
- 1学STM32(STM32F103RCT6)
- 2他人AS项目导入自己AS中的替换方法_as怎么导入别人的项目
- 3探秘AI Aimbot:游戏瞄准辅助神器的技术解析与应用
- 4掌握Python数据分析:从入门到精通
- 5聊聊我在腾讯和字节的测试岗工作感受,只想说:没有捷径,只有艰辛_字节跳动外包测试累吗
- 6第7天 | 28天学会PyQt5,控件事件_pyqt5 控件事件
- 7基于Javaweb福建厦门景区门票售票网站系统设计与实现
- 8MQ - RabbitMQ - 消息的可靠性 --学习笔记
- 9RK3568 OpenHarmony3.2 NFC 驱动适配(PN7150)II_openharmony nfc适配
- 10如何写出让面试官眼前一亮的Java开发简历(附模板),2024年最新2024年人行面试官是谁啊_java开发简历怎么写
CUDA架构介绍与设计模式解析
赞
踩
CUDA架构介绍与设计模式解析
1 CUDA 介绍
CUDA发展历程
CUDA 是 NVIDIA 于 2006 年推出的通用并行计算架构,经过多年发展,已成为 GPU 计算的重要标准。
CUDA主要特性
CUDA 提供强大的并行计算能力,具备以下特性:
- 线程层次结构
- 扩展了 C/C++ 语言,引入了 GPU 扩展如 kernel 函数
- 显式的内存层次结构,允许根据计算需求访问内存数据
- 跨平台支持
CUDA系统架构
CUDA 系统架构由以下三部分构成,为开发者提供丰富的资源和接口:
- 开发库
- 驱动
- 运行期环境
CUDA应用场景
CUDA 最初用于图形渲染,现已广泛应用于:
- 高性能计算
- 游戏开发
- 深度学习等领域
编程语言支持
CUDA 支持多种编程语言,包括:
- C
- C++
- Fortran
- Java
- Python等
但本次源码阅读和分析以 C/C++ 为主。
CUDA计算过程
- 分配 host 内存并进行数据初始化。
- 分配 device 内存,并将数据从 host 拷贝到 device 上。
- 调用 CUDA 核函数在 device 上完成指定的运算。
- 将 device 上的运算结果拷贝到 host 上。
- 释放 device 和 host 上分配的内存。
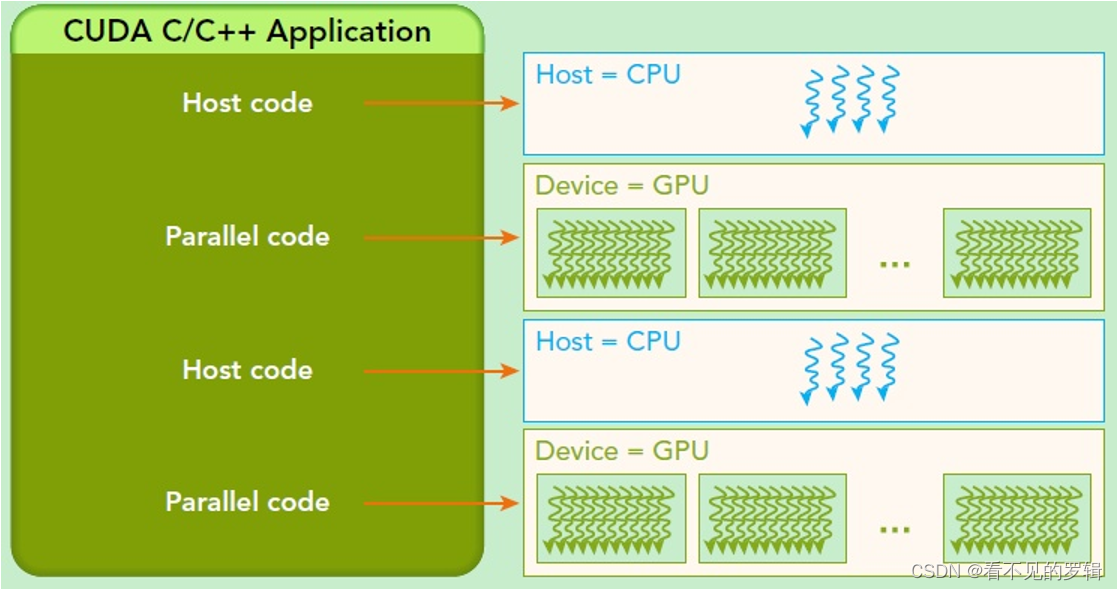
线程层次
- Grid:最高级的并行计算单位,由多个线程块(blocks)组成,可同时在 GPU 上执行。
- Block:线程块是网格的组成部分,包含多个线程,可协作和共享资源。
- Thread:最基本的并行执行单元,存在于线程块内部,每个线程可以独立执行计算任务,根据自身的线程索引执行。
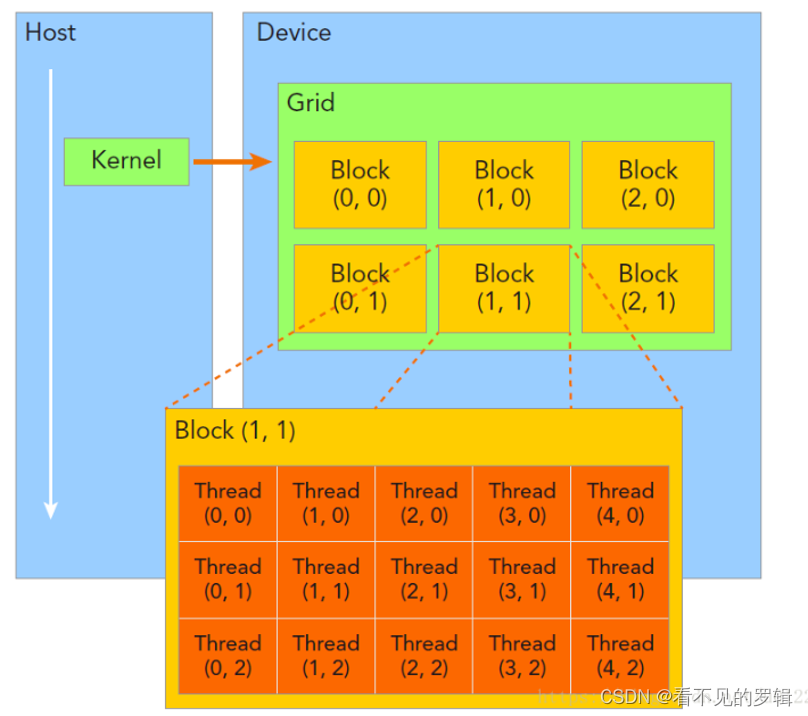
优势:
- 有效管理并行计算资源。
- 优化数据访问和内存使用。
- 提高任务并行度和负载均衡。
- 适应不同的并行计算需求。
存储层次
- 全局内存(Global Memory):GPU 中所有线程都可访问的主要存储区域,用于存储大量数据和程序状态,是主机与设备之间数据传输的主要桥梁。
- 常量内存(Constant Memory):用于存储只读数据,如常数和预计算的表格,具有较高的缓存性能。
