
- 1【 香橙派 AIpro评测】烧系统运行部署LLMS大模型跑开源yolov5物体检测并体验Jupyter Lab AI 应用样例(新手入门)
- 2linux的重要知识点_linux中的重要知识点
- 3深度学习:05 卷积神经网络介绍(CNN)_tride 池化
- 4sequoiadb java使用_Java开发基础_Java驱动_开发_JSON实例_文档中心_SequoiaDB巨杉数据库...
- 5AI时代,人工智能是开发者的助手还是替代者?
- 6大模型之SORA技术学习_sora模型csdn
- 7风险评估:IIS的安全配置,IIS安全基线检查加固
- 8pytorch之torch基础学习_torch 学习
- 9heic图片转换_heic-convert
- 10SpringCloud实战【九】: SpringCloud服务间调用_springcloud服务与服务之间的调用
stable diffusion学习笔记——文生图(一)_stablediffusion正向词和反向词的区分
赞
踩
模型设置

基本模型
基本模型也就是常说的checkpoint(大模型),基本模型决定了生成图片的主体风格。

如上图所示,基本模型的后缀为.safetensors。需要存放在特定的文件夹下。
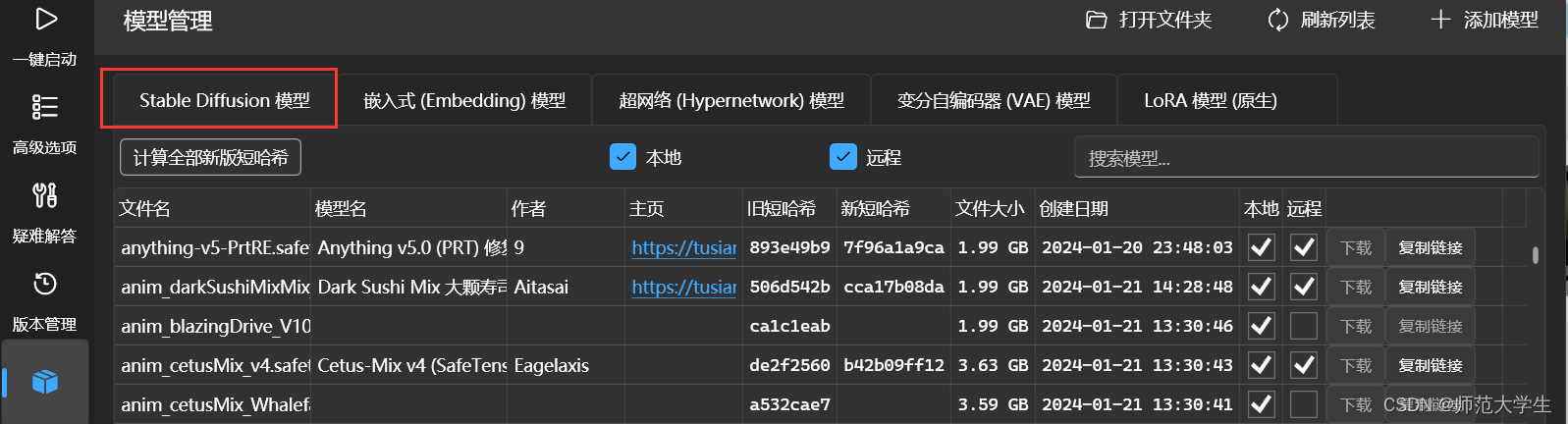
如果用的是启动器,可以在启动器内直接下载。
vae模型
