
- 1Unity开发——UGUI优化之图集的生成与运用_unity 创建图集
- 2基于javaweb jsp ssm电子竞技管理平台的设计与实现(源码+lw+部署文档+讲解等)
- 3按照CIS-Tomcat7最新基线标准进行中间件层面基线检测_cis安全标准 tomcat
- 4探索生成式AI的未来:Chat与Agent的较量与融合_aigc和agent的区别
- 5Linux中环境变量_linux环境变量是什么
- 64.UE数字人工程运行逻辑及程序逻辑_ue5 humen数字人及接口通信示例
- 7Hadoop入门学习笔记——五、在虚拟机中部署Hive_hive可以单独安装到一台虚拟机吗
- 8安装win11后电脑发热,升级win11电脑发热怎么办_win11升级后电脑发热
- 9对话系统中自然语言理解NLU——意图识别与槽位填充_意图识别,槽位抽取,nl2sql,语言大模型基本能力,rag
- 10在小公司做开发太难了!面试面到我心态爆炸..._进了家小公司,伦不到我开发
第23步 机器学习分类实战:决策树(DT)建模_dt模型
赞
踩
前言
假装有
一、Python调参
(1)建模前的准备
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(2)DT的重要参数
(A)首先,复习一下参数有啥(传送门),一共有12个,这种参数比较多的,我习惯先用默认的跑一次,看看效果如何:
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(random_state = 0)
classifier.fit(X_train, y_train)
- 1
- 2
- 3
看结果,妥妥的过拟合:
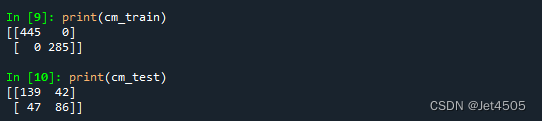
(B)所以,要尝试纠正过拟合问题,DT提供一些参数来优化过拟合问题:
(a)max_depth:限制树的最大深度,一般10-100之间。
(b)min_samples_leaf:默认1,一般数据非常多的情况下可以设置5左右。
(c)min_samples_split:默认2,一般数据非常多的情况下可以设置5-10。
(d)min_impurity_decrease:默认0.0,参数适当的设置也可能减小过拟合,我一般不优先调,选默认。
我们可以先试试,看是否调得动:
classifier = DecisionTreeClassifier(max_depth=50, min_samples_split=5, min_samples_leaf=5, random_state = 0)
- 1
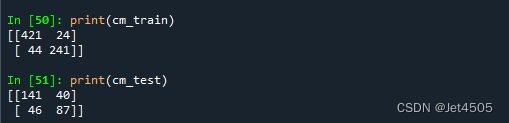
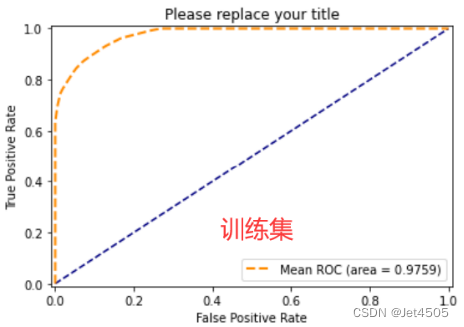
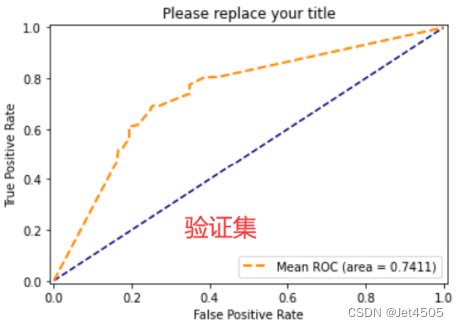
似乎还不错,然后我们在介绍下其他参数:
(a)criterion:绝大多数情况下默认gini系数就对了,不用动,效果甚微;
