
- 1nltk.download()问题-ssl:certificate_verify_failed_download failure: ssl verification failure
- 2【kafka源码】kafka分区副本的分配规则
- 3unity oss上传文件_unity 自动上传oss 代码
- 4翻译: Gen AI生成式人工智能学习资源路线图一_genai-handbook.github.io
- 5智能计算机控制方向,智能计算研究方向
- 6matlab仿真数字电路,基于matlab的数字逻辑电路仿真
- 7rabbitmq使用mqtt协议_rabbitmq qmtt
- 8手把手教你:个人信贷违约预测模型
- 9git push 提交后撤回--图文详解_如何撤销 git reset --hard后 git push -f不会回退合并的吗
- 10Modelsim原理图生成小白教程(含操作实例)_modelsim生成电路图
屌爆了!阿里 Qwen2 登顶全球开源第一...
赞
踩
1
OpenAI停止支持中国等地区
近期,OpenAI宣布将正式封锁来自中国、朝鲜、俄罗斯等非支持国家和地区的 API 流量,终止对中国提供 API 服务,进一步收紧国内开发者访问 GPT 等大模型,打压中国人工智能的发展。

一石激起千层浪,不少小伙伴也都担心后续无法使用到更高性能和更加精准的大模型,纷纷咨询我,就在大家担心和焦虑的时候,阿里云百炼率先发声,愿为OpenAI API用户推出高性价比的国产大模型解决方案,赠送中国开发者2200万免费tokens及专属迁移服务,可谓雪中送炭,让这些初创企业可以无缝过渡。
阿里云百炼集成了上百款大模型api,除了通义、Llama、ChatGLM、Yi等系列,还首家托管零一万物、百川智能等系列三方模型,覆盖国内外主流厂商
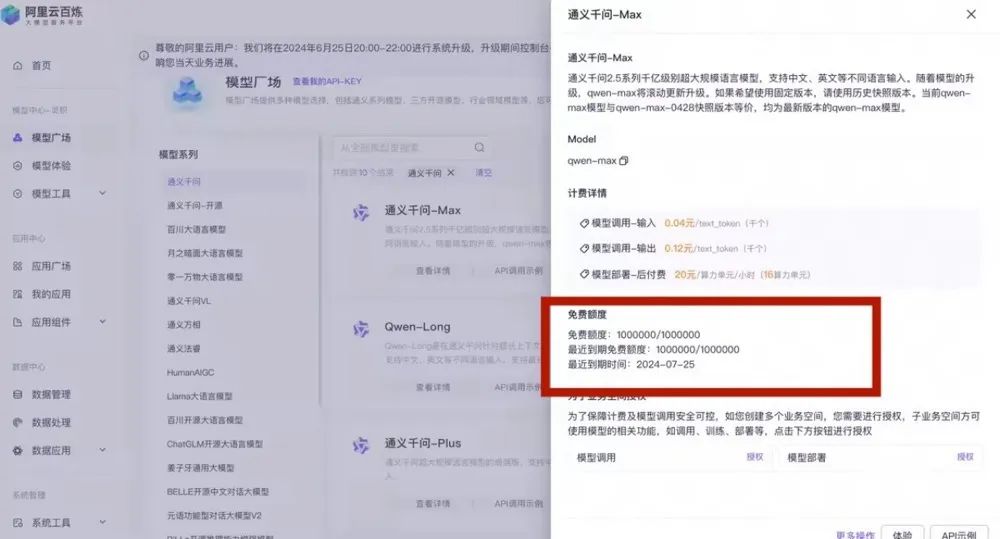
2
通义千问 Qwen2 登顶第一
与此同时,6月27日,全球知名的开源平台Hugging Face的联合创始人兼首席执行官Clem在社交平台宣布,阿里巴巴最新开源的Qwen2-72B指令微调版本在开源模型排行榜上荣登榜首,成功卫冕全球开源大模型第一名。
Clem则第一时间发文称:“Qwen2是王者,中国在全球开源大模型领域处于领导地位。”
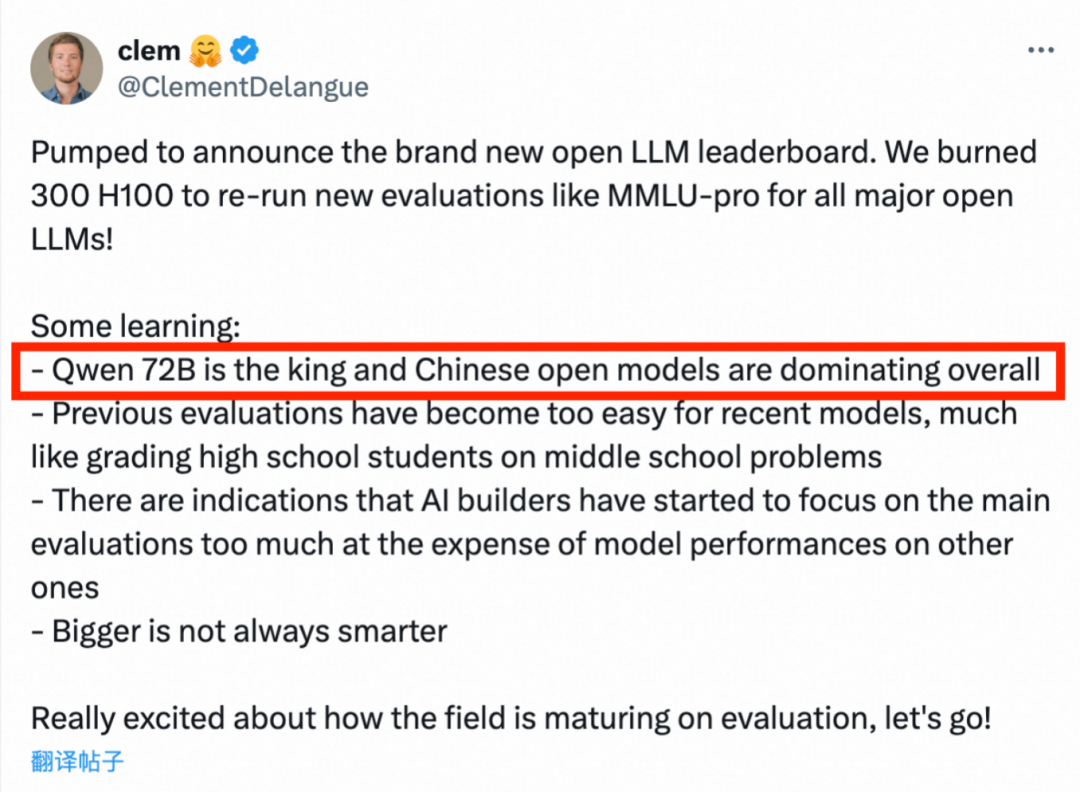
