
- 1Golang中读写锁的底层实现
- 2在 Linux 上使用 lspci 命令查看 PCI 总线硬件设备信息_怎样查看pci设备的设备功能号
- 3sequoiadb java使用_Java开发基础_Java驱动_开发_JSON实例_文档中心_SequoiaDB巨杉数据库...
- 4python安装缺失_python: 自动安装缺失库文件的方法
- 5【边缘检测】基于matlab八方向sobel图像边缘检测【含Matlab源码 1865期】_matlab sobel
- 6OpenAI回应马斯克诉讼:其因个人恩怨而起诉;苹果硬件工程灵魂人物Dan Riccio将退休;AI网络蠕虫被曝光| 极客头条...
- 7助力制造企业降本增效,生成式AI技术大有可为
- 8MYSQL数据库第七次作业---视图_数据库视图的创建含分组和排序
- 9完美解决 studio sdk tools 缺失下载选项问题_mac android-sdk 缺少 tools
- 10windows下编译tensorflow Faster RCNN的lib/Makefile
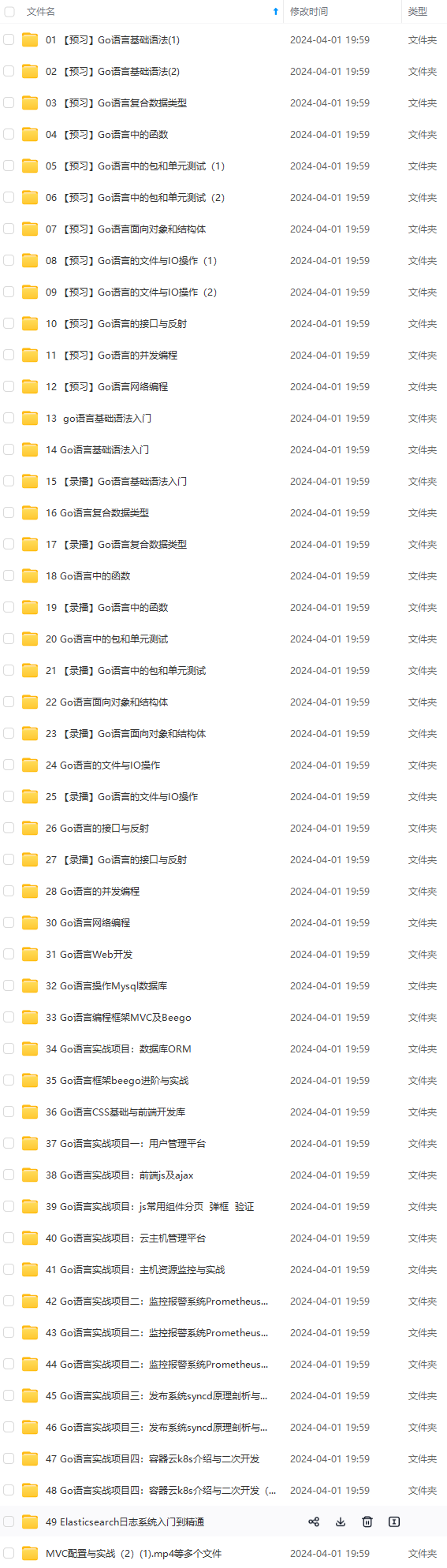
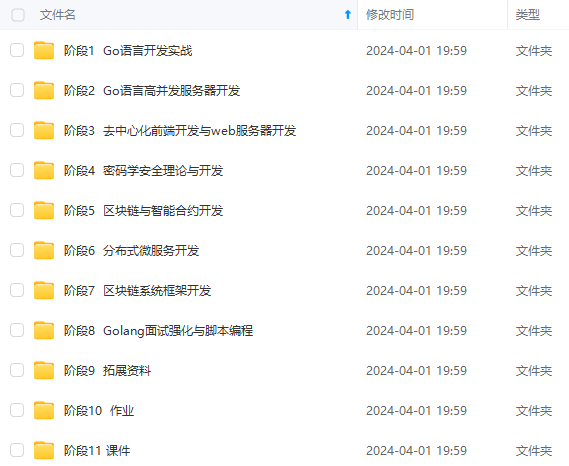
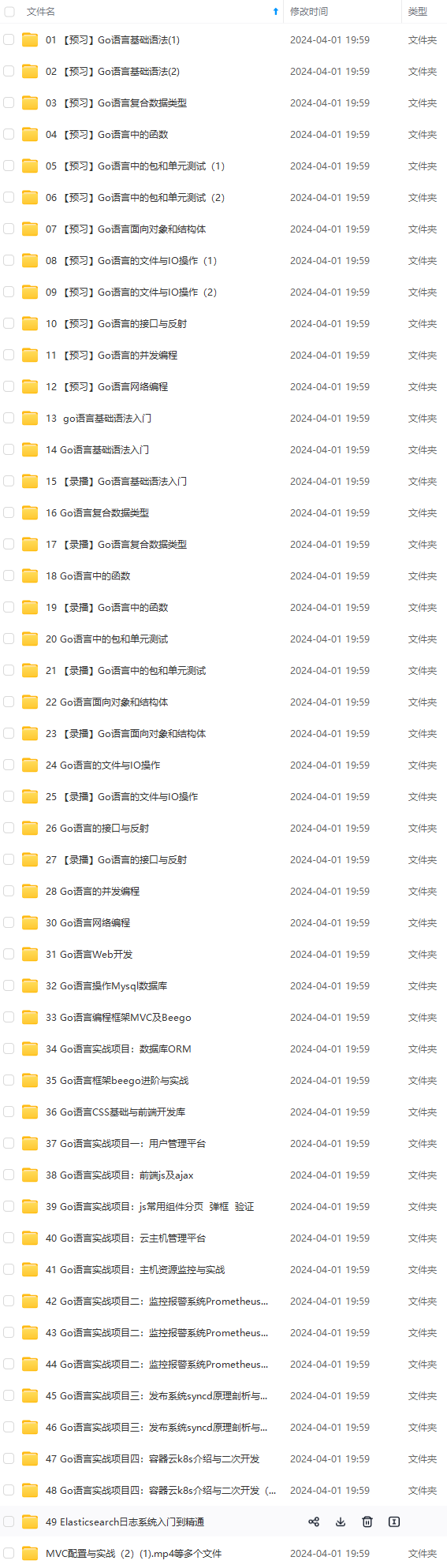
2024年最全最新golang语言面试题总结(一)_golang面试题(1),2024年最新2024Golang大厂面试知识分享_golang面试题2024
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Channel是Go中的一个核心类型,可以把它看成一个管道,通过它并发核心单元就可以发送或者接收数据进行通讯(communication),Channel也可以理解是一个先进先出的队列,通过管道进行通信。
Golang的Channel,发送一个数据到Channel 和 从Channel接收一个数据 都是 原子性的。而且Go的设计思想就是:不要通过共享内存来通信,而是通过通信来共享内存,前者就是传统的加锁,后者就是Channel。也就是说,设计Channel的主要目的就是在多任务间传递数据的,这当然是安全的
11、说一下map是有序的吗?如何实现有序
1、由于golang map内部存储机制是以key为hash的结构来实现,所以顺序是混乱的
2、如果希望是有顺序的,可以把 key 转移至 slice,将slice 进行排序,然后输出。
var keys []string for key := range maps { keys = append(keys, key) } sort.Strings(keys) //内值排序 for _, key := range keys { fmt.Printf("%s:%v\n", key, maps[key]) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

12、如下程序添加一段代码让程序不报panic异常。
func test() { //添加一段程序捕获panic异常 } func main() { defer test() panic(1) } 答案: func test() { //添加一段程序捕获panic异常 recover() } func main() { defer test() panic(1) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
13、使用go语言将数组中12300045变成12345000
func MobileNnm(arr []int) []int { arr2 := make([]int, 0) oneCount := 0 for _, v := range arr { if v == 0 { oneCount++ } else { arr2 = append(arr2, v) } } for i := 0; i < oneCount; i++ { arr2 = append(arr2, 0) } return arr2 } func main() { //使用go语言将12300045变成12345000 val1 := []int{1, 2, 3, 0, 0, 0, 4, 5} val2 := MobileNnm(val1) fmt.Println(val2) } 结果:[1 2 3 4 5 0 0 0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
14、算法题
