
- 1C#利用反射为属性赋值_c# 反射设置属性值
- 2网络安全---渗透测试---框架漏洞-ThinkPHP5.0、Struts2_struts2漏洞检测工具下载
- 3AI绘画Stable Diffusion 超高分辨率扩图教程:ControlNet组件-Tile妙用,增强细节保持构图完整!_controlnet-tile-sdxl-1.0怎么用
- 4python实现贪吃蛇游戏_用py写一个贪吃蛇
- 5GEC6818开发板配置网络以及telnet远程登录
- 6Python 安装下载好的 tar.gz_python安装tar.gz包
- 7树莓派系统入门教程(二)—— 连接树莓派,利用VNC和SSH登录_树莓派安装vnc服务
- 8力扣hot100-普通数组
- 9腾讯移动端推理框架NCNN_ncnn模型
- 10【MATLAB】指纹识别系统_matlab指纹识别系统
一站式解读多模态——Transformer、Embedding、主流模型与通用任务实战(下)_多任务模型训练 transformer
赞
踩
本文章由飞桨星河社区开发者高宏伟贡献。高宏伟,飞桨开发者技术专家(PPDE),飞桨领航团团长,长期在自媒体领域分享AI技术知识,博客粉丝9w+,飞桨星河社区ID为GoAI 。分享分为上下两期,本期分享从主流多模态模型和多模态实战项目等方面介绍多模态。
上篇文章主要从时间线对多模态模型进行总结,在文章最后引入模态对齐概念,本篇文章将针对经典的多模态模型展开详细介绍,围绕多模态模型如何进行模态对齐,最后以多模态框架PaddleMIX进行项目实战,欢迎大家讨论交流。
主流多模态模型介绍
本篇首先将围绕多模态模型的基本思想、模型结构、损失设计及训练数据集情况,对CLIP、BLIP、BLIP2等经典多模态模型展开详细介绍,总结如下:

CLIP
论文:Learning Transferable Visual Models From Natural Language Supervision
CLIP采用双塔结构,其核心思想是通过海量的弱监督文本对,通过对比学习,将图片和文本通过各自的预训练模型获得编码向量,通过映射到统一空间计算特征相似度,通过对角线上的标签引导编码器对齐,加速模型收敛。CLIP是一种弱对齐,可应用于图文相似度计算和文本分类等任务!
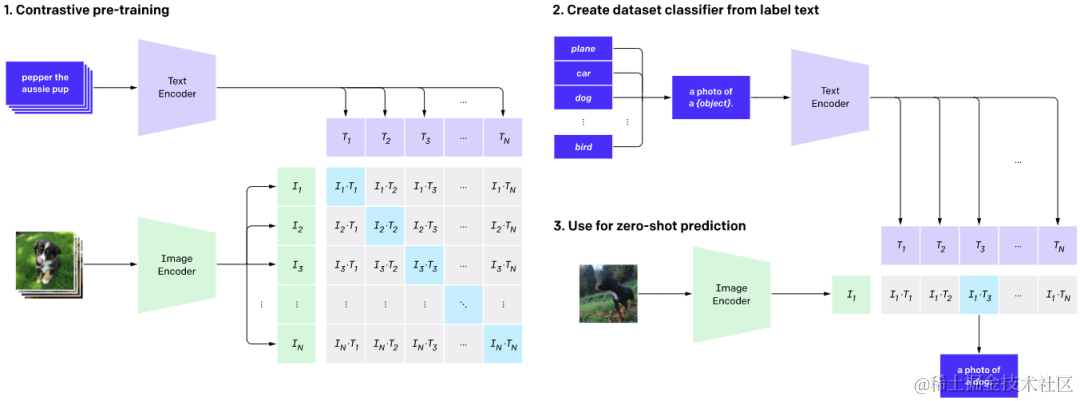
CLIP结构图CLIP具体步骤如下:
1.CLIP将图像和文本先分别输入一个图像编码器image_encoder和一个文本编码器text_encoder,得到图像和文本的向量表示 I_f 和 T_f 。其中 Image Encoder是 ResNet 或 Vision Transformer,Text Encoder 为 GPT-2。
2.将图像和文本的向量表示映射到一个多模态空间(不同类型的数据整合到一个统一的空间),得到新的可直接进行比较的图像和文本的向量表示 I_e 和T_e 。
3.计算图像向量和文本向量之间的cosine相似度。上述得到n x n矩阵,对角线为正样本为 1,其他为负样本0。有了n个图像的特征和n个文本的特征之后,计算 cosine similarity,得到的相似度用来做分类的logits。