对于本次各大模型排名测试,Clem表示:为了打造更为公正和准确的开源大模型排名,团队利用300块H100高性能硬件,对全球100多个主流开源大模型,包括Qwen2、Llama-3、Mixtral、Phi-3等,在BBH、MUSR、MMLU-PRO、GPQA等严格的基准测试集上进行了全面而深入的评估。
这次重新评估的初衷在于,许多开发者过于追求排行榜的名次,导致在模型训练过程中过度依赖评估集数据,并且过去的评估标准对于模型而言显得过于简单。因此,本次评估提高了难度标准,以检验这些模型在更高挑战下的真实性能。
令人瞩目的是,阿里通义开源的Qwen-2 72B模型在激烈竞争中脱颖而出,不仅超越了科技巨头Meta的Llama-3,还超越了法国知名大模型平台Mistralai的Mixtral,成为了新的行业领军者。这一成绩充分展示了中国在全球开源大模型领域的领导地位,而Qwen2成为了真正的王者。
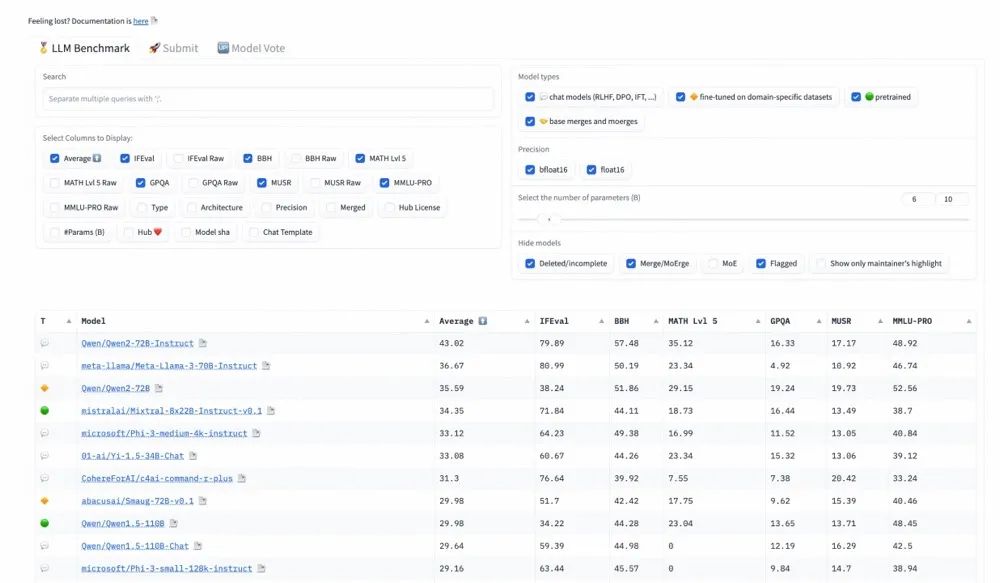
另外,该榜单前十名竞争非常激烈,多数模型都在之前登顶过TOP1,对手实力可谓强劲,有种大模型界“华山论剑”之感。本次,阿里独占多席,除了阿里的Qwen2-72B指令版排名第一外,第三名,第九名和第十名也均被阿里拿下,早期版本Qwen1.5-110B的基础版与Chat版本也均再次上榜,彰显了阿里在该领域的持续影响力与贡献。
