
热门标签
热门文章
- 1iperf2工具的使用_iperf2 jitter
- 2frp、FTP服务
- 3zynq PL部分无需打包,与PS AXI通信(linux系统)_ps axi转网络通信
- 4PowerInfer-2:智能手机上的大语言模型快速推理_powerinfer-2: fast large language model inference
- 5【最新案例】网络智能类SCI&EI,极速审稿,录用到检索仅2个月零9天_journal of network intelligence
- 6两个浏览器窗口间通信_gethub跨浏览器通讯项目
- 7AIGC技术赋能教育数字化转型的机遇与挑战
- 8AI大模型盘点:国内10强及体验网址_国内除了文心一言还有什么
- 9Git | git remote update 和 git fetch 的区别
- 10Qt中操作SQLite数据库_qt sqlite
当前位置: article > 正文
【Kaggle】Telco Customer Churn 电信用户流失预测案例_ibm telco customer churn dataset
作者:爱喝兽奶帝天荒 | 2024-07-29 12:26:16
赞
踩
ibm telco customer churn dataset

⭐️前言:案例学习说明与案例建模流程
我们将围绕Kaggle中的电信用户流失数据集(Telco Customer Churn)进行用户流失预测。在此过程中,将综合应用此前所介绍的各种方法与技巧,并在实践中提炼总结更多实用技巧。

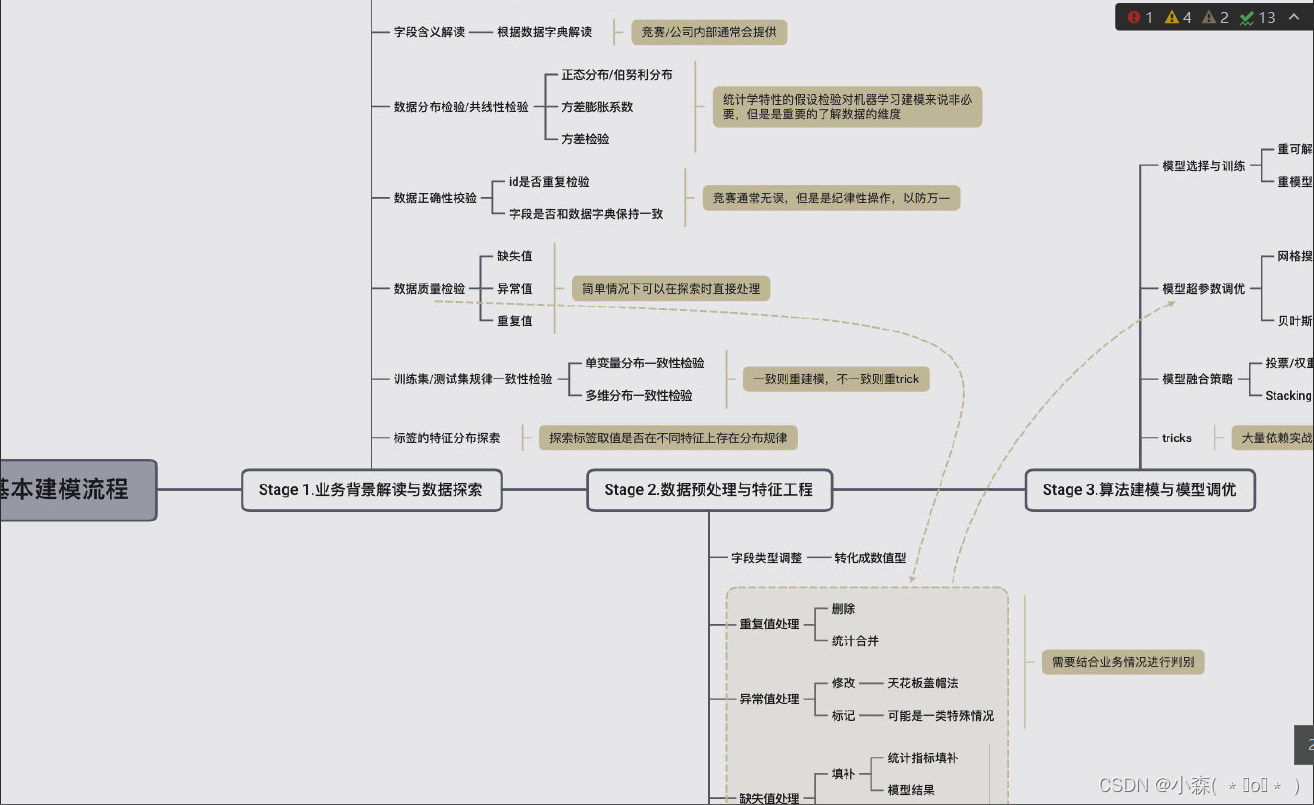
⭐️对于实战案例的讲解,我们将分为三个阶段进行,当然这也是我们在参与算法竞赛、或者在实际算法建模时的一般流程:
- Stage 1.业务背景解读与数据探索
在拿到数据(接受任务)的第一时间,需要对数据(也就是对应业务)的基本背景进行解读。由于任何数据都诞生于某业务场景下,同时也是根据某些规则来进行的采集或者计算得出,因此如果可以,我们应当尽量去了解数据诞生的基本环境和对应的业务逻辑,尽可能准确的解读每个字段的含义,而只有在无法获取真实业务背景时,才会考虑退而求其次通过数据情况去倒推业务情况。
当然,在进行了数据业务背景解读后,接下来就需要对拿到的数据进行基本的数据探索。一般来说,数据探索包括数据分布检验、数据正确性校验、数据质量检验、训练集/测试集规律一致性检验等。当然,这里可能涉及到的操作较多,也并非所有的操作都必须在一次建模过程中全部完成。但作为教学案例,我们将在后续的内容中详细介绍每个环节的相关操作及目的。 - Stage 2.数据预处理与特征工程
在了解了建模业务背景和基本数据情况后,接下来我们就需要进行实际建模前的“数据准备”工作了,也就是数据预处理(数据清洗)与特征工程。其中,数据清洗主要聚焦于数据集数据质量提升,包括缺失值、异常值、重复值处理,以及数据字段类型调整等;而特征工程部分则更倾向于调整特征基本结构,来使数据集本身规律更容易被模型识别,如特征衍生、特殊类型字段处理(包括时序字段、文本字段等)等。
当然,很多时候我们并不刻意区分数据清洗与特征工程之间的区别,很多时候数据清洗的工作也可以看成是特征工程的一部分。同时,也有很多时候我们也不会一定要求在不同阶段执行不同操作,例如如果在数据探索时发现缺失值比例较小,则可以直接对其进行均值/众数填补,而不用等到特征工程阶段统一处理,再例如很多特征工程的方法需要结合实际建模效果来判别,所以有的时候特征衍生也会和建模过程交替进行。 - Stage 3.算法建模与模型调优
在经过一系列准备工作后,就将进入到最终建模环节了,建模过程既包括算法训练也包括参数调优。当然,很多时候建模工作不会一蹴而就,需要反复尝试各种模型、各种调参方法、以及模型融合方法。此外,很多时候我们也需要根据最终模型输出结果来进行数据预处理和特征工程相关方法调整。
上述流程可以用如下流程图进行表示:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/898744?site
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

