
- 1Redis客户端之Redisson(二)Redisson组件_redissonclient
- 2Spark数据读取和创建_spark创建sc
- 3使用JMeter进行Apache Kafka负载测试_jmeter kafka
- 4[Python学习日记] 文件与文件系统(一)_python 日记文件系统
- 5华为路由器命令配置大全,看完赶快收藏_华为路由器配置常用命令
- 6前端技术岗,阿里 P7、百度 T6、腾讯 T3.1 的要求是怎样的?_t3前端啥水平
- 7【递归模板】常用递归JavaScript写法模板
- 8mysql sql执行过程_MySql一条语句执行的过程
- 9MacOS Mojave(苹果14系统) v10.14.6中文离线安装包_macos mojave下载
- 10预习 01 | 大数据技术发展史:大数据的前世今生_谷歌 最先提出 大数据
CV技术指南 | 其实Mamba是一种线性注意力?清华大学黄高团队揭秘开视觉Mamba的真实面目!_mamba论文精度
赞
踩
本文来源公众号“CV技术指南”,仅用于学术分享,侵权删,干货满满。
原文链接:其实Mamba是一种线性注意力?清华大学黄高团队揭秘开视觉Mamba的真实面目!
前言
本文揭示了 Mamba 模型与 Linear Attention Transformer 之间有着惊人的相似之处。作者通过探索 Mamba 和 Linear Transformer 之间的相似性和差异,在本文中提供了一个全面的分析来揭示 Mamba 成功的关键因素。
0 本文目录
1 揭秘视觉 Mamba:一种线性注意力机制视角
(来自清华大学 (黄高团队),阿里巴巴)
1 MLLA 论文解读
1.1 探索 Mamba 和 Linear Attention Transformer 的关联
1.2 线性注意力与选择性状态空间模型简介
1.3 用统一的视角看待选择性状态空间模型与线性注意力
1.4 关于每个差异的分析
1.5 宏观架构设计
1.6 每种差异的影响和 MLLA 最终方案
1.7 实验结果
太长不看版
Mamba 是一种具有线性计算复杂度的状态空间模型。其最近在处理不同视觉任务的高分辨率输入中展示出很不错的效率。本文揭示了 Mamba 模型与 Linear Attention Transformer 之间有着惊人的相似之处。作者通过探索 Mamba 和 Linear Transformer 之间的相似性和差异,在本文中提供了一个全面的分析来揭示 Mamba 成功的关键因素。
具体而言,作者使用统一的公式重新表述了选择性状态空间模型和线性注意力,将 Mamba 重新表述为 Linear Attention Transformer 的变体。它们主要有6个区别:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力归一化、single-head 和修改后的 Block Design。对于每个设计,本文仔细分析了它的优缺点,并实证性地评估了其对视觉模型性能的影响。更有趣的是,遗忘门 (forget gate) 和修改后的 Block Design 是 Mamba 模型成功的核心贡献,而其他的四种设计不太关键。
基于这些发现,作者将这两个比较重要的设计融入 Linear Attention 中,并提出一种类似 Mamba 的线性注意力模型,其在图像分类和高分辨率密集预测任务上都优于视觉 Mamba 模型,同时享受并行化的计算和快速推理。
本文做了哪些具体的工作
-
揭示了 Mamba 与 Linear Attention Transformer 之间的关系:Mamba 和 Linear Attention Transformer 可以使用一个统一的框架表示。与传统的 Linear Attention 的范式相比,Mamba 有6种不同设计:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力的归一化、single-head 和经过修改的 Block Design。
-
对上述的每一种特殊的设计进行了详细分析,并实证验证了遗忘门 (forget gate) 和 Block Design 很大程度上是 Mamba 性能优越的关键。此外,证明了遗忘门 (forget gate) 的循环计算可能不是视觉模型的理想选择。相反,适当的位置编码可以作为视觉任务中的遗忘门 (forget gate) ,同时保持并行化的计算和快速的推理。
-
开发了一系列名为 MLLA 的 Linear Attention Transformer 架构,它继承了 Mamba 的核心优点,并且往往比原始 Mamba 模型更适合视觉任务。
1 揭秘视觉 Mamba:一种线性注意力机制视角
论文名称:Demystify Mamba in Vision: A Linear Attention Perspective (Arxiv 2024.05)
论文地址:
https://arxiv.org/pdf/2405.16605
代码链接:
https://github.com/LeapLabTHU/MLLA
1.1 探索 Mamba 和 Linear Attention Transformer 的关联
最近,以 Mamba 为例的状态空间模型迅速引起了领域的研究兴趣。与主流 Transformer 模型的二次复杂度相比,Mamba 有线性复杂度的有效序列建模。这个关键的属性允许 Mamba 在处理极长的序列时更加占优势,使其称为语言[1]和视觉[2]模型的炙手可热的架构。

