- 1python第八章可视化课后作业_第八章课后作业(评测版)
- 2AD7606 + STM32F407VET6_ad7606和stm32f407开发板
- 3香橙派python编程_香橙派Orange Pi 4开发板在Ubuntu系统下使用python 控制GPIO
- 4使用Spring MVC生成Excel文件_spring 生成excel
- 5本地eureka启动报错_本地启动eureka失败
- 6智慧校园解决方案_高等学校智慧校园建设
- 7 大规模旅行商问题解决方案(基于分层规划,整数规划) ...
- 8总结!AI Agent开发的常见方法
- 9[渝粤教育] 中国地质大学 机械原理 复习题_单选对于转速较高的凸轮机构为了减小冲击和振动从动件运动规律最好采用()运动规律
- 10Hive引擎MR、Tez、Spark_tez spark
NodeJS 入门
赞
踩
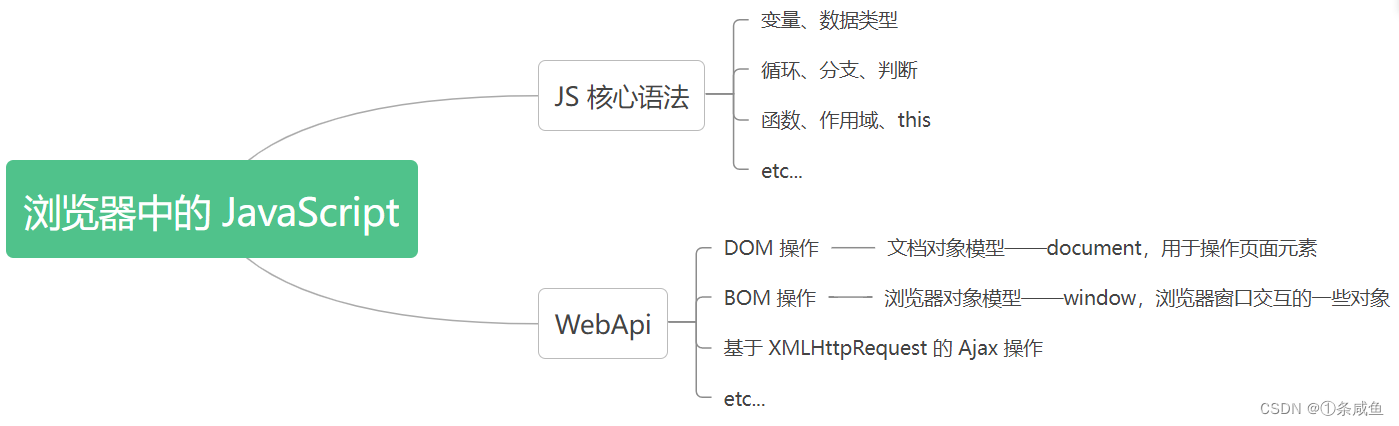
浏览器中的 JavaScript 的组成部分
NodeJS 是什么?
定义
● node.js 是一个开发平台,就像 JAVA 开发平台、.net 开发平台、PHP 开发平台
开发平台有对应的编程语言、有语言运行时、有能实现特性功能的 API(SDK:Software Development Kit)
● 该平台使用的编程语言是 JavaScript
●node.js平台基于 chrome VB JavaScript 引擎构建
● 基于 node.js 可以开发控制台程序(命令行程序、CLI程序)、桌面应用程序(GUI)(借助 node-webkit、electron 等框架实现)、Web应用程序(网址)
● node.js 全站开发技术栈:MEAN -- MongoDB Express Angular Node.js
组成部分
- require 指令:在 Node.js 中,使用 require 指令来加载和引入模块,引入的模块可以是内置模块,也可以是第三方模块或自定义模块
- 创建服务器:服务器可以监听客户端的请求,类似于 Apache、Nginx 等 HTTP 服务器
- 接受请求与响应请求:服务器很容易创建,客户端可以使用浏览器或终端发送 HTTP 请求,服务器接收请求后返回响应数据
特点
- 事件驱动(当事件被触发时,执行传递过去的回调函数)
- 非阻塞
I/O模型(当执行I/O操作时,不会阻塞线程) - 单线程
- 持有世界最大的开源库生态系统 –
npm
用途
- 基于 Express 框架 ,可以快速构建 Web 应用
- 基于 Electron 框架,可以构建跨平台的桌面应用
- 基于 restify 框架,可以快速构建 API 接口项目
- 读写和操作数据库、创建实用的命令行工具辅助前端开发
- etc…
Node Version Manager(Node 版本管理)
nvm(Linux,Unix,OS X)
- 常用命令
○nvm install node(安装最新版本的node)
○nvm use node(使用指定版本的node)
nvm-windows(Windows)
- 常用命令
○nvm version
○nvm install latest
○nvm install 版本号
○nvm uninstall 版本号
○nvm list:查看安装信息
○nvm use 版本号
node.js 开发网站和传统 PHP 等开发网站的区别
● 传统 PHP等开发网站:

● node.js 开发网站

模块操作
卸载
例如:卸载 express 模块
npm uninstall express
- 1
卸载后,可以到 /node_modules/ 目录下查看包是否还存在,或者使用以下命令查看:
npm ls
- 1
更新
例:更新 express 模块
npm update express
- 1
搜索
例:搜索 express 模块
npm search express
- 1
创建
1、创建模块,package.json 文件是必不可少的。
npm init
- 1
2、在 npm 资源库中创建用户(使用邮箱注册):
npm adduser
- 1
3、发布模块
npm publish
npm unpublish <package>@<version> # 可以撤销发布自己发布过的某个版本代码
- 1
- 2
- 3
版本号
NPM 使用语义版本号来管理代码。语义版本号分为 X.Y.Z 三位,分别代表主版本号、次版本号和补丁版本号。 当代码变更时,版本号按以下原则更新。
- 如果只是修复 bug,需要更新 Z 位
- 如果是新增了功能,但是向下兼容,需要更新 Y 位
- 如果有大变动,向下不兼容,需要更新 X 位
除了可依赖一个固定版本号外,还可依赖于某个范围的版本号。例如 “argv”:“0.0.x” 表示依赖于0.0.x系列的最新版 argv
REPL
REPL全称:Read-Eval-Print-Loop(交互式解释器)
●R读取 - 读取用户输入,解析输入了JavaScript数据结构并存储在内存中
●E执行 - 执行输入的数据结构
●P打印 - 输出结果
●L循环 - 循环操作以上步骤直到用户两次按下 ctrl-c 按钮退出- 在 REPL 中编写程序(类似于浏览器开发人员工具中的控制台功能)
● 直接在控制台输入 node 命令进入 REPL 环境 - 按两次
Control + C退出 REPL 界面 或者 输入.exit退出 REPL 界面 - Node REPL 支持输入多行表达式,这就有点类似 JavaScript。
使用变量
变量声明需要使用 var 关键字,如果没有使用 var 关键字变量会直接打印出来
使用 var 关键字的变量可以使用 console.log()来输出变量
> x = 10
10
> var y = 10
undefined
> x + y
20
- 1
- 2
- 3
- 4
- 5
- 6
下划线(_)变量
(_) 获取表达式的运算结果:
> var x = 10
undefined
> var y = 10
undefined
> x + y
20
> var sum = _
undefined
> console.log(sum);
30
undefined
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
命令
ctrl + c- 退出当前终端ctrl + c 按下两次- 退出 Node REPLctrl + d- 退出 Node REPL向上/向下 键- 查看输入的历史命令tab 键- 列出当前命令.help- 列出使用命令.break- 退出多行表达式.clear- 退出多行表达式.save filename- 保存当前的 Node REPL 会话到指定文件.load filename- 载入当前 Node REPL 会话的内容
回调函数
Node.js 异步编程的直接体现就是回调。
异步编程依托于回调来实现,但不能说使用了回调后程序就异步化了。
回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数。
回调函数一般作为函数的最后一个参数出现,回调函数接收错误对象作为第一个参数:
function foo1(name, age, callback) { }
function foo2(value, callback1, callback2) { }
- 1
- 2
实例
阻塞是按顺序执行的,非阻塞是不需要按顺序执行的。
- 阻塞:
fs.readFileSync() - 非阻塞:
fs.readFile()
// input.txt
这是一段文字!!!
- 1
- 2
阻塞
// 1.js
var fs = require('fs');
var data = fs.readFileSync('input.txt');
console.log(data.toString());
console.log('程序执行结束!');
- 1
- 2
- 3
- 4
- 5
- 6
执行结果:
> node 1.js
这是一段文字!!!
程序执行结束!
- 1
- 2
- 3
非阻塞
// 1.js
var fs = require('fs');
fs.readFile('input.txt', function(err, data) {
if(err) return console.error(err);
console.log(data.toString());
});
console.log('程序执行结束!');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
执行结果:
> node 1.js
程序执行结束!
这是一段文字!!!
- 1
- 2
- 3
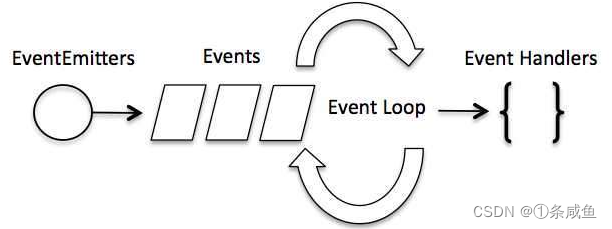
事件循环
- Node.js 是单进程单线程应用程序,但是因为 V8 引擎提供的异步执行回调接口,通过这些接口可以处理大量的并发,所以性能非常高
- Node.js 几乎每一个 API 都是支持回调函数的
- Node.js 基本上所有的事件机制都是用设计者模式中观察者模式实现
- 观察者模式:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新
- Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件观察者退出,每个异步事件都生成一个事件观察者,如果有事件发生就调用该回调函数.
事件驱动程序
Node.js 使用事件驱动模型,当 web server 接收到请求,就把它关闭然后进行处理,然后去服务下一个 web 请求。
当这个请求完成,它就被放回处理队列,当到达队列开头,这个结果被返回给用户。
webserver 一直接受请求而不等待任何读写操作。(这也称之为非阻塞式IO或者事件驱动IO)
在事件驱动模型中,会生成一个主循环来监听事件,当检测到事件时触发回调函数。
EventEmitter——绑定和监听事件
Node.js所有的异步I/O操作在完成时都会发送一个事件到事件队列。
Node.js里面的许多对象都会分发事件:一个 net.Server 对象会在每次有新连接时触发一个事件,一个 fs.readStream 对象会在文件被打开的时候触发一个事件。所有这些产生事件的对象都是 event.EventEmitter 的实例。
EventEmitter 的核心就是事件触发与事件监听器功能的封装。可以通过require("events")来访问这个模块
EventEmitter 对象如果在实例化时发生错误,会触发 error 事件。当添加新的监听器时,newListener 事件会触发,当监听器被移除时,removeListener 事件被触发。
// 引入 events 模块
const events = require('events');
// 创建 eventEmitter 对象
const eventEmitter = new events.EventEmitter();
// 绑定事件及事件的处理程序
eventEmitter.on('eventName', eventHandler);
// 触发事件
eventEmitter.emit('eventName');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
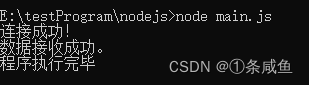
// 菜鸟例子----main.js // 引入 events 模块 const events = require('events'); // 创建 eventEmitter 对象 const eventEmitter = new events.EventEmitter(); // 创建事件处理程序 const connectHandler = function connected() { console.log("连接成功!"); // 触发 data_received 事件 eventEmitter.emit('data_received'); } // 绑定 connection 事件处理程序 eventEmitter.on('connection', connectHandler); // 使用匿名函数绑定 data_received 事件 eventEmitter.on('data_received', function() { console.log('数据接收成功。') }) // 触发 connection 事件 eventEmitter.emit('connection'); console.log('程序执行完毕');

