
- 1GPU加速深度学习训练_深度学习 在cuda 1上训练
- 2通信原理及系统系列31——DOA(AOA)原理分析及仿真_如何看懂通信doa文章
- 3python小助手_Python实现微信小助手
- 4Unix高级安全设置_wap5m.cc
- 5双剑合璧:CPU+GPU异构计算完全解析
- 6AI+HPC?人工智能高性能计算方向就业新路子_高性能和人工智能同时可以双份工资
- 72024新一波程序员跳槽季,闭关在家37天“吃透”这份345页PDF
- 8RK3576:革新智能设备体验的高性能AI芯片
- 9AD9361_FPGA的PL端纯逻辑(verilog)配置AD9361(五)_实现QPSK信号的数字调制_ad9361 qpsk
- 10聊聊从大模型来看NLP解决方案之UIE_paddlenlp uie模型
大咖齐聚CCIG论坛——文档图像智能分析的产业前沿_基于空域与频域关系建模的篡改文本图像检测_图像处理前沿及应用专题
赞
踩
目录
1 文档图像智能分析技术
文档图像智能分析是指使用计算机视觉和机器学习技术对文档图像进行自动化处理和分析的过程。这项技术能够将纸质文档、电子文档和图像转换成可编辑、可搜索、可索引的数字化文档,并能够自动识别文档中的各种元素,例如文字、图片、表格、图形等。

文档图像在日常生活中非常常见,例如金融票据、商业规划、技术规范、财务报表、会议记录、法律协议、合同、简历、采购订单、发票等等。因此文档图像智能处理的前景非常广阔,应用场景也会不断拓展。举例来说
- 电子博物馆:将大量历史文献、照片等材料进行数字化处理,并进行元数据标注和索引,从而创建电子博物馆,方便文化遗产的保护和传承。合合信息在这方面已有应用:焕新古文化传承之路,AI为古彝文识别赋能
- 法律文书处理:通过自动识别和提取法律文书中的各种信息,例如案号、法院名称、当事人姓名、判决结果等,从而方便进行法律文书的管理和查询;
- 财务报表处理:通过自动识别和提取财务报表中的各种信息,例如收入、支出、资产、负债等,从而方便进行财务报表的分析和管理
- …
总之,随着人工智能技术的飞速发展,文档图像智能处理将应用到医疗、教育、金融等诸多领域,为各行各业提供更加高效、智能的文档管理和数据分析解决方案。
2 大咖齐聚CCIG@2023
文档图像智能分析与处理是一个重要且极具挑战性的研究问题。其中的难点在于文档的多样性和复杂性:文档类型和格式繁多,包括报告、合同、发票、证明、证件等等。不同类型的文档有不同的格式和布局,例如文档中常常包含图片、表格、图形等各种图像,难以用统一的方法处理。而且智能文档处理受到图像质量、文字字体、文字大小、文字颜色等噪声因素的影响,容易出现误识别。此外,还有图像质量不一、文档获取繁琐等诸多问题

为了促进文档图像分析与处理领域的技术交流及发展,探讨文档图像处理及光学文字识别(OCR)相关前沿技术进展和产业应用,2023年5月13日,中国图象图形学学会文档图像分析与识别专业委员会与上海合合信息科技有限公司联合打造**《文档图像智能分析与处理》**高峰论坛。论坛特别邀请了来自中科院自动化研究所、北京大学、中科大的学术专家与华为等知名企业的研究者们,围绕文档图像处理及OCR领域的前沿技术展开“头脑风暴”,共同交流文档图像分析与处理的前沿学术进展、在典型行业的规模化应用情况,并探讨未来技术及产业发展趋势。

3 议题介绍
3.1 从模式识别到类脑研究
我们知道,在模式识别和人工智能领域,监督学习、半监督学习和无监督学习是三种不同的学习方式,它们在数据集标签的不同情况下对数据进行学习。目前不管是神经结构模拟还是学习行为模拟都是比较粗浅的,主要还是基于监督学习完成各种任务,也就是在训练数据集中已经标记好了正确答案或目标输出值。训练阶段,算法根据输入的特征和相应的目标值之间的关系进行学习,以便在未来对新数据进行准确预测。 监督学习的例子包括分类和回归问题,例如图像分类、情感分析和价格预测等。

