
- 1C# 随机打乱数组
- 2多人同步在线编辑文档(onlyoffice)服务器部署-测试_onlyoffice/communityserver
- 3windwos10搭建我的世界服务器,并通过内网穿透实现联机游戏Minecraft_windows server mc服务器
- 4unity3d中的字符串转码方法!!!_unity string转double
- 5数据挖掘决策树python_【Python数据挖掘】决策树、随机森林、Bootsing、
- 6使用Python Flask搭建一个简单的Web站点并发布到公网上访问_flask网站的部署和发布
- 7springboot发送文件到企业微信群机器人
- 8卷积神经网络详解(一)——基础知识_卷积模拟人眼视觉
- 9opencv总结(图像基本操作、直方图与模板匹配等+实战+报错记录)_opencv直方图匹配
- 10【EFK】基于K8S构建EFK+logstash+kafka日志平台
OpenAI私有自然语言处理模型、ChatGPT官方模型、百度智能云UNIT模型定制三者的使用方式、应用场景及区别_text-embedding-ada-002
赞
踩
目录
1.3.1、text-embedding-ada-002模型
4、OpenAI私有模型、ChatGPT官方模型、百度智能云UNIT模型定制三者区别
前言
ChatGPT是OpenAI开发的一个基于大规模预训练的自然语言处理模型。GPT的全称是Generative Pre-trained Transformer,是一种基于自然语言处理的人工智能模型,可以理解、处理、生成自然语言文本。GPT-4是ChatGPT家族的第五代产品,其拥有大量的训练数据和深度神经网络结构,能够在多个自然语言处理任务上取得惊人的表现。
OpenAI致力于研究和开发人工智能技术,包括自然语言处理、计算机视觉、机器学习等领域。通过大规模的数据集和计算资源,OpenAI的研究成果在人工智能领域处于领先地位。目前,OpenAI已经开发了许多人工智能应用,例如自然语言处理模型GPT-4、计算机视觉应用DALL-E等。
当今的ChatGPT是一个强大的语言模型,它可以帮你创建出色的产品并提高你的业务成功率。ChatGPT利用大规模的自然语言处理和机器学习算法,可以进行自然而流畅的对话,理解自然语言问题和回答,你可以使用ChatGPT来建立智能客服、智能助手、文本自动补全、图片生成及变体、语音识别和机器翻译等多种产品。ChatGPT可以快速适应新的数据和新的场景,使用ChatGPT,你可以轻松实现个性化、高效率和全天候的服务。ChatGPT背后的算法基于Transformer架构,这是一种使用自注意力机制处理输入数据的深度神经网络。Transformer架构广泛应用于语言翻译、文本摘要、问答等自然语言处理任务。以ChatGPT为例,该模型在大量文本对话数据集上进行训练,并使用自我注意机制来学习类人对话的模式和结构。这使它能够生成与它所接收的输入相适应且相关的响应。
OpenAI是一家人工智能研究机构,致力于推动人工智能的发展,而ChatGPT是OpenAI在自然语言处理领域的重要研究成果,代表了OpenAI在该领域的技术水平和实力。OpenAI和ChatGPT之间的关系是相辅相成的,彼此促进,为人工智能技术的发展做出了巨大的贡献。
1、ChatGPT私有自然语言模型数据响应
