
- 1python re模块compile_python正则表达式re模块理解(RE.COMPILE、RE.MATCH、RE.SEARCH)(六)...
- 2关于git配置代理的方法和一些需要注意的细节_git config --global proxy
- 3多模态大模型代表了人工智能领域的新一代技术范式
- 4计算机毕业设计hadoop+pyspark图书推荐系统 豆瓣图书数据分析可视化大屏 豆瓣图书爬虫 知识图谱 图书大数据 大数据毕业设计 机器学习_基于pyspark的推荐系统
- 5Caused by: kotlin.UninitializedPropertyAccessException: lateinit property rv has not been initialize
- 6弹出框 custombox.min.js 使用时候由于滚动条隐藏造成网页抖动变形的解决办法
- 7面相_面相 马鞍鼻
- 8数据安全与隐私保护在返利App中的实施策略
- 9Unity编程笔录--Unity Android 加密 so_unity text encry release
- 10STM32智能小车学习笔记(避障、循迹、跟随)_stm32f103rct6小车结合串口的避障循迹代码
公共数据+人工智能+强化学习模型,82.9分的《自然》顶级子刊说发就发!代码也公开,接稳咯!
赞
踩
出息了我的宝!公共数据+人工智能+强化学习模型,82.9分的《自然》顶级子刊说发就发!代码也公开,接稳咯!
原创 小欣 小心血 2024-03-03 19:00 上海

今天,小欣在看文献时,偶然发现了一篇非常厉害的高分文章,这篇文章仅凭公共数据就发了82分+Nature顶级大子刊!作者构建了基于人工智能的强化学习模型。
强化学习的基本思想是,智能体通过试错的方式,根据与环境的互动获得的奖励来调整其策略,以逐渐提高在特定任务上的性能。强化学习应用广泛,例如在游戏领域、机器人控制、自动驾驶等领域取得了显著的成就。其中,深度强化学习结合了深度学习技术和强化学习方法,使得智能体能够处理复杂的、高维度的输入和输出。不过今天咱们分享的自然是在医学领域的人工智能啦(ps:勇气和坚持是通往成功的金钥匙,这就是作者所追求的宝藏文献!)请坐稳,让小欣带你一同探索这篇强化学习的高分文献……
作者主要进行了以下工作:
1. 调查目的:研究人类偏好是否能够提高基于人工智能(AI)的诊断决策支持,在皮肤癌诊断中作为案例。
2. 使用强化学习:作者采用了基于专家生成表格的非均匀奖励和惩罚,以平衡各种诊断错误的利弊,这些错误是通过强化学习应用的。相比之下,与监督学习相比,强化学习模型提高了对黑色素瘤的敏感性,从61.4%提高到79.5%,对基底细胞癌的敏感性从79.4%提高到87.1%。
3. 减少AI过度自信:强化学习减少了AI的过度自信,同时保持准确性。此外,强化学习提高了皮肤科医生正确诊断的比率,增加了12.0%,并提高了最佳管理决策的比率,从57.4%提高到65.3%。
4. 在临床场景中的性能:作者进一步证明,奖励调整的强化学习模型和基于阈值的模型在各种临床场景中优于天真的监督学习。
5. 人类偏好的整合:研究结果表明,将人类偏好纳入基于图像的诊断算法具有潜力。
总体而言,研究的结论是,融入人类偏好可以改善基于人工智能的诊断决策支持,并且在开发临床实践中的人工智能工具时应考虑这些偏好。强化学习(RL)可能是在复杂临床场景中创建定制方法的潜在替代方法,而不仅仅是基于阈值的方法。然而,为了充分揭示强化学习在这一背景下的潜力,还需要进行额外的研究,包括评估患者和医生的满意度。
人工智能的应用越来越广泛了,小欣根据自己的文献阅读量打包票,这篇文章所用到的强化学习模型在预测肿瘤中的效果是杠杠的!如此高分的文章其创新性必然是毋庸置疑,大家快来一起学习吧~学到就是赚到啦!(渴望高分文章的朋友们,缺乏好的课题思路或者对分析方法不了解,那就快快加小欣微信吧!)


