
- 1Android11以上 Audio音频调试方法_dumpsys audio
- 2英特尔 Gaudi 加速辅助生成
- 3中国大学moocpython答案查询_python,中国大学MOOC(慕课)答案公众号搜题
- 4糖尿病预测模型-Pima印第安人数据集-论文_企业科研
- 5使用C#连接Mysql数据库(保姆级)_c# mysql
- 6工业革新先锋:探索边缘智能网关P1600的自动化魔力
- 7MongoDB 数据精简指南:删除文档操作详解_mongodb删除集合中的所有文档
- 8Career Essentials in Generative AI by Microsoft and LinkedIn【微软领英生成式ai证书】教程
- 9基于SSM框架的网上商城购物系统的设计与实现(开源项目——实现CRUD功能整体流程超详细)
- 10QT+OpenCV在Android上实现人脸实时检测与目标检测_qt目标检测
大模型~合集-xx20_towards more unified in-context visual understandi
赞
踩
# Towards More Unified In-context Visual Understanding
作者提出了一个框架可以将自回归模型的优势与上下文学习的视觉语言任务的具体要求无缝集成。作者尝试了多模态输入输出的上下文学习,旨在通过特定模态的量化和共享嵌入来统一视觉语言数据,然后对预先组织好的交错上下文样本序列执行自回归预测以实现上下文推理。
Towards More Unified In-context Visual Understanding
会议:CVPR 2024
论文链接:https://arxiv.org/abs/2312.02520
作者单位:中国科学技术大学,微软亚研院,Microsoft Cloud + AI,北京理工大学,北京电子科技学院
介绍与方法动机
随着大型语言模型的快速发展,上下文学习(ICL)逐渐成为自然语言处理(NLP)领域的一种新范式。如GPT-3中所述,给定语言序列作为通用接口,该模型可以通过使用有限数量的提示和示例,快速适应以不同语言为中心的任务。这是一种基于提示和示例的策略,通过修改演示和模板,大大简化了将任务知识集成到LLM中的过程。最近,ICL已被应用在视觉理解任务中,例如语义分割和图像字幕,在推理时表现出良好的泛化性能。 一些早期工作为将ICL应用于视觉语言(VL)任务进行了一些探索,通过将图像模态用预训练的语言模型建模以实现上下文学习。例如,Flamingo[2]将图像输入作为一个特殊的标记,以文本的形式进行交错输入提示,并将视觉信息注入到具有门控交叉注意力密集块的预训练LLM中。它展示了处理各种视觉语言任务的非凡能力。然而,基于LLM解码器设计使其只能输出文本。
后续视觉上下文学习方案中,大多采用图像修复的方式,同样将示例与输入图片表示为n宫格图像,通过修复指定的输出区域以实现上下文学习[3-5]。MAE-VQGAN[3]利用视觉相关文献中的插图和信息图,基于预训练的MAE进行图像修复,显示了基本上下文推理能力。此外,Painter[4]的研究在连续像素上使用MAE进行掩码图像建模,通过将各个视觉任务的输出统一为RGB格式的图像进行上下文学习。随后,SegGPT[5]采用类似的框架解决多样化的分割任务。但上述模型只能输出图片。
