
热门标签
热门文章
- 1neo4j 如何删除所以的节点和关系_neo4j怎么清空所有的节点,关系语句
- 2基于PicGo与Gitee搭建在线图床
- 3数据结构顺序表基本流程_表示流程的数据结构
- 4Your AWS Account is Compromised_account compromised
- 5开源开放,共建开发者新生态 | 2022 开发者生态汇_坚持开源开放 建立自主可控生态
- 6GeoServer学习笔记-2、基本使用(发布shapefile文件)_geoserver是哪家公司的
- 7学习underscore源码整体架构,打造属于自己的函数式编程类库
- 8TextMate中Command+R无法执行的变通解决方法
- 9module.exports指向问题_ts module.exports
- 10数据结构之算法设计题专攻_数据结构算法设计题怎么练
当前位置: article > 正文
Python爬虫 之 异步爬虫_async with as
作者:爱喝兽奶帝天荒 | 2024-06-20 12:42:37
赞
踩
async with as
完整版!!!!!!!
完整版!!!!!!!
完整版!!!!!!!
异步爬虫
初识异步爬虫方式
- 多线程,多进程(不建议):
- 优点:可以为相关堵塞(耗时间)的操作单独开启线程和进程,堵塞程序就会实现异步执行
- 缺点:无法限制多进程或多进程 - 线程池,进程池:
- 优点:降低系统对于线程和进程创建和销毁的频率,减小系统开销
- 缺点:池中线程和进程数量有上限
举个栗子直观地看一下线程的作用吧
