
LLM大模型如何微调?面试经验回答汇总(2024.7月最新)_大模型微调面试
赞
踩
目录
1. 如果想要在某个模型基础上做全参数微调,究竟需要多 少显存?
4. 领域模型Continue PreTrain 数据选取?
5. 领域数据训练后,通用能力往往会有所下降,如何缓解 模型遗忘通用能力?
6. 领域模型Continue PreTrain ,如何 让模型在预训练过 程中就学习到更多的知识?
7. 进行SFT操作的时候,基座模型选用Chat还是Base?
15. 想让模型学习某个领域或行业的知识,是应该预训练还 是应该微调?
25. 微调大模型时,如果 batch size 设置太小 会出现什么 问题?
26. 微调大模型时,如果 batch size 设置太大 会出现什么 问题?
27. 微调大模型时, batch size 如何设置问题?
1. 如果想要在某个模型基础上做全参数微调,究竟需要多 少显存?
一般 n B的模型,最低需要 16-20 n G的显存。(cpu offload基本不开的情况下)
vicuna-7B为例,官方样例配置为 4*A100 40G,测试了一下确实能占满显存。(global batch size 128,max length 2048)当然训练时用了FSDP、梯度累积、梯度检查点等方式降显存。
2. 为什么SFT之后感觉LLM傻了?
原版答案: SFT的重点在于激发大模型的能力,SFT的数据量一般也就是万恶之源alpaca数据集的52k量级,相比于 预训练的数据还是太少了。 如果抱着灌注领域知识而不是激发能力的想法,去做SFT的话,可能确实容易把LLM弄傻。
新版答案: 指令微调是为了增强(或解锁)大语言模型的能力。 其真正作用: 指令微调后,大语言模型展现出泛化到未见过任务的卓越能力,即使在多语言场景下也能有不错表现 。
3. SFT 指令微调数据 如何构建?
1. 代表性。应该选择多个有代表性的任务;
2. 数据量。每个任务实例数量不应太多(比如:数百个)否则可能会潜在地导致过拟合问题并影响模 型性能;
3. 不同任务数据量占比。应该平衡不同任务的比例,并且限制整个数据集的容量(通常几千或几 万),防止较大的数据集压倒整个分布。
4. 领域模型Continue PreTrain 数据选取?
技术标准文档或领域相关数据是领域模型Continue PreTrain的关键。因为领域相关的网站和资讯重要性 或者知识密度不如书籍和技术标准。
5. 领域数据训练后,通用能力往往会有所下降,如何缓解 模型遗忘通用能力?
动机:仅仅使用领域数据集进行模型训练,模型很容易出现灾难性遗忘现象. 解决方法:通常在领域训练的过程中加入通用数据集
那么这个比例多少比较合适呢?
目前还没有一个准确的答案。主要与领域数据量有关系,当数据量没有那么多时,一般领域数据与通用 数据的比例在1:5到1:10之间是比较合适的。
6. 领域模型Continue PreTrain ,如何 让模型在预训练过 程中就学习到更多的知识?
领域模型Continue PreTrain时可以同步加入SFT数据,即MIP,Multi-Task Instruction PreTraining。 预训练过程中,可以加下游SFT的数据,可以让模型在预训练过程中就学习到更多的知识。
7. 进行SFT操作的时候,基座模型选用Chat还是Base?
仅用SFT做领域模型时,资源有限就用在Chat模型基础上训练,资源充足就在Base模型上训练。(资源= 数据+显卡) 资源充足时可以更好地拟合自己的数据,如果你只拥有小于10k数据,建议你选用Chat模型作为基座进 行微调;如果你拥有100k的数据,建议你在Base模型上进行微调。
8. 领域模型微调 指令&数据输入格式 要求?
在Chat模型上进行SFT时,请一定遵循Chat模型原有的系统指令&数据输入格式。 建议不采用全量参数训练,否则模型原始能力会遗忘较多。
9. 领域模型微调 领域评测集 构建?
领域评测集时必要内容,建议有两份,一份选择题形式自动评测、一份开放形式人工评测。 选择题形式可以自动评测,方便模型进行初筛;开放形式人工评测比较浪费时间,可以用作精筛,并且 任务形式更贴近真实场景。
10. 领域模型词表扩增是不是有必要的?