如图1所示,先前的工作通常局限于特定模态的输出。我们尝试了多模态输入输出的上下文学习,旨在通过特定模态的量化和共享嵌入来统一视觉语言数据,然后对预先组织好的交错上下文样本序列执行自回归预测以实现上下文推理。
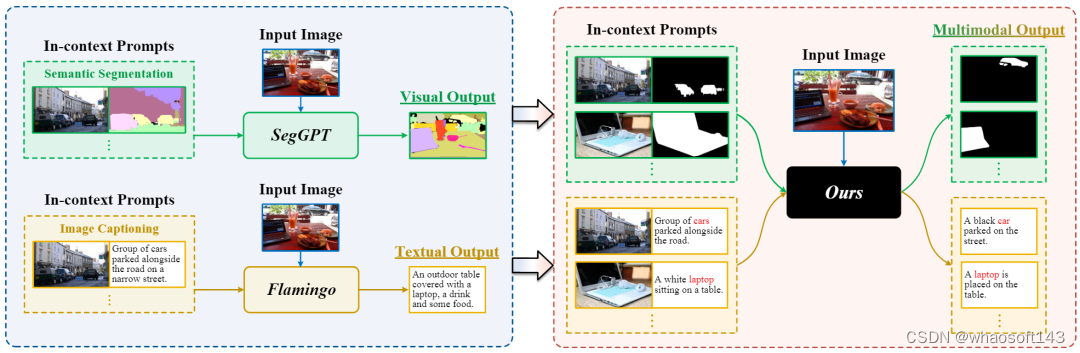
图1. 我们方法的动机说明。
方法
我们提出了一个框架可以将自回归模型的优势与上下文学习的视觉语言任务的具体要求无缝集成。主要分为三个流程:(1)通过组织良好的视觉语言提示,以描述基本的视觉理解任务,如分割和字幕。(2)在将输入转换为预定义的提示格式后,使用特定于模态的标记器将输入对的上下文提示量化为离散标记,然后使用通用嵌入网络将它们嵌入到统一表示中。(3)引入具有稀疏MoE的解码器transformer网络来对交织的统一表示执行生成建模。
视觉语言提示

多模态上下文统一嵌入框架
有了上下文任务的视觉语言提示后,需要解决的是如何对多模态数据进行建模,从DALLE的结构收到启发,我们多模态上下文统一嵌入框架实现对不同输入模态的表示。具体而言分为两个阶段:Stage1:多模态量化,为了支持多模态输入,采用模态特有的量化器对不同模态数据量化为离散token;Stage2:统一编码,对多模态的输入离散token通过特定的prompt组织后通过统一的embedding网络编码到统一空间。 whaosoft aiot http://143ai.com
经过这样的处理后,不同模态的数据在表示空间得到统一,方便下个阶段的学习。
稀疏MoE解码器框架
最后,为了对输入序列进行建模以实现上下文学习,我们决定采用transformer decoder-only的结构,基于next-token prediction的预测方式天然和上下文较为匹配。为了解决多模态和多任务可能带来的相互干扰,引入稀疏MoE结构替换decoder transformer块中的FFN,来对输入序列执行生成式建模。损失采用标准的交叉熵损失和MoE门控网络的辅助损失。所提出的多模态上下文统一嵌入框架和稀疏MoE解码器框架分别如图2和图3所示:

图2. 所提出的多模态上下文统一嵌入框架

图3. 所提出的稀疏MoE解码器框架
实验
实现细节
为了评估模型对上下文能力,我们设计了两个任务来验证模型的有效性。因此,我们利用语义线索重新定义传统视觉任务,强调视觉语言理解任务,例如语义分割和图像字幕,分别称为类感知上下文分割和描述(CA-ICL Segmentation、Captioning)。通过利用MS-COCO和Visual-Genome数据集分别构建类别实例池,我们为这两个任务构建了相应的训练与评估数据。
实现细节上,图片量化器我们采用了码本大小为1024的VQ-GAN,文本量化器采用码本大小为50257的GPT-2 BPE 量化器。我们使用 GPT-small架构来实现我们的模型,同时替换部分解码器层中的 FFN 为基于Uni-Perceiver v2引入的属性路由MoE,具体超参数参考补充材料。