import time def get_text(char): print("正在下载",char) time.sleep(2) print("成功加载",char) return char #单线程运行: #运行文本 text=['a','b','c','d'] #记录开始时间 start_time=time.time() for i in text: get_text(i) #记录结束时间 end_time=time.time() print("单进程共需要时间:",end_time-start_time) #多线程运行 #导库 from multiprocessing.dummy import Pool #实例化4线程池 pool=Pool(4) start_time=time.time() text_list=pool.map(get_text#进行多线程的目标函数名,没有() ,text#传入数据的列表 ) #该函数返回值为函数return值组成的列表,顺序和传入列表相对应 end_time=time.time() print("多进程共需要时间:",end_time-start_time) print(text_list) 结果为: 正在下载 a 成功加载 a 正在下载 b 成功加载 b 正在下载 c 成功加载 c 正在下载 d 成功加载 d 单进程共需要时间:8.001578569412231 正在下载 a 正在下载 b 正在下载 c 正在下载 d 成功加载 b成功加载 d 成功加载 c 成功加载 a 多进程共需要时间:2.0006678104400635 ['a', 'b', 'c', 'd'] 我们发现:多线程输出的顺序结束时间是随机的,也证实了多线程之间运行并不会相互影响

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
li视频源码讲解
文本源码见评论
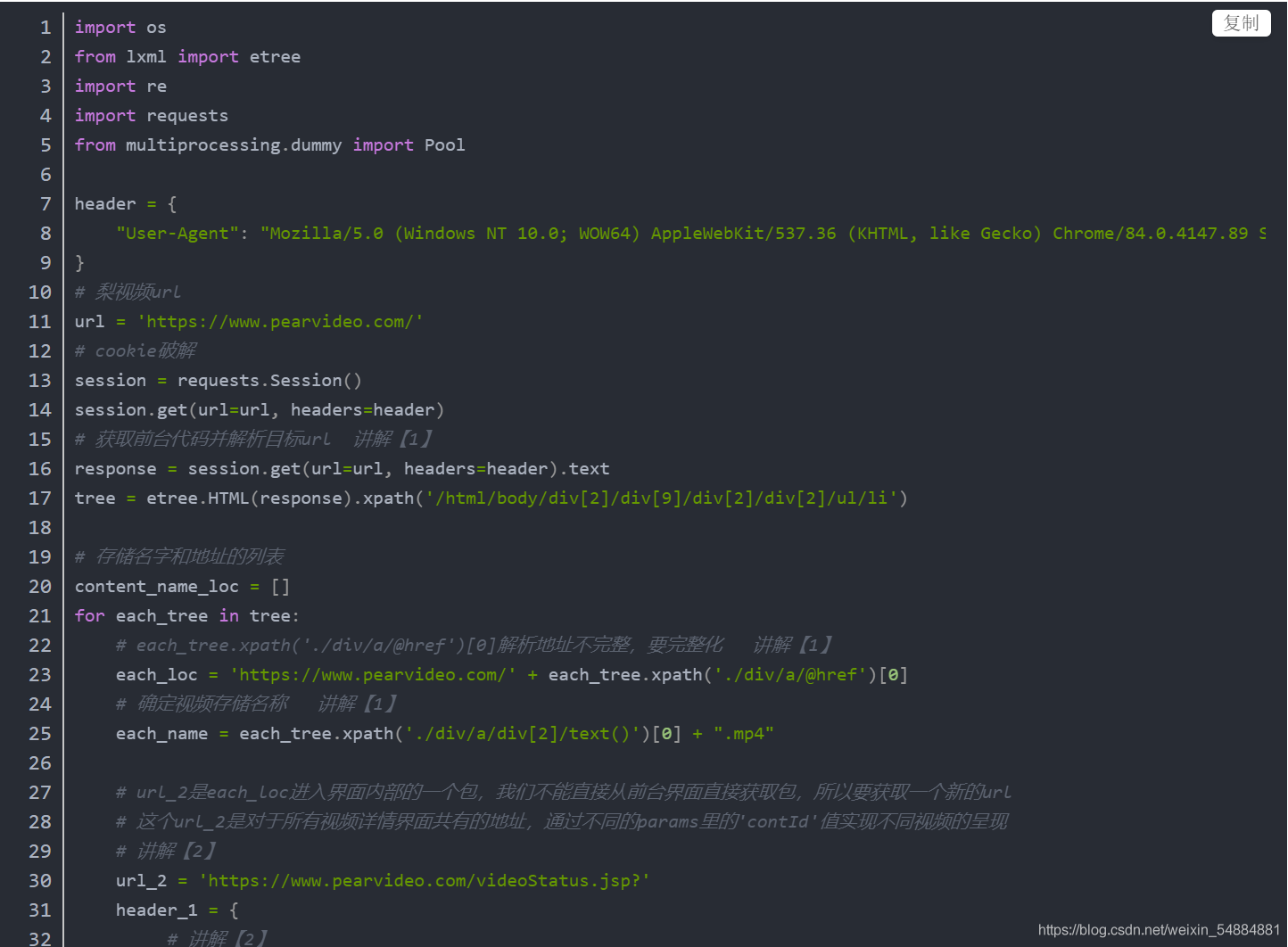
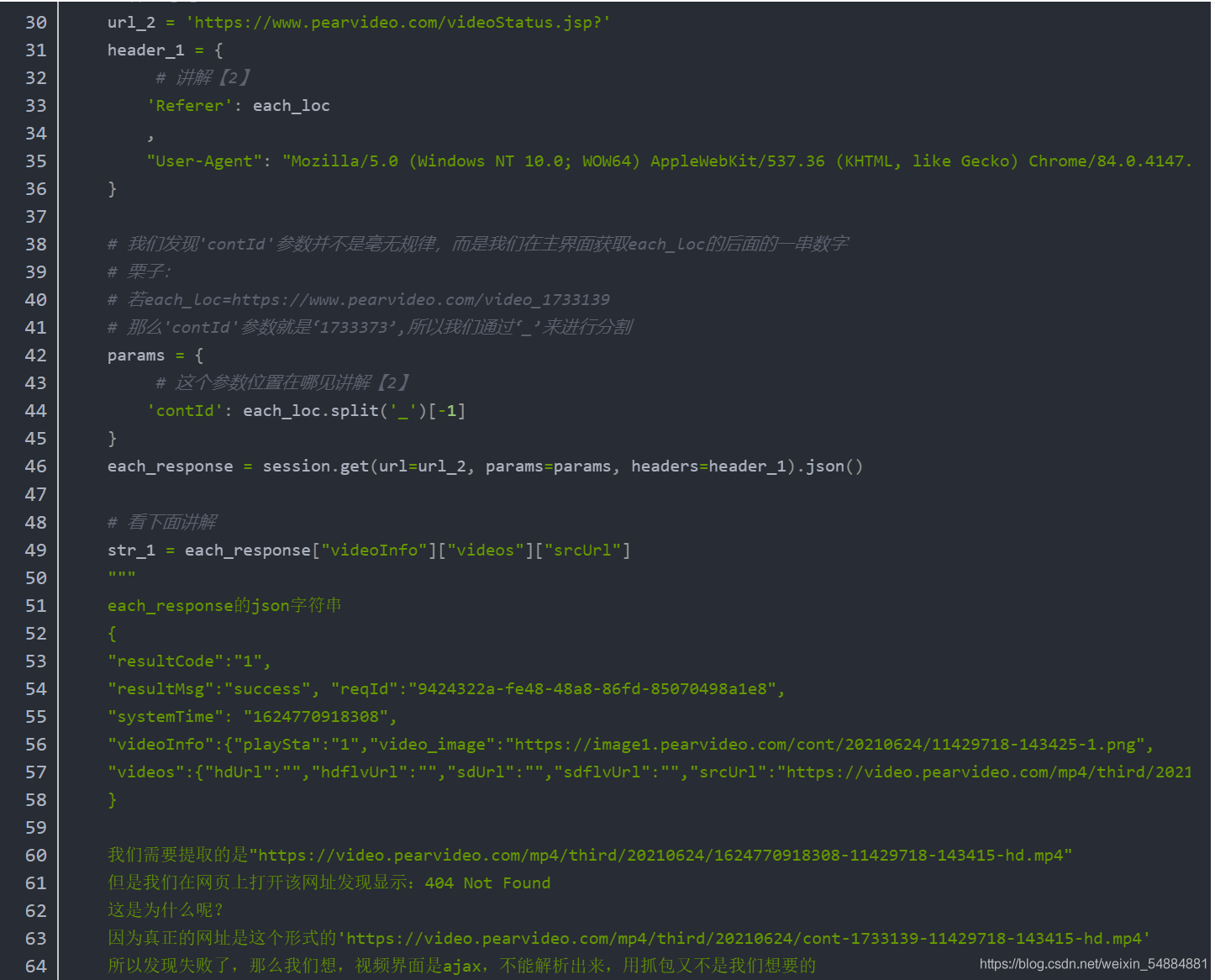
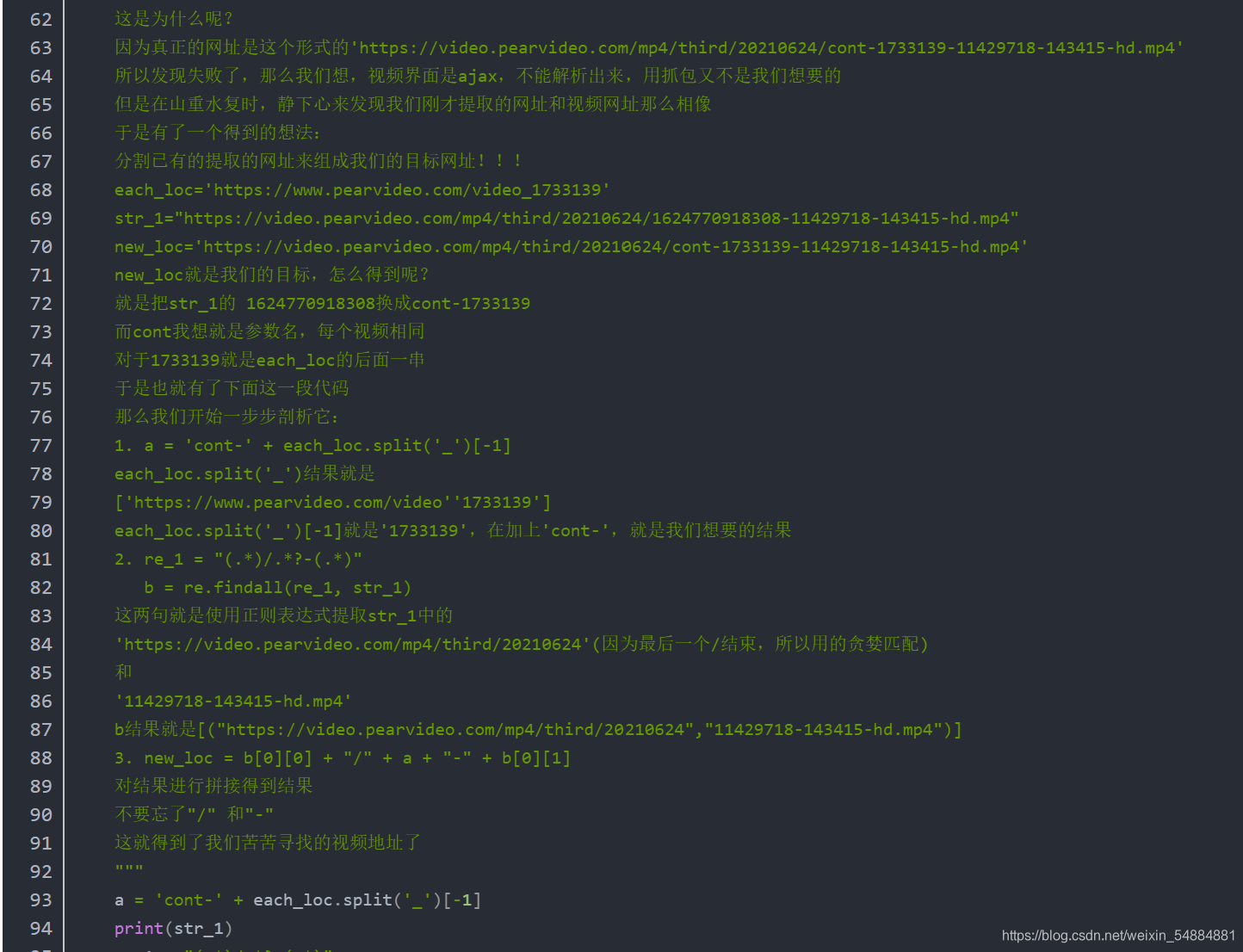
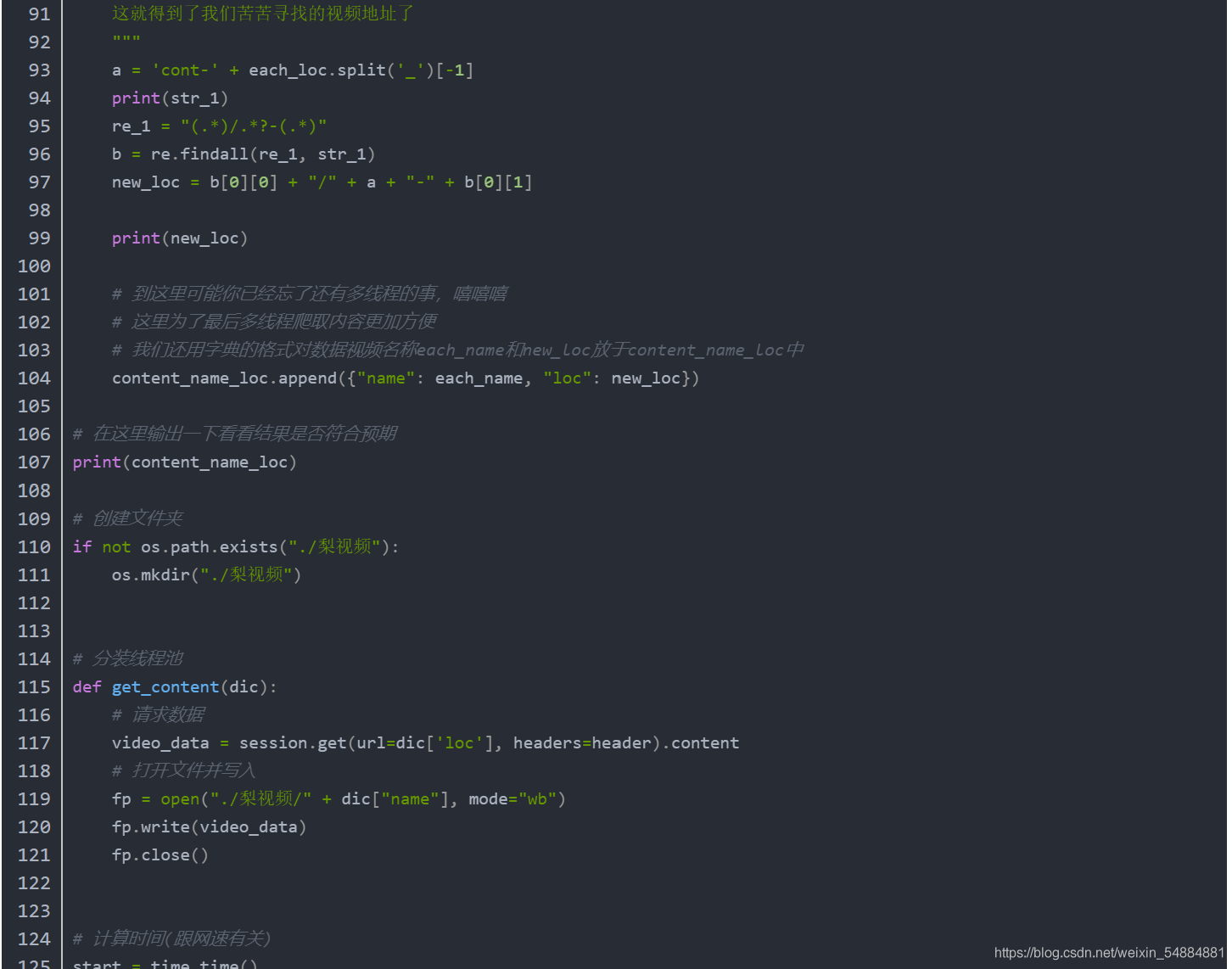

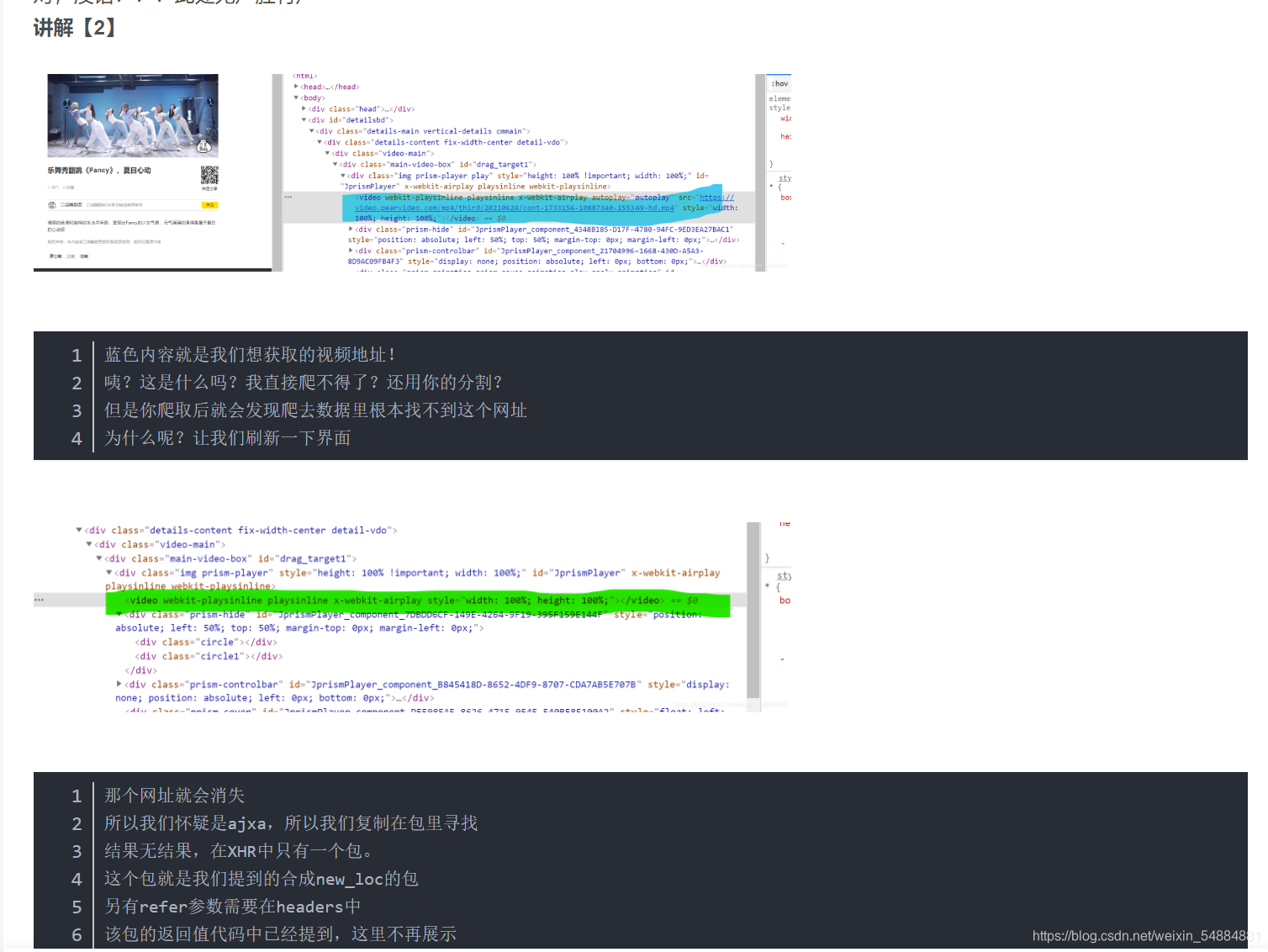
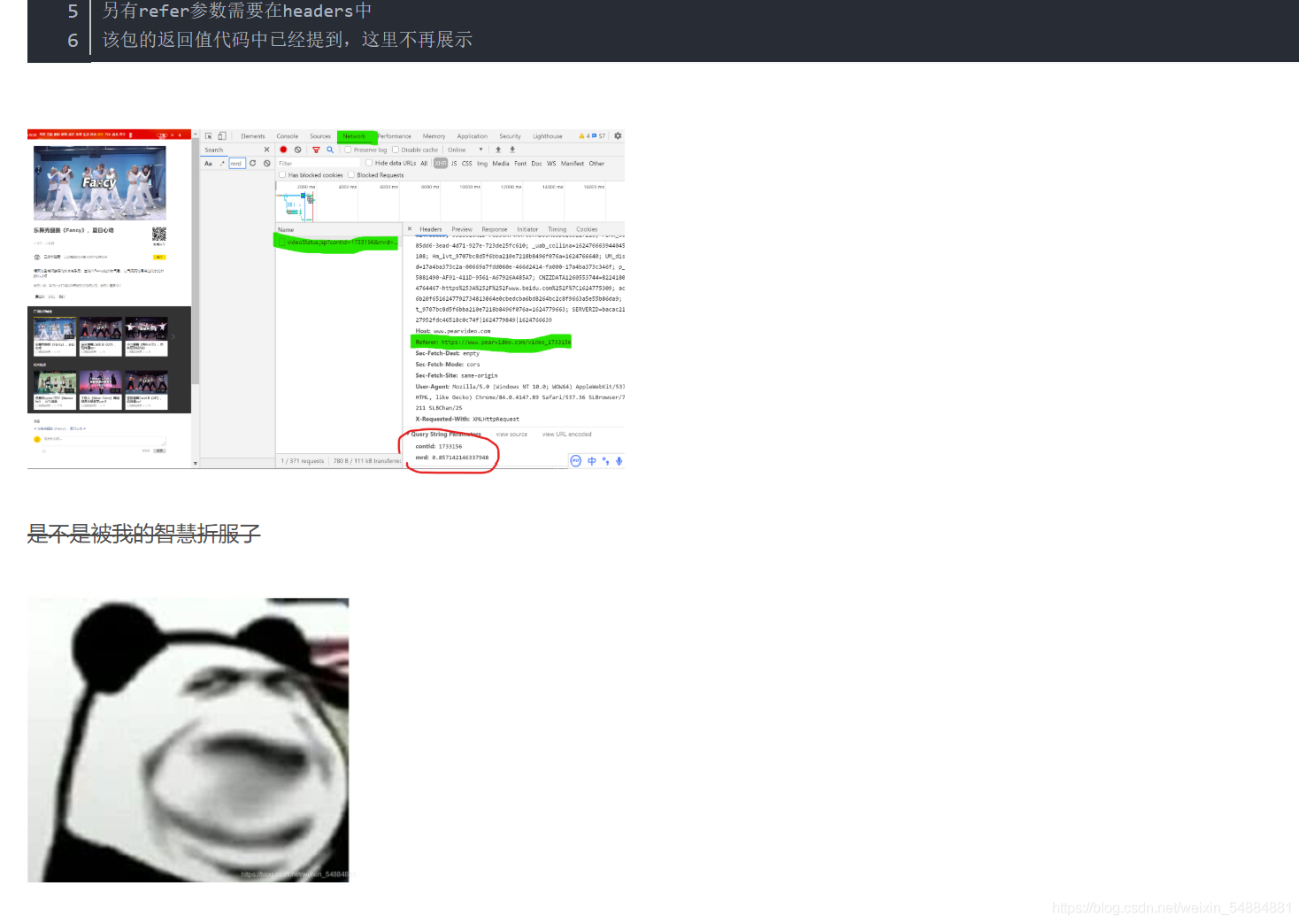
下面我们开始最常用也是最难的基于协程的异步编程了
不过只要静下心来理解,一定能理解的啊,加油!!!
