
- 1关于 Uncaught (in promise) DOMException: The play() request was interrupted by a call to pause() 错误...
- 2理解循环神经网络(RNN)
- 3VSCode远程连接实验室服务器的方法记录_failed to find a non-windows ssh installed. passwo
- 4nodeJs--koa2 REST API
- 5知识图谱:基于嵌入的模型(TransE 、TransH、TransR和TransD)_transe模型
- 6倒计时1天!WAVE SUMMIT+2021峰会六大亮点提前看
- 7Linux SPI 驱动分析(1)— 结构框架_spi transfer
- 8不同格式图片相互转换的开源库分享_seticonlocation
- 9电商用户行为预测:AI大语言模型的深度学习方法_用户行为预测深度学习模型
- 10Github---使用入门及安装教程_guthub怎么看软件的安装说明
LLM Agent 自动完成数据处理工作!喝着咖啡就把活干了,妙啊!_llm agent function tools
赞
踩
前言
之前一直在研究 Chatchat 开源项目,并且已经把环境调试成功了,但是我一直想摸索一种全新的大模型的应用点,突发奇想有了一个关于数据处理的思路,因为单位里有很大部分工作都是数据处理工作,而数据处理工作平时都是调用各种小工具来进行的,如果我能使用 Agent 对话的形式,让同事通过对话就完成数据的处理工作岂不是美哉!说干就干!

环境搭建
之前写的《搭建 Langchain-Chatchat 详细过程》一文中已经详细介绍了环境的搭建过程,这里就不再赘述。
至于使用的大模型,因为现在阿里的通义千问的大模型 qwen-turbo 限时免费,注册账号之后会送 200 万的 token 额度足够用了,所以我选择了这个大模型。如果想用的话要先注册阿里云账号并进行登陆,然后按照申请教程获取 api-key 即可使用。
任务介绍
我的手里有三个文件 重点信息.xlsx、普查信息.xlsx、地址信息.xlsx,这三个文件中都有互相关联的字段挂接了关键的信息,我需要干的事情分为三步:
- 在
普查信息.xlsx文件中通过关键字段id找出和重点信息.xlsx相关的结果,将结果保存到result.csv中。 - 在
地址信息.xlsx文件中通过关键字段id找出和result.csv相关的地址信息,将结果保存到result1.csv。 - 因为
result1.csv都是非标准化的地址,所以还要使用自己写的地址匹配引擎,将result1.csv中的字段为地址的信息全部匹配到标准化的地址库上,完成标准化定位。
关键代码
我们需要在 tools 文件夹之下写两个工具函数 filter_by_field_in_two_files 和 match_address ,逻辑内容涉及到工作细节,不方便透露这里就不贴了,然后在 tools_select.py 中加入这两个要用到的工具,具体的函数含义就是其中的 description 部分,如下:
Tool.from_function(
func=filter_by_field_in_two_files,
name="filter_by_field_in_two_files",
description="Useful for when you need to find and save special info from given two files by specified field name,there is a string composed of four function parameters.which are input A filename , input B filenam, field name, output filename",
args_schema=filter_by_field_in_two_files_Input,