- 纹理内存(Texture Memory):存储图像和多维数据,提供高效、灵活的访问方式。
- 共享内存(Shared Memory):位于线程块内部的低延迟、高带宽的存储区域,用于线程块内部的数据共享和通信。

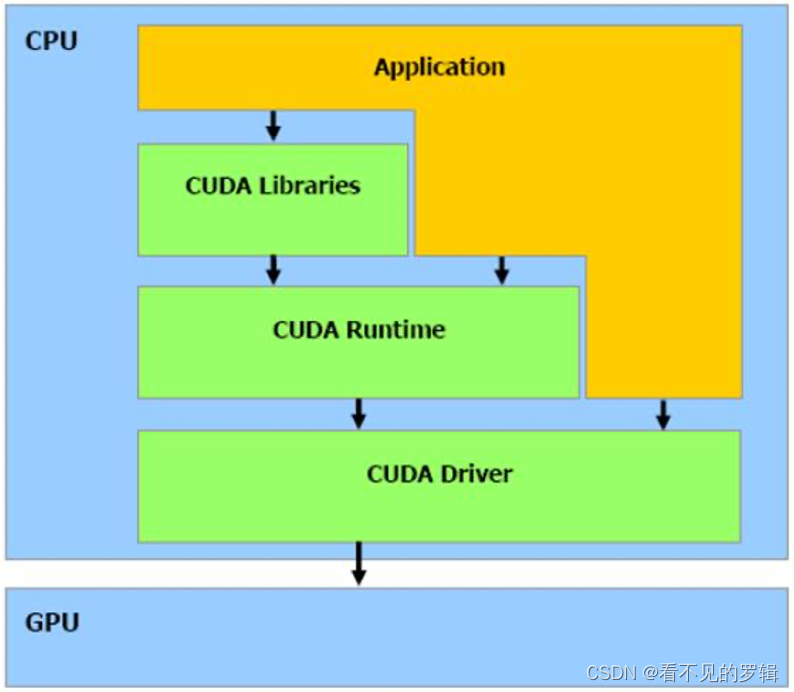
2 CUDA 系统架构
分层架构
从体系结构的组成来说,CUDA 包含了三个部分:
- 开发库 (Libraries):它是基于 CUDA 技术所提供的应用开发库。CUDA 包含两个重要的标准数学运算库——CUFFT(离散快速傅立叶变换)和 CUBLAS(基本线性代数子程序库)。这两个数学运算库解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。
- 运行期环境 (Runtime):提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。例如:
- 运行时 API:提供了一系列函数,用于执行设备内存分配、内核启动、事件管理、流控制等操作。
- 核函数:这是在 GPU 上并行执行的函数,由开发者编写,用于执行具体的并行计算任务。
- 驱动 (Driver):驱动程序层位于硬件层之上,是 CUDA 架构中的中间件,负责硬件抽象、资源管理、错误处理、CPU 和 GPU 通信。驱动程序层通过 CUDA 运行时 API 与主机代码交互。
并行计算模式
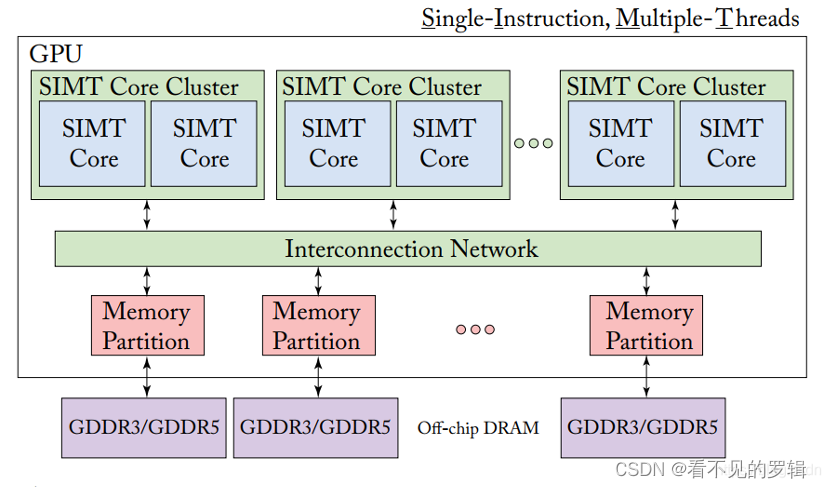
-
SIMT (Single Instruction Multiple Threads):单指令多线程是 CUDA 架构中的重要执行模型,它允许一组线程(称为线程束或 warp)同时执行相同的指令,但处理不同的数据。
- 每个 warp 包含一定数量的 core 用于执行,warp 是硬件调度的并行的最小单位。
- 与 CPU 不同的是,GPU 的执行调度单位为 warp,而 CPU 调度可以精细化为单个线程。因为 CPU 同时执行的线程数目比较少,而 GPU 要同时管理成千上万个线程,因此 GPU 一次性调度的是多个线程。
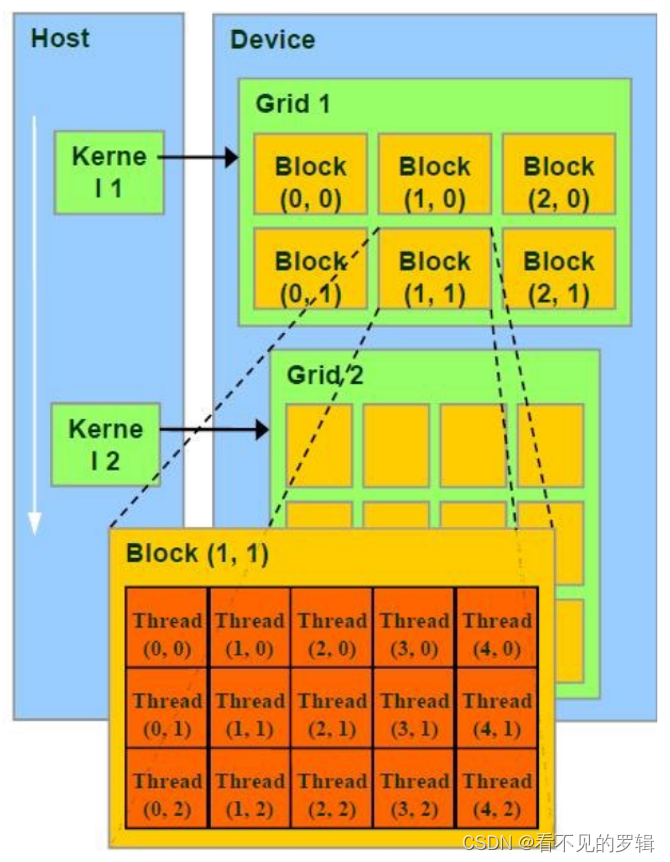
-
Grids, Blocks, Threads:具体到编程层面,程序员可以通过 Grids、Blocks 和 Threads 的编程模型来组织执行的线程:
- Threads (线程):是 CUDA 中最小的执行单位。每个线程执行核函数中的指令,并且可以独立处理数据。
- Blocks (块):一个 Block 是一组线程的集合,这些线程可以共享一个内存空间。Block 内的线程通过 threadIdx 进行索引。
- Grids (网格):Grid 是多个 Block 的集合,构成了核函数调用的全部执行范围。Grid 内的 Block 通过 blockIdx 进行索引。
- 当启动一个核函数时,CUDA 运行时环境会创建一个 Grid,该 Grid 由多个 Blocks 组成,每个 Block 又包含多个 Threads。
示例代码:
__global__ void vectorAdd(int *A, int *B, int *C, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { C[idx] = A[idx] + B[idx]; } } int main() { int N = 1000; int *A, *B, *C; int block_size = 256; int grid_size = (N + block_size - 1) / block_size; // 分配和初始化设备内存 cudaMalloc(&A, N * sizeof(int)); cudaMalloc(&B, N * sizeof(int)); cudaMalloc(&C, N * sizeof(int)); // 将数据从主机复制到设备 cudaMemcpy(A, host_A, N * sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(B, host_B, N * sizeof(int), cudaMemcpyHostToDevice); // 启动核函数 vectorAdd<<<grid_size, block_size>>>(A, B, C, N); // 等待核函数执行完成 cudaDeviceSynchronize(); // 将结果从设备复制回主机 cudaMemcpy(host_C, C, N * sizeof(int), cudaMemcpyDeviceToHost); // 释放设备内存 cudaFree(A); cudaFree(B); cudaFree(C); return 0;}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
源码分析:
- 核函数 vectorAdd() 定义了向量加法的操作;
int idx = blockIdx.x * blockDim.x + threadIdx.x;:计算出了当前线程的全局索引。blockIdx.x表示当前线程所在的块的索引,blockDim.x表示当前块中线程的数量,threadIdx.x表示当前线程在块内的索引。- 在 main 函数中,定义了 Blocks 的数量(grid_size)和每个 Block 的线程数量(block_size),并启动核函数
vectorAdd<<<grid_size, block_size>>>。 - 核函数中的每个线程都将执行相同的加法操作,但操作不同的数据元素,也就是向量中不同维度的数据。
生产-消费者模式
CUDA 中的生产者-消费者模式用于解决主机(CPU)和设备(GPU)之间的数据传输和计算任务之间的协作。主机(CPU)充当生产者,负责生成指令和数据并将其传输到设备上,而设备(GPU)充当消费者,负责获取数据并执行计算任务。
生产者-消费者模式的主要特点包括:
- 数据传输:生产者负责生成数据,并将数据传输到设备的内存中。这可以通过 CUDA 的内存复制函数(如
cudaMemcpy)来完成。 - 计算任务:消费者负责从设备的内存中获取数据,并执行相应的计算任务,通常是通过启动核函数来实现的。