到底是什么因素促使了 Mamba 的成功,及其对 Linear Attention Transformer 的优势?
作者在本文中提供了理论和实证分析,站在 Linear Attention Transformer 的角度来揭示 Mamba。具体而言,作者使用统一的公式重写了选择性状态空间模型和 Linear Attention 的公式,指出 Mamba 与 Linear Attention Transformer 的区别主要有6点:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力的归一化、single-head 和经过修改的 Block Design。为了揭示到底是哪种因素导致 Mamba 的有效性,作者进行了实证研究来评估每种设计的影响。结果表明,遗忘门 (forget gate) 和经过修改的 Block Design 是 Mamba 模型优越性的核心贡献。
遗忘门 (forget gate) 需要循环计算,可能不太适合非自回归的视觉模型。因此,作者深入研究了遗忘门 (forget gate) 的本质,验证其可以被位置编码所取代。基于这些发现,作者设计了 Mamba-like Linear Attention (MLLA) 模型。
1.2 线性注意力与选择性状态空间模型简介

Linear Attention

Selective State Space Model

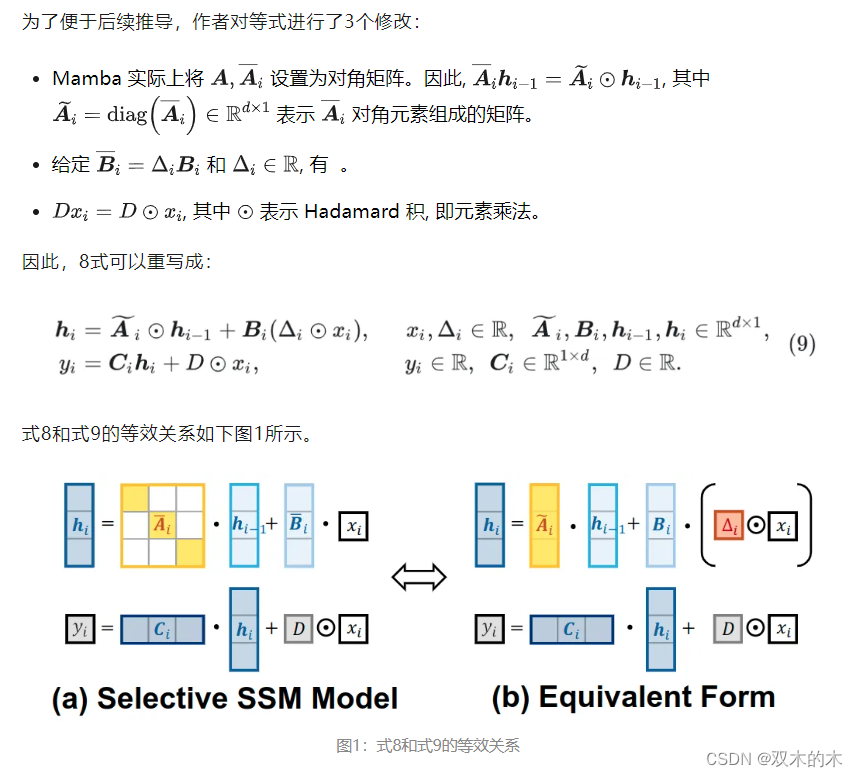

1.3 用统一的视角看待选择性状态空间模型与线性注意力


除了这4个差异之外,重要的是要注意式12表示单头线性注意力。这表明选择性状态空间模型类似于单头线性注意,不包含多头设计。
总之,选择性 SSM 和线性注意力之间的相似性和差异可以概括为:
选择性状态空间模型类似于具有附加输入门、遗忘门和 Shortcut 的线性注意力,同时省略归一化和多头设计。
1.4 关于每个差异的分析


1.5 宏观架构设计
线性注意 Transformer 模型通常采用图 3(a) 中的设计,它由线性注意力模块和 MLP 模块组成。相比之下,Mamba 通过结合 H3[5]和 Gated Attention[6]这两个设计来改进,得到如图 3(b) 所示的架构。改进的 Mamba Block 集成了多种操作,例如选择性 SSM、深度卷积、线性映射、激活函数、门控机制等,并且往往比传统的 Transformer 设计更有效。