),
Tool.from_function(
func=match_address,
name="match_address",
description="Useful for when you need to match addresses in a file by specified field name,there is only a string composed of three function parameters which are input filename ,field name, output filename.",
args_schema=match_address_Input,
),
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 第一个函数
filter_by_field_in_two_files主要接受四个参数,包括 A 文件名,B文件名,关联字段名,结果文件名,完成从两个关联的文件中通过指定字段过滤信息并进行保存的任务。 - 第二个函数
match_address主要接受三个参数,包括文件名,字段名,结果文件名,完成将指定文件的字段内容进行地址标准化匹配的任务。
效果展示
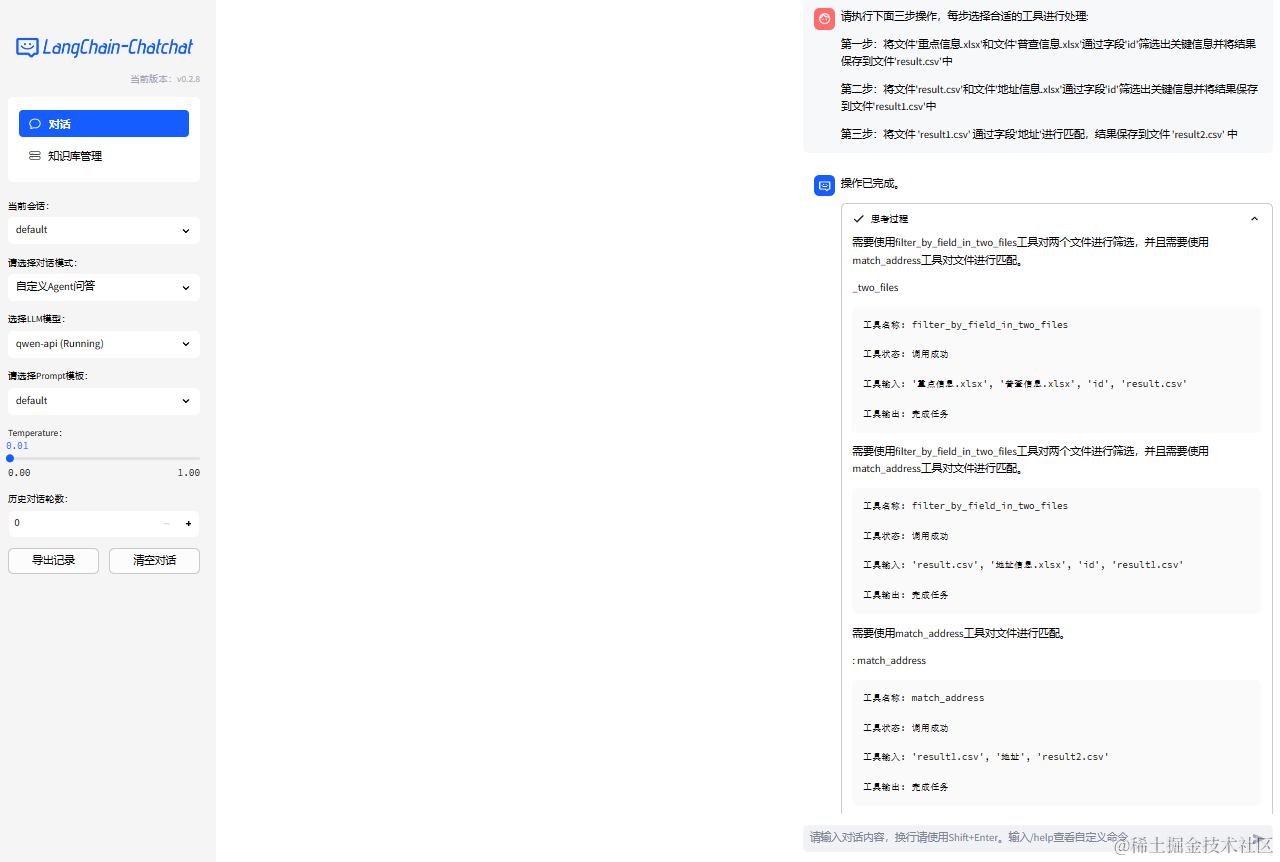
启动项目后,我选择了自己要用的大模型为线上的 qwen-api ,然后再选择对话模式为 自定义 Agent 问答,为了输出的答案比较合理,我就将 Temperature 降低为 0.01 ,然后输入自己的 Prompt 命令让大模型自动调用合适的工具去完成任务:
请执行下面三步操作,每步选择合适的工具进行处理:
第一步:将文件'重点信息.xlsx'和文件'普查信息.xlsx'通过字段'id'筛选出关键信息并将结果保存到文件'result.csv'中
第二步:将文件'result.csv'和文件'地址信息.xlsx'通过字段'id'筛选出关键信息并将结果保存到文件'result1.csv'中
第三步:将文件 'result1.csv' 通过字段'地址'进行匹配,结果保存到文件 'result2.csv' 中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以从图中看出,大模型的思考过程分为三步,每一步都将我的指令中的参数提取了出来,并且调用了合适的工具去解决。第一步和第二步都调用了 filter_by_field_in_two_files 工具,第三步调用了 match_address 工具,PERFECT!
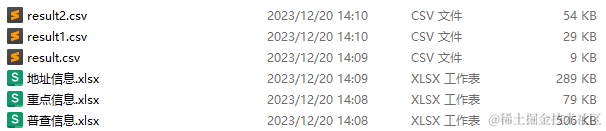
最终生成的三份结果文件也都在文件夹中,而且处理的结果内容正确,这表明大模型自动调用工具来完成数据处理的工作这一个思路是可行的。也就是说只要把关键的操作过程写成一个个具体的参数可控的工具,理论上只要大模型的理解能力足够高,操作人员只要将数据处理的需求讲清楚,大模型就可以自动调用合适的工具来自动地一步一步地完成任务。
OMG!我发现了一个震惊的结果!这下好了,这些活小学生都可以干了,又要失业一批人了。喝杯咖啡压压惊~~

参考
- 我的原文入口
- https://juejin.cn/post/7298927211994333234
- https://github.com/chatchat-space/Langchain-Chatchat
- https://link.juejin.cn/?target=https%3A%2F%2Fhelp.aliyun.com%2Fzh%2Fdashscope%2Fdeveloper-reference%2Factivate-dashscope-and-create-an-api-key
n.com%2Fzh%2Fdashscope%2Fdeveloper-reference%2Factivate-dashscope-and-create-an-api-key