领域词表扩增真实解决的问题是解码效率的问题,给模型效果带来的提升可能不会有很大。
11. 如何训练自己的大模型?
如果我现在做一个sota的中文GPT大模型,会分2步走:1. 基于中文文本数据在LLaMA-65B上二次预训 练; 2. 加CoT和instruction数据, 用FT + LoRA SFT。
提炼下方法,一般分为两个阶段训练:
第一阶段:扩充领域词表,比如金融领域词表,在海量领域文档数据上二次预训练LLaMA模型;
第二阶段:构造指令微调数据集,在第一阶段的预训练模型基础上做指令精调。还可以把指令微调 数据集拼起来成文档格式放第一阶段里面增量预训练,让模型先理解下游任务信息。
当然,有低成本方案,因为我们有LoRA利器,第一阶段和第二阶段都可以用LoRA训练,如果不用 LoRA,就全参微调,大概7B模型需要8卡A100,用了LoRA后,只需要单卡3090就可以了。
12. 训练中文大模型有啥经验?
链家技术报告《Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation》中,介绍了开源模型的训练和评估方法:
结论:
扩充中文词表后,可以增量模型对中文的理解能力,效果更好
数据质量越高越好,而且数据集质量提升可以改善模型效果
数据语言分布,加了中文的效果比不加的好
数据规模越大且质量越高,效果越好,大量高质量的微调数据集对模型效果提升最明显。解释下: 数据量在训练数据量方面,数据量的增加已被证明可以显著提高性能。值得注意的是,如此巨大的 改进可能部分来自belle-3.5和我们的评估数据之间的相似分布。评估数据的类别、主题和复杂性将 对评估结果产生很大影响
扩充词表后的LLaMA-7B-EXT的评估表现达到了0.762/0.824=92%的水平
中文大模型的训练是可行的,虽然与ChatGPT还有差距。这里需要指出后续RLHF也 很重要,我罗列在这里,抛砖引玉。
13. 指令微调的好处?
有以下好处:
1. 对齐人类意图,能够理解自然语言对话(更有人情味)
2. 经过微调(fine-tuned),定制版的GPT-3在不同应用中的提升非常明显。OpenAI表示,它可以让 不同应用的准确度能直接从83%提升到95%、错误率可降低50%。解小学数学题目的正确率也能提 高2-4倍。(更准)
踩在巨人的肩膀上、直接在1750亿参数的大模型上微调,不少研发人员都可以不用再重头训练自己的AI 模型了。(更高效)
14. 预训练和微调哪个阶段注入知识的?
预训练阶段注入知识的,微调是在特定任务训练,以使预训练模型的通用知识跟特定任务的要求结合, 使模型在特定任务上表现更好。
15. 想让模型学习某个领域或行业的知识,是应该预训练还 是应该微调?
可以使用预训练和微调相结合的方式,先用篇章数据进行预训练以获取广泛的知识,再用问答对数据进 行微调,使模型更好的学习到特定领域的知识。
当然,GPT大模型的预训练和微调,从实现方式来讲是没有什么差别的,都是decoder only的语言模型 训练并更新参数,如果样本集小,没有大量的篇章文档数据,我认为只进行微调也能注入知识的,不必 太纠结预训练。而且特定领域跟预训练模型的分布差别不大,也不用二次预训练。
16. 多轮对话任务如何微调模型?