图3:线性注意力 Transformer 架构,Mamba 架构,以及本文 MLLA 架构
Mamba 和线性注意力 Transformer 的关系
Mamba 可以看作是具有特殊线性注意力和改进的 Block 设计的线性注意力 Transformer 变体。 线性注意力的变体,即选择性状态空间模型,与常见的线性注意力范式相比有5大区别。
下面作者通过实验来评估每个区别的影响,揭示了 Mamba 成功背后的核心贡献到底是什么。
作者采用了 Swin Transformer[7]架构来验证六个差异的影响。首先将 Swin Transformer 中的 Softmax attention 替换为线性注意力来创建基线模型。然后分别对基线模型引入每个区别来评估其影响。作者进一步将有用的设计集成到线性注意力 Transformer 中以创建本文的 Mamba-like Linear Attention (MLLA) 架构,并将其与各种视觉 Mamba 进行比较来评估其有效性,包括 ImageNet-1K 分类 、COCO 目标检测和 ADE20K 语义分割。
1.6 每种差异的影响和 MLLA 最终方案
作者分别将每个区别应用于线性注意力模型并评估其在 ImageNet-1K 上的性能,结果如下图4所示。

图4:每种差异的影响实验结果
1) 输入门: 使用输入门可以略微提升模型的精度 0.2%。图5中的可视化有助于理解输入门的影响。可以看出,该模型倾向于为前景物体等信息丰富的区域生成更高的输入门值,同时抑制不太有用的 tokens。此外,使用输入门会导致模型吞吐量降低 7%。