注:HuggingFace的开源模型排行榜,被誉为全球最为权威的评估标准,再次见证了Qwen2的非凡实力,它连续占据榜首之位,稳固了其在开源大模型领域的冠军宝座。
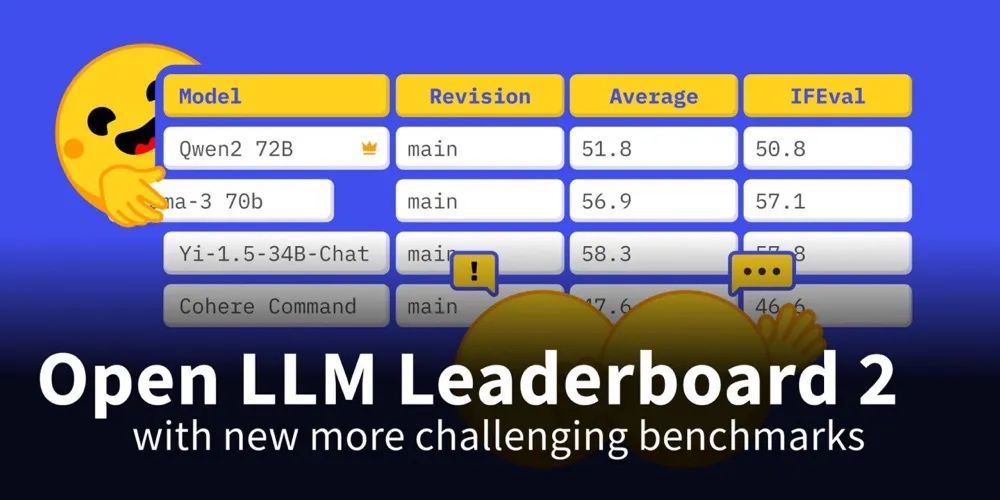
针对这次的榜单是v2版本,也是HuggingFace一年来首次全面更新的版本。榜单内的测试集,更难、更好、更快、更强(Harder, better, faster, stronger),对模型的考察也更有说服力。
无论在旧版还是新版的排行榜上,Qwen2都稳稳坐头把交椅,无悬念地巩固了其作为全球顶尖开源模型的地位。
Qwen2开源地址:https://huggingface.co/Qwen/Qwen2-72B-Instruct
3
国产开源大模型备受瞩目
针对中国开源大模型,外界也在关注,除了在最新的Huggingface开源大模型排行榜中,Qwen2-72B位居榜首之外。
6月27日上海人工智能实验室大模型测评榜单Compass Arena的最新结果,阿里通义千问Qwen2-72B在排名中仅次于GPT-4o,以1分之差位居第二,成为排名国内最高的开源大模型。它的总成绩超过了文心4.0、讯飞星火3.5等闭源大模型。