(b)splitter:两种选择,best或者random;看大佬总结:“实际分类任务设置时默认best就行,毕竟random生成的树实在是过于离谱。如果你想对一个数据集有很多种不同的树模型,又不太关注合理性,可以选择random。”
max_features:特征小于50默认就好;
(d)max_leaf_nodes:特征不多默认就好;
(e)class_weight:默认就好;
(C)所以,用网格搜索(Grid Search)试试:
from sklearn.tree import DecisionTreeClassifier
param_grid=[{
'max_depth':[50,60,70,80,90,100],
'min_samples_split':[i for i in range(5,11)],
'min_samples_leaf':[i for i in range(5,11)],
},
]
boost = DecisionTreeClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 1, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果,一般般:
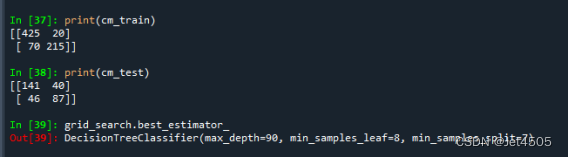
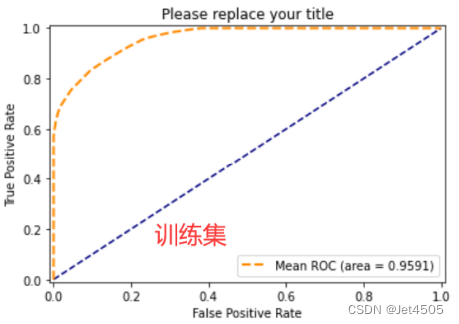
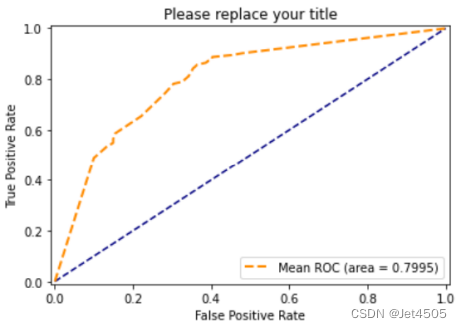
最优参数是:max_depth=90, min_samples_leaf=8, min_samples_split=7。
还可以再调整一下,比如探讨下min_impurity_decrease和criterion:
param_grid=[{
'max_depth':[50,60,70,80,90,100],
'min_samples_split':[i for i in range(5,11)],
'min_samples_leaf':[i for i in range(5,11)],
'min_impurity_decrease':[0.0,0.1,0.3,0.5,0.8,1.0],
'criterion':['gini','entropy'],
},
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
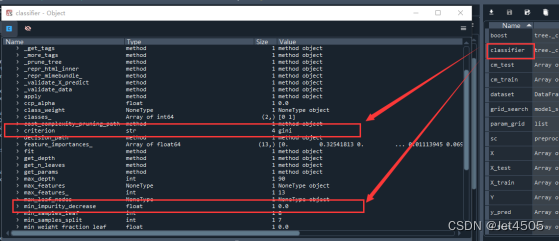
min_impurity_decrease和criterion依旧是默认的好,可以点击classifier查看模型其他参数:
再探讨下max_leaf_nodes和ccp_alphanon-negative,一个一个试,看看是否有变化。比如先来,max_leaf_nodes,节点减少一点,来个50吧
classifier = DecisionTreeClassifier(max_depth=90, min_samples_split=8, min_samples_leaf=7, max_leaf_nodes=50, random_state = 0)
- 1
训练集AUC升高到0.9644,验证集也下降到0.7776,无趣;再看ccp_alphanon-negative,一般是手动调节alpha,从0开始,一点一点增大,0.001到0.1,具体根据经验选个合适的:
classifier = DecisionTreeClassifier(max_depth=90, min_samples_split=8, min_samples_leaf=7, ccp_alpha=0.001, random_state = 0)
- 1
训练集AUC下降到0.9602,验证集也下降到0.7584,再调大0.1:
classifier = DecisionTreeClassifier(max_depth=50, min_samples_split=5, min_samples_leaf=5, ccp_alpha=0.01, random_state = 0)
- 1
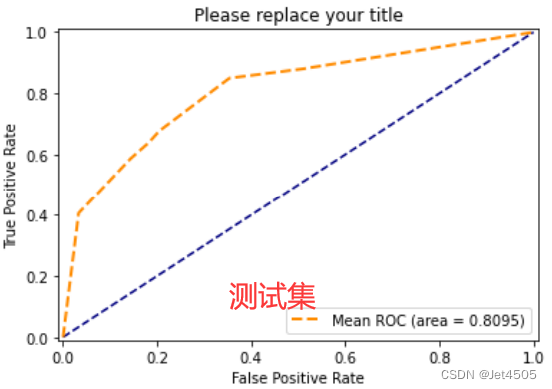
哟呵,调过了,训练集AUC是0.8757,验证集到0.8095,那就用网格:
param_grid=[{
'max_depth':[50,60,70,80,90,100],
'min_samples_split':[i for i in range(5,11)],
'min_samples_leaf':[i for i in range(5,11)],
'max_leaf_nodes':[50,80,100,150,200],
'ccp_alpha':[0.0,0.01,0.1,0.5,0.8,1.0],
},
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
看结果,基本可以了,反正我不想再调了:
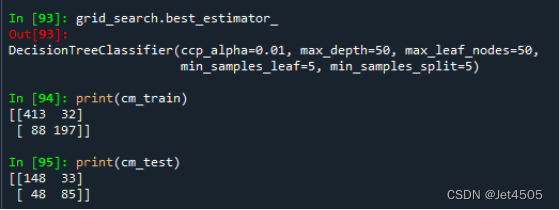
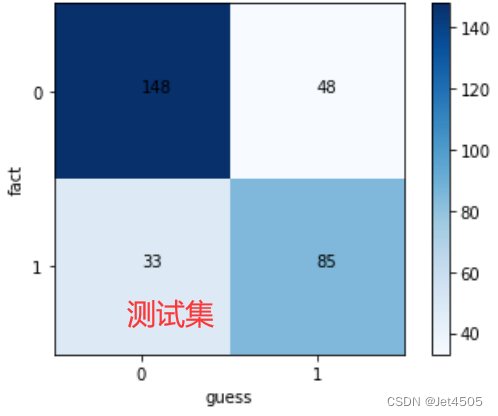
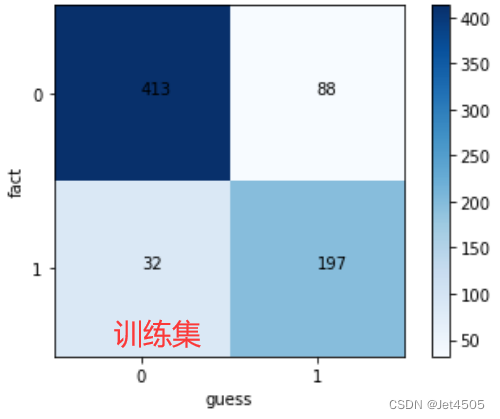
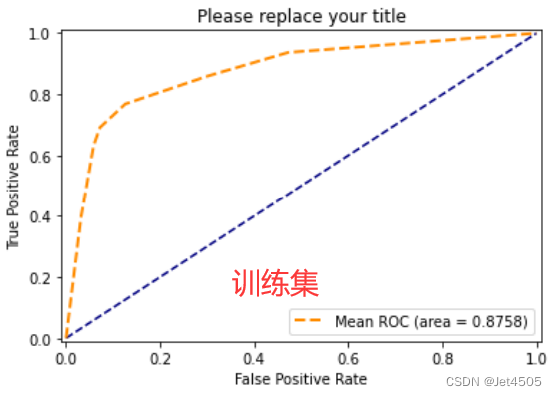
二、SPSSPRO调参
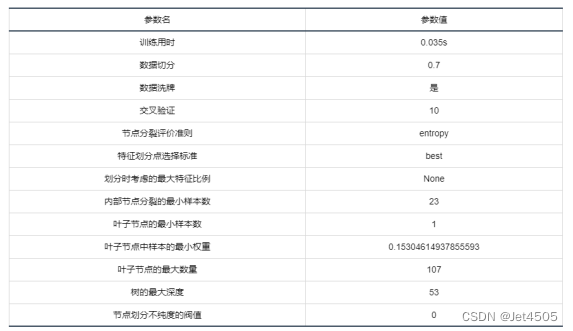
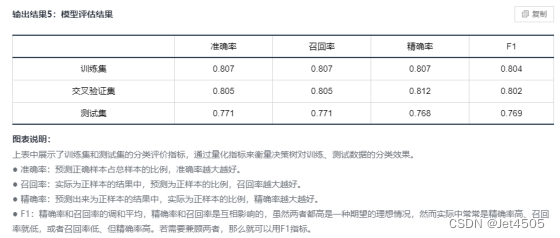
这回SPSSPRO的性能要比python的要好,有没有很好奇?那我们用SPSSPRO的参数来python试一试:
classifier = DecisionTreeClassifier(max_depth=53, min_samples_split=23, min_samples_leaf=1, min_weight_fraction_leaf=0.153, max_leaf_nodes=107, random_state = 0)
- 1
然后看看结果:

居然不一样,有没有很困惑呢?
其实,我之前也说过,别忘了这个东西的重要性random_state!!!
SPSSPRO是没有这个设置函数的,所以不能保证它的训练集和验证集跟我们做pyhton是一样的,那就没有可比性。
当然,可以从random_state入手,随机生成N个训练集和验证集,构建N个模型,然后看看整体的性能情况,这个后面我再介绍。
总结
懒!