题目:1、(( 结果是false 2、(())() 是true 3、((()))())是false 用go实现 思路:压栈找到匹配的出栈,找不到还放入栈中,直到栈为空,代表都匹配上了。 代码如下:(仅供参考) func main() { //题目:1、(( 结果是false //2、(())() true //3、((()))())false 用go实现 s0 := []string{"(", "("} fmt.Println(IsMatch(s0))//false s1 := []string{"(", "(", ")", ")", "(", ")"} fmt.Println(IsMatch(s1)) //true s2 := []string{"(", "(", ")", ")", "(", ")", ")"} fmt.Println(IsMatch(s2))//false } func IsMatch(str []string) bool { //压栈的思想 if len(str) == 0 { return false } stack := NewStack() for _, v := range str { if stack.IsEmpty() { stack.Push(v) } else { sp := stack.Pop() if sp == "(" && string(v) == ")" { continue } else { stack.Push(sp) stack.Push(v) } } } if stack.IsEmpty() { return true } return false } type Element interface{} //可存入任何类型 type Stack struct { list []Element } //初始化栈 func NewStack() *Stack { return &Stack{ list: make([]Element, 0), } } //判断栈是否空 func (s *Stack) IsEmpty() bool { if len(s.list) == 0 { return true } else { return false } } //入栈 func (s *Stack) Push(x interface{}) { s.list = append(s.list, x) } //出栈 func (s *Stack) Pop() Element { if len(s.list) <= 0 { fmt.Println("Stack is Empty") return nil } else { ret := s.list[len(s.list)-1] s.list = s.list[:len(s.list)-1] return ret } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
15、算法题
题目:上楼梯有一阶和两阶 例如3层楼梯有如下种 1 2 1 1 1 2 1 n阶有多少种: 代码如下:(仅供参考) func main() { n := Upstairs(3) fmt.Println(n) } var mapData = make(map[int]int, 0) func Upstairs(n int) int { if n == 1 { return 1 } if n == 2 { return 2 } if _, ok := mapData[n]; !ok { mapData[n] = Upstairs(n-1) + Upstairs(n-2) } return mapData[n] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
16、用go实现单链表的反转
题目:单链表12345678910反转成10987654321 代码如下:(仅供参考) func main() { //实现单链表的反转例如12345678910变成10987654321 var head = new(ListNode) CreateNode(head, 10) PrintNode("前:", head) yyy := reverseList(head) PrintNode("后:", yyy) } type ListNode struct { data interface{} next *ListNode } func reverseList(head *ListNode) *ListNode { cur := head var pre *ListNode for cur != nil { cur.next, pre, cur = pre, cur, cur.next } return pre } func CreateNode(node *ListNode, max int) { cur := node for i := 1; i <= max; i++ { cur.next = &ListNode{} cur.data = i cur = cur.next } } //打印链表的方法 func PrintNode(str string, node *ListNode) { fmt.Print(str) for cur := node; cur != nil; cur = cur.next { if cur.data != nil { fmt.Print(cur.data, " ") } } fmt.Println() } 结果: 前:1 2 3 4 5 6 7 8 9 10 后:10 9 8 7 6 5 4 3 2 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
17、算法题(在线求答案)
题目: 输入文件构成规则如下: 1. 每行代表一条记录,字段之间以逗号(,)分隔 2. 若字段内容包含逗号(,),则以双引号包围该字段 3. 若字段内容包含双引号("),则以双引号包围该字段,字段内的双引号由一个变两个 请参照上面三条规则,编写一个解析程序,将解析后的记录内容按行输出,字段之间以TAB(\t)分隔,2小时内完成 示例: John,33,"足球,摄影",New York John,33,"足球,""摄影",New York 输出: John 33 足球,摄影 New York John 33 足球,"摄影 New York 输入: 2,John,45,"足球,摄影",New York 3,Carter Job,33,"""健身"",远足","河北,石家庄" 4,Steve,33,"大屏幕164""","DC""Home""" 5,"Jul,y",33,Football,Canada 求输出!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
package main import ( "bufio" "fmt" "os" "strings" ) func parseRecord(line string) string { var fields []string var inQuote bool var field string for i := 0; i < len(line); i++ { c := line[i] if c == ',' && !inQuote { fields = append(fields, field) field = "" } else if c == '"' { inQuote = !inQuote if i > 0 && line[i-1] == '"' { field += "\"" } } else { field += string(c) } } fields = append(fields, field) return strings.Join(fields, "\t") } func main() { scanner := bufio.NewScanner(os.Stdin) for scanner.Scan() { line := scanner.Text() fmt.Println(parseRecord(line)) } if err := scanner.Err(); err != nil { fmt.Fprintln(os.Stderr, "reading standard input:", err) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
18、slice和map区别代码输出题
题目一: func main() { s1 := []int{1, 2, 3, 4, 5} changeslice(s1) fmt.Println(s1)//?s1的结果会变化吗? fmt.Println(len(s1), cap(s1))//?s1长度和容量会变化吗? m1 := map[int]int{1: 1, 2: 2, 3: 3, 4: 4} changeMap(m1) fmt.Println(m1) //?m1中key等于1的值会变化吗? fmt.Println(len(m1))//?m1长度和容量会变化吗? } func changeslice(s []int) { s[0] = 2 s = append(s, 7, 8, 9, 10) } func changeMap(m map[int]int) { m[1] = 2 m[5] = 5 m[6] = 6 } 答案:s1的值会变化,但是长度和容量不会变化。m1的值会变化,长度会变化。 切记: map 没有容量限制,所以内置函数 cap 也不接受 map 类型 题目二: func main() { m := make(map[int]int) mdMap(m) fmt.Println(m) //输出结果 } func mdMap(m map[int]int) { m[1] = 100 m[2] = 200 } --------------------------------- func main() { var m1 map[int]int mdMap(m1) fmt.Println(m1)//输出的结果 } func mdMap(m map[int]int) { m = make(map[int]int) m[1] = 100 m[2] = 200 } 答案:m结果map[2:200 1:100] m1的结果map[]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