解决方法:
对 历史对话 做一层文本摘要,取其精华去其糟粕 将 历史对话 做成一个 embedding 如果是 任务型对话,可以将 用户意图 和 槽位 作为 上一轮信息 传递给 下一轮
17. 微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
所谓的灾难性遗忘:即学习了新的知识之后,几乎彻底遗忘掉之前习得的内容。这在微调ChatGLM-6B 模型时,有同学提出来的问题,表现为原始ChatGLM-6B模型在知识问答如“失眠怎么办”的回答上是正确 的,但引入特定任务(如拼写纠错CSC)数据集微调后,再让模型预测“失眠怎么办”的结果就答非所问 了。
我理解ChatGLM-6B模型是走完 “预训练-SFT-RLHF” 过程训练后的模型,其SFT阶段已经有上千指令微调 任务训练过,现在我们只是新增了一类指令数据,相对大模型而已,微调数据量少和微调任务类型单 一,不会对其原有的能力造成大的影响,所以我认为是不会导致灾难性遗忘问题,我自己微调模型也没 出现此问题。 应该是微调训练参数调整导致的,微调初始学习率不要设置太高,lr=2e-5或者更小,可以避免此问题, 不要大于预训练时的学习率。
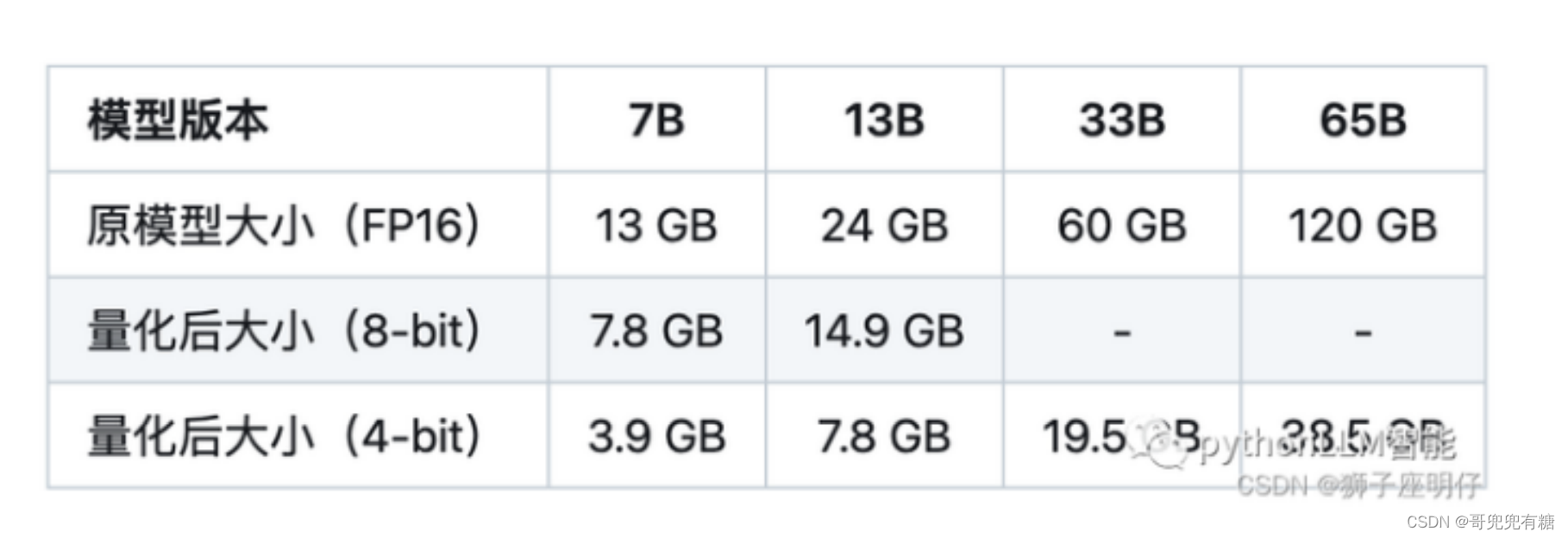
18. 微调模型需要多大显存?
19. 大模型LLM进行SFT操作的时候在学习什么?
(1) 预训练->在大量无监督数据上进行预训练,得到基础模型-->将预训练模型作为SFT和RLHF的起点。
(2) SFT-->在有监督的数据集上进行SFT训练,利用上下文信息等监督信号进一步优化模型-->将SFT训练 后的模型作为RLHF的起点。
(3) RLHF-->利用人类反馈进行强化学习,优化模型以更好地适应人类意图和偏好-->将RLHF训练后的模 型进行评估和验证,并进行必要的调整。
20. 预训练和SFT操作有什么不同
此SFT的逻辑和原来的预训练过程是一致的,但是通过构造一些人工的高质量问答语料,可以高效地 教会大模型问答的技巧。
21. 样本量规模增大,训练出现OOM错
问题描述:模型训练的样本数量从10万,增大300万,训练任务直接报OOM了。
解决方案,对数据并行处理,具体实现参考海量数据高效训练,核心思想自定义数据集本次的主要 目标是使向量化耗时随着处理进程的增加线性下降,训练时数据的内存占用只和数据分段大小有 关,可以根据数据特点,灵活配置化。核心功能分为以下几点:
均分完整数据集到所有进程(总的GPU卡数)
每个epoch训练时整体数据分片shuffle一次,在每个进程同一时间只加载单个分段大小数据 集
重新训练时可以直接加载向量化后的数据。
22. 大模型LLM进行SFT 如何对样本进行优化?