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
EventEmitter 的每个事件由一个事件名和若干个参数组成,事件名是一个字符串,通常表达一定的语义。对于每个事件,EventEmitter 支持若干个事件监听器。
当事件触发时,注册到这个事件的事件监听器被依次调用,事件参数作为回调函数参数传递。
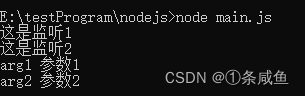
const events = require("events");
const eventsEmitter = new events.EventEmitter();
eventsEmitter.on("func_name", function() {
console.log("这是监听1");
});
eventsEmitter.on('func_name', function(arg1, arg2) {
console.log("这是监听2");
console.log("arg1", arg1);
console.log("arg2", arg2);
})
eventsEmitter.emit("func_name", "参数1", "参数2");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
方法
-
addListener(event, listener):为指定事件添加一个监听器到监听器数组的尾部 -
on(event, listener):为指定事件注册一个监听器,接受一个字符串 event 和一个回调函数 -
once(event, listener):为指定事件注册一个单次监听器,即 监听器最多只会触发一次,触发后立刻解除该监听器 -
removeListener(event, listener):移除指定事件的某个监听器,监听器必须是该事件已经注册过的监听器。它接受两个参数,第一个是事件名称,第二个回调函数名称 -
removeAllListeners([event]):移除所有事件的所有监听器,如果指定事件,则移除指定事件的所有监听器 -
sexMaxListeners(n):默认情况下,EventEmitters 如果你添加的监听器超过 10 个就会输出警告信息。 setMaxListeners 函数用于改变监听器的默认限制的数量。 -
listeners(event):返回指定事件的监听器数组 -
emit(event, [arg1], [arg2], [...]):按监听器的顺序执行每个监听器,如果事件有注册监听返回 true,否则返回 false -
listenerCount(emitter, event):返回指定事件的监听器数量。events.emitter.listenerCount(eventName);- 1
API 操作
全局模块可以直接使用,而非全局模块需要先通过 require('') 加载该模块。

fs 文件系统模块
fs模块是 Node.js 官方提供的,用来操作文件的模块。它提供了一系列的方法和属性,用来满足用户对文件的操作需求。
fs.readFile(path, [, options], callback)方法,用来读取指定文件中的内容- path:必选参数,字符串,表示文件的路径
- options:可选参数,表示以什么编码格式来读取文件
- callback:必选参数,文件读取完成后,通过回调函数拿到读取的结果
fs.writeFile()方法,用来向指定的文件中写入内容
如果要在 JavaScript 代码中,使用 fs 模块来操作文件,则需要使用如下的方式先导入它:
const fs = require('fs')
- 1
例子:
// fs.js // 执行文件操作 // 实现文件写入操作 // 1.加载文件操作模块: fs 模块 var fs = require('fs'); // 2.实现文件写入操作 let msg = 'hello world, 你好世界!'; // 3.调用 fs.writeFile() 进行文件写入 // fs.writeFile(file, data[, options], callback) fs.writeFile('./hello.txt', msg, 'utf-8', function(err) { // 如果 err === null,表示写入文件成功,没有错误! // 只要 err 里面不是 null,就表示写入文件失败! if(err) { console.log('写文件失败!具体错误为:', err); } else { console.log('写入成功啦!') } }) // 读取文件 // 如果传递了编码(utf8),那么回调函数中的 data 默认就会转换为字符串,没有的话则为一个 Buffer 对象,需要将 buffer 对象转换为字符串,调用 toString()方法 fs.readFile('./hello.txt', 'utf8', function(err, msg) { if(err) { throw err; } })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