生成式模型就是人工智能的未来发展趋势之一,相比判别式模型的独特优势,使之可以应对更多的任务,例如推动内容开发、视觉艺术创作、数字孪生、自动编程,甚至为科学研究提供AI视角、Al直觉…
| 项目 | 判别式模型 | 生成式模型 |
|---|---|---|
| 特点 | 寻找最优决策边界,反映不同模式数据间的差异性 | 寻找各模式边界,反映数据全体的统计全貌及不同模式间的相似度 |
| 联系 | 由生成式模型可推导判别式模型,反之不成立 | |
| 本质 | 对后验概率建模 | 对联合概率建模 |
| 实例 | 线性回归、Logistic回归、支持向量机、决策树、神经网络等 | 贝叶斯网络、贝叶斯分类器、隐马尔科夫模型等 |
| 性能 | 学习过程更简单,但不能反映数据本身特性 | 模型信息量更丰富、灵活,但学习过程较复杂 |
| 应用 | 图像文本分类、时间序列预测等 | 自然语言处理等 |
随着未来类脑智能研究在结构类脑和行为类人方面的深入,人工智能应用将不再局限于这类判别式模型。动物和人类表现出的学习能力和对世界的理解,远远超出了 AI 和机器学习系统。一个青少年可以在大约 20 小时的练习中学会开车,小朋友可以在只需要很少的交流后就学会语言沟通,人类可以在他们从未遇到过的情况下采取行动。
相比之下,传统的判别式模型需要花费比人类大几个量级的试验进行训练,以便在训练期间可以覆盖最意外的情况。这表明人脑的学习具有很强的灵活性,从小样本开始,不断地随环境自适应。这种学习灵活性应该是未来机器学习的一个主要研究目标。比如近期图灵奖得住LeCun提出的全新自主智能架构,最关键的一点是让机器了解世界是如何运转的,掌握广泛的现实知识,并依据此进行推理。

图源网络,侵删
3.2 视觉-语言预训练模型演进及应用
2022年12 月 1 日,OpenAI的联合创始人山姆·奥特曼在推特上公布ChatGPT并邀请人们免费试用