4.对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。logits 和 ground truth 的labels 计算交叉熵损失,loss_i,loss_t分别是 Image 和 Text 的 loss,最后求平均就得到loss。CLIP代码示例:
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
BLIP
论文:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (统一视觉语言理解和生成的引导语言图像预训练)
代码地址:https://github.com/salesforce/BLIP
BLIP既可以做内容理解,还可以做文本生成,是一个大一统的多模态预训练框架。(理解+生成)
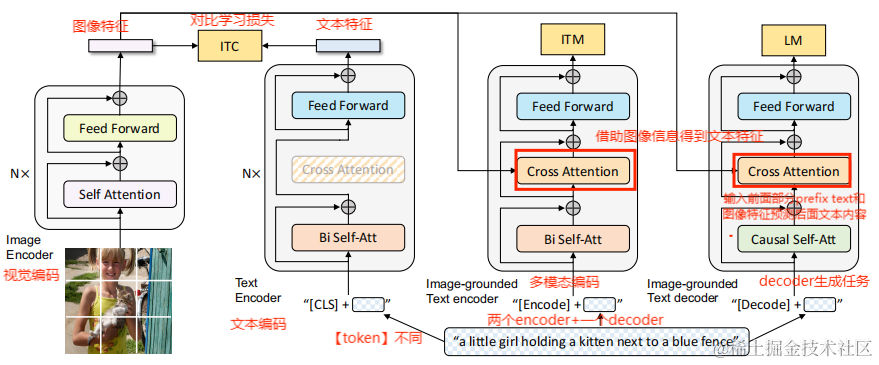
BLIP结构图
引用来源:论文《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation》
模型组成
BLIP由四个模块组成,分别是image encoder、text encoder(和image encoder 统一称为unimodal encoder)、image-grounded text encoder、image-grounded text decoder。
-
Image encoder:visual transformer,VIT
-
text encoder:BERT(双向自注意力机制+FFN),加一个 cls_token放在text input前面总结整句话
-
image-grounded text encoder:将image encoder的输出一起输入cross attention中(image embedding作为key,value,text embedding作为query),输入端加一个任务特定的encoder token,采用双向自注意力机制,使得text全部可见。
-
image-grounded text decoder:将image encoder的输出一起输入cross attention中(image embedding作为key,value,text embedding作为query),输入端加一个任务特定的decoder token,attention采用causal self-attention,使得text只能见到当前和历史的文本。
损失构成
BLIP由三个损失函数监督,前两个是understanding-based ,另一个是generation-based。具体损失如下:
Image-Text Contrastive Loss (ITC)
ITC通过对比学习,鼓励正向的图像-文本对在特征空间内靠近,与负向对相远离,对齐视觉和文本转换器的特征空间。研究表明,ITC有效地促进了视觉和语言理解的提升。为了强化这一过程,ITC引入了动态编码器以产生特征,并利用软标签作为训练目标,以识别负对中潜在的正对。
Image-Text Matching Loss (ITM)