vae模型的全名叫变分自编码器,这里先不讲解原理。在AI绘图中主要的作用是起到画面滤镜的效果。目前较多的大模型都是自带vae的,因此这里不需要额外设置,修改成NONE即可。
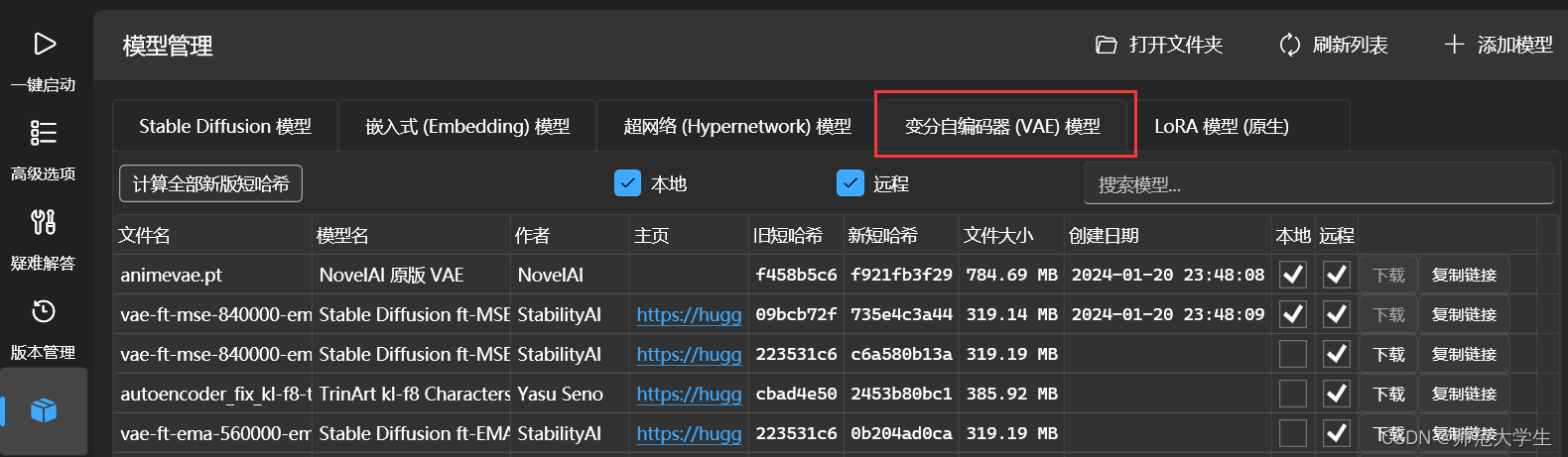
在启动器中也可以直接下载。如果生成画面的饱和度看起来不太正常,可以检查下是不是使用了不合适的vae模型。
终止层数
可以将stable diffusion看做一个扩散模型,终止层数就是指到倒数第几层停止。
终止层数设置的很小,提示词的体现在画面中就更多,但是运算时间会增加;反之,终止层数设置的较大,会导致处理提前停止,丢失的提示词信息会更多,运算时间会相应的减少。
通常这个值默认为2,即倒数第二层的时候停止处理,我们通常不需要修改这个值。
提示词书写
stable diffusion通过提示词来控制图像中应当出现以及不应当出现的元素。
正向提示词
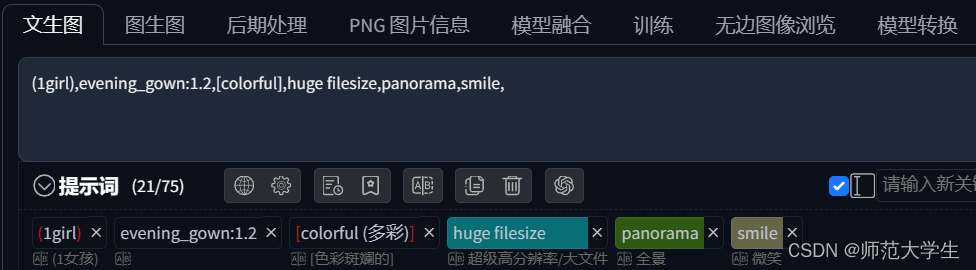
正向提示词用于描述图片想要表现出的内容。正向提示词的语法如下:
- (1girl):权重为1.1倍
- ((1girl)):权重为1.1*1.1 = 1.21倍
- evening_gown:1.2:权重为1.2倍
- [colorful]:权重为0.9倍
提示词权重越高,在画面中出现的概率越大。
反向提示词
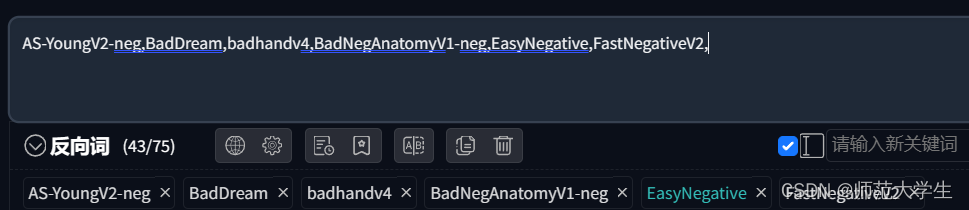
反向提示词主要作用是抑制图像中的元素。提示词的语法与正向提示词相同。