19、mysql有那几种存储引擎
MyISAM:
创建一个myisam存储引擎的表的时候回出现三个文件
1.tb_demo.frm,存储表定义; 2.tb_demo.MYD,存储数据; 3.tb_demo.MYI,存储索引。
MyISAM表无法处理事务,这就意味着有事务处理需求的表,不能使用MyISAM存储引擎。
MyISAM存储引擎特别适合在以下几种情况下使用:
1.选择密集型的表。MyISAM存储引擎在筛选大量数据时非常迅速,这是它最突出的优点。
2.插入密集型的表。MyISAM的并发插入特性允许同时选择和插入数据。例如:MyISAM存储引擎很适合管理邮件或Web服务器日志数据。
InnoDB:
InnoDB是一个健壮的事务型存储引擎MySQL 5.6.版本以后InnoDB就是作为默认的存储引擎。
InnoDB还引入了行级锁定和外键约束,在以下场合下,使用InnoDB是最理想的选择:
- 更新密集的表。InnoDB存储引擎特别适合处理多重并发的更新请求。
2.事务。InnoDB存储引擎是支持事务的标准MySQL存储引擎。
3.自动灾难恢复。与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
4.外键约束。MySQL支持外键的存储引擎只有InnoDB。
5.支持自动增加列AUTO_INCREMENT属性。
MEMORY:
使用MySQL Memory存储引擎的出发点是速度。为得到最快的响应时间,采用的逻辑存储介质是系统内存。虽然在内存中存储表数据确实会提供很高的性能,但当mysqld守护进程崩溃时,所有的Memory数据都会丢失。获得速度的同时也带来了一些缺陷。它要求存储在Memory数据表里的数据使用的是长度不变的格式,这意味着不能使用BLOB和TEXT这样的长度可变的数据类型,VARCHAR是一种长度可变的类型,但因为它在MySQL内部当做长度固定不变的CHAR类型,所以可以使用。
一般在以下几种情况下使用Memory存储引擎:
1.目标数据较小,而且被非常频繁地访问。在内存中存放数据,所以会造成内存的使用,可以通过参数max_heap_table_size控制Memory表的大小,设置此参数,就可以限制Memory表的最大大小。
2.如果数据是临时的,而且要求必须立即可用,那么就可以存放在内存表中。
3.存储在Memory表中的数据如果突然丢失,不会对应用服务产生实质的负面影响。Memory同时支持散列索引和B树索引。B树索引的优于散列索引的是,可以使用部分查询和通配查询,也可以使用<、>和>=等操作符方便数据挖掘。散列索引进行“相等比较”非常快,但是对“范围比较”的速度就慢多了,因此散列索引值适合使用在=和<>的操作符中,不适合在<或>操作符中,也同样不适合用在order by子句中
MERGE:
MERGE存储引擎是一组MyISAM表的组合,这些MyISAM表结构必须完全相同,尽管其使用不如其它引擎突出,但是在某些情况下非常有用。说白了,Merge表就是几个相同MyISAM表的聚合器;Merge表中并没有数据,对Merge类型的表可以进行查询、更新、删除操作,这些操作实际上是对内部的MyISAM表进行操作。Merge存储引擎的使用场景。对于服务器日志这种信息,一般常用的存储策略是将数据分成很多表,每个名称与特定的时间端相关。例如:可以用12个相同的表来存储服务器日志数据,每个表用对应各个月份的名字来命名。当有必要基于所有12个日志表的数据来生成报表,这意味着需要编写并更新多表查询,以反映这些表中的信息。与其编写这些可能出现错误的查询,不如将这些表合并起来使用一条查询,之后再删除Merge表,而不影响原来的数据,删除Merge表只是删除Merge表的定义,对内部的表没有任何影响。
ARCHIVE:
rchive是归档的意思,在归档之后很多的高级功能就不再支持了,仅仅支持最基本的插入和查询两种功能。在MySQL 5.5版以前,Archive是不支持索引,但是在MySQL 5.5以后的版本中就开始支持索引了。Archive拥有很好的压缩机制,它使用zlib压缩库,在记录被请求时会实时压缩,所以它经常被用来当做仓库使用。
20、mysql中事务隔离级别有哪几种