node.js中单线程-非阻塞IO解释
JavaScript V8 引擎:堆和调用栈

浏览器:

__dirname 和 __filename
__dirname: 当前正在执行的 js 文件所在的目录__filename:当前正在执行的 js 文件的完整路径
__dirname 和 __filename 并不是全局的
/* * 此处的 ./ 相对路径,相对的是执行 node 命令的路径 * 而不是相对于正在执行的这个 js 文件来查找 hello.txt */ fs.readFile('./hello.txt', 'utf8', function(err, msg) { if(err) { throw err; } }); // 解决方案: // __dirname: 当前正在执行的 js 文件所在的目录 // __filename:当前正在执行的 js 文件的完整路径 // __dirname 和 __filename 并不是全局的 var filename = __dirname + '\\' + 'hello.txt'; fs.readFile(filename, 'utf8', function(err, msg) { if(err) { throw err; } });
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
通过 path 模块进行路径拼接
var path = require('path');
var filename = path.join(__dirname, 'hello,txt');
fs.readFile(filename, 'utf8', function(err, msg) {
if(err) {
throw err;
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
http 服务
request(http.IncomingMessage)和 response(ServerResponse)
request:服务器解析用户提交的http请求报文,将结果解析到request对象中,凡是要获取和用户相关的数据都可以通过 request 对象获取request对象类型<http.IncomingMessage>,继承自stream.Readablerequest对象常用成员
■request.header:返回的是一个对象,这个对象包含了所有的请求报文头
■request.rawHeaders:返回的是一个数组,数组中保存的都是请求报文头的字符串
■request.httpVersion:获取请求客户端所使用的http版本
■request.method:获取客户端请求使用的方法(post、get…)
■request.url:获取这次请求的路径(获取请求报文中的请求路径,不包含主机名称、端口号、协议)
response:在服务器端用来向用户做出响应的对象,凡是需要向用户(客户端)响应的操作,都需要通过response对象来进行



通过 http 模块构建一个简单的 http 服务程序
// 1.加载 http 模块 var http = require('http'); // 2.创建一个 http 服务对象 var server = http.createServer(); // 3.监听用户的请求事件(request 事件) // request 对象包含了用户请求报文中的所有内容,通过 request 对象可以获取所有用户提交过来的数据 // response 对象用来向对象响应一些数据,当服务器要向客户端响应数据的时候必须使用 response 对象 server.on('request', function(request, response) { // body... // 解决乱码的思路:服务器通过设置 http 响应报文头,告诉浏览器使用相应的编码来解析 response.setHeader('Content-Type', 'text/plain;charset=utf-8') response.write('hello world!'); // 对于每一个请求,服务器必须结束响应,否则客户端(浏览器)会一直等待服务器响应结束 response.end(); }) // 4.启动服务 server.listen(8080, function() { console.log('服务器启动了,请访问 http://localhost:8080') })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
根据不同请求做出不同响应
var http = require('http'); http.createServer(function(req, res) { // body... // 获取用户请求的路径 req.url // console.log(req.url); // 结束响应 // res.end(); req.setHeader('Content-Type', 'text/plain;charset=utf-8'); if(req.url === '/' || req.url === '/index') { res.end('Hello Index'); } else if(req.url=== '/login') { res.end('hello login') } else if(req.url === "/images/index.png") { fs.readFile(path.join(__dirname, 'images', 'index.png'), function(err, data) { // image // body... res.setHeader('Content-Type', 'text/css'); res.end(data); }) }else if(req.url === '/css/index.css') { // css fs.readFile(path.join(__dirname, 'css', 'index.css'), function(err, data) { res.setHeader('Content-Type', 'text/css'); res.end(data); } ) } }).listen(8080, function() { console.log('http://localhost:8080') })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
根据用户不同请求-读取不同HTML文件响应
var http = require('http'); var fs = require('fs'); var path = require('path') http.createServer(function(req, res) { // body... // 获取用户请求的路径 req.url // console.log(req.url); // 结束响应 // res.end(); req.setHeader('Content-Type', 'text/plain;charset=utf-8'); if(req.url === '/' || req.url === '/index') { fs.readFile(path.join(__dirname, 'htmls', 'index.html'), function(err, data) { if(err) { throw err } res.end(data); }) } }).listen(8080, function() { console.log('http://localhost:8080') })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
try-catch 与 异步操作
nodeJS:只能捕获同步操作的异常,对于异步操作的异常是无法捕获的。对于异步操作,要通过判断错误号(err.code)来进行错误处理
模拟 Apache 服务