消融实验
在本节中,我们从任务定义、模型定义和多任务协同训练策略三个角度进行了分析。
任务定义
在任务定义上,我们针对两个任务进行了实验上的探索。对分割任务,我们研究了不同实例大小与缩放尺度的影响,发现较大的实例与更丰富的实例缩放有助于学习。

对描述任务,我们从密集字幕和视觉定位任务中汲取灵感,分析提供对象位置信息是否有利于模型捕获上下文样本传达的语义线索。我们尝试了两种不同的边界框定义。第一种方法要求模型将目标对象的 bbox 输出为二进制掩码,其中 0 表示目标,1 表示背景。第二种方法将 bbox 信息直接集成到标题中。实验表明采用文本编码的方式更有利于模型关注到指定的区域,并且可以大大减小输入序列的长度。
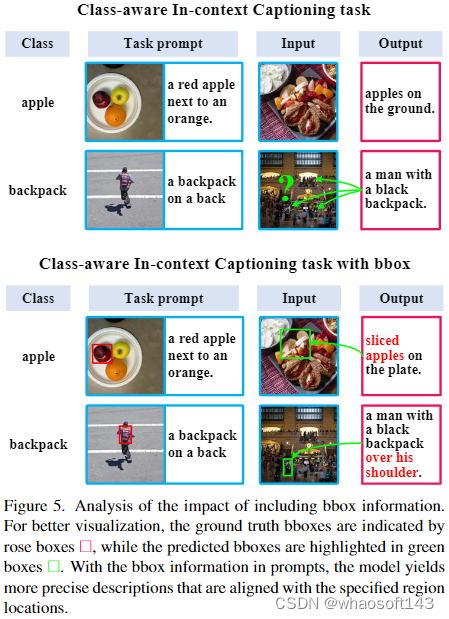
模型定义
通过将原始的GPT-2结构,单独任务训练作为基准,我们分析了不同的模型结构设置。简单地将baseline结构用于多任务训练会导致两个任务性能下降,尤其对于分割任务。因此,我们用G-shard中提出的MoE层和Uni-Perceiver v2中引入的AG_MoE替换部分变压器块中的FFN以期解决多任务联合训练的问题。结果表明AG_MoE结构可以缓解多任务之间的干扰。
多任务协同训练策略
在模型定义中我们发现采用标准 GPT-2 小型架构进行协同训练会导致性能显着下降,这表明在处理涉及不同数据模态的任务时存在相当大的差异。AG MoE架构的实现使得跨任务性能更加均衡,但与单任务场景相比仍然存在明显的性能差距。
为了进一步提高基于AG_MoE模型的性能,我们采用多任务学习范式来缓解任务干扰问题,同时稳定MoE结构的训练。我们引入了非混合批采样策略和相关的优化器。这里,每个数据集的采样权重sk被配置为与数据集大小的平方根成正比,并控制每个batch只采样一种任务数据以减小batch内干扰。并对Adam优化器梯度进行加权平衡。实现表明这可以有效地缓解多任务干扰,结合了AG_MoE结构和多任务策略在两个任务上都相对baseline有提升。

主要实验
我们与few-shot segmentation和dense captioning任务上当前最先进的专家模型以及视觉理解上下文通才SegGPT和OpenFlamingo的对比实验表明,本文所提出的多模态上下文模型可以在一个通用架构内实现相近甚至更优的性能,并具有良好的任务与模态扩展性。

可视化结果

 值得一提的是,我们对训练未见过的类别进行测试,发现模型表现出一定的OOD泛化能力。
值得一提的是,我们对训练未见过的类别进行测试,发现模型表现出一定的OOD泛化能力。

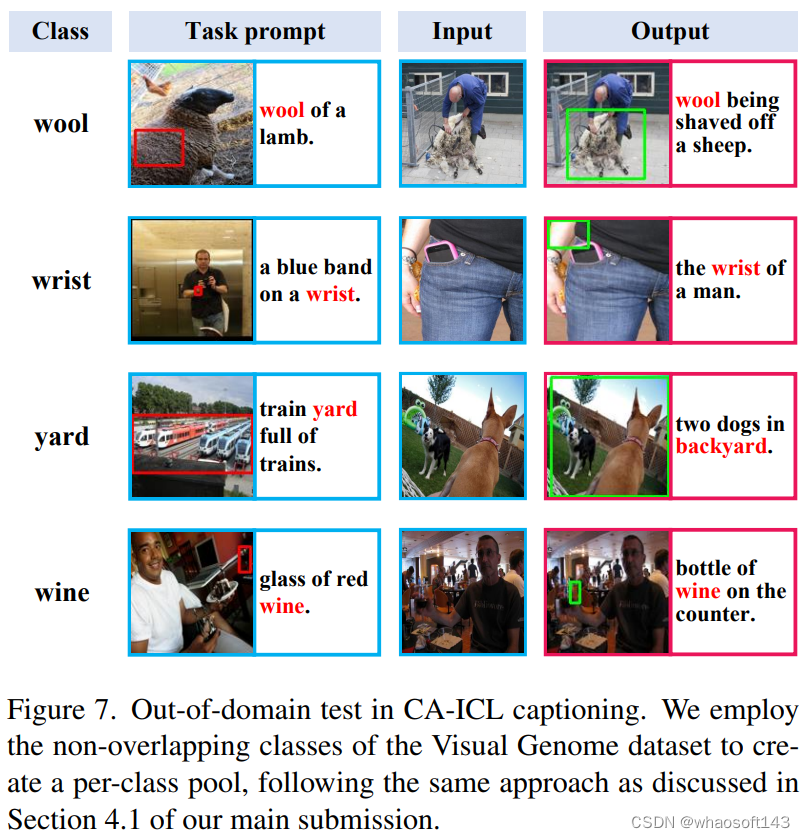 其他细节与代码开源敬请期待我们的camera-ready版本。
其他细节与代码开源敬请期待我们的camera-ready版本。
# Copilot GPTs
仅存活三个月的Copilot GPTs,因无盈利希望,被微软强制「退休」,Copilot GPTs 下月停服,Recall AI 功能也被推迟发布,微软这是啥情况?