- 读未提交(READ UNCOMITTED)
- 读提交(READ COMMITTED)
- 可重复读(REPEATABLE READ)
- 串行化(SERIALIZABLE)
- | 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| — | — | — | — |
| READ UNCOMITTED | √ | √ | √ |
| READ COMMITTED | × | √ | √ |
| REPEATABLE READ | × | × | √ |
| SERIALIZABLE | × | × | × |mysql数据库事务的隔离级别有4个,而默认的事务处理级别就是【REPEATABLE-READ】,也就是可重复读
21、 B树、B+tree、Hash有什么区别
B树是一种多路自平衡搜索树,它类似普通的二叉树,但是B书允许每个节点有更多的子节点。B树示意图如下:
B树的特点:
- 所有键值分布在整个树中
- 任何关键字出现且只出现在一个节点中
- 搜索有可能在非叶子节点结束
- 在关键字全集内做一次查找,性能逼近二分查找算法
- 树深度会很深,因为树顶放到元素比较少导致,检索元素比较慢。
缺点:
业务数据的大小可能远远超过了索引数据的大小,每次为了查找对比计算,需要把数据加载到内存以及 CPU 高速缓存中时,都要把索引数据和无关的业务数据全部查出来。本来一次就可以把所有索引数据加载进来,现在却要多次才能加载完。如果所对比的节点不是所查的数据,那么这些加载进内存的业务数据就毫无用处,全部抛弃。
B+Tree:
从图中也可以看到,B+树与B树的不同在于:
- 所有关键字存储在叶子节点,非叶子节点不存储真正的data
- 为所有叶子节点增加了一个链指针
- 树顶可以放很多元素,树的深度比较矮,检索元素比较快。
缺点:
仍然有一个致命的缺陷,那就是它的索引数据与业务绑定在一块,而业务数据的大小很有可能远远超过了索引数据,这会大大减小一次 I/O 有用数据的获取,间接的增加 I/O 次数去获取有用的索引数据
Hash:
特点:数组+链表
1、查询单条数据很快,先解析出hash值,根据hash找到链表,然后找到索引最后根据索引找到数据。
缺点:
- 容易hash碰撞
- Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询
- 联合索引中,Hash索引不能利用部分索引键查询。
- Hash索引无法避免数据的排序操作
- Hash索引任何时候都不能避免表扫描
- Hash索引遇到大量Hash值相等的情况后性能会下降



22、 Mysql 中 MyISAM 和 InnoDB 的区别有哪些?
- InnoDB支持事务,MyISAM不支持
- 对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
- InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
- InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。
- 但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此主键不应该过大,因为主键太大,其他索引也都会很大。
- 而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
- Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高
23、 go向关闭的channel发送和读取数据是否报错
package main import "fmt" //向已关闭的通道读取数不会报错 func main1() { var ch = make(chan int) go func() { close(ch) }() fmt.Println(<-ch) } //向已关闭的通道发送数据报panic: send on closed channel func main2() { var ch = make(chan int) go func() { close(ch) }() ch <- 1 } //关闭通道向有缓存区接收数据会报错 func main3() { var ch = make(chan int, 10) go func() { close(ch) }() fmt.Println(<-ch) } //关闭通道向有缓冲区发送数据会报错panic:send on closed channel func main4() { var ch = make(chan int, 10) go func() { close(ch) }() ch <- 1 } //关闭通道向有缓冲区循环发送数据会报错 panic: send on closed channel func main() { var ch = make(chan int, 10) go func() { close(ch) }() for { ch <- 1 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
