
- 1vue2.0 集成UEditor富文本编辑器_vue2富文本编辑器
- 2win10专业版关闭Windows Defender Antivirus
- 3(YOLOv5-lite)-ONNX模型转换及Openvino推理_yolov5 lite openvino
- 4软考高级之系统分析师及系统架构设计师备考过程记录
- 5utf8mb4_0900_ai_ci_utf8mb40900aici
- 6【银行测试】超细支付功能测试+测试点总结分析(详全)_围绕银行的付款功能和接口进行测试分析
- 7《伸手系列》之arm架构服务器安装kubernetes_kubernetes arm版安装包下载
- 8【C++ QT项目实战-03】---- C++ QT系统实现读取JSON文件数据的自动化模式_qt读json文件
- 9Kafka环境搭建
- 10java 字符数组对象_java-将对象数组转换为字符串数组
智能优化算法——灰狼优化算法(Python&Matlab实现)_灰狼算法
赞
踩
目录
1 灰狼优化算法基本思想
灰狼优化算法是一种群智能优化算法,它的独特之处在于一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进。在了解灰狼优化算法的特点之前,我们有必要了解灰狼群中的等级制度。


灰狼群一般分为4个等级:处于第一等级的灰狼用α表示,处于第二阶级的灰狼用β表示,处于第三阶段的灰狼用δ表示,处于第四等级的灰狼用ω表示。按照上述等级的划分,灰狼α对灰狼β、δ和ω有绝对的支配权;灰狼ω对灰狼δ和ω有绝对的支配权;灰狼δ对灰狼ω有绝对的支配权。
2 灰狼捕食猎物过程
GWO 优化过程包含了灰狼的社会等级分层、跟踪、包围和攻击猎物等步骤,其步骤具体情况如下所示。
2.1 社会等级分层
当设计 GWO 时,首先需构建灰狼社会等级层次模型。计算种群每个个体的适应度,将狼群中适应度最好的三匹灰狼依次标记为


编辑、


、


而剩下的灰狼标记为


。也就是说,灰狼群体中的社会等级从高往低排列依次为
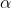

编辑、


、


及


。GWO 的优化过程主要由每代种群中的最好三个解(即
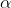

、


、


)来指导完成。
2.2 包围猎物
灰狼群体通过以下几个公式逐渐接近并包围猎物:


式中,t是当前的迭代代数,A和C是系数向量,Xp和X分别是猎物的位置向量和灰狼的位置向量。A和C的计算公式如下:

式中,a是收敛因子,随着迭代次数从2线性减小到0,r1和r 2服从[ 0,1]之间的均匀分布。
2.3 狩猎
狼群中其他灰狼个体Xi根据α、β和百的位置Xa、XB和Xo来更新各自的位置:

式中,Da,Dβ和D6分别表示a,β和5与其他个体间的距离;Xa,Xβ和X6分别代表a,β和5的当前位置;C1,C2,C3是随机向量,X是当前灰狼的位置。
灰狼个体的位置更新公式如下:

2.4 攻击猎物
构建攻击猎物模型的过程中,根据2)中的公式,a值的减少会引起 A 的值也随之波动。换句话说,A 是一个在区间[-a,a](备注:原作者的第一篇论文里这里是[-2a,2a],后面论文里纠正为[-a,a])上的随机向量,其中a在迭代过程中呈线性下降。当 A 在[-1,1]区间上时,则捜索代理(Search Agent)的下一时刻位置可以在当前灰狼与猎物之间的任何位置上。
2.5 寻找猎物
灰狼主要依赖


、


、
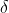

的信息来寻找猎物。它们开始分散地去搜索猎物位置信息,然后集中起来攻击猎物。对于分散模型的建立,通过|A|>1使其捜索代理远离猎物,这种搜索方式使 GWO 能进行全局搜索。GWO 算法中的另一个搜索系数是C。从2.2中的公式可知,C向量是在区间范围[0,2]上的随机值构成的向量,此系数为猎物提供了随机权重,以便増加(|C|>1)或减少(|C|<1)。这有助于 GWO 在优化过程中展示出随机搜索行为,以避免算法陷入局部最优。值得注意的是,C并不是线性下降的,C在迭代过程中是随机值,该系数有利于算法跳出局部,特别是算法在迭代的后期显得尤为重要。
3 实现步骤及程序框图
3.1 步骤
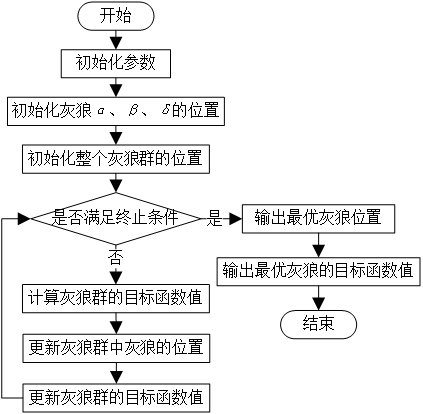
Step1:种群初始化:包括种群数量N,最大迭代次数Maxlter,调控参数a,A,C.Step2:根据变量的上下界来随机初始化灰狼个体的位置X。
Step3:计算每一头狼的适应度值,并将种群中适应度值最优的狼的位置信息保存
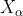

,将种群中适应度值次优的狼的位置信息保存为


,将种群中适应度第三优的灰狼的位置信息保存为


。
Step4:更新灰狼个体X的位置。
step5:更新参数a,A和C。
Step6:计算每一头灰狼的适应度值,并更新三匹头狼的最优位置。
Step7:判断是否到达最大迭代次数Maxlter,若满足则算法停止并返回Xa的值作为最终得到的最优解,否则转到Step4。
3.2 程序框图

4 Python代码实现




5 Matlab实现