在请求服务器的时候,请求的 url 就是一个标识

response.setHeader 和 response.writeHead
response.setHeader(name, value)
为header对象设置一个单一的header值。如果该header已经存在了,则将会被替换。
response.writeHead(statusCode[, statusMessage][, headers])
- 发送一个响应头给请求。
- 状态码是一个三位数的
HTTP状态码,如404 statusMessage是可选的状态描述headers是响应头- 该方法在消息中只能被调用一次,且必须在
response.end()被调用之前调用
区别
setHeader 只可以设置一个 header,但是 writeHead 可以设置多个 headers,其中第一个是状态码,第二个是包含 headers 的对象。
当使用 response.setHeader() 设置响应头时,它们将与传给 response.writeHead() 的任何响应头合并,其中 response.writeHead() 的响应头优先。
重定向
浏览器路由跳转
var list = [];
list.push(urlObj.query); // 要写入 data.json 数据
// 将数据写入 data.json 文件
fs.writeFile(path.join(__dirname, "data", 'data.json'), JSON.stringify(list), function(err) {
if(err) {
throw err;
}
console.log("OK");
// 设置响应报文头,通过响应报文头告诉浏览器,执行一次页面跳转操作
// 重定向
res.statusCode = 302; // 状态码
res.statusMessage = "Found"; // 状态信息
res.setHeader("Location", "/"); // 设置响应报文头
res.end(); // 每次请求都要写--结束响应
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
多次对文件进行写操作
GET方式提交
先判断文件是否存在数据,如果存在则先读取文档数据(防止数据被覆盖),再将新增数据与原有数据一起写到文件中
// 读取 data.json 文件中的数据,并将读取到的数据转换为一个数组 // 此处,读取文件的时候可以直接写一个 utf8 编码,回调函数中的 data 就是一个字符串了 fs.readFile(path.join(__dirname, "data", "data.json", "utf-8", function(err, data) { // 因为第一次访问网站,data.json 文件本身就不存在,所以肯定是有错误的 // 但是这种错误,我们并不认为是网站出错了,所以不需要抛出异常 if(err && err.code !== 'ENOENT') { throw err; } // 如果读取到数据了,那么就把读取到的数据 data,转换为 list 数组 // 如果没有读取到数据,那么就把 '[]' 转换为数据 var list = JSON.parse(data || '[]'); // 向数组对象 list 中 push 一条新闻 list.push(urlObj.query); var list = []; list.push(urlObj.query); // 要写入 data.json 数据 // 将数据写入 data.json 文件 fs.writeFile(path.join(__dirname, "data", 'data.json'), JSON.stringify(list), function(err) { if(err) { throw err; } console.log("OK"); // 设置响应报文头,通过响应报文头告诉浏览器,执行一次页面跳转操作 // 重定向 res.statusCode = 302; // 状态码 res.statusMessage = "Found"; // 状态信息 res.setHeader("Location", "/"); // 设置响应报文头 res.end(); // 每次请求都要写--结束响应 }) }))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
POST方式提交
因为post提交数据的时候,数据量可能比较大,所以会分多次进行提交,每次提交一部分数据。
此时要想在服务器中获取用户提交的所有数据,就必须监听request事件的data事件。
req.on("data", function(chunk) {
})
- 1
- 2
chunk就是浏览器本次提交过来的一部分数据chunk的数据类型是Buffer(chunk就是一个Buffer对象)
当request对象的end事件被触发的时候,浏览器把所有数据都提交到服务器了。
req.on("end", function() {
// 在这个事件中只要把 array 中的所有数据汇总起来就好了
})
- 1
- 2
- 3
var querystring = require('querystring'); // 读取 data.json 文件中的数据 fs.readFile(path.join(__dirname, "data", "data.json", "utf-8", function(err, data) { if(err && err.code !== 'ENOENT') { throw err; } var list = JSON.parse(data || '[]'); var array = []; req.on("data", function(chunk) { array.push(chunk); }); // 监听 request 对象的 end 事件 // 当 end 事件被触发的时候,表示上述所有数据都已经提交完毕了 req.on("end", function() { // 在这个事件中只要把 array 中的所有数据汇总起来就好了 // 把 array 中的每个 buffer 对象,集合起来转换为一个 buffer 对象 var postBody = Buffer.concat(array); // 把获取到的 buffer 对象转换为一个字符串 postBody = postBody.toString('utf8'); // 把 post 请求的查询字符串,转换为一个 json 对象 postBody = querystring.parse(postBody); // 将用户提交的新闻 push 到 list 中 list.push(postBody); // 将新的 list 数组,再写入到 data.json 文件中 // 将数据写入 data.json 文件 fs.writeFile(path.join(__dirname, "data", 'data.json'), JSON.stringify(list), function(err) { if(err) { throw err; } console.log("OK"); // 设置响应报文头,通过响应报文头告诉浏览器,执行一次页面跳转操作 // 重定向 res.statusCode = 302; // 状态码 res.statusMessage = "Found"; // 状态信息 res.setHeader("Location", "/"); // 设置响应报文头 res.end(); // 每次请求都要写--结束响应 }) }) }))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
module模块和package包的区别
1、A module is any file or directory that can be loaded by Node.js’ require().
模块可以是任何一个文件或目录(目录下可以有很多个文件),只要能被node.js通过require()即可。
2、A package is a file or directory that is described by a package.json. This can happen in a bunch of different ways!
包是一个文件或目录(目录下可以有多个文件)必须有一个package.json文件来描述,就可以是一个包。
package.json文件
作用
package.json文件是一个包说明文件(项目描述文件),用来管理组织一个包(一个项目)package.json文件是一个json格式的文件- 位于当前项目的根目录下
文件中常见的项
name*:包的名字version*:包的版本description:包描述homepage:包的官网 urlauthor:包的作者contributors:包的其他贡献者姓名dependencies:依赖包列表。如果依赖包没有安装,npm 会自动将依赖包安装在 node_module 目录下main:程序的主入口文件。包的入口js文件,从main字段这里指定的那个js文件开始执行repository:包代码存放的地方的类型,可以是 git 或 svn,git 可在 Github 上keywords:关键字
package-lock.json文件
该文件旨在跟踪被安装的每个软件包的确切版本,以便产品可以以相同的方式被100%复制(即使软件包的维护者更新了软件包)。
这解决了 package.json 一直尚未解决的特殊问题。 在 package.json 中,可以使用 semver 表示法设置要升级到的版本(补丁版本或次版本),例如:
- 如果写入的是
〜0.13.0,则只更新补丁版本:即0.13.1可以,但0.14.0不可以。 - 如果写入的是
^0.13.0,则要更新补丁版本和次版本:即0.13.1、0.14.0、依此类推。 - 如果写入的是
0.13.0,则始终使用确切的版本。
可能是你,或者是其他人,会在某处尝试通过运行 npm install 初始化项目。
因此,原始的项目和新初始化的项目实际上是不同的。 即使补丁版本或次版本不应该引入重大的更改,但还是可能引入缺陷。
package-lock.json 会固化当前安装的每个软件包的版本,当运行 npm install时,npm 会使用这些确切的版本。
package-lock.json 文件需要被提交到 Git 仓库,以便被其他人获取(如果项目是公开的或有合作者,或者将 Git 作为部署源)。
当运行 npm update 时,package-lock.json 文件中的依赖的版本会被更新。
underscore
Underscore 一个 JavaScript 实用库,提供了一整套函数式编程的实用功能,但是没有扩展任何 JavaScript 内置对象。它弥补了部分 jQuery 没有实现的功能,同时又是 Backbone.js 必不可少的部分。
- 安装:
npm install underscore
_.zip(*arrays)和_.unzip(array)–数组(Arrays)
_.zip(*arrays):将每个arrays中相应位置的值合并在一起。 当您有通过匹配数组索引进行协调的独立数据源时,这非常有用。_.unzip(array):给定若干arrays,返回一串联的新数组,其第一元素个包含所有的输入数组的第一元素,其第二包含了所有的第二元素,依此类推。
const _ = require('underscore'); // 引用
const names = ['张三', '李四', '王五'];
const ages = [23,43,55];
const genders = ['女', '男', '男'];
const result = _.zip(names, ages, genders); // 压缩
console.log(result);
const result1 = _.unzip(result); // 解压缩
console.log(result1);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 结果:

template–工具函数(Utility)
_.template(templateString, [settings]):将 JavaScript 模板编译为可以用于页面呈现的函数, 对于通过 JSON 数据源生成复杂的 HTML 并呈现出来的操作非常有用。
- 模板函数可以使用
<%= … %>插入变量, 也可以用<% … %>执行任意的 JavaScript 代码。 - 如果您希望插入一个值, 并让其进行
HTML转义,请使用<%- … %>。 - 当你要给模板函数赋值的时候,可以传递一个含有与模板对应属性的
data对象 。 - 如果您要写一个一次性的, 您可以传对象
data作为第二个参数给模板template来直接呈现, 这样页面会立即呈现而不是返回一个模板函数. - 参数
settings是一个哈希表包含任何可以覆盖的设置_.templateSettings.
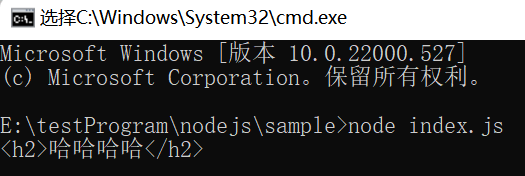
const _ = require("template");
// 声明了一段模板代码的 html 文档
let html = '<h2><%= name %></h2>'; // 有可能是完整的复杂的 html 文档
// template() 函数返回依然是一个函数
const fn = _.template(html);
// 调用 template() 返回的这个函数 fn
// fn 接受一个数据对象,并用该数据对象,将 html 中的模板内容替换,生成最终的 html 代码
html = fn({name: '哈哈哈哈'});
console.log(html);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行结果:
替换html中的模板
html文档