图片生成
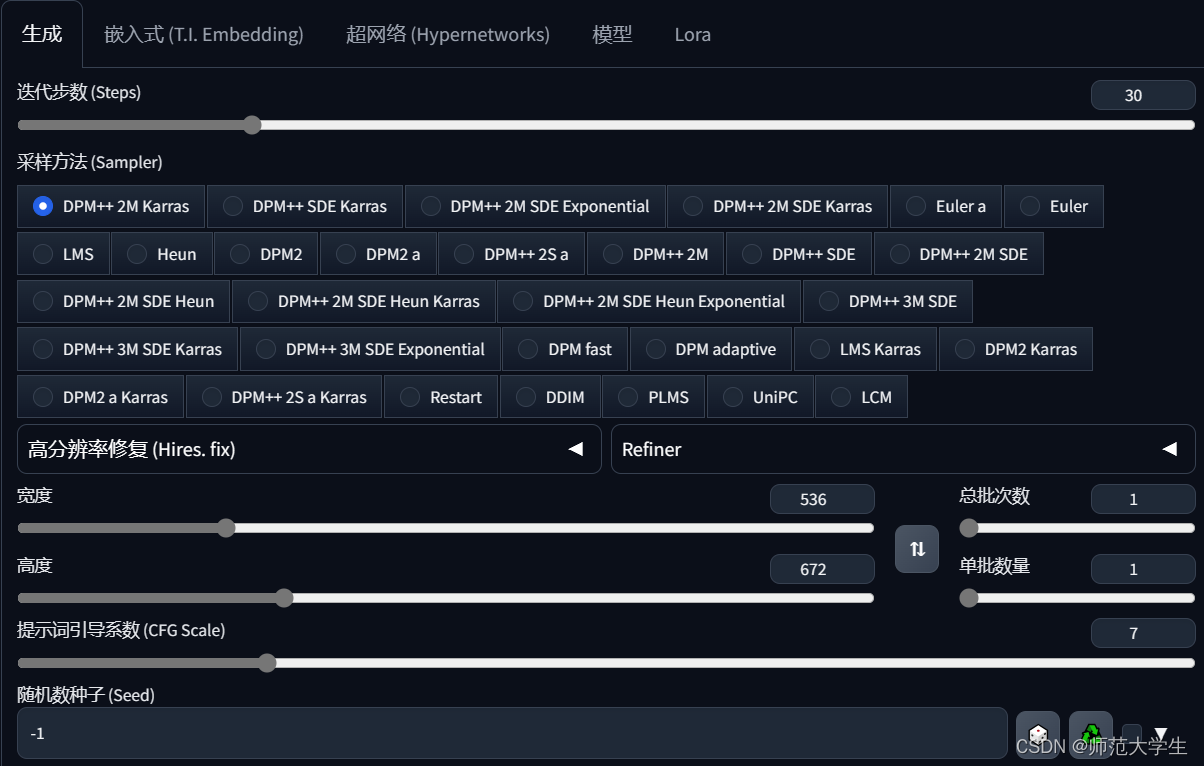
图片生成部分涉及的配置较多。
采样方法与迭代步数
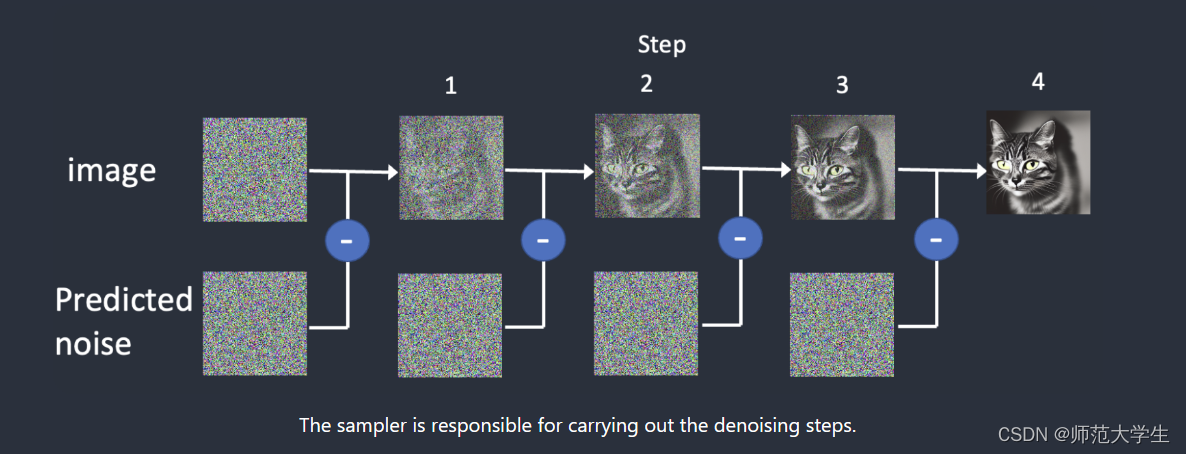
采样的原理可以参考官网:Stable Diffusion Samplers: A Comprehensive Guide - Stable Diffusion Art (stable-diffusion-art.com)
简单讲,stable diffusion会随机生成一个充满噪声点的原始图像,随后一步步迭代去除噪声,最终得到一张清晰的图片。
在这个过程中,去噪的执行步数就是迭代步数;去噪的方式就是采样方法。
显然,迭代步数过低会导致画面不清晰;而迭代步数过高也会增加处理时间。通常迭代步数在20步之后画面的变化就不明显了。因此迭代步数设置为20即可。
采样方法涉及到较多的数学原理,刚上手的话可以参考如下结论:
- 如果你想使用快速且质量不错的东西,那么最好的选择是DPM++2M Karras,UniPC
- 如果你想要高质量的图像并且不关心收敛,那么不错的选择是DPM++SDE Karras
- 如果你喜欢稳定、可重复的图像,请避免使用任何ancestral samplers(后缀加a的采样器)。
- 如果你喜欢简单的东西,Euler和Heun是不错的选择
图片尺寸
设置图片尺寸受以下因素影响:
- 显卡的显存大小。图片的尺寸(分辨率)设置过大会导致爆显存,无法生成图片。