第三方也没提供他们购买的openai的账号和密码给我们这边搭建自己的私有模型,训练个人的意图及词槽库。没办法在这里演示给大家看了。但我们可以列出当前可用的模型,并提供有关每个模型的基本信息,例如所有者和可用性。
1.1、私有模型列表
实例请求
- # 查看azure提供的模型
- openai.api_type = "azure"
- openai.api_key = "api_key provided by third parties" # 第三方提供的api_key
- openai.api_base = "api_base provided by third parties" # 第三方提供的api_base
- openai.api_version = "2022-12-01"
- url = openai.api_base + "API suffix" # API后缀
- r = requests.get(url, headers={"api-key": "api_key provided by third parties"}) # 第三方提供的api_key
- print(r.text)
响应 - 这里我只显示一个模型列表
- {
- "data": [
- {
- "scale_settings": {
- "scale_type": "standard"
- },
- "model": "text-davinci-003",
- "owner": "organization-owner",
- "id": "davinci",
- "status": "succeeded",
- "created_at": 1680140316,
- "updated_at": 1680269840,
- "object": "deployment"
- }
- ],
- "object": "list"
- }
1.2、搭建属于自己的 WEB AI 应用
通过第三方提供的 api_key 和 api_base 我们可以简单的搭建 web 应用,但模型输出的方式及数据响应结果取决于模型的训练程度。代码如下:
链接:https://pan.baidu.com/s/1FInYq_WRI4A7j6ySU-ypLg
提取码:lflf
AI示例
CSV文件字段

如果不想读取CSV文件的数据,想获取数据库数据,我们可以将CSV文件的数据导入到数据库中。需要在代码层面上加上数据库连接信息。示例如下:
- # 建立数据库连接
- conn = pymysql.connect(
- host="127.0.0.1", # 数据库服务器地址
- port=3306, # 数据库服务器端口号
- user="root", # 数据库用户名
- password="123456", # 数据库密码
- database="bzatest", # 数据库名
- charset="utf8mb4" #字符集
- )
-
- # 构建SQL语句
- sql = "SELECT Product, KeyMessage, TextCategory, Doc_Name, Doc_Link FROM bzatest"
-
- # 执行SQL语句
- df = pd.read_sql(sql, conn)
1.3、模型介绍及使用场景