ITM专注于学习精细的视觉-语言对齐多模态表示。作为一个二分类任务,ITM用于预测图像-文本对是否匹配,通过线性层(ITM头)和它们的多模态特征。采用硬负采样策略,选择批次中对比相似度较高的负对参与损失计算,以获得更信息丰富的负样本。与ITC不同,ITM直接处理图像输入,能更精确地判断图像与文本的一致性。
Language Modeling Loss (LM)
LM旨在基于给定图像生成文本描述。LM通过交叉熵损失优化,以自回归形式训练模型,最大化文本可能性。在计算损失时,采用了0.1的标签平滑策略。不同于VLP中广泛使用的Masked Language Modeling损失,LM赋予模型根据视觉信息生成连贯文本描述的泛化能力。
数据生产
BLIP的关键创新在于引入了预训练部分的Filter和Captioner模块。尽管CLIP使用了超过4亿个未经筛选的网络数据进行训练,但由于数据中包含大量噪声,模型的准确性受到了影响。在此基础上,BLIP引入了以下两个模块:Filter和Captioner。
Filter用于清除不匹配的文本信息(去除噪声图像-文本对),而Captioner用于生成高质量文本信息(生成给定web图像的标题),进而提升图像-文本对训练数据集质量。两种都是通过相同的预训练MED模型进行初始化,并在COCO数据集上分别进行微调,调优是一个轻量级的过程。
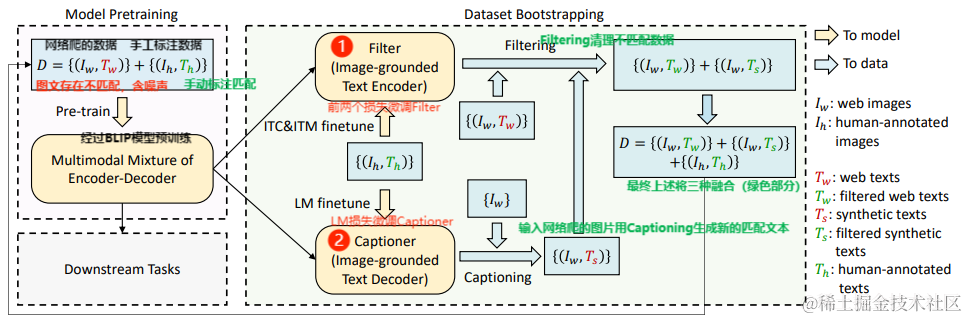
BLIP数据生产过程(Filter和Captioner模块)
引用来源:论文《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation》
具体来说,首先,BLIP使用从网络爬取到的可能不匹配的数据和部分人工标注的匹配数据(如COCO数据集)组成的数据集D进行预训练。BLIP利用人工标注的数据和内部的ITC&ITM模块微调Filter,筛选出不匹配的图像-文本对。其次,使用同样的标注数据和BLIP的Decoder微调Captioner,使其能根据图像生成匹配的文本。这些新文本再通过Filter判断其与原图像的匹配程度。
注:Captioner生成的文本并非始终比网络数据更匹配,但提供了更多选择,以实现更优的匹配结果。通过这种方法,BLIP能构建一个高质量的新数据集D。
BLIP-2
论文:Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models (节约多模态训练成本:冻结预训练好的视觉语言模型参数 )
代码:
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
为减少计算成本并避免灾难性遗忘的问题,BLIP-2 在预训练时冻结预训练图像模型和语言模型,但简单地冻结预训练模型参数会导致视觉特征和文本特征难以对齐。论文中,作者提出了一种预训练框架,利用 “预训练frozen冻结的图像编码器 + 可学习的Q-Former” 和 “预训练frozen冻结的LLM大规模语言模型” 来进行图像和语言的联合预训练。
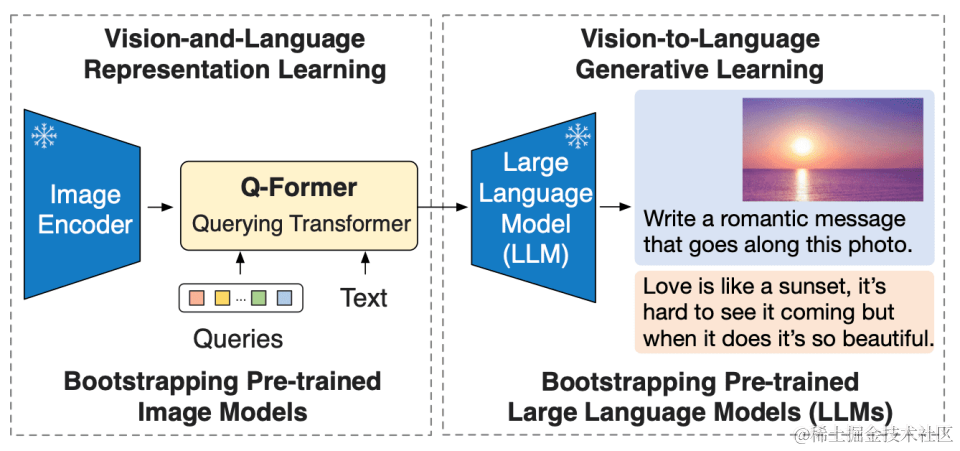
引用来源:论文《Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models》