近日,微软在其官网宣布,将于 2024 年 7 月 10 日起停止其 Copilot GPTs 服务,同时将删除所有由用户创建的既有 Copilot GPT 及相关数据。
一石激起千层浪。
不少用户在社交平台上表达强烈不满。
X 网友 NerdPropellant 表示,作为一名 Copilot GPTs 的深度用户,微软此举非常令人失望。
网友 Tim Hulse 毫不客气地指出,「这很符合微软的风格,他们总是设法让事情变得极其复杂」,甚至还拿出了陈年旧事来「鞭尸」。
人工智能影响者、宾夕法尼亚大学沃顿商学院教授 Ethan Mollick 也对此表示惊讶,认为这可能会阻碍草根用户的创新。
虽然微软给出的官方解释是,公司正在进行战略调整,会将 GPT 的重点转向商业和企业场景,但不少网友质疑,背后真正的原因可能是缺乏商业回报。
网友 Alexanaru Fartade 称,微软并未放弃,只是需要用户支付相应的费用,而这将成为企业级服务的一部分。
3月中旬,微软推出了Copilot GPT Builder 。
作为微软 Copilot Pro 订阅服务的一部分,用户每月上交20美元,可用于创建定制版本的Copilot GPT,其功能类似于微软投资的OpenAI的GPT Builder 和GPT Store。
微软当时解释道:「比如说,购买杂货的Copilot GPT可以用来根据你发送给Copilot GPT的膳食计划开列杂货采购清单。」
客户可以使用 Copilot GPT Builder 来创建、编辑和发布定制的 GPT,微软补充道:「只有你可以编辑你的 Copilot GPT,所以你可以将链接分享给 Copilot GPT,不用担心别人修改或删除链接。」
但现在,所有这些定制构建的GPTs在2024年7月14日之后将不能访问。
此外,出于安全考虑,微软还推迟了 Recall AI 功能的发布。
短命的 Copilot GPTs
近日,微软发布公告称,GPT Builder 即将退休。
「微软将从 2024 年 7 月 10 日起停止创建 GPT 的功能,并在 2024 年 7 月 10 日至 7 月 14 日期间,删除所有由微软和客户创建的 GPT 及其相关数据。」
同时微软保证,通过 GPT Builder 从 Copilot Pro 订阅者那里收集的数据将被永久删除。
由于所有数据都会被销毁,微软还向使用 Copilot GPT Builder 的用户支招,以保存已创建的 Copilot GPT 的自定义指令:
在「编辑」模式下打开自定义 Copilot GPT,然后点击「配置」标签并「复制指令将其保存至别处备用」。
不过,对那些习惯用自定义 GPT 的用户来说,这安慰可能不够暖心,以后得总装着这些指令,或手动粘贴到 Copilot 里,用起来繁琐麻烦。
那么,问题来了:微软为何要这样做呢?
要知道,三个月前,微软刚推出自定义 Copilot GPTs 和 Copilot GPT Builder 时还引发了一股热潮。
对此,微软解释称,「我们正持续审视并优化消费者版 Copilot 的扩展策略,同时将重点放在提升核心产品的用户体验上,并继续支持开发者的创新机会。为此,我们决定将 GPT 的应用中心转向商业和企业级场景,并暂停在消费者版 Copilot 上的 GPT 开发工作。」
这意味着,对于企业 Copilot 的订阅者,可能会有一种形式的 Copilot GPT Builder 存在,但微软尚未公开宣布这样的服务。
微软打的小算盘
对于微软的官方解释,网友并不买账。
不少人质疑,Copilot GPTs「被退休」的背后,是微软的人工智能在消费者市场「遇冷」。
迄今为止,微软在这波人工智能热潮中获益,主要通过两种途径:一是得益于云服务的快速增长,二是对企业广泛使用的 Teams 和 Office 等软件进行人工智能赋能。
然而,微软面向消费者的 AI 产品被 ChatGPT 盖过风头,ChatGPT 自身也已数月未见网络增长。OpenAI 的 Custom GPTs 同样未能成为市场宠儿,它们并未带来新增长,预期的 GPTs 盈利模式也未实现。
微软试图用 Bing 聊天机器人抢占谷歌搜索市场份额,但目前看来,这一尝试已告失败。尽管微软 CEO 萨提亚・纳德拉力推,但消费者似乎对用聊天机器人替代搜索引擎并不看好,或者微软的产品尚未达到改变用户习惯的水平。
微软此次撤回 GPT Builder 服务,或许意味着公司希望暂时将消费者 AI 服务限定在特定功能。
