
- 1Java实现excel导出功能的几种方法——poi、easyExcel、easypoi、jxl_java导出excel的三种方法
- 2ChatGPT AIGC人工智能助力职场,办公人员的福音来了 WPS AI
- 3flutter vscode+第三方安卓模拟器
- 4【数据结构】排序:插入排序与希尔排序详解_数据结构输入一组数据使用直接插入算法进行排序,输出排序结果
- 5计算机科学与技术万金油专业,盘点工学大类里的“万金油”专业
- 6LSS 和 BEVDepth算法解读_bev自底向上和自顶向下
- 7深入解析 JWT(JSON Web Tokens):原理、应用场景与安全实践_jwt 适用场景
- 8mysql 数据丢失更新的解决方法
- 9python爬虫获取的网页数据为什么要加[0-python3爬虫爬取网页思路及常见问题(原创)...
- 10HBase无法启动HRegionServer_hbase没有hquorumpeer进程
base64编码_Base64编码详解
赞
踩
来源 | 公众号 架构师必备
Base64编码原理
Base64编码之所以称为Base64,是因为其使用64个字符来对任意数据进行编码,同理有Base32、Base16编码。标准Base64编码使用的64个字符为:
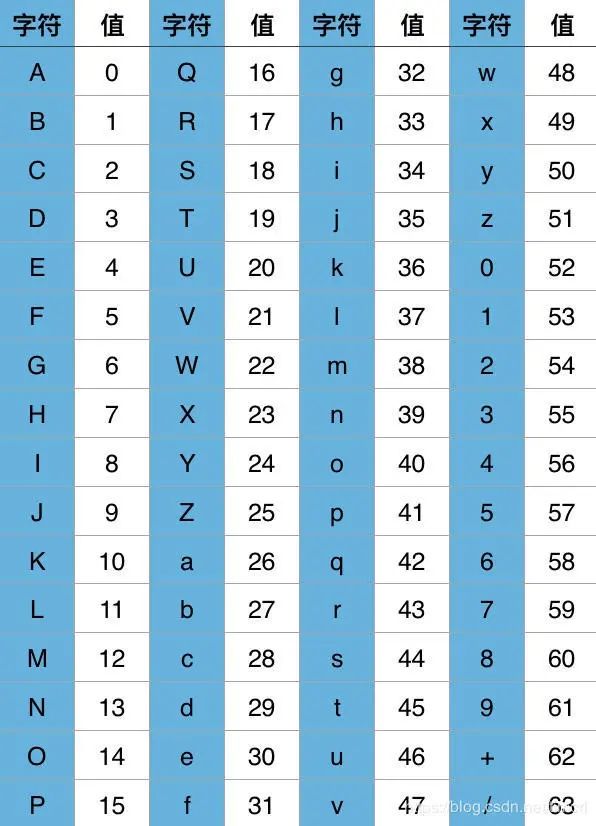
这64个字符是各种字符编码(比如ASCII编码)所使用字符的子集,基本,并且可打印。唯一有点特殊的是最后两个字符,因对最后两个字符的选择不同,Base64编码又有很多变种,比如Base64 URL编码。
Base64编码本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续6比特(2的6次方=64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。
假设我们要对 Hello! 进行Base64编码,按照ASCII表,其转换过程如下图所示:

可知 Hello! 的Base64编码结果为 SGVsbG8h ,原始字符串长度为6个字符,编码后长度为8个字符,每3个原始字符经Base64编码成4个字符,编码前后长度比4/3,这个长度比很重要 - 比原始字符串长度短,则需要使用更大的编码字符集,这并不我们想要的;长度比越大,则需要传输越多的字符,传输时间越长。Base64应用广泛的原因是在字符集大小与长度比之间取得一个较好的平衡,适用于各种场景。
是不是觉得Base64编码原理很简单?