- 大模型设置时训练图片的大小。很多大模型是用分辨率不高的图片训练的,这样的模型生成图片时尽量不要把图片尺寸设置的过大;部分模型使用分辨率高的图片训练(通常发布网站上会有说明),这样的模型生成图片时要将图片尺寸设置大一些,不然会很影响出图效果。
- 预期的构图。如果预期得到一张人物的全身图,适当减少图片尺寸的宽高比会有较好的表现。
同样比例的图片精度不等于放大后为同样比例的图片精度。比如原本尺寸为1024*1024的图片精度不如512*512经过放大算法放大至1024*1024的图片精度,这是因为“改善总是比创造更容易的”,1024*1024会和原来一样生成瑕疵,但重绘是将这些瑕疵渐渐减少。
综上,大部分生成图片的case中,应当以小分辨率生成图片,再用高分辨率修复生成更加高清的图片。
引导系数
引导系数用于控制模型应尊重你的提示的程度。如果CFG值太低,稳定扩散将忽略你的提示。太高时图像的颜色会饱和。
通常设置在4-10之间,可以先用默认值7观察下效果。
种子
种子控制图像的内容。生成的每个图像都有自己的种子值。如果设置为-1,stable diffusion将使用随机种子值;如果设置为一个固定的种子值(比如用那个绿色的回收图标定为之前的图片样式),你可以增加或替换关键词达到在图片上增加或替换的效果。
简单讲,如果想要每次生成一张完全随机的图片,应当把种子设置为-1。如果想要一定程度上复制某张图片,应当将该图片的种子设置为当前种子值。