24、Golang并发模型有几种
控制并发有三种种经典的方式,一种是通过channel通知实现并发控制 一种是WaitGroup,另外一种就是Context。
1、无缓冲通道
无缓冲的通道指的是通道的大小为0,也就是说,这种类型的通道在接收前没有能力保存任何值,它要求发送
goroutine和接收goroutine同时准备好,才可以完成发送和接收操作。从上面无缓冲的通道定义来看,发送
goroutine和接收gouroutine必须是同步的,同时准备后,如果没有同时准备好的话,先执行的操作就会阻塞等待,直到另一个相对应的操作准备好为止。这种无缓冲的通道我们也称之为同步通道。正式通过无缓冲通道来实现多
goroutine并发控制func main() { ch := make(chan instruct{}) go func() { ch <- struct{}{} }() fmt.Println(<-ch) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
当主
goroutine运行到<-ch接受channel的值的时候,如果该channel中没有数据,就会一直阻塞等待,直到有值。 这样就可以简单实现并发控制2. 通过sync包中的WaitGroup实现并发控制
在
sync包中,提供了WaitGroup,它会等待它收集的所有goroutine任务全部完成,在主goroutine中Add(delta int)索要等待goroutine的数量。在每一个goroutine完成后Done()表示这一个goroutine已经完成,当所有的goroutine都完成后,在主goroutine中WaitGroup返回返回。func main() { var wg sync.WaitGroup // 开N个后台打印线程 for i := 0; i < 10; i++ { wg.Add(1) go func() { fmt.Println("你好, 世界") wg.Done() }() } // 等待N个后台线程完成 wg.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3. 在Go 1.7 以后引进的强大的Context上下文,实现并发控制
3.1 简介
在一些简单场景下使用
channel和WaitGroup已经足够了,但是当面临一些复杂多变的网络并发场景下channel和WaitGroup显得有些力不从心了。比如一个网络请求Request,每个Request都需要开启一个goroutine做一些事情,这些goroutine又可能会开启其他的goroutine,比如数据库和RPC服务。所以我们需要一种可以跟踪goroutine的方案,才可以达到控制他们的目的,这就是Go语言为我们提供的Context,称之为上下文非常贴切,它就是goroutine的上下文。它是包括一个程序的运行环境、现场和快照等。每个程序要运行时,都需要知道当前程序的运行状态,通常Go 将这些封装在一个Context里,再将它传给要执行的goroutine。context包主要是用来处理多个goroutine之间共享数据,及多个goroutine的管理。3.2 package context
context包的核心是struct Context,接口声明如下:// A Context carries a deadline, cancelation signal, and request-scoped values // across API boundaries. Its methods are safe for simultaneous use by multiple // goroutines. type Context interface { // Done returns a channel that is closed when this `Context` is canceled // or times out. Done() <-chan struct{} // Err indicates why this Context was canceled, after the Done channel // is closed. Err() error // Deadline returns the time when this Context will be canceled, if any. Deadline() (deadline time.Time, ok bool) // Value returns the value associated with key or nil if none. Value(key interface{}) interface{} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Done()返回一个只能接受数据的channel类型,当该context关闭或者超时时间到了的时候,该channel就会有一个取消信号Err()在Done()之后,返回context取消的原因。