(frame, str(num), (l,t), cv2.FONT_HERSHEY_PLAIN, 2.0,(0,0,255),2) # 显示画面 cv2.imshow('PPE', frame) if cv2.waitKey(10)==ord('q'): break self.cap.release() cv2.destroyAllWindows() ppe = PPE_detector() ppe.detect()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49

