- 1java实现微信订阅功能记录_java 微信用户订阅公众号消息
- 2【自然语言处理】中文开源工具汇总(7种)_opennlp 中文语料库
- 3导出 Whisper 模型到 ONNX_whisper large-v2 onnx
- 4聚类算法之LDA_lda困惑度一直上升
- 5SQLServer2022新特性Window子句_sqlserver2022xin特性
- 6ModuleNotFoundError: No module named '_sqlite3'_error: cannot find module 'sqlite3
- 7php小h站视频系统源码,苹果cms v10x 原创自适应x站h站源码 视频模板 带试看功能 带自动采集YM源码...
- 8【回眸】ChatGPT Plus 测评体验
- 9【Java】JS简介_java js
- 10Pikachu靶场全级别通关教程详解_pikachu使用教程
ShardingSphere-JDBC5自定义类分片算法
赞
踩
前言
本文是基于ShardingSphere-JDBC5.1.1来写的,跟之前的4版本有一些差别,请对照好版本配置
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
这里采用分库分表,不同库不同分段表的方式操作,最复杂的场景能够配置好,其他的单纯分库,分表就不在话下了。
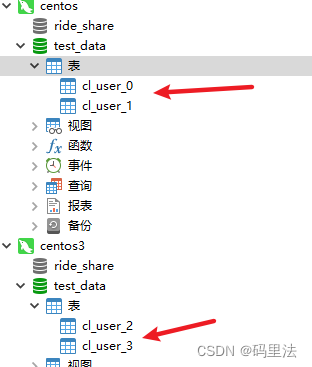
准备数据库
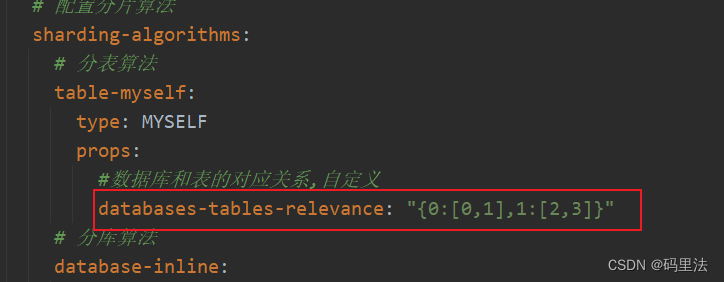
配置详解
- 配置数据源
spring:
shardingsphere:
props:
# 是否在日志中打印 SQL 更多属性参考->https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/props/
sql-show: true
datasource:
names: slave0,slave1
slave0:
url: jdbc:mysql://192.168.150.129:3306/test_data?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
slave1:
url: jdbc:mysql://192.168.150.132:3306/test_data?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里我们准备两个库,要实现的算法规则:
首先要根据id取模方法选出库,然后再根据选出来的库找到库下对应的表信息,最后通过随机算法拿到一张表进行数据添加。
比如:添加数据的时候,选择了slave0号库,而0号库下对应的是cl_user_0和cl_user_1表,我们就要拿到这两张表的信息,然后随机算出一张表用来存储数据。在yml中无法满足这种需求,所以只能用自定义算法。
自定义算法的核心接口为StandardShardingAlgorithm,这个接口是针对单片键的,因为现在5.1的资料比较少,所以配置的话可以自己看源码找到对应的配置接口。比如这里,我们可以根据StandardShardingAlgorithm实现的接口ShardingAlgorithm,查看它的各个实现类,然后找到复合分片的接口ComplexKeysShardingAlgorithm。
言归正传,开始具体编写吧。
/**
* @author: zhouwenjie
* @description: 自定义分片算法
* @create: 2022-04-29 10:29
**/
public class MyStandardShardingAlgorithm implements StandardShardingAlgorithm<Long> {
private static final String DATABASES_TABLES_RELEVANCE = "databases-tables-relevance";
