
一、资源简介
这次给大家推荐一篇关于卷积神经网络迁移学习的实战资料,卷积神经网络迁移学习简单的讲就是将一个在数据集上训练好的卷积神经网络模型通过简单的调整快速移动到另外一个数据集上。
随着模型的层数及模型的复杂度的增加,模型的错误率也随着降低。但是要训练一个复杂的卷积神经网络需要非常多的标注信息,同时也需要几天甚至几周的时间,为了解决标注数据和训练时间的问题,就可以使用迁移学习。
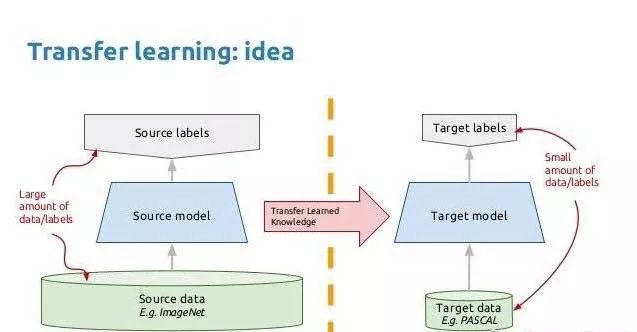
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” 。
二、主要内容
比如在训练好的inception-v3模型中,因为将瓶颈层的输出再通过一个单层的全连接层神经网络可以很好的区分1000种类别的图像,所以可以认为瓶颈层输出的节点向量可以被作为任何图像的一个更具有表达能力的特征向量。于是在新的数据集上可以直接利用这个训练好的神经网络对图像进行特征提取,然后将提取得到的特征向量作为输入来训练一个全新的单层全连接神经网络处理新的分类问题。

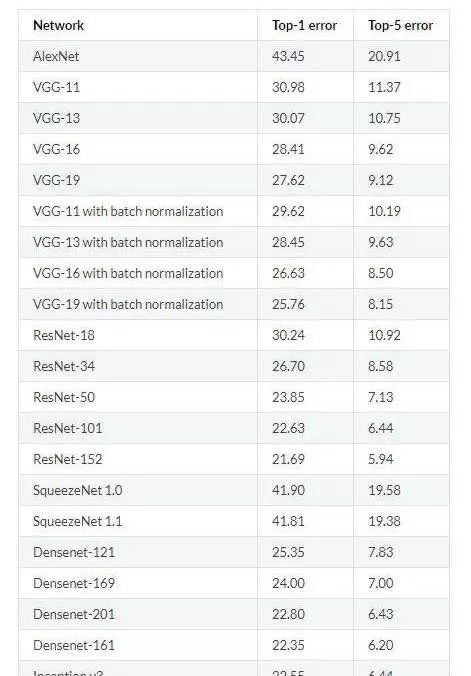
一般来说在数据量足够的情况下,迁移学习的效果不如完全重新训练。但是迁移学习所需要的训练时间和训练样本要远远小于训练完整的模型。资源见参考文献[1]
三、什么是迁移学习?