尽管用户自定义 GPTs 颇具吸引力,但内容审核和质量保证对微软而言可能是沉重负担,尤其是考虑到可能涉及大量敏感数据。而且,OpenAI 已在 ChatGPT 中免费提供类似服务。
对微软定制解决方案感兴趣的用户,现在只能转向其商业产品。
微软推迟 Recall AI 功能的发布
除了停止 Copilot GPTs 外,微软还推迟了 Recall AI 功能的发布。
6 月 13 日,也就是官宣停止 Copilot GPTs 服务后的两天,微软又宣布,将推迟其为 Copilot+ PC 设计的「Recall AI」功能的全面发布。
原计划于 6 月 18 日向 Copilot+ PC 用户全面开放的「Recall AI」,现在将先向 Windows Insider 项目的成员提供预览版。
微软决定延后「Recall AI」功能的全面推出,主要是为了在此之前收集更多用户反馈,以确保这一新功能能够完全符合公司对安全和质量的严格要求。
「Recall AI」通过在本地设备上运用人工智能技术,定期抓取屏幕截图,构建了一个可搜索的视觉化时间轴。这一功能使用户能够迅速检索到他们在应用程序、网站、图片和文档中曾经浏览过的信息。
尽管微软称赞这一特性如同拥有「摄影记忆」般提升工作效率,但同时,公众对于如何存储和处理这些敏感数据,以及其对隐私和安全性的潜在影响,也表达了合理的担忧。
为解决这些担忧,微软正在为「Recall AI」实施额外的安全措施。这包括使用由 Windows Hello 增强登录安全保护的「即时」解密,确保只有用户验证身份后才能访问「Recall AI」快照。公司还对与「Recall AI」相关的搜索索引数据库进行了加密。
虽然「Recall AI」推迟发布可能会让一些急于尝试的早期用户感到失望,但行业专家认为,这一决策是确保「Recall AI」这类 AI 工具能够长期获得成功和信任的关键。随着企业越来越多地寻求利用 AI 提升生产力和获得竞争优势,这些技术的负责任开发和部署将至关重要。
微软尚未提供「Recall AI」将何时向所有 Copilot+ PC 用户开放的具体时间表,仅透露将在收集并分析了 Windows Insider 计划的反馈之后「不久」推出。
参考链接:
https://www.zdnet.com/article/microsoft-scraps-copilot-pro-gpt-builder-after-just-3-months-how-to-save-your-work/
https://venturebeat.com/ai/microsoft-kills-off-copilot-gpt-builder-after-just-3-months/
https://support.microsoft.com/en-us/topic/gpt-builder-is-being-retired-d1de6c3a-4c7a-4bcd-98ff-2f65f3d23cd1
https://venturebeat.com/ai/microsoft-delays-broad-release-of-recall-ai-feature-due-to-security-concerns/
# ExCP
大模型Checkpoint极致压缩,精度无损存储降低70
在 Pythia-410M 模型上,实现了近乎无损的性能下达到约70倍的压缩比例。
大型语言模型最近成为人工智能领域的研究热点,然而它们的训练过程耗费巨大的计算和存储资源。因此,高效压缩存储模型的checkpoint文件显得尤为关键。我们提出了一种创新的模型 checkpoint 压缩方案(ExCP),该方案能够在保持性能几乎不受损失的前提下,显著降低训练过程中的存储开销。
首先,我们通过计算相邻 checkpoint 的残差值来捕获关键但稀疏的信息,从而提高压缩比。接下来,我们实行权重和优化器动量的联合压缩,利用优化器存储的动量信息实现更高效的压缩,并通过压缩优化器动量进一步去除 checkpoint 中的冗余参数。
最终,我们采用非均匀量化及编码压缩策略进一步减小 checkpoint 文件的存储尺寸。在从 410M 到 7B 不同规模的模型上测试我们的压缩框架,特别是在 Pythia-410M 模型上,我们实现了近乎无损的性能下达到约70倍的压缩比例。
论文标题:
ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking
论文地址:
https://arxiv.org/abs/2406.11257
代码地址:
https://github.com/Gaffey/ExCP
01 方法

1.1 Checkpoint残差