index.js文件


异步函数有数据返回,可以用回调函数:

node.js中的模块
分类
核心模块
核心模块(Core Module),也称内置模块、原生模块
fshttppathurl...
所有内置模块在安装node.js的时候就已经编译成二进制文件,可以直接加载运行(速度较快)
部分内置模块,在node.exe这个进程启动的时候就已经默认加载了,所以可以直接使用
文件模块
按文件后缀来分
如果加载时,没有指定后缀名,那么就按照如下顺序依次加载相应模块
.js.json.node(C/C++编写的模块)
自定义模块(第三方模块)
mimecheeriomomentmongo...
关于require()
require()引用情况
- 情况一:
require()的参数是一个路径(相对或者绝对路径)
require("./index2.js");
require('./index2');
/*
* 没有写后缀名的时候:
* 系统首先会找 index2.js 文件;
* 如果没有 index2.js 文件,
* 就会找 index2.json 文件;
* 如果没有 index2.json 文件,
* 系统会找 index2.node 文件;
* 都没有就会想 是不是文件夹(index2 文件夹) --> 第三方模块 --> package.json 文件 --> main(入口文件 app.js --> index.js/index.json/index.node) --> 加载失败
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 情况二:
require()的参数不是路径,直接就是一个模块名称
1.先在核心模块中查找,是否有和给定的名字一样的模块。如果有,则直接加载该核心模块
require('http')
- 1
- 如果核心模块中没有该模块,那么就会认为这个模块是一个第三方模块(自定义模块)
先会去当前js文件所在的目录下去找是否有一个node_modules文件夹
require("mime");
- 1
require加载模块注意点
require加载模块是同步的- 所有模块第一次加载完毕后都会有缓存,二次加载直接读取缓存,避免了二次开销
因为有缓存,所以模块中的代码只在第一次加载的时候执行一次 - 每次加载模块的时候都优先从缓存中加载,缓存中没有的情况下才会按照
node.js加载模块的规则去查找 - 核心模块在
node.js源码编译的时候,都已经编译为二进制执行文件,所以加载速度较快(核心模块加载的优先级仅次于缓存加载) - 核心模块都保存在
lib目录下 - 试图加载一个和
核心模块同名的自定义模块(第三方模块)是不会成功的
自定义模块要么名字不要与核心模块同名
要么使用路径的方式加载 核心模块只能通过模块名称来加载
错误示例:require('./http');这样是无法加载核心模块 http的require()加载模块使用./相对路径时,相对路径是相对当前模块,不受执行node命令的路径影响- 建议加载
文件模块的时候始终添加文件后缀名,不要省略
两个模块进行通信–module.exports
一个模块,默认被require()加载后,返回的是一个空对象{}
// a.js
var b = require("./b.js");
console.log(b);
- 1
- 2
- 3
// b.js
console.log('2aaaa')
- 1
- 2

如果要返回其他类型,需要引用module.exports
// b.js
module.exports.name = "张三";
module.exports.age = 23;
module.exports.show = function() {
console.log(this.name,"今年",this.age,"岁了");
}
this.show();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
// a.js
var b = require("./b.js");
console.log(b);
- 1
- 2
- 3

module.exports和exports
exports 变量在模块的文件级作用域内可用,并在评估模块之前被分配 module.exports 的值。
它允许一个快捷方式,以便 module.exports.f = ... 可以更简洁地写成 exports.f = ...。
但是,请注意,与任何变量一样,如果将新值分配给 exports,则它就不再绑定到 module.exports:
module.exports.hello = true; // 从模块的 require 中导出
exports = { hello: false }; // 未导出,仅在模块中可用
- 1
- 2
当 module.exports 属性被新对象完全替换时,通常也会重新分配 exports:
module.exports = exports = function Constructor() {
// ... 等等。
};
- 1
- 2
- 3
为了阐明该行为,想象一下 require() 的这个假设实现,它与 require() 的实际实现非常相似:
function require(/* ... */) {
const module = { exports: {} };
((module, exports) => {
// 模块代码在这里。 在本例中,定义一个函数。
function someFunc() {}
exports = someFunc;
// 此时,exports 不再是 module.exports 的快捷方式,
// 并且此模块仍然会导出空的默认对象。
module.exports = someFunc;
// 此时,该模块现在将导出 someFunc,
// 而不是默认对象。
})(module, module.exports);
return module.exports;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
通过b.js不同情况进行分析,a.js文件不变
// a.js
const b = require('./b.js');
console.log(b);
- 1
- 2
- 3
b.js原始文件:
// b.js
module.exports.name = "张三";
exports.age = 10;
exports.show = function() {
console.log(this.name + ":" + this.age);
}
- 1
- 2
- 3
- 4
- 5
- 6


- 案例一:新增
module.exports输出字符串
// b.js
module.exports.name = "张三";
exports.age = 10;
exports.show = function() {
console.log(this.name + ":" + this.age);
}
module.exports = "Hello world!";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
最终require()函数返回的是module.exports中的数据return module.exports;
–>输出内容被替换了:


- 案例二:
exports输出一个字符串
// b.js
module.exports.name = "张三";
exports.age = 10;
exports.show = function() {
console.log(this.name + ":" + this.age);
}
exports = "Hello world!";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果:

exports指向变了,module.exports指向没变。由于return module.exports,所以输出还是对象

Buffer(缓冲区)
JavaScript 只有字符串数据类型,没有二进制数据类型。
Node.js 定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区,用来处理像 TCP流或文件流这种必须使用到二进制数据。
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。
// 例子
const buf = Buffer.from("测试文字", 'ascii');
console.log(buf.toString('hex'));
console.log(buf.toString('base64'));
- 1
- 2
- 3
- 4
- 5
目前支持的字符编码
- ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ucs2 - utf16le 的别名。
- base64 - Base64 编码。
- latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
- binary - latin1 的别名。
- hex - 将每个字节编码为两个十六进制字符。
创建 Buffer 类
Buffer.alloc(size[, fill[, encoding]]):返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满0Buffer.allocUnsafe(size):返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据Buffer.allocUnsafeSlow(size):不从 buffer 缓冲区里分配,直接从操作系统分配,slow 指的是没有从缓冲池高效分配Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
写入缓冲区
buf.write(string[, offset[, length]][, encoding]);
返回:
实际写入的大小。如果 buffer 空间不足,则只会写入部分字符串。
参数:
string-写入缓冲区的字符串
offset-缓冲区开始写入的索引值,默认为0
length-写入的字节数,默认为buffer.length
encoding-使用的编码。默认为'utf8'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
根据 encoding 的字符编码写入 string 到 buf 中的 offset 位置。length 参数是写入的字节数。 如果 buf 没有足够的空间保存整个字符串,则只会写入 string 的一部分。 只部分解码的字符不会被写入。
const buf = Buffer.alloc(10);
len = buf.write("这是一条测试语句!", 'utf8');
console.log("写入的字节数:", buf, len);
- 1
- 2
- 3
- 4

从缓冲区读取数据
buf.toString([encoding[, start[, end]]])
参数:
encoding - 使用的编码。默认为 'utf8' 。
start - 指定开始读取的索引位置,默认为 0。
end - 结束位置,默认为缓冲区的末尾。
返回值:
解码缓冲区数据并使用指定的编码返回字符串
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取Get和Post请求
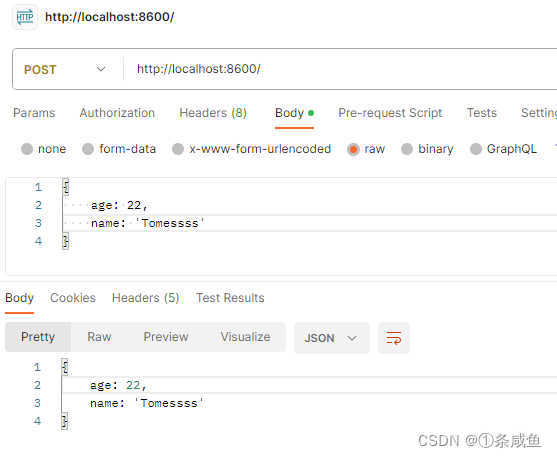
Post
req.on('data'):响应数据上传的事件,并对数据进行收集。req.on('end'):响应数据上传结束的事件,并判断是否存在上传数据。如果存在,则执行后续逻辑。
const http = require("http"); const server = http.createServer((req, res)=>{ let postData = ""; req.on("data", (chunk)=>{ postData += chunk.toString(); }) req.on('end', ()=>{ if(postData) { res.setHeader("content-type", "application/json"); res.end(postData) } }) }) server.listen(8600, ()=>{ console.log("8600 is running!") })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
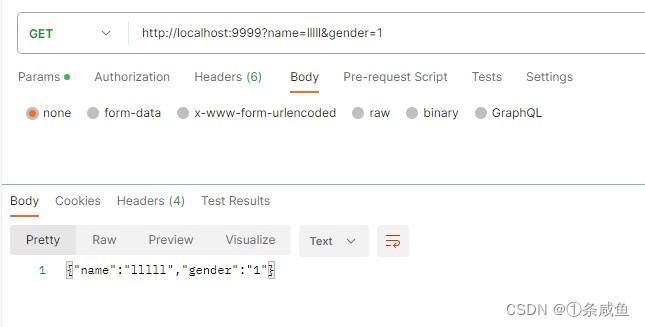
Get
node:querystring模块提供了用于解析和格式化网址查询字符串的实用工具。
const http = require("http");
const querystring = require("querystring");
const server = http.createServer((req, res)=>{
const param = req.url.split("?");
req.query = {};
if(param && param.length>0) {
if(param[1]) {
req.query = querystring.parse(param[1]);
}
}
res.end(JSON.stringify(req.query))
}).listen(9999, ()=>{
console.log("9999 is running!");
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15