Deadline()设置该context cancel的时间点Value()方法允许Context对象携带request作用域的数据,该数据必须是线程安全的。
Context对象是线程安全的,你可以把一个Context对象传递给任意个数的gorotuine,对它执行 取消 操作时,所有goroutine都会接收到取消信号。一个
Context不能拥有Cancel方法,同时我们也只能Done channel接收数据。
背后的原因是一致的:接收取消信号的函数和发送信号的函数通常不是一个。
一个典型的场景是:父操作为子操作操作启动goroutine,子操作也就不能取消父操作。3.4 context例子
当然,想要知道 Context 包是如何工作的,最好的方法是看一个例子。
func childFunc(cont context.Context, num *int) { ctx, _ := context.WithCancel(cont) for { select { case <-ctx.Done(): fmt.Println("child Done : ", ctx.Err()) return } } } func main() { gen := func(ctx context.Context) <-chan int { dst := make(chan int) n := 1 go func() { for { select { case <-ctx.Done(): fmt.Println("parent Done : ", ctx.Err()) return // returning not to leak the goroutine case dst <- n: n++ go childFunc(ctx, &n) } } }() return dst } ctx, cancel := context.WithCancel(context.Background()) for n := range gen(ctx) { fmt.Println(n) if n >= 5 { break } } cancel() time.Sleep(5 * time.Second) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
在上面的例子中,主要描述的是通过一个
channel实现一个为循环次数为5的循环,
在每一个循环中产生一个goroutine,每一个goroutine中都传入context,在每个goroutine中通过传入ctx创建一个子Context,并且通过select一直监控该Context的运行情况,当在父Context退出的时候,代码中并没有明显调用子Context的Cancel函数,但是分析结果,子Context还是被正确合理的关闭了,这是因为,所有基于这个Context或者衍生的子Context都会收到通知,这时就可以进行清理操作了,最终释放goroutine,这就优雅的解决了goroutine启动后不可控的问题。3.5 Context 使用原则
- 不要把
Context放在结构体中,要以参数的方式传递- 以
Context作为参数的函数方法,应该把Context作为第一个参数,放在第一位。- 给一个函数方法传递
Context的时候,不要传递nil,如果不知道传递什么,就使用context.TODOContext的Value相关方法应该传递必须的数据,不要什么数据都使用这个传递Context是线程安全的,可以放心的在多个goroutine中传递
25、go分布式锁有几种
1 、进程内加锁
想要得到正确的结果的话,要把对计数器(counter)的操作代码部分加上锁: // ... 省略之前部分 var wg sync.WaitGroup var l sync.Mutex for i := 0; i < 1000; i++ { wg.Add(1) go func () { defer wg.Done() l.Lock() counter++ l.Unlock() }() } wg.Wait() println(counter) // ... 省略之后部分 这样就可以稳定地得到计算结果了: ❯❯❯ go run local_lock.go 1000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2、trylock