对于输入历史对话数据进行左截断,保留最新的对话记录。
去掉样本中明显的语气词,如嗯嗯,啊啊之类的。
去掉样本中不合适的内容,如AI直卖,就不应出现转人工的对话内容。
样本中扩充用户特征标签,如年龄,性别,地域,人群等
23. 模型参数迭代实验
验证历史对话轮次是否越长越好,通过训练两个模型,控制变量max_source_length| max_target_length,对训练好之后的模型从Loss、Bleu指标、离线人工评估等角度进行对比分析。 问题:描述计算机主板的功能 回答:计算机主板是计算机中的主要电路板。它是系统的支撑。 输入:描述计算机主板的功能[BOS]计算机主板是计算机中的主要电路板。它是系统的支撑。[EOS] 标签:[......][BOS]计算机主板是计算机中的主要电路板。它是系统的支撑。[EOS]
结论:从人工评估少量样本以及loss下降来看,历史对话长度1024比512长度好,后续如果训练可能上 线模型,可以扩大到1024长度。
24. 微调大模型的一些建议
1 模型结构:
模型结构+训练目标: Causal Decoder + LM。有很好的zero-shot和few-shot能力,涌现效应
layer normalization: 使用Pre RMS Norm
激活函数: 使用GeGLU或SwiGLU
embedding层后不添加layer normalization,否则会影响LLM的性能
位置编码: 使用ROPE或ALiBi。ROPE应用更广泛
去除偏置项:去除dense层和layer norm的偏置项,有助于提升稳定性
2 训练配置:
batch: 选用很大的batch size; 动态地增加batch size的策略,GPT3逐渐从32K增加到3.2M tokens。
学习率调度:先warmup再衰减。学习率先线性增长,再余弦衰减到最大值的10%。最大值一般在 5e-5到1e-4之间。
梯度裁剪:通常将梯度裁剪为1.0。
权重衰减: 采用AdamW优化器,权重衰减系数设置为0.1Adamw相当于Adam加了一个L2正则项
混合精度训练:采用bfloat16,而不是foat16来训练。
3 训练崩溃挽救:
选择一个好的断点,跳过训练崩溃的数据段,进行断点重训。选择一个好的断点的标准: 损失标度 lossscale>0;梯度的L2范数<一定值 && 波动小
25. 微调大模型时,如果 batch size 设置太小 会出现什么 问题?
当 batch size 较小时,更新方向(即对真实梯度的近似)会具有很高的方差,导致的梯度更新主要是噪 声。经过一些更新后,方差会相互抵消,总体上推动模型朝着正确的方向前进,但个别更新可能不太有 用,可以一次性应用(使用更大 batch size 进行更新)。
26. 微调大模型时,如果 batch size 设置太大 会出现什么 问题?
当 batch size 非常大时,我们从训练数据中抽样的任何两组数据都会非常相似(因为它们几乎完全匹配 真实梯度)。因此,在这种情况下,增加 batch size 几乎不会改善性能,因为你无法改进真实的梯度预 测。换句话说,你需要在每一步中处理更多的数据,但并不能减少整个训练过程中的步数,这表明总体 训练时间几乎没有改善。但是更糟糕的是你增加了总体的 FLOPS。
27. 微调大模型时, batch size 如何设置问题?