1)Image Encoder:负责从输入图片中提取视觉特征,本文试验CLIP 训练的 ViT-L/14和EVA-CLIP训练的 ViT-g/14两种网络结构。
2)Large Language Model:负责文本生成,本文试验decoder-based LLM and encoder-decoder-based LLM。
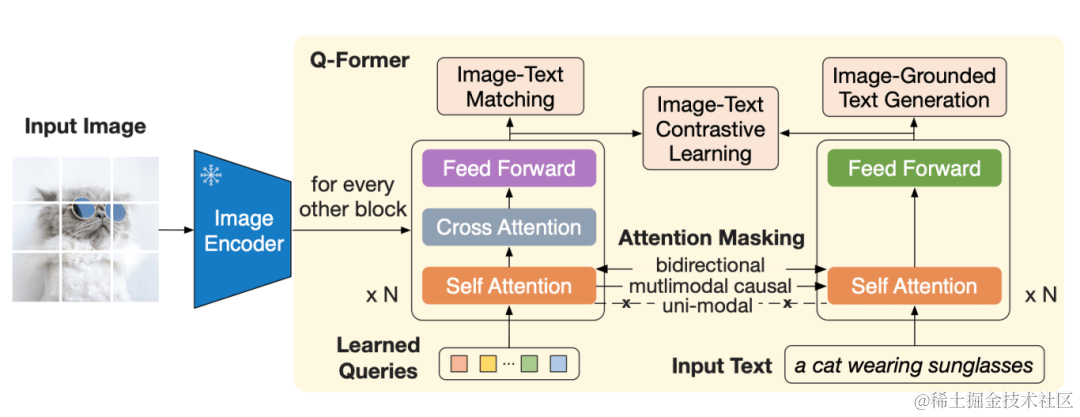
3)Q-Former:为BLIP2核心使用,用两阶段预训练 Q-Former 来弥补模态差距,共分为表示学习和生成学习两个阶段。
第一阶段:表征学习
BLIP2第二阶段
引用来源:论文《Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models》
学习阶段:Q-Former作为桥梁,来衔接图像编码器和LLM,并缩小两者表征上的GAP。Q-Former整体训练目标沿用BLIP(即图文匹配,图生文,图文对比学习),但在框架上更加精简,使用UniLM风格的统一自编码和自回归,使得由BERT随机初始化的32个Learned Queries将图像编码器的表示在语言空间中压缩对齐(其中,CA为每两层插入一次,用于融合图片视觉表征)。
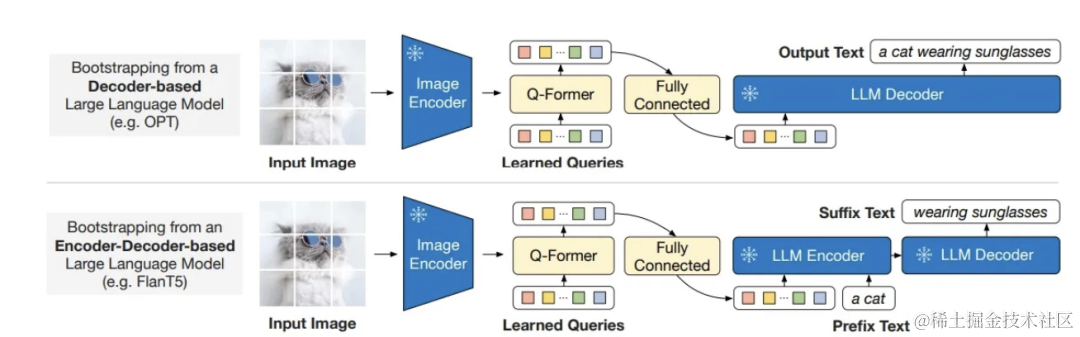
第二阶段:从大规模语言模型学习视觉到语言生成
生成学习阶段:将 Q-Former连接到冻结的 LLM,以利用 LLM 的语言生成能力。这里使用全连接层(FC,可视为Q-Former到LLM的适配器)将输出的Query嵌入线性投影到与 LLM 的文本嵌入相同的维度,然后将投影的Query嵌入添加到输入文本嵌入前面,实现替换LLM的部分文本嵌入(即软提示)。
由于 Q-Former 已经过预训练,可以提取包含语言信息的视觉表示,因此它可以有效地充当信息瓶颈,将最有用的信息提供给 LLM,同时删除不相关的视觉信息,减轻了 LLM 学习视觉语言对齐的负担。BLIP2在Decoder-only 和Encoder-Decoder 架构的模型上均进行了实验。
BLIP2第二阶段
引用来源:论文《Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models》
多模态实战项目
实战平台:本次实战平台环境推荐采用飞桨星河社区,平台项目展示页面如下。
飞桨星河社区提供强大易用的环境,包括上传自己的数据集及训练可视化,还可以加载多任务套件(PaddleNLP、PaddleOCR、PaddleDetection、PaddleClas任等),更大的亮点在于轻量代码实现,共同助力开发者轻松进行深度学习。相比个人环境,飞桨平台已预配环境,用户无需自行安装GPU环境可直接编程、运行实验,用户注册后进入BML Code Lab享受编程乐趣,可快速搭建模型,降低门槛。
PaddleMIX 介绍
官网Github:PaddleMIX PaddleMIX是基于飞桨的跨模态大模型开发套件,聚合图像、文本、视频等多种模态,覆盖视觉语言预训练、文生图、文生视频等丰富的跨模态任务。提供开箱即用的开发体验,同时满足开发者灵活定制需求,探索通用人工智能。目前支持的多模态预训练模型:

1. 使用教程
克隆PaddleMIX项目:
git clone https://github.com/PaddlePaddle/PaddleMIX
- 1
安装PaddleMIX和ppdiffusers环境
cd PaddleMIX
pip install -e .
cd ppdiffusers
pip install -e .
- 1
- 2
- 3
- 4
安装appflow 依赖环境
pip install -r paddlemix/appflow/requirements.txt
- 1
2. 一键预测
PaddleMIX提供一键预测功能,无需训练,覆盖图文预训练,文生图,跨模态视觉任务,实现图像编辑、图像描述、数据标注等多十几种种跨模态应用(可自行更开预训练任务模型)。以开放世界检测分割为例,在安装环境后新建如下.py脚本直接运行即可。
from paddlemix.appflow import Appflow
from ppdiffusers.utils import load_image
task = Appflow(app="openset_det_sam", #更改应用名称
models=["GroundingDino/groundingdino-swint-ogc","Sam/SamVitH-1024"], #更换模型任务,可组合
static_mode=False) #如果开启静态图推理,设置为True,默认动态图
url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/stable-diffusion-v1-4/overture-creations.png"
image_pil = load_image(url)
result = task(image=image_pil,prompt="dog")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注:以上部分模型支持SFT和Lora微调,由于篇幅原因,大家可以访问Readme文档自行查看。具体任务效果大家可以自行尝试,非常方便!下面作者将主要以PaddleMIX库中的BLIP2模型展开介绍。
基于PaddleMIX的多模态模型VQA和Caption任务–以BLIP2为例
- 环境准备
cd PaddleMIX
pip install -r requirements.txt
- 1
- 2
2.数据准备
(1)coco数据 数据部分,默认使用coco_karpathy数据,使用该数据不需另外配置,会自动下载。目前已支持 “coco_caption”,"vg_caption"等数据集训练。数据标注示例:
{'caption': 'A woman wearing a net on her head cutting a cake. ', 'image': 'val2014/COCO_val2014_000000522418.jpg', 'image_id': 'coco_522418'}
- 1
(2)自定义数据 如果需要自定义数据,推荐沿用上述数据格式处理自己的数据。更多可参考数据集中的annotations/coco_karpathy_train.json文件。在准备好自定义数据集以后, 可以使用 load_dataset() 来加载数据.