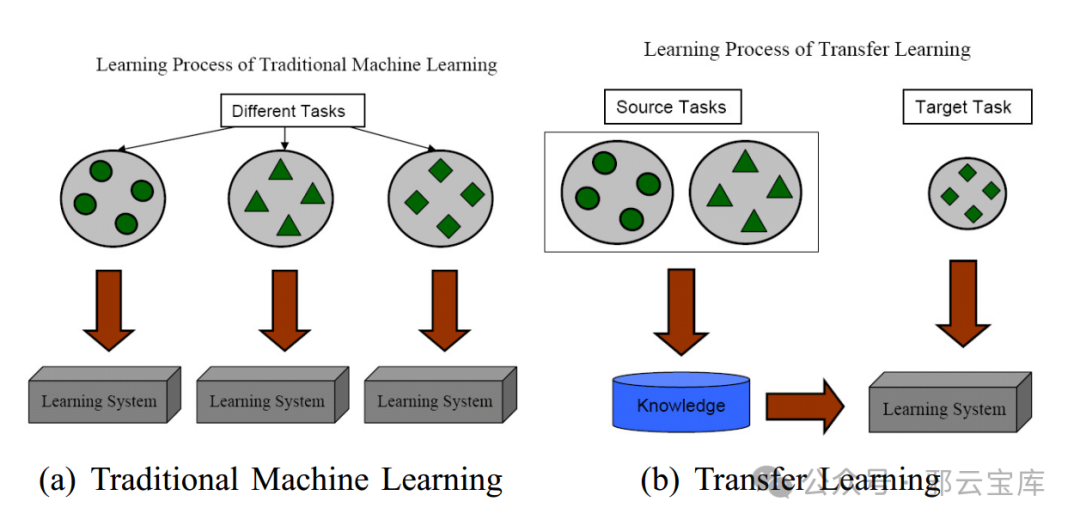
3.1 引用文章:

文章链接:
https://www.cse.ust.hk/~qyang/Docs/2009/tkde_transfer_learning.pdf迁移学习(TL)是机器学习(ML)技术的一种,是指将针对一项任务预训练的模型进行微调以用于新的相关任务。训练新的机器学习模型是一个耗时且复杂的过程,需要大量的数据、计算能力和多次迭代才能投入生产。通过迁移学习,组织则可以使用新数据针对相关任务对现有模型进行重新训练。例如,如果机器学习模型可以识别狗的图像,则可以使用较小的图像集来训练其识别猫,该图像集需要突出狗和猫之间的特征差异。
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
四、 迁移学习有哪些好处?
TL 为创建 ML 应用程序的研究人员提供了以下几项好处。
4.1 提高效率
训练 ML 模型需要时间,因为它们可以构建知识和识别模式。它还需要一个大型数据集,而且计算成本很高。在 TL 中,预训练模型保留了任务、特征、权重和功能的基础知识,使其能够更快地适应新任务。您可以使用更小的数据集和更少的资源,同时获得更好的结果。
4.2 提高可访问性
构建深度学习神经网络需要大量数据、资源、计算能力和时间。TL 克服了这些创作障碍,允许组织在自定义使用案例中采用 ML。您可以调整现有模型以满足您的需求,而只需要支出一小部分成本。例如,使用预训练的图像识别模型,您可以创建用于医学成像分析、环境监测或面部识别的模型,而只需进行最少的调整。
4.3 提高性能
通过 TL 开发的模型通常在多样化和具有挑战性的环境中表现出更高的稳健性。他们在最初的训练中接触了各种场景,因此可以更好地应对现实世界中的可变性和噪音。它们可以提供更好的结果,并更灵活地适应不可预测的条件。
五、有哪些不同的迁移学习策略?
您用于促进 TL 的策略将取决于您正在构建的模型的域、需要完成的任务以及训练数据的可用性。
5.1 转导迁移学习
转导迁移学习涉及将知识从特定的源域转移到不同但相关的目标域,主要重点放在目标域。当目标域中标记的数据很少或根本没有时,它特别有用。
转导迁移学习要求模型使用先前获得的知识对目标数据进行预测。由于目标数据在数学上与源数据相似,因此模型可以更快地找到模式并执行。
例如,考虑采用经过产品评论训练的情感分析模型来分析电影评论。源域(产品评论)和目标域(电影评论)在上下文和细节上有所不同,但在结构和语言使用上有相似之处。该模型很快学会将其对情感的理解从产品域应用到电影域。
5.2 归纳迁移学习
归纳迁移学习是指源域和目标域相同,但模型必须完成的任务不同。预训练模型已经熟悉源数据,并且可以更快地训练新功能。
自然语言处理(NLP)就是归纳迁移学习的一个例子。模型在大量文本上进行预训练,然后使用归纳迁移学习对情感分析等特定功能进行微调。同样,像 VGG 这样的计算机视觉模型在大型图像数据集上进行预训练,然后进行微调以开发目标检测。
5.3 无监督迁移学习
无监督迁移学习使用类似于归纳迁移学习的策略来开发新能力。但是,当源域和目标域中都只有未标记的数据时,可以使用这种形式的迁移学习。
当被要求执行目标任务时,该模型会学习未标记数据的共同特征,以便更准确地进行泛化。如果获取标记的源数据具有挑战性或成本高昂,则此方法非常有用。
例如,考虑在交通图像中识别不同类型的摩托车的任务。最初,该模型是根据大量未标记的车辆图像进行训练的。在这种情况下,模型独立确定不同类型的车辆(例如汽车、公共汽车和摩托车)之间的相似之处和区别特征。接下来,向模型介绍少量特定的摩托车图像。与以前相比,模型性能显著提高。
六、迁移学习的步骤有哪些?