但这里需要注意一个点:Base64编码是每3个原始字符编码成4个字符,如果原始字符串长度不能被3整除,那怎么办?使用0值来补充原始字符串。
以 Hello!! 为例,其转换过程为:

注:图表中蓝色背景的二进制0值是额外补充的。
Hello!! Base64编码的结果为 SGVsbG8hIQAA 。最后2个零值只是为了Base64编码而补充的,在原始字符中并没有对应的字符,那么Base64编码结果中的最后两个字符 AA 实际不带有效信息,所以需要特殊处理,以免解码错误。
标准Base64编码通常用 = 字符来替换最后的 A,即编码结果为 SGVsbG8hIQ==。因为 =字符并不在Base64编码索引表中,其意义在于结束符号,在Base64解码时遇到 = 时即可知道一个Base64编码字符串结束。
如果Base64编码字符串不会相互拼接再传输,那么最后的 = 也可以省略,解码时如果发现Base64编码字符串长度不能被4整除,则先补充 = 字符,再解码即可。
解码是对编码的逆向操作,但注意一点:对于最后的两个 = 字符,转换成两个 A 字符,再转成对应的两个6比特二进制0值,接着转成原始字符之前,需要将最后的两个6比特二进制0值丢弃,因为它们实际上不携带有效信息。
为了理解Base64编码解码过程,个人实现了一个非常简陋的Base64编码解码程序,见:youngsterxyf/xiaBase64。
由于Base64应用广泛,所以很多编程语言的标准库都内置Base64编码解码包,如:
PHP:base64_encode、base64_decode
Python:base64包
Go:encoding/base64
…
Base64编码应用
本文开始提到的青云应用例子只是Base64编码的应用场景之一。由于Base64编码在字符集大小与编码后数据长度之间做了较好的平衡,以及Base64编码变种形式的多样,使得Base64编码的应用场景非常广泛。下面举2个常用常见的例子。
HTML内嵌Base64编码图片
前端在实现页面时,对于一些简单图片,通常会选择将图片内容直接内嵌在页面中,避免不必要的外部资源加载,增大页面加载时间,但是图片数据是二进制数据,该怎么嵌入呢?绝大多数现代浏览器都支持一种名为 Data URLs 的特性,允许使用Base64对图片或其他文件的二进制数据进行编码,将其作为文本字符串嵌入网页中。以百度搜索首页为例,其中语音搜索的图标是个背景图片,其内容以 Data URLs 形式直接写在css中,这个css内容又直接嵌在HTML页面中,如下图所示:
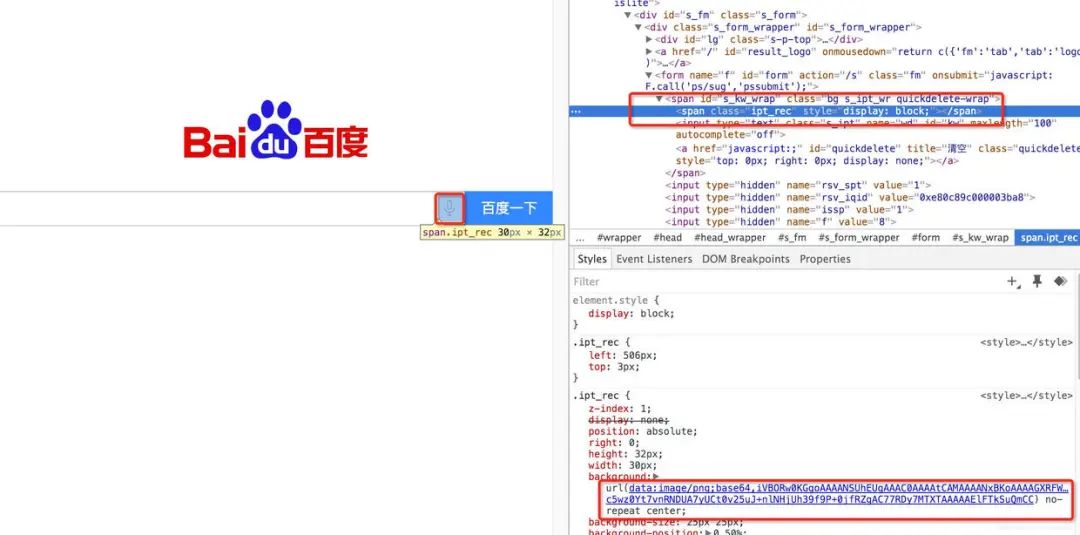
Data URLs 格式为:url(data:文件类型;编码方式,编码后的文件内容)。
当然,也可以直接基于image标签嵌入图片,如下所示:
<img alt="Embedded Image" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAADIA..." />但请注意:如果图片较大,图片的色彩层次比较丰富,则不适合使用这种方式,因为其Base64编码后的字符串非常大,会明显增大HTML页面,影响加载速度。
MIME(多用途互联网邮件扩展)