//Getter Setter一定要加,不加拿不到自定义的参数
@Getter
@Setter
private Properties props = new Properties();
private Map<Integer, List<Integer>> databasesTablesRelevance;
private static final Random r = new Random();
@Override
public String getType() {
//对应yml中的type,这里怎么定义,那里就怎么写
return "MYSELF";
}
@Override
public void init() {
databasesTablesRelevance = getShardingCount();
}
private Map<Integer, List<Integer>> getShardingCount() {
Preconditions.checkArgument(props.containsKey(DATABASES_TABLES_RELEVANCE), "databases-tables-relevance cannot be null.");
//根据选择的库随机分配库所对应的表 [{0:[0,1]},{1:[2,3]}]
Map map = JSON.parseObject(props.get(DATABASES_TABLES_RELEVANCE).toString(), Map.class);
HashMap<Integer, List<Integer>> hashMap = new HashMap<>();
hashMap.putAll(map);
return hashMap;
}
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
//计算出选了哪一个库,因为数据库的选择就是基于分片键取模计算出来的
int value = (int) (shardingValue.getValue() % 2);
//获取value号库对应的多张表集合
List<Integer> list = databasesTablesRelevance.get(value);
//随机获取一张表
int index = r.nextInt(list.size());
Integer num = list.get(index);
for (String name : availableTargetNames) {
//通过配置好的库表对应关系,返回随机表名称
if (name.endsWith(num.toString())) {
return name;
}
}
return null;
}
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
return availableTargetNames;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
这么配置以后,你会发现一个问题,你配置的这个类并不生效,查看之后发现没有被加载,那么就看一下官方定义的算法InlineShardingAlgorithm是怎么被加载的,点一下看看
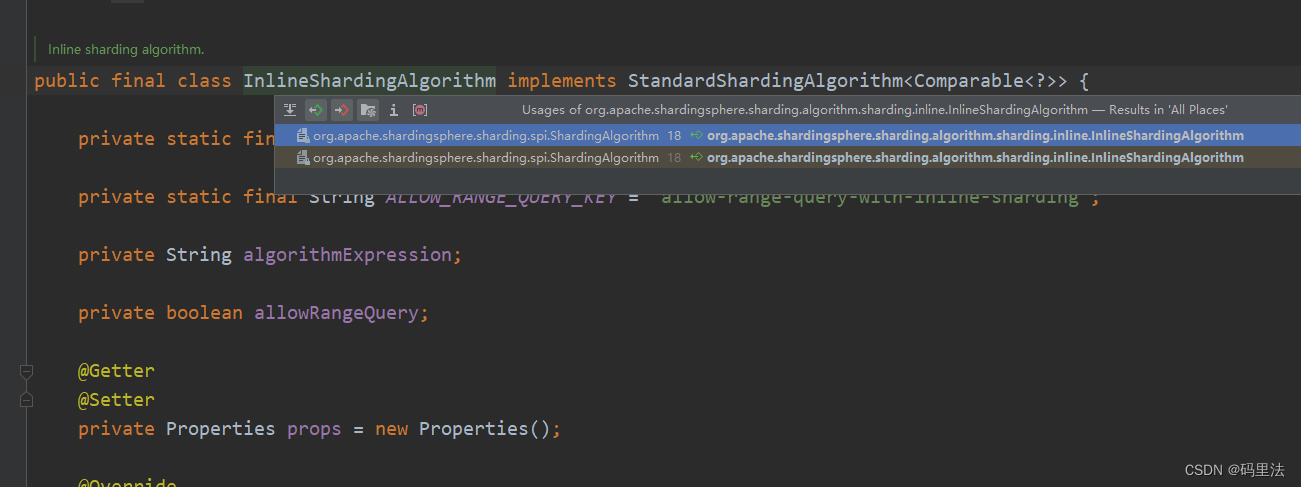
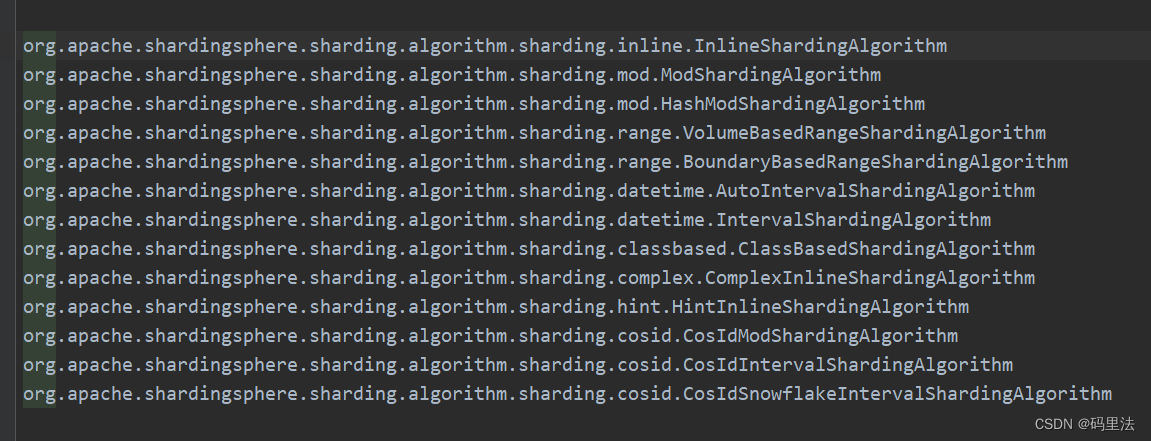
因为这里有个文件,不管它是什么吧,我们也在resource下定义一个,然后把我们的自定义算法类也放进去试试。
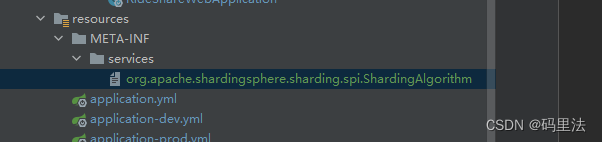
文件名:org.apache.shardingsphere.sharding.spi.ShardingAlgorithm
文件内容:

好了,重启就可以了,这里注意一下,自定义中的prop一定要加getter和setter注解,否则拿不到你自定义的值。
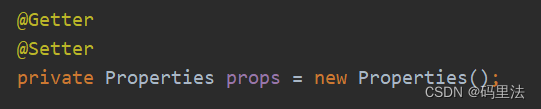
对应这里