- 数据同步:CUDA 使用流(Stream)来管理并行执行的操作序列,进行数据同步操作,以确保数据传输和计算任务的正确执行顺序。
示例代码:
#include <iostream> __global__ void kernel(int *data, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { data[idx] *= 2; } } int main() { const int N = 1000; int *hostData, *deviceData; // 分配主机内存并初始化数据 hostData = new int[N]; for (int i = 0; i < N; ++i) { hostData[i] = i; } // 分配设备内存 cudaMalloc(&deviceData, N * sizeof(int)); // 将数据从主机复制到设备 cudaMemcpy(deviceData, hostData, N * sizeof(int), cudaMemcpyHostToDevice); // 启动核函数,在设备上执行计算任务 const int blockSize = 256; const int gridSize = (N + blockSize - 1) / blockSize; kernel<<<gridSize, blockSize>>>(deviceData, N); // 将结果从设备复制回主机 cudaMemcpy(hostData, deviceData, N * sizeof(int), cudaMemcpyDeviceToHost); // 打印结果 for (int i = 0; i < N; ++i) { std::cout << hostData[i] << " "; } std::cout << std::endl; // 释放内存 delete[] hostData; cudaFree(deviceData); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
源码分析:
- 主机(生产者)生成了一个包含 1000 个整数的数据,并将数据传输到设备上。
- 设备(消费者)执行了核函数,进行具体的处理。
- 最后,设备将处理后的数据传输回主机,主机打印出结果。
- 通过这种方式,实现了主机和设备之间的生产者-消费者模式,充分利用了 GPU 的并行计算能力。
工作池模式
CUDA 中的工作池模式用于管理和调度大量的任务,以实现高效的并行计算。在工作池模式中,任务被组织成一个池子(工作池),并由多个工作线程并行执行。这种模式使得可以在 GPU 上同时处理多个任务,从而充分利用 GPU 的并行计算资源。
工作池模式的关键组件:
- 任务队列(Task Queue):用于存储待执行的任务。任务可以是任何需要在 GPU 上执行的操作,例如核函数调用、数据传输等。
- 工作线程(Worker Threads):负责从任务队列中获取任务,并执行这些任务。通常,工作线程会持续地从任务队列中获取任务,并在 GPU 上执行这些任务,直到任务队列为空或者达到某个终止条件。