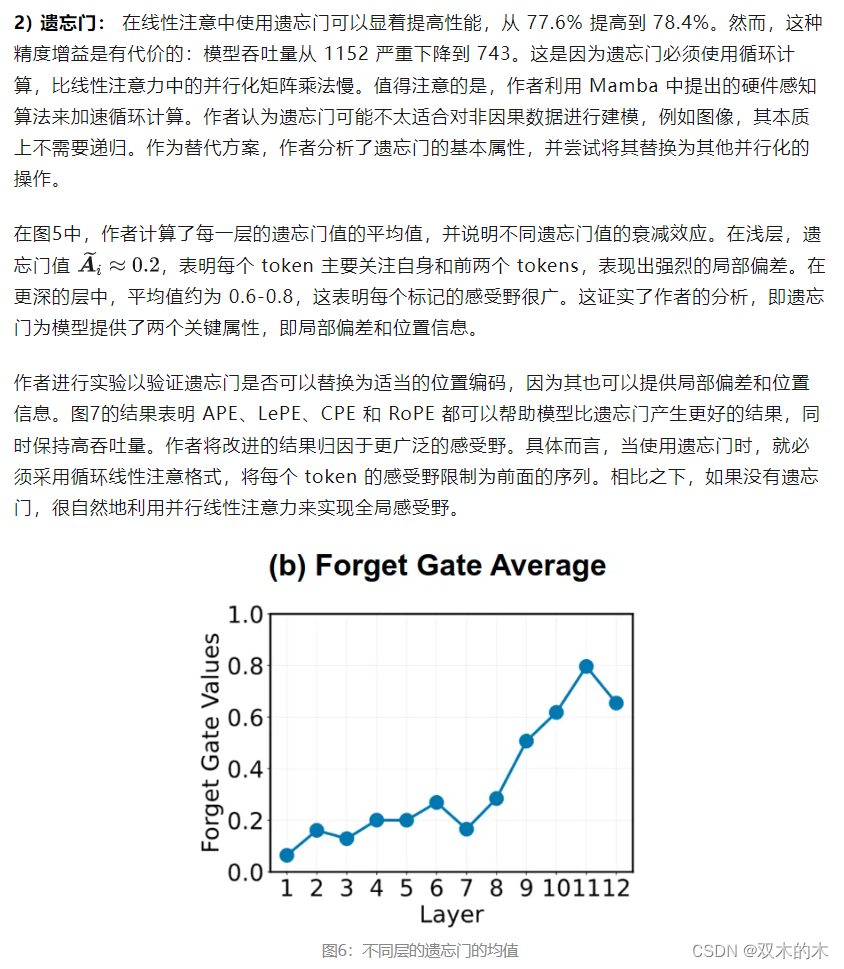

图7:把遗忘门替换为不同位置编码的结果
3) Shortcut: 在线性注意力中使用可学习 Shortcut 提供了 0.2% 的精度增益,同时将吞吐量从 1152 降低到 1066。
4) 归一化: 在没有归一化的情况下,模型严重的性能下降从 77.6% 下降到 72.4%。
5) Multi-head: 现代 Transformer 通常采用多头设计来增强其表达能力。移除这种设计降低了计算成本并加速了模型,但显着降低了性能。因此作者不使用这个做法。
6) Block Design: 作者采用两种方法来评估 Mamba 的 Block Design 的影响:
1. 用 Mamba 的 Block Design 替换整个 Transformer Block。
2. 用 Mamba Block 设计替换注意力 Block,同时保留 MLP Block。在这两种情况下,Mamba BLock 中的选择性 SSM 都被替换为线性注意力。为了维护类似的 FLOP,作者对两种设置分别使用 Mamba 扩展因子 E = 2.0 和 E = 1.0。结果如图4所示。这两种情况分别用 Block Design all 和 Block Design sub 表示。两种替换方法都可以提高性能,证明了 Mamba 宏观设计的有效性。替换注意力 Block 可以产生更好的结果,得到如图 3(c) 所示的 MLLA 架构。MLLA 架构的计算复杂度可以表示为:

基于这些发现,作者将遗忘门和 Block Design 集成到线性注意力中, 得到本文的 MLLA 模型。值得注意的是,MLLA 实际上使用 LePE、CPE 和 RoPE 分别替换遗忘门的局部偏差、依赖于输入的位置信息和全局位置信息。
1.7 实验结果
图像分类实验结果
如图8所示,由于集成了 Mamba 和 Linear Attention 的有用设计,本文的 MLLA 模型在所有模型大小上始终优于各种视觉 Mamba 模型。这些结果也说明了凭借 Mamba 的这两点设计,线性注意力机制模型的性能也可以超越 Mamba 架构。作者也实证性地观察到,与视觉 Mamba 模型相比,MLLA 表现出更高的可扩展性,因为 MLLA-B 达到了 85.3 的精度,大大超过了其他模型。

图8:ImageNet-1K 上与各种视觉 Mamba 的结果对比
作者在图9中提供了速度测量结果。用位置编码替换遗忘门,本文的 MLLA 模型受益于并行化的计算,与视觉 Mamba 模型相比推理速度明显更快。
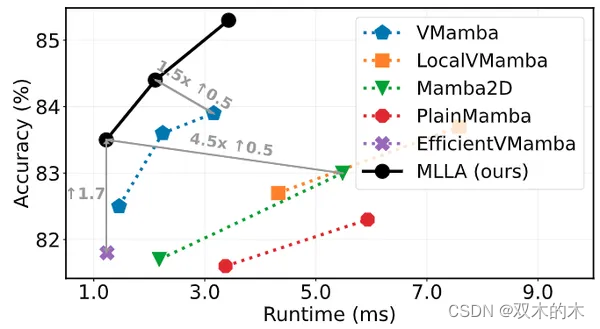
图9:RTX3090 GPU 的速度测量结果
COCO 目标检测实验结果
如图10所示,在 COCO 数据集上,MLLA 模型结果也优于视觉 Mamba 模型,这意味着 MLLA 对于高分辨率密集预测任务的有效性。MLLA 提供了具有线性复杂度 \mathcal{O}(N)\mathcal{O}(N) 的全局建模和并行化的计算,使其非常适合高分辨率图像建模。值得注意的是,MLLA 大大优于 MambaOut,这也与 MambaOut 中的结论 (即 SSM 对于高分辨率密集预测任务很重要) 是一致的。

图10:COCO 实验结果
ADE-20K 语义分割
如图11所示为 ADE-20K 数据集的结果。与目标检测任务类似,MLLA 在语义分割也得到了更好的结果,进一步验证了本文分析和 MLLA 模型的有效性。

图11:ADE-20K 语义分割实验结果
参考
-
^abMamba: Linear-Time Sequence Modeling with Selective State Spaces
-
^Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
-
^Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
-
^FLatten Transformer: Vision Transformer using Focused Linear Attention
-
^Hungry Hungry Hippos: Towards Language Modeling with State Space Models
-
^Transformer Quality in Linear Time
-
^Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