在训练过程中,当前的参数可以看作上一个checkpoint存储的权重加上逐次迭代时梯度更新的总和,这部分是相对稀疏的,包含的信息量较少,因此我们对这一残差进行压缩,可以获得更好的压缩比例。
而与此相反的,优化器中存储的动量是梯度一阶矩和二阶矩的滑动平均值,对于一阶矩来说,它的滑动平均默认的参数是0.9,在数百到数千个迭代之后与上一次checkpoint存储的内容已经没有太大的关联,所以我们对于优化器直接压缩其本身的值而非残差。最终待压缩的checkpoint我们表示为:
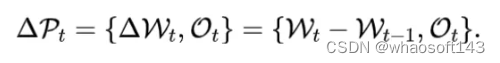
1.2 权重-优化器动量联合压缩
目前已有的模型压缩相关的工作中,大家一般只关注于模型的推理性能,或者是模型最终存储checkpoint的大小,而不关注模型在整个训练过程中对储存空间的开销。因而已有工作只对权重进行压缩,而忽略了Adam等常见优化器中实际上存储了两倍于权重数量的动量。我们的工作一方面将两者一起进行了压缩,显著提升了整体的压缩比例;另一方面也利用了权重和优化器动量的关联性,进一步提升彼此的压缩比例。
权重剪枝:由于我们剪枝的权重是残差值,优化器动量的二阶矩可以大致表示在过去一段时间内权重残差值的变化幅度,所以我们可以使用优化器动量的二阶矩作为指标来确定不同层的剪枝比例。我们的剪枝策略如下文公式所示:

1.3 整体压缩流程
我们的整体压缩流程如Algorithm 1所示,依次进行计算权重残差/联合压缩/非均匀量化/编码压缩等步骤,得到最终的压缩结果。

而恢复出checkpoint完整文件的流程则如Algorithm 2所示,进行解压缩之后,首先从非均匀量化后存储的码本和下标中恢复出浮点结果,然后再与基准权重(上一个checkpoint的原始权重或恢复出的重建权重)相加,得到checkpoint完整文件。
而恢复出整个训练流程中的checkpoint文件的流程如Algorithm 3所示,我们在完成训练后只保存初始化权重的随机种子和每个checkpoint存储的压缩结果,然后依次对checkpoint进行恢复以得到完整的checkpoint序列,以供从其中选择某个或多个checkpoint恢复训练/进行测试等。

02 实验结果
2.1 大语言模型
我们在 Pythia 和 PanGu- 上验证了我们的压缩效果,其中Pythia-410M上我们选取了Pile数据集的一个1/20的子集进行基准模型训练和带压缩的模型训练以进行对比,而 PanGu- 上我们遵从了原论文的训练策略。

可以看到,我们的结果对比原始模型几乎没有损失,同时实现了25-70倍的高倍率整体压缩。同时,我们也提供了在Pythia-410M上的训练loss曲线和checkpoint文件尺寸变化曲线。可以看到带压缩的训练loss曲线与无压缩的训练基本保持一致,损失只有非常微小的增加。
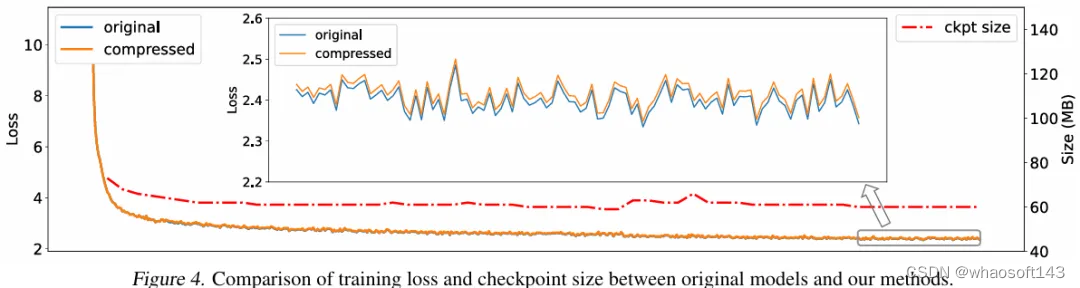
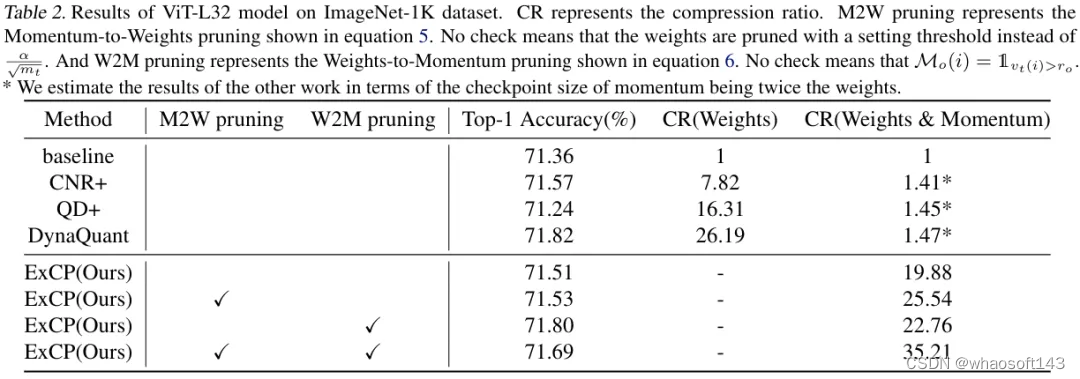
2.2 视觉模型
此外,为了方便与现有方法进行对比,我们在ViT-L32模型上进行了实验,同时比较了其他SOTA方法以及我们的不同剪枝策略。为了进行公平比较,我们根据权重和优化器动量的尺寸大小估算了其他方法的整体压缩率。但需要注意的是,即使是用其他方法在权重上的压缩率与我们的整体压缩率比较,我们仍然要高出很多。表里的消融也证明了我们联合剪枝策略的有效性。
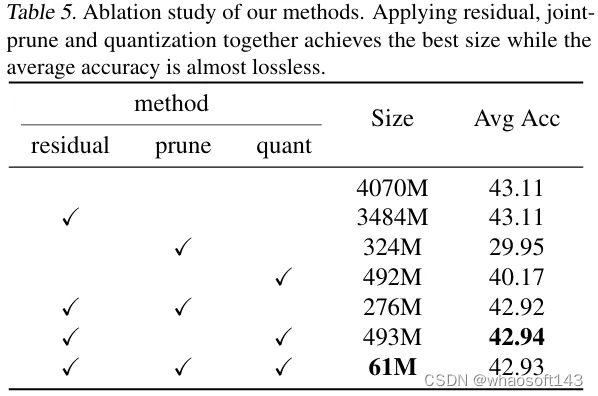
2.3 消融实验
我们进一步在Pythia-410M上进行了消融实验,尝试去除压缩流程中的不同步骤以评估各部分的效果。结果表明,直接对权重而非权重残差进行压缩时,精度损失会比较严重,联合使用残差计算、剪枝和量化能够取得最好的压缩比例和精度。
03 总结
我们提出了一个大模型Checkpoint压缩框架(ExCP),通过Checkpoint残差、权重与优化器动量的联合剪枝,以及非均匀量化等策略,在保持性能几乎不受损失的前提下,显著降低训练过程中的存储开销。我们在大型语言模型和视觉模型上均对此方法进行了评估,证实了方法的有效性。
# 最强Claude 3.5回答离谱,LeCun嘲讽LLM
LLM能否解决「狼-山羊-卷心菜」经典过河难题?最近,菲尔兹奖得主Timothy Gowers分享了实测GPT-4o的过程,模型在最简单的题目上竟然做错了,甚至网友们发现,就连Claude 3.5也无法幸免。
在经典的「狼-山羊-卷心菜」过河问题上,如今所有的LLM都失败了!