- 任务调度器(Task Scheduler):负责调度工作线程的执行。任务调度器通常会根据任务队列的状态和工作线程的负载情况,动态地分配任务给工作线程,以实现任务的均衡分配和高效执行。
示例代码:
// 任务类型 typedef void (*Task)(int *, int); // 任务队列 std::queue<Task> taskQueue; std::mutex queueMutex; std::condition_variable queueCondition; // 工作线程函数 void workerThread(int *array, int N) { while (true) { Task task; { std::unique_lock<std::mutex> lock(queueMutex); // 等待任务队列非空 queueCondition.wait(lock, [](){ return !taskQueue.empty(); }); // 从任务队列中获取任务 task = taskQueue.front(); taskQueue.pop(); } // 执行任务 task(array, N); } } // 核函数,将数组中的每个元素乘以2 __global__ void kernel(int *array, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { array[idx] *= 2; } } // 添加任务到任务队列 void addTask(int *array, int N) { taskQueue.push(kernel); queueCondition.notify_one(); // 唤醒一个工作线程 } int main() { const int N = 1000; int *d_array; cudaMalloc(&d_array, N * sizeof(int)); // 定义并行执行的任务数量 const int numTasks = 10; // 创建并启动工作线程 std::thread threads[numTasks]; for (int i = 0; i < numTasks; ++i) { threads[i] = std::thread(workerThread, d_array, N); } // 添加多个任务到任务队列 for (int i = 0; i < numTasks; ++i) { addTask(d_array, N); } // 等待所有工作线程执行完成 for (int i = 0; i < numTasks; ++i) { threads[i].join(); } // 处理执行结果... cudaFree(d_array); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
源码分析:
- 在 main 中创建一组任务和工作线程。
- 每个工作线程不断地从任务队列中获取任务,并在 GPU 上执行这些任务,直到任务队列为空。
异步编程模式
CUDA 中的异步编程模式是指,在主机和设备之间并行执行多个任务,从而提高了整体的计算和数据传输效率。
CUDA 中异步编程模式的特点:
- 并行执行:允许主机和设备之间同时执行多个任务,从而避免了在等待一个任务完成时的空闲时间,提高了整体的计算和数据传输效率。
- 任务调度:CUDA 运行时会自动管理和调度异步任务的执行顺序,以最大程度地利用 GPU 的并行计算资源,减少任务之间的等待时间。
- 流控制:开发者可以通过 CUDA 中的流(Stream)对异步任务进行组织和管理。通过流控制,开发者可以控制任务的执行顺序,以及任务之间的依赖关系,从而实现更复杂的并行计算和数据传输操作。
示例代码:
#include <iostream> __global__ void kernel(int *array, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { array[idx] *= 2; } } int main() { const int N = 1000; int *d_array; cudaMalloc(&d_array, N * sizeof(int)); // 创建一个流 cudaStream_t stream; cudaStreamCreate(&stream); // 异步启动核函数 kernel<<<(N + 255) / 256, 256, 0, stream>>>(d_array, N); // 主机代码继续执行其他任务... // 等待流中的核函数执行完成 cudaStreamSynchronize(stream); // 处理核函数执行结果... // 释放流 cudaStreamDestroy(stream); cudaFree(d_array); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
源码分析:
- 主机创建一个流,并把核函数绑定到这个流实现异步启动,这样主机可以继续执行其他任务。
- 然后,主机通过
cudaStreamSynchronize函数等待流中的核函数执行完成,以确保可以安全地处理核函数的执行结果。 - 通过异步编程模式,主机和设备之间实现了并行执行,提高了整体的计算和数据传输效率。
3 CUDA 中的设计模式
工厂模式
工厂模式(Factory Pattern)是一种常用的软件设计模式,属于创建型模式。其核心思想是通过工厂类中的一个共用方法来处理对象的创建,将对象的创建和对象的使用分离开来,以便于达到扩展性高、耦合度低的目的。
工厂模式的基本组成:
- 产品 (Product):定义了产品的接口。
- 具体产品 (Concrete Product):实现了产品接口的具体类。
- 工厂 (Factory):提供了一个创建产品的方法,可以返回不同类型的产品对象。
内存分配函数 cudaMalloc
示例代码:
#include <stdio.h>
#include <cuda_runtime.h>
int main() {
int size = 1024 * sizeof(int);
int *d_array;
// 使用工厂模式的 cudaMalloc 在设备上分配内存
cudaMalloc((void**)&d_array, size);
// 内存分配成功后,可以在设备上使用 d_array
// ...