Compass Arena是上海人工智能实验室推出的一项权威榜单,专注于评估主流大模型的能力。这个结果显示,阿里通义千问Qwen2-72B在自然语言处理领域具备强大的表现。
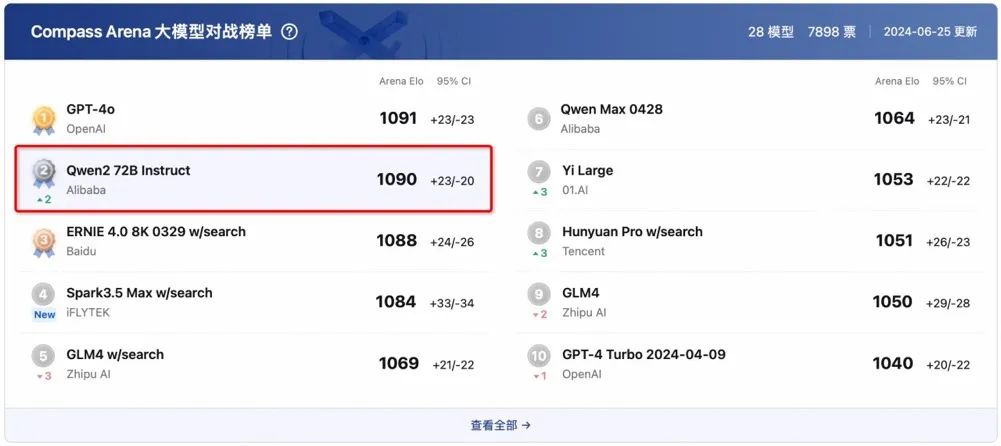
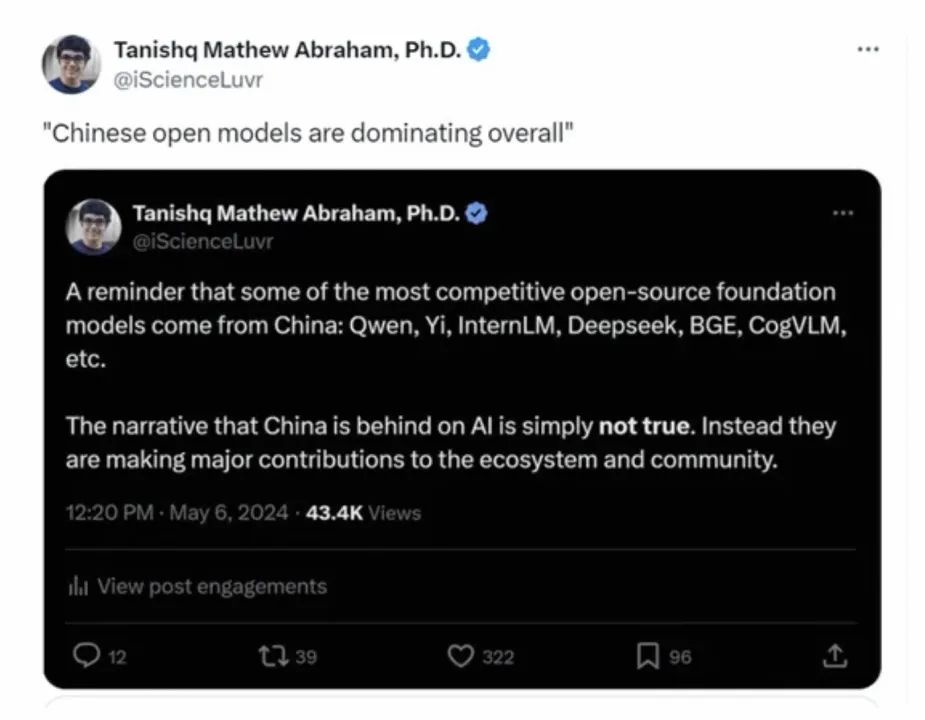
对于排名结果,StabilityAI的研究总监Tanishq表示,他们一直认为中国在开源大模型领域非常有竞争力,并坚信自己处于领导者地位。他认为那些说中国处于落后状态的说法简直可笑。
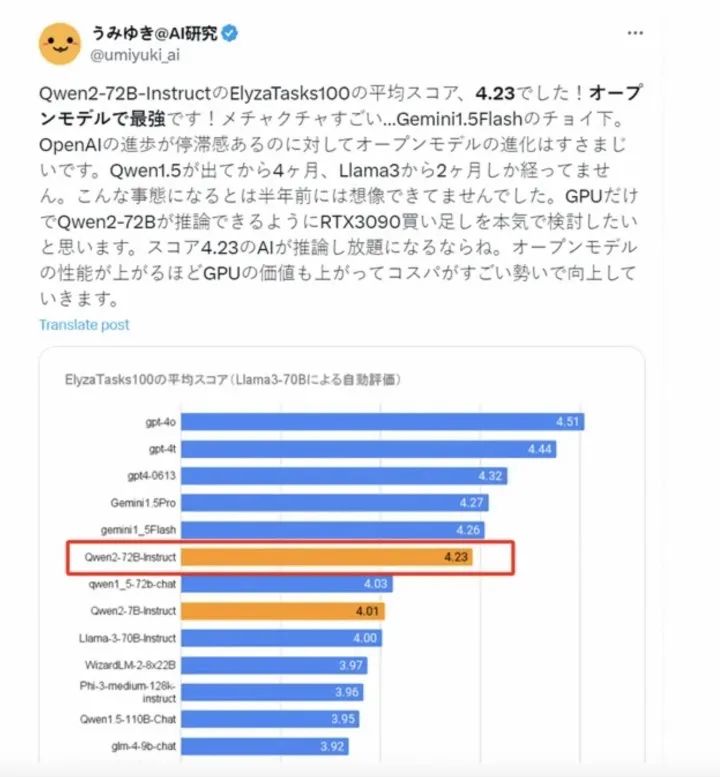
之前也有海外开发者发布过ElyzaTasks100的性能评测,其中Qwen2-72B的指令微调版本被证实是性能最高的开源大模型之一,在性能上仅次于OpenAI的GPT-4o,并超过了谷歌的Gemini1.5Pro。这表明Qwen2-72B的指令微调版本在开源大模型领域具备出色的性能和表现。
在美国对我们AI各方面不断打压,禁用的情况下,国产AI大模型仍能有今天的成绩,实属不易,希望能越来越好。
好了,对于国产开源大模型,大家有什么看法呢?欢迎在评论区留言。