协程异步编程
什么是协程:
协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。
一个程序可以包含多个协程,可以对比与一个进程包含多个线程,因而下面我们来比较协程和线程。我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程由当前协程来控制。
协程的意义:
同时对于多个耗时间的操作进行同时运行以提高我们代码运算效率,在爬虫中,就可以同时请求多条数据,爬取多个数据/图片/视频
实现携程的方法:
- greeenlt
- yeid
- asyncio
- async,await关键字
这里不需要知道1,2,3 我们重点关注4,因为第四种效率最高,代码更简洁。
事件循环
- 时间循环可理解为死循环,一直检查一些代码执行情况,并做出相应处理 - 事件就是指我们在爬取数据过程,不过该事件通常是以函数调用的形式出现 - 就像我们想爬取多个视频,那么一个事件就可以是将视频url传入函数,进行爬取的过程 # 每个事件均有他自己的状态已完成:finished,未完成:pending 任务列表=[任务1,任务2,任务3....] while True: 可执行的任务列表=任务列表中取出可以被运行的任务 已完成任务列表=任务列表中取出已经运行完成的任务 for 就绪任务 in 可执行的任务列表: 执行就绪任务 for 已完成任务 in 已完成任务列表: 在任务列表移除已完成任务 直到任务列表全部完成跳出循环
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
形如
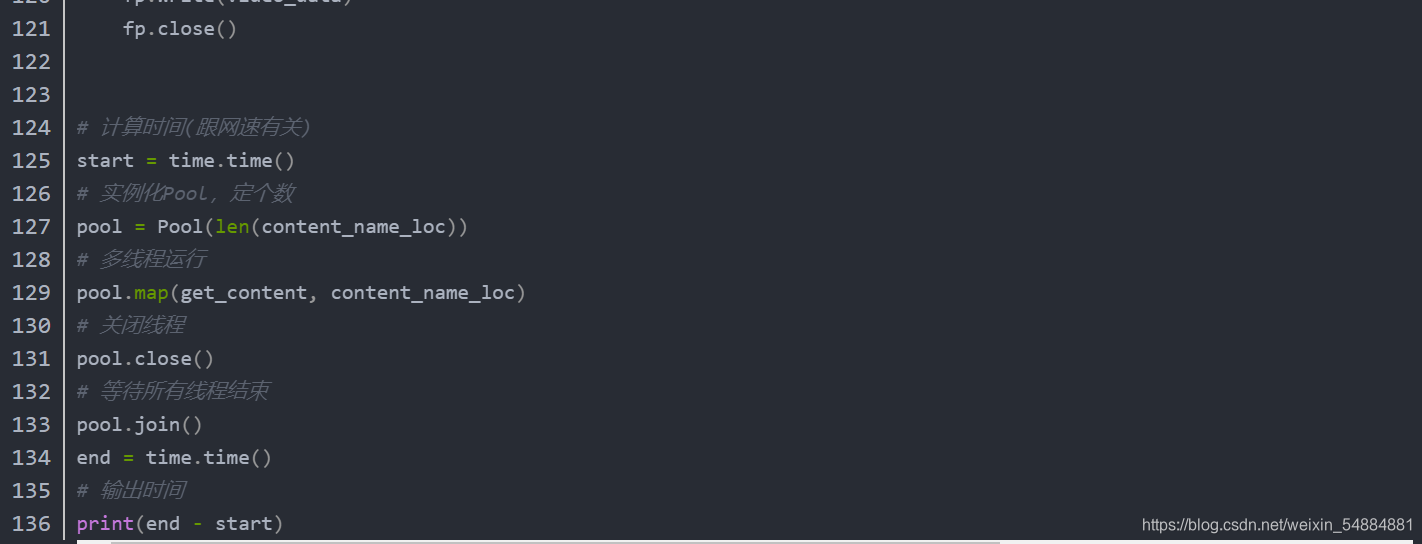
async def 函数名:
函数体
就是一个协程函数
协程函数的调用就是一个协程对象即 函数名()
但是调用协程函数得到的对象并不会直接执行(因为事件并未加载进事件循环的任务列表中去)
需要用到特定函数才能实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
单条时间启动
import asyncio async def request_1(url): print('正在请求的url是',url) print('请求成功,',url) return url async def request_2(url): print('正在请求的url是', url) print('请求成功,', url) return url # 创建一个事件循环对象 loop = asyncio.get_event_loop() # 基于loop创建了一个task_1任务对象(注意创建任务loop.create_task必须在事件循环创建以后) task_1 = loop.create_task(request_1("https://www.taobao.com/")) # 基于loop创建了一个task_2任务对象,现在loop事件循环的时间里就存在了两个任务 task_2=loop.create_task(request_2("https://www.baidu.com/?")) print(task_2)#查看一下状态 # 启动事件循环loop,可以传入task对象,也可以是协程对象 # 只不过传入协程对象该函数会自动增加一步在loop事件循环中注册该协程对象 loop.run_until_complete(task_1) print(task_2)#结果 finished print(task_1)#结果 finished #说明loop.run_until_complete(task_1)在运行task_1时启动了事件循环loop中所有的task事件对象 # 那么是不是咋以后的启动事件循环时只启动一个就可以运行所有了呢,当然不是 # 因为在task_1完成后极短时间内,主程序还没来得及print(task_2),task_2也随即完成了,使我们看到print(task_2)时task_2已完成 #当task_2耗时更长一点时(例如在request_2添加await asyncio.sleep(0.01),就会发现虽然是0.01秒print(task_2)结果是pending,即未完成) #说明可能某些原因导致在其他任务未完成的情况下就执行了下面代码 #所以我们需要保证所有任务都要完成才能继续运行那么该怎么做呢?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
多个事件启动(重要)
import asyncio async def request_1(url): print('正在请求的url是',url) print('请求成功,',url) return url async def request_2(url): print('正在请求的url是', url) print('请求成功,', url) return url #******************方法一**************** # 创建一个事件循环对象 loop = asyncio.get_event_loop() #实际上不用使用loop.create_task也可以运行,不过还是建议加上 task_list = [ loop.create_task(request_1("https://www.baidu.com/?")) ,loop.create_task(request_1("https://www.taobao.com/")) ] #上面已提到在run_until_complete中要传入任务对象和协程对象 #所以loop.run_until_complete(task_list)是错误的,因为task_list是一个列表 #而添加上asyncio.wait就可以实现传入任务列表了 #这样一来就可以实现loop里面所有任务全部实现完成后才进行下一步 