为新任务微调机器学习模型时,主要有三个步骤。
6.1 选择预训练的模型
首先,为相关任务选择具有先验知识或技能的预训练模型。选择合适模型的一个有用上下文是确定每个模型的源任务。如果您了解模型执行的原始任务,则可以找到更有效地过渡到新任务的任务。
6.2 配置预训练模型
选择源模型后,将其配置为将知识传递给模型以完成相关任务。有两种主要的方法可以做到这一点。
6.2.1 冻结预训练层
层是神经网络的构建基块。每一层由一组神经元组成,并对输入数据执行特定的转换。权重是网络用于决策的参数。最初设置为随机值,当模型从数据中学习时,权重会在训练过程中进行调整。
通过冻结预训练层的权重,可以使它们保持固定,从而保留深度学习模型从源任务中获得的知识。
6.2.2 移除最后一层
在某些使用案例中,您还可以移除预训练模型的最后一层。在大多数 ML 架构中,最后一层是特定于任务的。移除这些最后一层有助于您重新配置模型以满足新的任务要求。
6.2.3 引入新层
在预训练模型的基础上引入新层有助于适应新任务的特殊性质。新层使模型适应新要求的细微差别和功能。
为目标域训练模型
您可以根据目标任务数据训练模型,以开发其标准输出以与新任务保持一致。预训练模型产生的输出可能与所需的输出不同。在训练期间监控和评估模型的性能后,您可以调整超参数或基线神经网络架构以进一步提高输出。与权重不同,超参数不是从数据中学习的。它们是预先设置的,在确定培训过程的效率和有效性方面起着至关重要的作用。例如,您可以调整正则化参数或模型的学习率,以提高其与目标任务相关的能力。
七、生成式人工智能中的迁移学习策略有哪些?
迁移学习策略对于各行各业采用生成式人工智能至关重要。组织可以自定义现有基础模型,而无需大规模训练数十亿个数据参数的新模型。以下是生成式人工智能中使用的一些迁移学习策略。
7.1 域对抗训练
域对抗训练涉及训练基础模型,以生成与目标域中的真实数据无法区分的数据。这种技术通常采用辨别者网络,如生成对抗网络所示,试图区分真实数据和生成数据。生成器学习创建越来越真实的数据。
例如,在图像生成中,可以对经过照片训练的模型进行调整以生成图稿。辨别者有助于确保生成的图稿在风格上与目标域保持一致。
7.2 师生学习
师生学习涉及更大、更复杂的“教师”模型,教授更小、更简单的“学生”模型。学生模型学习模仿教师模型的行为,从而有效地传授知识。这对于在资源受限的环境中部署大型生成模型非常有用。
例如,大型语言模型(LLM)可以作为小型模型的教师,传授其语言生成能力。这将允许较小的模型以更少的计算开销生成高质量的文本。
7.3 特征解缠
生成模型中的特征解缠涉及将数据的不同方面(例如内容和风格)分成不同的表现形式。这使模型能够在迁移学习过程中独立操作这些方面。
例如,在人脸生成任务中,模特可能会学习将面部特征与艺术风格区分开。这将使它能够在保持拍摄对象肖像的同时生成各种艺术风格的肖像。
7.4 跨模态迁移学习
跨模态迁移学习涉及在不同模态(例如文本和图像)之间转移知识。生成模型可以学习适用于这些模式的表示形式。经过文本描述和相应图像训练的模型可能会学习从新的文本描述中生成相关图像,从而有效地将其理解从文本转移到图像。
7.5 零样本和少样本学习
在零样本和少样本学习中,生成模型经过训练,可以执行任务或生成数据,而这些任务或数据在训练过程中很少或根本没有看到任何示例。这是通过学习具有良好泛化的丰富表示形式来实现的。例如,可以训练生成模型来创建动物图像。通过少样本学习,它可以通过理解和组合其他动物的特征来生成鲜为人知的动物图像。
八、实战例子(torch代码)
8.1 模型定义和预训练
跑的有点慢,建议转移到gpu跑
- import torch
- import torch.nn as nn
- import torchvision.models as models
- import torchvision.transforms as transforms
- import torch.optim as optim
- import torchvision.datasets as datasets
-
- # 定义预训练模型
- class PretrainedModel(nn.Module):
- def __init__(self, num_classes):
- super(PretrainedModel, self).__init__()
- self.features = models.resnet18(pretrained=True)
- self.features.fc = nn.Linear(512, num_classes) # 修改最后一层以适应新的任务
-
- def forward(self, x):
- x = self.features(x)
- return x
-
- # 数据预处理
- transform = transforms.Compose([
- transforms.Resize((224, 224)),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
- ])
-
- # 加载预训练模型并修改最后一层
- model = PretrainedModel(num_classes=10) # 假设新任务有10个类别
-
- # 准备数据集
- train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