各种结果表明似乎存在着一个关于数据并行程度的临界点,通过找到这个临界点,我们可以有效的平衡 训练的效率和模型的最终效果。 OpenAI 发现最优步长:
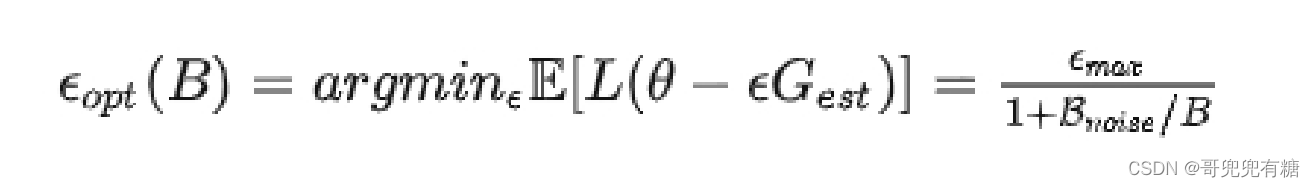
注:B 为 batch size,Bnoise为 噪声尺度
在采用最优 step size 时,从含有噪声的梯度中获得的损失的最优改进现在变为:
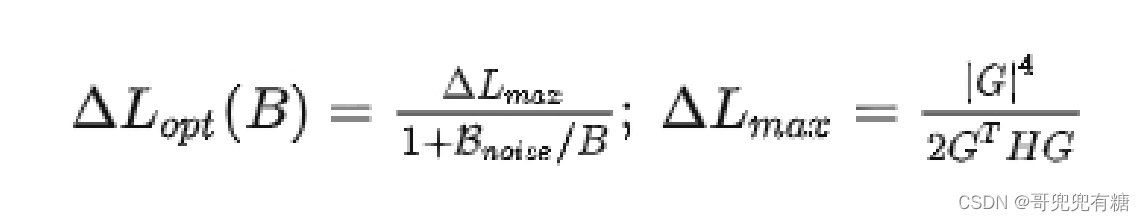
从这些公式中我们可以得出两个结论: 1. 无论我们如何准确地估计真实梯度,总存在一个最大步长 2. 批处理大小越大,我们优化模型的步长就越大(有一个上限)
28. 微调大模型时, 优化器如何?
除了Adam和AdamW,其他优化器如Sophia也值得研究,它使用梯度曲率而非方差进行归一化,可能提 高训练效率和模型性能。
29. 哪些因素会影响内存使用?
内存使用受到模型大小、批量大小、LoRA参数数量以及数据集特性的影响。例如,使用较短的训练序列 可以节省内存。
30. 进行领域大模型预训练应用哪些数据集比较好?
通过分析发现现有的开源大模型进行预训练的过程中会加入书籍、论文等数据。主要是因为这些数据的 数据质量较高,领域相关性比较强,知识覆盖率(密度)较大,可以让模型更适应考试。给我们自己进 行大模型预训练的时候提供了一个参考。同时领域相关的网站内容、新闻内容也是比较重要的数据。
31. 用于大模型微调的数据集如何构建?
进行大模型微调时,数据是比较重要的,数据的高度决定模型效果的高度,因此数据的质量重要性大于 数据的数量的重要性,因此对于构建微调数据时的几点建议如下所示:
1. 选取的训练数据要干净、并具有代表性。
2. 构建的prompt尽量多样化,提高模型的鲁棒性。
3. 进行多任务同时进行训练的时候,要尽量使各个任务的数据量平衡。
32. 大模型训练loss突刺原因和解决办法