done,pending=loop.run_until_complete(asyncio.wait(task_list)) #done是已完成任务的集合,pending是未完成任务的集合 #******************方法二**************** task_list = [ request_1("https://www.baidu.com/?") ,request_1("https://www.taobao.com/") ] #这句代码的含义是创建事件循环并运行 #相当于loop = asyncio.get_event_loop()和loop.run_until_complete(asyncio.wait(task_list))的集合 #不过要特别注意的是因为创建任务必须在事件循环创建以后,所以在创建task_list时只能写成协程对象,不能是任务对象 done,pending=asyncio.run(asyncio.wait(task_list))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
到这里上述的协程代码均是单线程运行的,也就是说在启动事件循环时运行的顺序是一个任务运行完后又运行下一个任务,并不是时间循环中所有时间同时运行,所以并没有达到我们多线程的目的,对于同时运行多个线程的话,需要手动对于协程函数中某些特定语句进行挂起,这些挂起的函数一般是比较费时间的函数,在函数挂起后什么时候向下运行呢?这里回到我们的循环时间,循环时间的作用就是对于任务里挂起函数进行状态检测,当检测到已完成就会向下运行。那么怎么挂起呢,就用到关键字await
await关键字(重要)
import asyncio # await+可等待对象(协程对象,Future,Task对象)IO等待 # 在运行await后的语句时,会自动切换到其他任务实现同时运行多个任务 #在爬虫使用时通常是get,post请求 async def request_1(url): print('正在请求的url是', url) await asyncio.sleep(5) print('请求成功,', url) return url async def request_2(url): print('正在请求的url是', url) await asyncio.sleep(2) print('请求成功,', url) return url task_list = [ request_1("https://www.baidu.com/?") , request_2("https://www.taobao.com/") ] start = time.time() done,pending=asyncio.run(asyncio.wait(task_list)) print(time.time() - start) 结果: 正在请求的url是 https://www.baidu.com/? 正在请求的url是 https://www.taobao.com/ 请求成功, https://www.taobao.com/ 请求成功, https://www.baidu.com/? 5.001507520675659 """ asyncio.run(asyncio.wait(task_list))运行顺序: 先进入request_1("https://www.baidu.com/?")中运行,运行到await asyncio.sleep(5)挂起 接着进入request_2("https://www.taobao.com/")中运行,运行到await asyncio.sleep(2)挂起(若有其他任务接着运行), 检测到没有任务了那么这一个循环结束,那么事件循环继续对整个任务列表中任务依次检测状态, 如果挂起函数仍未完成,那么进行下一个任务,都没有完成就再来继续对整个任务列表中任务依次检测状态, 若检测有任务完成了挂起函数,那么会紧接着运行这个任务挂起函数的下面,直到又遇见其他await函数或者运行完(从任务列表删除), 再进行下一个任务状态检测 """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
回调函数(重要)
为什么要有回调函数
async def request_1(url):
print('正在请求的url是', url)
await asyncio.sleep(5)
print('请求成功,', url)
return url
在爬虫使用时,通常是传入url,
return返回所get,post的信息
但是我们不能直接拿到return返回的值
所以要通过回调函数进行实现
另外回调函数实在任务结束后立即执行,属于异步进行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
import asyncio #协程函数 async def request_1(url): print('正在请求的url是', url) await asyncio.sleep(2) print('请求成功,', url) return url #回调函数 def call_back(t): # 可在此通过t.result()进行数据解析 print(t.result()) #创建事件循环 loop=asyncio.get_event_loop() #在时间循环中添加任务 task_1=loop.create_task(request_1("https://www.baidu.com/?")) #将协程任务绑定回调函数 task_1.add_done_callback(call_back) #运行loop loop.run_until_complete(task_1) 注:回调函数一定是在运行完async def request_1(url)后 会自动将返回值经过特殊的包装作为参数传入def call_back(t)中 在回调函数中通过t.result()就能拿到request_1返回的值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