在某些场景,我们只是希望一个任务有单一的执行者。而不像计数器场景一样,所有goroutine都执行
成功。后来的goroutine在抢锁失败后,需要放弃其流程。这时候就需要trylock了。
trylock顾名思义,尝试加锁,加锁成功执行后续流程,如果加锁失败的话也不会阻塞,而会直接返回
加锁的结果。在Go语言中我们可以用大小为1的Channel来模拟trylock:package main import ( "sync" ) type Lock struct { c chan struct{} } // NewLock generate a try lock func NewLock() Lock { var l Lock l.c = make(chan struct{}, 1) l.c <- struct{}{} return l } // Lock try lock, return lock result func (l Lock) Lock() bool { lockResult := false select { case <-l.c: lockResult = true default: } return lockResult } // Unlock , Unlock the try lock func (l Lock) Unlock() { l.c <- struct{}{} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
因为我们的逻辑限定每个goroutine只有成功执行了 Lock 才会继续执行后续逻辑,因此
在 Unlock 时可以保证Lock结构体中的channel一定是空,从而不会阻塞,也不会失败。上面的代
码使用了大小为1的channel来模拟trylock,理论上还可以使用标准库中的CAS来实现相同的功能且
成本更低,读者可以自行尝试。
在单机系统中,trylock并不是一个好选择。因为大量的goroutine抢锁可能会导致CPU无意义的资源
浪费。有一个专有名词用来描述这种抢锁的场景:活锁。
活锁指的是程序看起来在正常执行,但实际上CPU周期被浪费在抢锁,而非执行任务上,从而程序整体
的执行效率低下。活锁的问题定位起来要麻烦很多。所以在单机场景下,不建议使用这种锁。3、基于Redis的setnx
在分布式场景下,我们也需要这种“抢占”的逻辑,这时候怎么办呢?我们可以使用Redis提供
的 setnx 命令:package main import ( "fmt" "sync" "time" "github.com/go-redis/redis" ) func incr() { client := redis.NewClient(&redis.Options{ Addr: "localhost:6379", Password: "", // no password set DB: 0, // use default DB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
lock,理论上还可以使用标准库中的CAS来实现相同的功能且
成本更低,读者可以自行尝试。
在单机系统中,trylock并不是一个好选择。因为大量的goroutine抢锁可能会导致CPU无意义的资源
浪费。有一个专有名词用来描述这种抢锁的场景:活锁。
活锁指的是程序看起来在正常执行,但实际上CPU周期被浪费在抢锁,而非执行任务上,从而程序整体
的执行效率低下。活锁的问题定位起来要麻烦很多。所以在单机场景下,不建议使用这种锁。3、基于Redis的setnx
在分布式场景下,我们也需要这种“抢占”的逻辑,这时候怎么办呢?我们可以使用Redis提供
的 setnx 命令:package main import ( "fmt" "sync" "time" "github.com/go-redis/redis" ) func incr() { client := redis.NewClient(&redis.Options{ Addr: "localhost:6379", Password: "", // no password set DB: 0, // use default DB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
[外链图片转存中…(img-UOy50P70-1715408234341)]
[外链图片转存中…(img-qiL6ESlv-1715408234341)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

