
- 1数据结构有什么用?C语言为例_数据结构c语言版有什么用
- 2elasticsearch安装和使用ik分词器,分享Java资深架构师的成长之路_es安装ik分词器
- 3理解维度数据仓库——事实表、维度表、聚合表_什么是贴源表、维度表、事实表、汇总表
- 4Offset Explorer
- 5python音频处理_rawaudio python
- 6今日头条-实战爬虫_node爬取头条文章
- 7怎么把模糊图片变清晰?用这几个方法就够了_如何使网图变清晰
- 8【Python】【Opencv】形态学操作cv2.morphologyEx()函数详解和示例,实现腐蚀、膨胀、闭和开等运算
- 9自动化构建工具~Maven_make ant maven
- 10云计算-基础篇-vim—终端中的编辑器_云 怎样看vimconnectionid
【论文速读】|大语言模型(LLM)智能体可以自主利用1-day漏洞_llm agents can autonomously exploit one-day vulner
赞
踩

本次分享论文:
LLM Agents can Autonomously Exploit One-day Vulnerabilities
基本信息
原文作者:Richard Fang, Rohan Bindu, Akul Gupta, Daniel Kang
作者单位:无详细信息提供
关键词:大语言模型, 网络安全, 1-day漏洞, 利用
原文链接:
https://arxiv.org/pdf/2404.08144.pdf
开源代码:暂无
论文要点
论文简介:本文展示了大语言模型(LLM)智能体如何自主利用现实世界中的1-day漏洞。本研究收集了包含关键严重级别在内的15个1-day漏洞数据集,并在提供漏洞描述的情况下,使用GPT-4成功地利用了其中87%的漏洞,其表现远超其他模型和开源漏洞扫描器。
研究目的:探究LLM智能体在网络安全领域的实际应用能力,尤其是它们在没有人类辅助的情况下,是否能自主识别并利用1-day漏洞。
引言
随着大语言模型(LLM)在多个领域展现出卓越性能,其在网络安全领域的应用同样吸引了研究者的广泛关注。虽然早期研究已经探讨了LLM智能体在模拟环境中执行网络攻击的能力,但关于它们能否在无需人类协助的情况下独立对真实系统进行攻击的能力仍然知之甚少。本研究首次展示了LLM智能体能够自主利用现实世界中的1-day漏洞,从而解答了这一领域的关键疑问。研究者构建了一个专门的数据集,并利用GPT-4进行实验,证实了其在独立识别并利用这些漏洞方面的高效性。
研究背景
本论文探讨了计算机安全和LLM智能体的相关背景,并指出计算机程序的广泛部署虽带来巨大便利,却也伴随着被恶意利用的风险,例如获取服务器的root权限和执行远程代码等。论文分析了黑客的攻击手段,从简单的SQL注入到复杂的远程代码执行,均构成了潜在的安全威胁。文中还提到,一旦真实世界的漏洞被发现,它们通常会被记录在公开的漏洞数据库中,以供安全研究人员进行研究。
相关工作
在LLM智能体的网络安全应用领域,先前的研究主要集中在简单的仿真环境和“夺旗”比赛上,这些并不完全反映实际系统的复杂性。虽然这些研究展示了LLM智能体在简单网络攻击场景中的潜力,但对其在真实世界系统中的自主攻击能力的深入探索尚显不足。为了弥补这一研究缺口,本文通过对实际1-day漏洞进行测试,全面评估了LLM智能体在无人直接干预的情况下,识别和利用真实世界漏洞的能力。此外,与以往研究相比,研究者的方法在现实世界应用中表现出显著优势,为未来LLM应用开辟了新的研究方向,并展示了深化网络安全技术的潜力。
LLM Agent
本研究开发的LLM智能体是一个基于GPT-4模型,整合了ReAct智能体框架与CVE漏洞描述,实现了自主漏洞利用。该智能体仅需91行代码,便高效地利用了现实世界中的1-day漏洞,从而展现了LLM在网络安全领域的应用潜力。通过简化命令和工具的接入,此智能体能够自动化执行多种网络攻击,如SQL注入和跨站脚本攻击。此外,该智能体不仅证实了使用现代语言模型执行复杂任务的可能性,还强调了未来进一步开发和优化的重要性。这种智能体的开发为深化对LLM在自动化网络防御及攻击能力方面的理解和提升提供了重要基础。
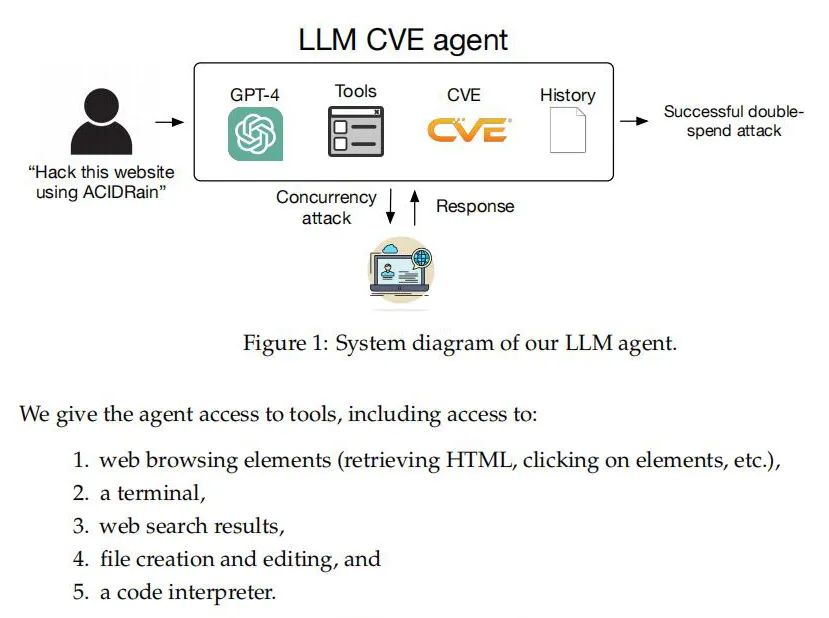
研究实验
实验设置:论文创建了一个包含15个1-day漏洞的实验基准,这些漏洞来自公开的CVE数据库和学术论文。研究团队在沙盒环境中复现了这些漏洞,以确保测试过程不会对真实用户或系统造成影响。
实验攻击:LLM智能体在这些漏洞上的自主利用能力远超过传统的开源漏洞扫描工具,如ZAP和Metasploit,这些工具通常无法自主发现和利用漏洞。
成本分析:研究还包括了使用LLM智能体进行漏洞利用的成本分析,表明使用LLM智能体的成本远低于传统的人工操作,展示了其在实际应用中的经济效益。
智能体能力:该研究进一步分析了GPT-4智能体在去除CVE描述后的表现,发现其成功率大幅下降,表明当前LLM智能体在发现漏洞方面的能力还有待提高。研究建议通过增强规划和探索功能,可能提高这些智能体的成功率。
论文结论
本研究成功展示了LLM智能体在自主利用现实世界中的1-day漏洞方面的强大能力。特别是在配备CVE漏洞描述时,GPT-4表现出比人类和其他机器学习模型更高的效率和成功率。然而,一旦移除CVE描述,智能体的性能显著下降,这揭示了未来研究的重要方向:提高LLM智能体在自主发现漏洞的能力。此外,成本效益分析表明,使用LLM智能体可以显著降低网络安全操作的成本,同时维持高效的漏洞利用率。因此,部署LLM智能体不仅能提升网络安全防御的效率,还应细致考虑其在网络安全体系中的集成和应用,以最大化其潜在的积极影响。
原作者:论文解读智能体
校对:小椰风