几天前,菲尔兹奖得主、剑桥大学研究主任Timothy Gowers直接拿GPT-4o开刀,去解决动物过河难题。
在此,他给出了一个新的基准——废话比率(crapness ratio),即LLM给出的总答案与正确答案之间的比率。
经过测试,Gowers发现大模型的废话比率可以达到5倍。
一开始,他先给出了一个农民带2只鸡过河,一只船只能容纳一个人和2个动物,那么农夫带着两只鸡渡河所需的最少渡河次数是多少?
别说成年人了,就拿低幼小孩子来说,一听完题目,就立马给出正确的答案。
搞笑的是,ChatGPT的回答分解了5个步骤,让人看着极其愚蠢荒谬。
第一次渡河: 农夫带着两只鸡一起过河;现状: 农夫和两只鸡在河对岸。
第二次渡河: 农夫把两只鸡留在对岸,然后独自返回;现状:农夫在起始岸,两只鸡在对岸。
第三次渡河: 农夫带一只鸡过河;现状:农夫和一只鸡在对岸,一只鸡在起始岸。
第四次渡河: 农夫把鸡留在对岸,独自返回;现状:农夫在起始岸,一只鸡在对岸。
第五次渡河: 农夫带着第二只鸡过河。现状:农夫和两只鸡都在对岸。
因此,农夫带两只鸡过河所需的最少次数是5次。
这里,ChatGPT必须在逻辑上把「农民」和人联系起来,把「鸡」和动物联系起来,然后规划出最佳的过河次数。
对此,LeCun表示,大模型全新基准——废话比率。
当然,也有为LLM打抱不平的网友。
他表示,你可以对任何人做类似的事情。如果你愿意,可以让任何一个人不及格。LLM与人类的智商相去甚远,但把它们放在极端的测试中不会很好地评估它们。
还有人劝诫道,朋友们,现在辞职太早了。
加大难度:100、1000只鸡如何?
为了得到较大的比率,Gowers这次给出了100只鸡过河的问题。
这里虽没有放出具体的解题过程,不过,Gowers表示,GPT-4o竟答对了。
接下来,再次加大难度,一个农民带1000只鸡过河,模型表现怎么样?
提示是,1000只鸡在河的一边,农夫需要将999只鸡移到河的另一边,留下1只鸡在起点。
然而,他的船上有一个洞,所以在每次渡河开始时,他可以带上十只鸡。但到渡河快结束时,船里进了太多水,如果不想让任何鸡溺水,就只能容纳两只鸡。
为了实现目标而不让任何鸡溺亡,农民最少需要渡河几次?
Gowers表示,这次的废话比率是125倍。
随后,Gowers展示了相当长的例子,却发现ChatGPT的答案比正确答案呈指数级增长。(然而,这更多与它的数学能力有关,所以有点取巧。)
在网友测试的一个案例中,即使被告知农夫根本不需要过河,GPT-4o仍提出了一个9次渡河的复杂解决方案。
而且它忽视了重要的约束条件,比如不能让鸡单独和狼在一起,这本来是完全可行的,因为农夫根本不需要过河。
Claude 3.5也失败了
在接下来的讨论中,网友用Claude 3.5进行了测试,得到了3倍的比率。
Gowers称,这算是输了。
另一个测试题中,「一个农夫带着一只羊站在河边。河上有一条船,可以容纳一个人和一只羊。农夫怎样才能用最少的船把自己和羊送到河对岸?」
Claude 3.5依旧答错了。
LLM行不行,就看提示了
一位网友分析总结了,以上LLM失败的原因。
他表示,LLM本身就是个「哑巴」,所以需要很好的提示。
上面的提示方式提供了太多不必要的信息,使得token预测变得更加困难。
如果给出更清晰的提示,LLM就能提供更清晰的解决方案。所以,不用担心AGI会很快出现。
如下是另一个名词替换的例子。
或许是模型的训练数据误导了自己,让问题变得过于复杂。
对于鸡的问题,在相同的提示下一遍又一遍地重复问题会让它更好地理解它。网友重复了5次,试了15次才得到正确的答案。
菲尔兹奖得主发现LLM数学缺陷
值得一提的是,发出渡河问题帖子的这位Timothy Gowers不仅是剑桥大学三一学院的教授。早在1998年,他就因为将泛函分析和组合学联系在一起的研究获得了菲尔兹奖。
近些年来,他的研究工作开始关注LLM在数学推理任务中的表现。
去年他与别人合著的一篇论文就指出了当今LLM评估数学任务的缺陷。
论文地址:https://www.pnas.org/doi/10.1073/pnas.2318124121
文章表示,目前评估LLM的标准方法是依赖静态的输入-输出对,这与人类使用LLM的动态、交互式情境存在较大的差异。
静态的评估限制了我们理解LLM的工作方式。为此,作者构建了交互式评估平台CheckMate和评分数据集MathConverse。
在对GPT-4、InstructGPT和ChatGPT尝试进行评估的过程中,他们果然探测到了LLM犯数学错误的一个可能原因——模型似乎倾向于依赖记忆解题。