协程中的requests—aiohttp(重要)
由于requests不支持多线程运行,所以我们不得不更换库来实现数据爬取,那就是aiohttp中的ClientSession()
它和requests用法相同,除了get,post函数中参数proxy从字典形式换成了字符串形式。
- 1
- 2
import asyncio import aiohttp #关于为什么会用async with as 实现是因为它结束运行后自动关闭实例化对象,修饰关键字async是协程函数with as的固定用法 async def request(url_1): async with aiohttp.ClientSession() as session: # 不要忘了ClientSession()中的() async with await session.get(url_1) as response: # 注意是字符串类型数据text() # 二进制(图片视频)类型数据read() # json()返回json对象 page_text = await response.text() return page_text def call_back_fun(t): # 可解析存放数据 print("结果是:",t.result()) # 爬取网址目标 loc_list = [ "https://www.taobao.com/" , "https://www.jd.com/" ] # 创建事件循环 loop = asyncio.get_event_loop() # 存储任务对象 task_list = [] for i in loc_list: # 在loop中添加任务对象 task = loop.create_task(request(i)) # 对每个任务对象进行回调函数绑定 task.add_done_callback(call_back_fun) # 将任务存入列表 task_list.append(task) # 启动loop loop.run_until_complete(asyncio.wait(task_list))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
基于协程的数据爬取
一般思路:
1. 将数据地址存入列表
2. 通过协程函数进行异步爬取
3. 通过回调函数进行数据解析和储存
- 1
- 2
- 3
- 4
import os import asyncio import aiohttp header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.5211 SLBChan/25" } # 传入url和图片名称 async def request(url_1, name): async with aiohttp.ClientSession() as session: async with await session.get(url_1,headers=header) as response: page_text = await response.read() return [page_text, name] # 把数据和图片名称给回调函数 # 回调参数是列表形式 # 由于request函数直接返回的是图片数据就没有进行数据解析的需要(和通用爬虫聚焦爬虫使用情况相同) def call_back_fun(t): # 数据命名 data=t.result()[0] # 存储名称 name=t.result()[1] with open("./图片爬取/" + name + ".jpg", mode="wb") as fp: fp.write(data) print(name," has been over") # 爬取网址目标(两张图片地址) loc_list = [ "https://img1.baidu.com/it/u=684012728,3682755741&fm=26&fmt=auto&gp=0.jpg" , "https://img2.baidu.com/it/u=3236440276,662654086&fm=26&fmt=auto&gp=0.jpg" ] name_list = ["小姐姐1", "小姐姐2"] # 创建事件循环 loop = asyncio.get_event_loop() # 存储任务对象 task_list = [] for j, i in enumerate(loc_list): # 在loop中添加任务对象 task = loop.create_task(request(i, name_list[j])) # 对每个任务对象进行回调函数绑定 task.add_done_callback(call_back_fun) # 将任务存入列表 task_list.append(task) if not os.path.exists("./图片爬取"): os.mkdir("./图片爬取") # 启动loop loop.run_until_complete(asyncio.wait(task_list))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53


over
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/739830
推荐阅读
![[nlp] torch.load 和 torch.load_state_dict 有什么区别](https://img-blog.csdnimg.cn/img_convert/77fcfea2a41749d7867f62f0e98b01ca.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)
相关标签