-
- # 定义损失函数和优化器
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.Adam(model.parameters(), lr=0.001)
-
- # 训练预训练模型
- train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
- for epoch in range(5): # 仅进行5个epoch用于演示
- for inputs, labels in train_loader:
- optimizer.zero_grad()
- outputs = model(inputs)
- loss = criterion(outputs, labels)
- loss.backward()
- optimizer.step()
-
- # 保存模型
- torch.save(model.state_dict(), 'pretrained_model.pth')
- print("Pretrained model saved.")

8.2 模型读取和迁移
- # 定义迁移学习模型
- class TransferLearningModel(nn.Module):
- def __init__(self, pretrained_model, num_classes):
- super(TransferLearningModel, self).__init__()
- self.pretrained_model = pretrained_model
- self.fc = nn.Linear(10, num_classes) # 修改适应新任务的输出层
-
- def forward(self, x):
- x = self.pretrained_model(x)
- x = self.fc(x)
- return x
-
- # 读取预训练模型
- pretrained_model = PretrainedModel(num_classes=10)
- pretrained_model.load_state_dict(torch.load('pretrained_model.pth'))
-
- # 冻结预训练模型的参数
- for param in pretrained_model.parameters():
- param.requires_grad = False
-
- # 创建迁移学习模型
- transfer_model = TransferLearningModel(pretrained_model, num_classes=5) # 假设新任务有5个类别
-
- # 准备新任务的数据集
- new_train_dataset = datasets.CIFAR100(root='./data', train=True, download=True, transform=transform)
-
- # 定义新任务的损失函数和优化器
- new_criterion = nn.CrossEntropyLoss()
- new_optimizer = optim.Adam(transfer_model.fc.parameters(), lr=0.001)
-
- # 训练迁移学习模型
- new_train_loader = torch.utils.data.DataLoader(new_train_dataset, batch_size=32, shuffle=True)
- for epoch in range(5): # 仅进行5个epoch用于演示
- for inputs, labels in new_train_loader:
- new_optimizer.zero_grad()
- outputs = transfer_model(inputs)
- loss = new_criterion(outputs, labels)
- loss.backward()
- new_optimizer.step()
-
- # 保存迁移学习模型
- torch.save(transfer_model.state_dict(), 'transfer_model.pth')
- print("Transfer learning model saved.")
Ref:
[1] cnn迁移学习: https://mp.weixin.qq.com/s/r_wYhYCaUbr1WhVVKVNyLQ 链接: https://pan.baidu.com/s/11jvH8K2GwSR73zidIyQkwg 提取码: umvd
[2] 零基础实战迁移学习VGG16解决图像分类问题: https://mp.weixin.qq.com/s/PU-TQvO60593lVlSxQ9o6g
[3] 迁移学习实例:https://mp.weixin.qq.com/s/Hmyt046msq0MxWx-8pR6qg
[4] 代码模板 | 迁移学习实战torch代码: https://mp.weixin.qq.com/s/3o5UP3r_m2GconBUiC33lg
[5] Pytorch迁移学习微调技术实战:使用微调技术进行2分类图片热狗识别模型训练【含源码与数据集】:链接:https://pan.baidu.com/s/1dRJFlrHobN_H_44eRDsUlQ 提取码:qesv