l题目:基于人工智能的皮肤癌决策支持的强化学习模型
l杂志:Nat Med
l影响因子:IF=82.9
l发表时间:2023年8月
公众号后台回复“123”,即可领取原文,文献编号-240226
数据来源

研究思路
文章的研究思路主要集中在如何利用强化学习(RL)模型来优化皮肤癌的诊断和治疗决策。以下是对文章研究思路的梳理:
1. 定义RL决策支持模型:首先,作者明确定义了一个基于RL的决策支持模型,并通过与监督学习(SL)模型的比较,突显了RL模型的优越性。
2. 采用统计方法进行数据比较:在方法方面,文章使用了配对或非配对t检验、Wilcoxon符号秩检验等统计方法,结合了RL和SL的学习方法,以全面比较两者的性能。
3. 数据来源和训练方法:文章明确说明了训练集和测试集图像的来源,并利用专家生成的奖励表进行RL模型的训练,这有助于保证模型的准确性和可靠性。
4. RL模型在高风险患者监测场景的应用:作者将RL模型应用于高风险患者的监测场景,通过逐个患者的所有病变图像,以最大化每个患者的累积奖励,展示了模型的实际应用。
5. 与SL模型的比较:最后,文章通过与SL模型的混淆矩阵比较,详细展示了RL模型在提高真阳性率和减少误诊方面的优势。
总体而言,文章通过引入和比较不同的学习模型,结合统计分析和实际数据,清晰地展示了RL模型在皮肤癌诊断中的潜力和实际应用价值。
主要结果
1. 模型与读者研究结果的比较
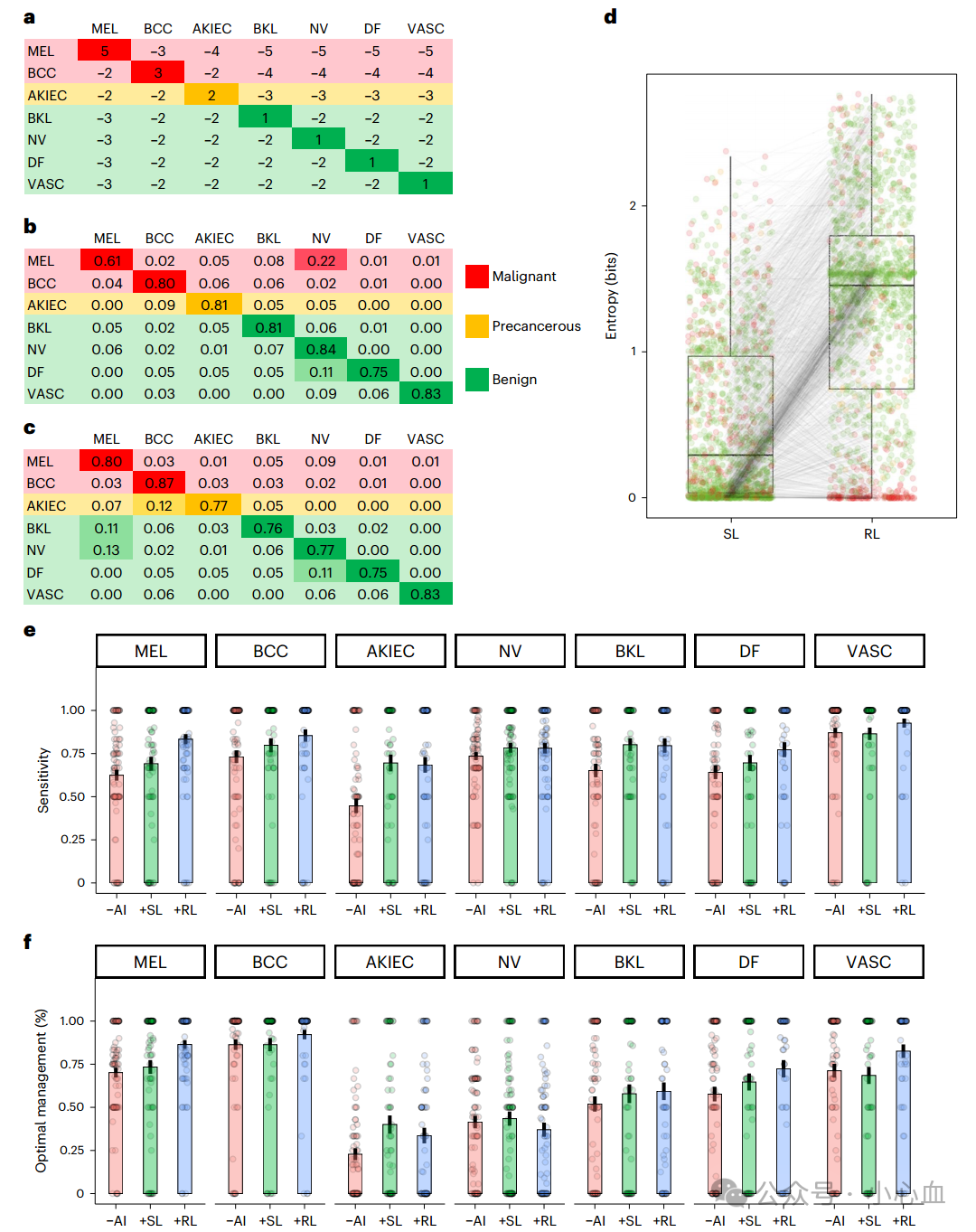
图1模型和读者研究结果的比较
a. 专家生成的奖励表:用于训练强化学习(RL)模型的奖励表。行表示实际情况,列表示预测结果。
b,c. 混淆矩阵:展示了监督学习(SL)模型(b)和强化学习(RL)模型(c)在相同测试集上的混淆矩阵。行表示实际情况,列表示预测结果。矩阵的比例通过行总和进行了归一化(MEL:n = 171;BCC:n = 93;AKIEC:n = 43;BKL:n = 217;NV:n = 908;DF:n = 44;VASC:n = 35)。
d. 配对测试集预测熵的差异箱线图:展示了SL模型和RL模型在配对测试集预测上熵的差异。黑线表示中位数,盒子表示第25到第75百分位数,须表示最小和最大值,P < 0.0001(Wilcoxon检验)。
e,f. 读者研究结果:比较了89名皮肤科医生在无人工智能支持(-AI)、使用SL模型支持(+SL)和使用RL模型支持(+RL)的情况下的敏感性(e)和最佳管理决策的频率(f)。最佳管理决策包括对黑色素瘤和基底细胞癌采取"切除"措施;对于光老化性角化症/表皮内癌采取"局部治疗"措施;对于痣、良性角化病变、皮肤纤维瘤和血管病变采取"解除"措施。条形图显示平均值,须表示标准误差。