参考:A Theory on Adam Instability in Large-Scale Machine Learning
32.1 大模型训练loss突刺是什么?
loss spike指的是预训练过程中,尤其容易在大模型(100B以上)预训练过程中出现的loss突然暴涨的 情况
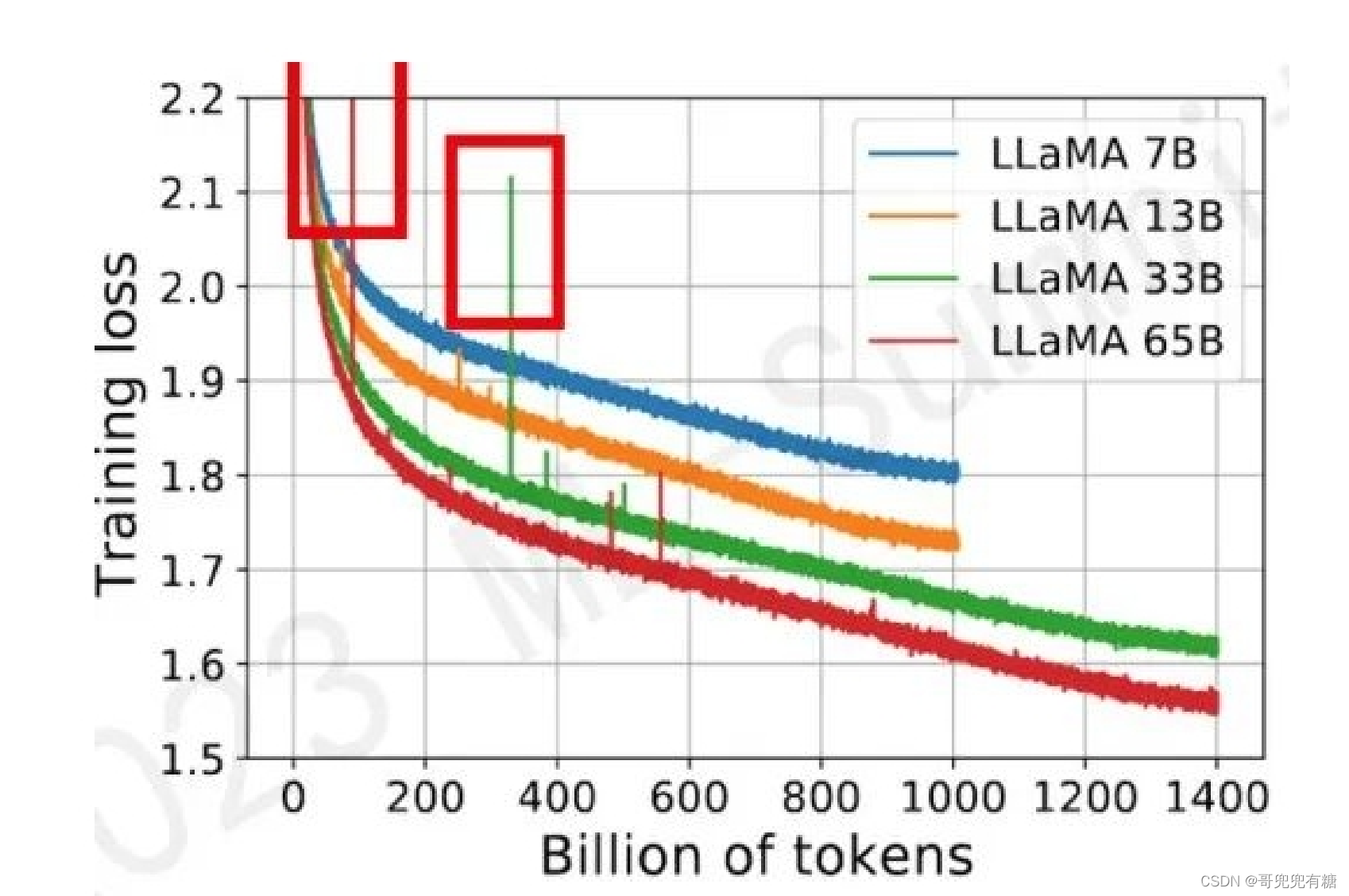
如图所示模型训练过程中红框中突然上涨的loss尖峰 loss spike的现象会导致一系列的问题发生,譬如模 型需要很长时间才能再次回到spike之前的状态(论文中称为pre-explosion),或者更严重的就是loss 再也无法drop back down,即模型再也无法收敛 PaLM和GLM130b之前的解决办法是找到loss spike之前最近的checkpoint,更换之后的训练样本来避 免loss spike的出现。
32.2 为什么大模型训练会出现loss突刺?
大模型训练使用的Adam优化器 会导致 loss突刺。
32.3 大模型训练loss突刺 如何解决?
本文最后提到了防止loss spike出现的一些方法:
1. 如之前提到的PaLM和GLM130B提到的出现loss spike后更换batch样本的方法(常规方法,但是成 本比较高)
2. 减小learning rate,这是个治标不治本的办法,对更新参数的非稳态没有做改进
3. 减小 e 大小。或者直接把 e 设为0,
其实这块我有个自己的想法,e 和 a 是否也可以做衰减,随着训练过程逐渐减小,来避免loss spike的现 象 另外假设我们能一次性加载所有样本进行训练(实际上不可能做到),是否还会出现loss spike的现象 最后目前流行的fp8,fp16混合训练,如果upscale设置的过小,导致梯度在进入优化器之前就下溢,是 不是会增加浅层梯度长时间不更新的可能性,进而增加loss spike的出现的频率。(这么看来似乎提升 upscale大小以及优化 e 大小是进一步提升模型效果的一个思路)