cudaFree(d_array); // 释放设备内存
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
源码分析:
cudaMalloc函数是 CUDA Runtime API 提供的内存分配函数,其定义如下:
cudaError_t cudaMalloc(void** devPtr, size_t size);
- 1
devPtr是一个指向设备内存指针的指针,在函数调用后将指向分配的设备内存。size是要分配的内存大小(字节数)。- 函数返回
cudaError_t类型的错误码,表示函数执行的状态。
策略模式
策略模式(Strategy Pattern)是一种定义一系列算法的软件设计模式,它属于行为型模式。策略模式允许客户端在运行时根据需要选择不同的算法,而不需要修改客户端代码。其目的是将算法的使用从算法的实现中分离出来,让两者之间不相互依赖,从而提高程序的灵活性和可扩展性。
策略模式的基本组成:
- 策略 (Strategy):定义所有支持的算法的公共接口。
- 具体策略 (Concrete Strategy):实现了策略接口的具体算法类。
- 环境 (Context):持有一个策略类的引用,用该策略的接口来与之交互。
示例代码:
#include <iostream> #include <cuda_runtime.h> class ParallelizationStrategy { public: virtual void execute(int* data, int size) const = 0; virtual ~ParallelizationStrategy() {} }; class ThreadPerElementStrategy : public ParallelizationStrategy {//基于线程的并行化 public: virtual void execute(int* data, int size) const override { // Execute algorithm with one thread per element int idx = threadIdx.x + blockIdx.x * blockDim.x; if (idx < size) { // Do computation } } }; class ThreadBlockStrategy : public ParallelizationStrategy {//基于线程块的并行化 public: virtual void execute(int* data, int size) const override { // Execute algorithm with one thread per block int idx = blockIdx.x; if (idx < size) { // Do computation } } }; class Kernel { private: ParallelizationStrategy* strategy; public: Kernel(ParallelizationStrategy* strat) : strategy(strat) {} void run(int* data, int size) const { strategy->execute(data, size); } }; int main() { const int dataSize = 1000; int* data; cudaMalloc(&data, dataSize * sizeof(int)); ThreadPerElementStrategy perElementStrategy; Kernel kernel1(&perElementStrategy); kernel1.run(data, dataSize); ThreadBlockStrategy blockStrategy; Kernel kernel2(&blockStrategy); kernel2.run(data, dataSize); cudaFree(data); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
源码分析:
在主函数中创建了两个不同的Kernel对象,分别使用不同的策略来执行内核函数。这样就实现了在运行时选择不同的算法行为,而不需要改变客户端代码的逻辑。
观察者模式
观察者模式(Observer Pattern)是一种行为型设计模式,它定义了对象之间的一对多依赖关系。当一个对象(被观察者)的状态发生变化时,所有依赖它的对象(观察者)都会收到通知并自动更新。这种模式常用于事件驱动的系统,以实现松耦合。
观察者模式的基本组成:
- 主题 (Subject):维护了一个观察者列表,并能够触发观察者列表中的所有观察者。
- 观察者 (Observer):定义了一个更新接口,用以更新状态。
- 具体主题 (Concrete Subject):实现了主题,具体通知观察者。
- 具体观察者 (Concrete Observer):实现了观察者的更新接口,以反映主题的状态。
CUDA 事件可以用来监视核函数执行的状态,并在完成时通知主机。
示例代码:
cudaEvent_t event;
cudaEventCreate(&event); // 创建事件