(3)模型介绍 PaddleMix支持BLIP-2系列模型,目前包括BLIP-2-OPT、BLIP-2-FlanT5
- blip2-stage1 :对应上述blip2的第一阶段预训练模型,可用于开启第二阶段预训练;
- blip2-stage2 :使用论文中数据训练好的第一阶段模型,可用于开启第二阶段预训练;
- blip2-pretrained-opt :对应论文精度Blip2第二阶段训练完成的模型,语言模型使用opt,可用于模型微调任务或进行zeroshot vqa推理;
- blip2-caption-opt :对应论文精度Blip2第二阶段训练完成并在caption数据集进行微调的模型,语言模型使用opt,可用于image caption推理;
3.BLIP2训练配置
BLIP2训练无需更改参数即可开始训练,参考代码如下:
MODEL_NAME="paddlemix/blip2-stage2"fleetrun --master '127.0.0.1' --nnodes 1 --nproc_per_node 8 --ips '127.0.0.1:8080' run_pretrain_stage2.py \
--per_device_train_batch_size 128 \
--model_name_or_path ${MODEL_NAME} \
--warmup_steps 2000 \
--eta_min 1e-5 \
--learning_rate 0.0001 \
--weight_decay 0.05 \
--num_train_epochs 10 \
--tensor_parallel_degree 1 \ #设置张量模型的并行数。
--sharding_parallel_degree 1 \ #设置分片数量,启用分片并行。
--output_dir "./output" \
--logging_steps 50 \
--do_train \
--save_strategy epoch \
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注:其中#MODEL_NAME 路径配置为 paddlemix/ + 已支持的model name(如blip2-pretrained-opt2.7b,paddlemix/blip2-stage1等) 可配置参数说明(具体请参考paddlemix/examples/blip2/run_pretrain_stage2.py)
第一阶段训练
单卡训练
CUDA_VISIBLE_DEVICES=0 python paddlemix/examples/blip2/run_pretrain_stage1.py
- 1
多卡训练
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_pretrain_stage1.py
- 1
第二阶段训练
单卡训练
CUDA_VISIBLE_DEVICES=0 python paddlemix/examples/blip2/run_pretrain_stage2.py
- 1
多卡训练
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_pretrain_stage2.py
- 1
4.评估
问答任务评估
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_eval_vqav2_zeroshot.py
- 1
生成任务评估
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_eval_caption.py
- 1
5.预测
CUDA_VISIBLE_DEVICES=0 python paddlemix/examples/blip2/run_predict.py
- 1
多模态模型趋势总结
思想:图文特征对齐、指令微调、多任务;
结构:图像编码器Image Encoder±大语言模型LLM+对齐模块 Loss;
设计:参考对比学习探索不同的图文特征对齐方式,同时增加指令微调能力;
多模态任务学习项目推荐:PaddleMIX
Github: https://github.com/PaddlePaddle/PaddleMIX
跨模态检索相关项目:多模态CLIP以文搜图注:更多完整的多模态项目可访问飞桨官方查阅!
地址:https://aistudio.baidu.com/index
全文总结
本文主要对多模态模型的概念、下游任务类型、数据集、发展时间线的基础理论进行介绍,着重讲解经典多模态大模型(CLIP、BLIP、BLIP2等)原理及结构,最后对飞桨多模态框架PaddleMIX进行介绍,对多模态通用任务基础项目实战,感兴趣的同学可访问官方Github进行学习,最后欢迎大家相互交流学习!