2. 三种不同场景下的模型比较

图2三种不同场景下的模型比较
顶层(二元场景:良性与恶性):
a. 专家对决定是否切除的恶性概率阈值:显示了10位专家对判断是否切除的恶性概率阈值。
b. 接收者操作特征曲线(ROC曲线):由SL模型产生,并使用阈值(SL模型)或奖励(RL模型)的十位专家的操作点。可能的管理决策为“解除”或“切除”。真正例率和假正例率指的是被切除的恶性和良性病变的比例。黑色三角形表示天真方法(如果恶性概率 > 0.5,则切除)。
c. 比较SL模型和RL模型提供的黑色素瘤真阳性率(TPR)阈值:使用阈值(SL模型)和奖励(RL模型)的十位专家提供的黑色素瘤真阳性率。条形图显示平均值,须表示标准偏差(P = 0.11,配对t检验);虚线表示天真方法。
中层(多类别场景,额外的治疗选择):
d. 十位专家对光老化性角化症/表皮内癌治疗概率的阈值:显示了决定局部治疗的十位专家对光老化性角化症/表皮内癌概率的阈值。
e. 每个动作和诊断的中位奖励:
f-h. 通过诊断的行动的混淆矩阵:天真方法(f)、阈值调整的SL模型(g)和RL模型(h)。
底层(以患者为中心的方法,7,375个病变,524名患者):
i. 十位专家对判断是否解雇、监测或切除的恶性概率阈值。
j. 每个动作和诊断的中位奖励。
k. 根据模型判断的良性病变切除数量。
l. 根据模型监测的良性病变数量。
m. 根据模型的55例黑色素瘤管理策略。
文章小结
这篇文章通过探索基于强化学习(RL)的模型在皮肤癌诊断和治疗决策中的应用,展现了其在提高真阳性率和减少误诊方面的优越性。创新之处在于引入RL模型,并与传统监督学习(SL)模型进行比较,凸显了RL的灵活性和适应性,尤其适用于高风险个体的诊断和监测。方法上采用了统计方法,如配对或非配对t检验、Wilcoxon符号秩检验,并综合了RL和SL的学习策略。文章为皮肤癌AI决策提供了新的思路和路径,凸显了其在提高准确性和管理效率方面的潜力。作者对强化学习领域有深厚造诣,独到的分析思路使其发表在Nature大子刊中,表现出色,值得广大研究者学习借鉴。对于对这一领域感兴趣的读者而言,这篇文章的研究思路将为未来的研究提供有益的参考。另外国自然申请不会写,课题设计没头绪,生信分析不会做等困扰都可以来找小欣啦!
小欣有话说
小心血公众号持续为大家带来最新医学思路,更多创新性分析思路请点击链接。想复现这种思路或者定制更多创新性思路欢迎直接call小欣,竭诚为您的科研助力!