在数学领域,记住概念和定义是必不可少的,但具体问题的解决更需要一种通用、可概括的理解。
这对于人均做过奥数题的中国人来说并不难理解。除非考试出原题,单纯把例题背下来没有任何益处,有时候还会误导思路、适得其反。
作者提出,虽然没有办法看到GPT-4的训练数据,但是从行为来看,强烈怀疑模型是「死记硬背」了看似合理的示例或者解题模式,因而给出了错误答案。
他们也发现,在LLM对数学问题的回答中,人类感知到的「有用性」和答案本身的「正确性」,这两个指标高度相关,皮尔逊相关系数高达0.83。
也许这就是为什么Gowers在推文中会用「废话比率」来调侃LLM。
其他测试
事实上,大模型被诟病推理能力已经不是一天两天了。
论文地址:https://arxiv.org/abs/2406.02061
「爱丽丝有M个兄弟,N个姐妹,请问爱丽丝的兄弟有几个姐妹?」
如果你的答案是M+1,那么恭喜你。你的推理能力已经超越了当今的几乎所有LLM。
推特网友还发现了另一个绊倒几乎所有LLM的简单问题:(剧透,只有Claude 3.5 Sonnet答对了)
「你有一个 3 加仑的水壶和一个 5 加仑的水壶,还有无限量的水。如何准确测量 5 加仑的水?」
他总结道,如果想要羞辱LLM的推理能力,只需要挑一些流行的推理/逻辑谜题,稍微修改一下语言表述,你就能搬起小板凳狂笑了。
OpenAI CTO曾放话说GPT-4已经达到了「聪明高中生」的智力水平,下一代模型要达到博士水平…这番言论放在众多LLM失败案例面前显得格外讽刺。
我们之所以会如此震惊于LLM在简单的推理任务上翻车,不仅仅是因为与语言任务的惨烈对比,更是因为这与各种基准测试的结果大相径庭。
从下面这张图中可以看到,LLM在各种基准测试上的饱和速度越来越快。
几乎是每提出一个新的测试集,模型就能迅速达到人类水平(图中0.0边界)甚至超越,其中不乏非常有挑战性的逻辑推理任务,比如需要复杂多步骤推理的BBH(Big-Bench Hard)和数学应用题测试集GSK8k。
其中的HellaSwag测试集,由华盛顿大学和Allen AI在2019年推出,专门针对人类擅长但LLM一塌糊涂的常识推理问题。
刚刚发布时,人类在HellaSwag上能达到超过95%的准确率,SOTA分数却始终难以超过48%。
但这种情况并没有持续很久。各个维度的分数持续猛涨,2023年3月,GPT-4在HellaSwag上的各项得分就逼近,甚至超过了人类水平。
https://rowanzellers.com/hellaswag/
为什么在基准测试上如此惊艳的模型,一遇到现实的数学问题就翻车?
由于我们对LLM的工作原理知之甚少,这个问题的答案也是众说纷纭。
目前的大部分研究依旧假设LLM有这方面的潜力,因此从调整模型架构、增强数据、改进训练或微调方法等方面「多管齐下」,试图解锁模型在非语言任务上的能力。
比如上面那个提出用「装水问题」测试LLM的Rolf小哥就表示,根本原因是模型的过度训练(也可以理解为过拟合),需要引入多样化的推理任务。
也有人从基准测试的角度出发,认为是数学、推理等任务的测试集设计得不够好,
Hacker News论坛上曾有数学家发文,表示GSK8k这种小学数学应用题级别的测试根本不能衡量LLM的实际数学能力。
此外,测试数据泄露也是不可忽视的因素。HellaSwag或者GSK8k这样的公开测试集一旦发布,很难不流入互联网(Reddit讨论、论文、博客文章等等),进而被抓取并纳入到LLM的训练数据中。
文章地址:https://www.jasonwei.net/blog/evals
最极端的一派当属LeCun等人了,他们坚称自回归LLM发展下去没有任何出路。
现在的模型没法推理、规划,不能理解物理世界也没有持久记忆,智能水平还赶不上一只猫,回答不了简单的逻辑问题实属意料之中。
LLM的未来究竟走向何处?最大的未知变量也许就在于,我们是否还能发现类似思维链(CoT)这种解锁模型性能的「大杀器」了。
参考资料:
https://the-decoder.com/llms-give-ridiculous-answers-to-a-simple-river-crossing-puzzle/
https://www.pnas.org/doi/10.1073/pnas.2318124121
https://claude101.com/llm-large-language-model-benchmarks/
------
Taobao 天皓智联 whaosoft aiot