图源网络,侵删
ChatGPT可以与人类进行谈话般的交互,可以回答追问,连续性的问题,承认其回答中的错误,指出人类提问时的不正确前提,拒绝回答不适当的问题,其性能大大超乎人们对弱人工智能的想象。目前其影响已经席卷各行各业。ChatGPT是基于GPT-3开发的,具有强大的对话能力,能够理解语言上下文,并能够生成富有表现力和连贯的响应。所谓GPT,全称是Generative Pre-trained Transformer,本质上这是一种基于Transformer的语言模型。
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化、存储的,则是一个目前仍未探明的东西。因此,大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码。相应的,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码。在语言模型中,编码器和解码器都是由一个个的Transformer组件拼接在一起形成的
Transformer又是什么呢?它是一种用于自然语言处理和其他**序列到序列(sequence-to-sequence)**任务的神经网络架构。它于2017年由谷歌的研究人员提出,被认为是自然语言处理领域的一项重大突破。
Transformer**基于注意力机制(Attention Mechanism)构建,其核心思想是在序列中进行全局信息的交互和捕捉,而不是像以往的循环神经网络(RNN)一样在序列中逐个位置处理信息。Transformer通过多个自注意力层(Self-Attention Layer)**进行信息的交互和表示,而每个自注意力层包含了注意力机制的三个部分:查询(query)、键(key)和值(value)。
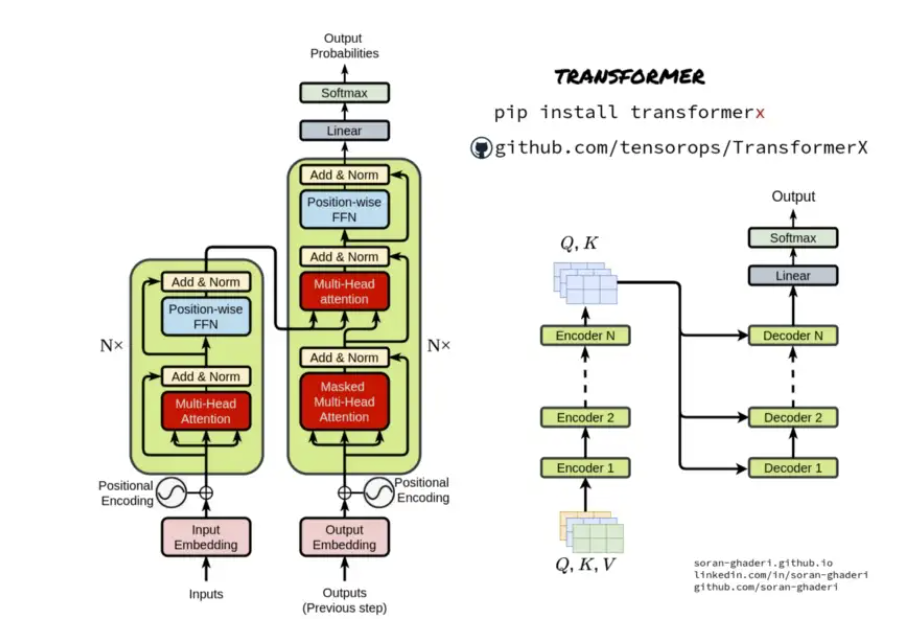
图源网络,侵删
具体来说,对于一个输入序列,Transformer将其转换为多个词向量(word embeddings),然后通过自注意力层进行特征提取。在自注意力层中,查询向量通过与所有键向量的相似度计算来计算注意力分数,这些分数用于加权求和值向量,最终得到每个位置的输出向量。然后,这些输出向量被馈送到下一个自注意力层或全连接层进行后续处理。
相比于传统的序列模型,Transformer的优点在于可以并行处理输入序列,从而加速模型的训练和推断。此外,Transformer还能够有效地处理长序列,因为它可以在不受时间限制的情况下一次性处理整个序列,而不需要像RNN那样进行逐个位置的处理。
但是,目前关于ChatGPT这类大规模预训练模型还有一些争议,主要的争论点在于:
- 超大模型学到了什么?如何验证?
- 如何从超大模型迁移“知识”,提升下游任务的性能?
- 更好的预训练任务设计、模型架构设计和训练方法?
- 选择单模态预训练模型还是多模态训练模型?
预训练模型、跨模态预训练模型方面的研究是非常值得探索的,无论是模型结构、训练策略还是预训练任务的设计都尚有非常大的潜力。例如2021年10月份Facebook发布的Video CLIP相关工作,从这个模型可以看出,Video CLIP颇具野心,期待对于下游任务不需要任务相关训练数据集,不需要进行微调,直接基于Video CLIP进行零样本迁移。这对于提升大模型的训练效率和训练效果具有非常重大的意义。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数同学面临毕业设计项目选题时,很多人都会感到无从下手,尤其是对于计算机专业的学生来说,选择一个合适的题目尤为重要。因为毕业设计不仅是我们在大学四年学习的一个总结,更是展示自己能力的重要机会。
因此收集整理了一份《2024年计算机毕业设计项目大全》,初衷也很简单,就是希望能够帮助提高效率,同时减轻大家的负担。
既有Java、Web、PHP、也有C、小程序、Python等项目供你选择,真正体系化!
由于项目比较多,这里只是将部分目录截图出来,每个节点里面都包含素材文档、项目源码、讲解视频
如果你觉得这些内容对你有帮助,可以添加VX:vip1024c (备注项目大全获取)

、Python等项目供你选择,真正体系化!**
由于项目比较多,这里只是将部分目录截图出来,每个节点里面都包含素材文档、项目源码、讲解视频
如果你觉得这些内容对你有帮助,可以添加VX:vip1024c (备注项目大全获取)
[外链图片转存中…(img-GdeVGRMW-1712574030976)]