myKernel<<<numBlocks, threadsPerBlock>>>();//核函数执行
cudaEventRecord(event); // 记录事件,核函数执行完成后触发事件
cudaEventSynchronize(event); // 等待事件完成
// 处理事件完成后的逻辑
…
- 1
- 2
- 3
- 4
- 5
- 6
- 7
适配者模式
迭代器模式(Iterator Pattern)是软件设计中的一种常用行为型模式,它允许客户端在不暴露其底层数据结构的情况下,顺序访问聚合对象中的元素。迭代器模式定义了一个数据访问接口,用于在元素之间进行导航,而不依赖于聚合对象的具体类。
迭代器模式的基本组成:
- 迭代器 (Iterator):定义了访问和遍历元素的接口。
- 具体迭代器 (Concrete Iterator):实现了迭代器接口,跟踪当前访问的位置。
- 聚合 (Aggregate):定义了一个创建迭代器的方法。
- 具体聚合 (Concrete Aggregate):实现了创建具体迭代器的方法。
有两个版本的核函数,它们执行相同的操作,但是实现方式不同。在主机代码中使用一个统一的接口来调用这些核函数,而不需要关心它们的具体实现细节。
示例代码:
// 核函数版本1 __global__ void kernelVersion1(int *data, int value) { int tid = threadIdx.x + blockIdx.x * blockDim.x; if (tid < size) { data[tid] += value; } } // 核函数版本2 __global__ void kernelVersion2(int *data, int value) { int tid = threadIdx.x + blockIdx.x * blockDim.x; atomicAdd(&data[tid], value); // 使用原子操作来更新数据 } // 核函数版本1的适配器 class KernelLauncherV1 : public IKernelLauncher { public: void launch(int *data, int value, int size) override { kernelVersion1<<<...>>>(data, value); } }; // 核函数版本2的适配器 class KernelLauncherV2 : public IKernelLauncher { public: void launch(int *data, int value, int size) override { kernelVersion2<<<...>>>(data, value); } }; int main() { int *data; // 假设已经分配和初始化了设备内存 int value = 10; int size = 1024; // 根据需要选择使用哪个版本的核函数 std::unique_ptr<IKernelLauncher> launcher; if (useVersion1) { launcher = std::make_unique<KernelLauncherV1>(); } else { launcher = std::make_unique<KernelLauncherV2>(); } // 使用适配器接口调用核函数 launcher->launch(data, value, size); cudaDeviceSynchronize(); // 等待GPU完成工作 // ... 后续处理 ... return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
源码分析:
在上述CUDA适配器模式的示例中,其创建了一个抽象的IKernelLauncher接口,该接口定义了启动核函数的通用方法launch。这个接口允许我们通过统一的调用方式来执行不同的核函数实现,而不必在主机代码中硬编码每个核函数的具体调用。
迭代器模式
迭代器模式(Iterator Pattern)是软件设计中的一种常用行为型模式,它允许客户端在不暴露其底层数据结构的情况下,顺序访问聚合对象中的元素。迭代器模式定义了一个数据访问接口,用于在元素之间进行导航,而不依赖于聚合对象的具体类。
迭代器模式的基本组成:
- 迭代器 (Iterator):定义了访问和遍历元素的接口,通常包含
next(),prev(),first(),last(),isDone()和currentItem()等方法。 - 具体迭代器 (Concrete Iterator):实现了迭代器接口,跟踪当前访问的位置,并在内部维护一个指向聚合对象中某个位置的引用。
- 聚合 (Aggregate):定义了一个创建迭代器的方法,通常是一个
createIterator()方法,用于返回一个迭代器的实例。 - 具体聚合 (Concrete Aggregate):实现了创建具体迭代器的方法,返回一个具体迭代器的实例,该实例能够遍历具体聚合中的所有元素。
Ps:迭代器模式在CUDA中不是直接应用的,因为CUDA的编程模型主要关注于如何高效地映射并行计算到GPU上。迭代器模式在CUDA中的一种可能应用场景:遍历设备内存中的数组。