我们的电子邮件系统,一般是使用SMTP(简单邮件传输协议)将邮件从客户端发往服务器端,邮件客户端使用POP3(邮局协议,第3版本)或IMAP(交互邮件访问协议)从服务器端获取邮件。
SMTP协议一开始是基于纯ASCII文本的,对于二进制文件(比如邮件附件中的图像、声音等)的处理并不好,所以后来新增MIME标准来编码二进制文件,使其能够通过SMTP协议传输。
举例来说,我给自己发封邮件,正文为空,带一个名为hello.txt的附件,内容为 您好!世界!。导出邮件源码,其关键部分如下图所示:
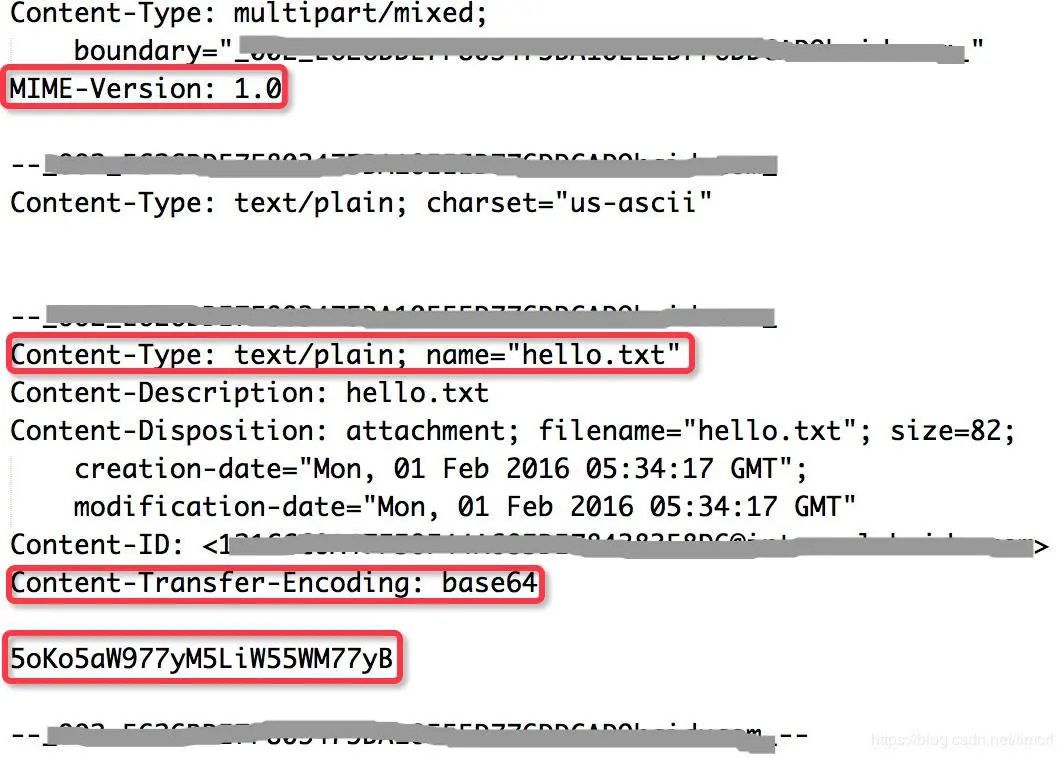
MIME-Version: 1.0:表示当前使用MIME标准1.0版本。
Content-Type: text/plain; name="hello.txt":表示附件文件名为 hello.txt ,格式为纯文本。
Content-Transfer-Encoding: base64:表示附件文件内容使用base64编码后传输。
5oKo5aW977yM5LiW55WM77yB:则是文件内容 您好,世界! Base64编码后的结果。
不过,MIME使用的不是标准Base64编码。
Base64使用注意事项
Base64编码要求把3个8位字节(38=24)转化为4个6位的字节(46=24),之后在6位的前面补两个0,形成8位一个字节的形式。如果剩下的字符不足3个字节,则用0填充,输出字符使用'=',因此编码后输出的文本末尾可能会出现1或2个'='。
| 外文名 | base64 | 定 义 | 8Bit字节代码的编码方式之一 |
|---|---|---|---|
| 属 性 | 编码方式 | 可用于 | 在HTTP环境下传递较长的标识信息 |
| 应用 | 用于传输8Bit字节代码 | 特 性 | Base64编码具有不可读性 |
一、Base64和URL传参问题
标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它在末尾填充'='号,并将标准Base64中的“+”和“/”分别改成了“-”和“_”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
二、Base64和URL传参问题改善
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
此外还有一些变种,它们将“+/”改为“-”或“.”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“_:”(用于XML中的Name)。
三、Base64转换后比原有的字符串长1/3
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(38 = 46 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
四、Base64转换总结
Base64转换,最好是不要用在加密上,尤其是参数加密,很容易出问题。
参考资料:
http://blog.xiayf.cn/2016/01/24/base64-encoding/
https://www.sojson.com/base64.html
END