该AI示例针对csv文件做模型查找处理,使用了 text-embedding-ada-002 模型和 davinci 模型。
1.3.1、text-embedding-ada-002模型
"text-embedding-ada-002" 模型是OpenAI提供的一个文本嵌入(text embedding)模型,它的作用是将文本转换为数值表示,也称为嵌入向量(embedding vectors)。这些嵌入向量捕捉了文本的语义和上下文信息,并可以用于各种自然语言处理(NLP)任务。例如在上述文件代码中,使用了embedding模型对 csv 文件的 KeyMessage 字段(存储为字典)计算其相应的嵌入向量,并将输入数据中的每行文本嵌入向量进行预处理,方便进行文本匹配和搜索。
该模型的使用场景包括但不限于:
- 文本相似度计算:可以利用模型生成的嵌入向量来衡量不同文本之间的相似度或距离,从而进行文本匹配、聚类或推荐等任务。
- 文本分类:通过将文本转换为嵌入向量,可以将其输入到分类模型中进行情感分析、主题分类、垃圾邮件检测等任务。
- 信息检索:可以将查询文本和文档转换为嵌入向量,以便在大规模文本库中进行高效的相似度匹配和相关性排序。
- 语义搜索:可以利用文本嵌入向量进行基于语义的搜索,从而提高更准确和相关的搜索结果。
- 命名实体识别:通过将文本转换为嵌入向量,可以对文本中的命名实体(如人名、地名、机构名等)进行识别和标记。
除了上述应用场景,"text-embedding-ada-002" 模型还可用于其他需要对文本进行语义理解和表示的任务。
使用该模型时,您需要将文本输入模型中,并获取生成的嵌入向量作为输出。您可以使用OpenAI的API或相关库(如OpenAI Python库)来调用模型并进行相应的处理。
1.3.2、davinci模型
"davinci"模型是GPT-3模型系列中最强大和最通用的模型之一。它的主要作用是进行自然语言处理任务。但目前自然语言处理模型已经更新到了GPT4,在GPT-3.5-turbo的基础上进行了延申。
该模型的使用场景包括但不限于:
- 文本生成:Davinci模型可以生成各种类型的文本,如文章、故事、评论、新闻等。通过提供一个提示或上下文,它能够生成连贯、富有逻辑和创造性的文本。通常会结合embedding模型一起使用。
- 语言理解和回答问题:Davinci模型可以理解自然语言的含义,并回答与之相关的问题。它能够从给定的文本中提取信息,并给出相关的回答。
- 对话系统和聊天机器人:Davinci模型可以进行对话,与用户进行交互并提供有意义的回复。它能够理解用户的提问、指令或对话内容,并生成合适的回应。
- 文本摘要和翻译:Davinci模型可以将长文本进行摘要,提取出关键信息或概要。此外,它还可以进行文本的翻译,将一种语言转换为另一种语言。
- 创意和艺术应用:Davinci模型在创意和艺术领域也有应用。它可以生成诗歌、音乐、绘画描述等创作内容,为创作者提供灵感和创意的支持。
总的来说,Davinci模型具备强大的文本生成和理解能力,可应用于多个领域,包括自然语言处理、对话系统、文本摘要、翻译和创意等方面。
2、ChatGPT官方模型
2.1、OpenAI GPT-4介绍
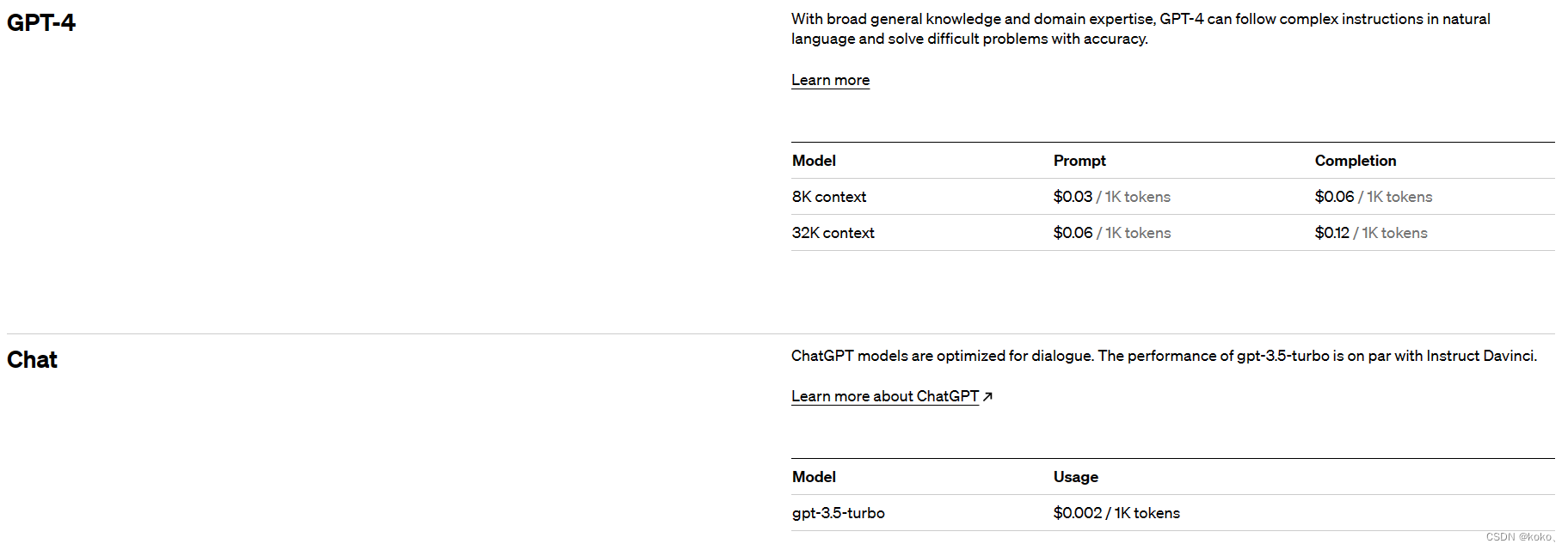
3月14日OpenAI开放了ChatGPT背后的GPT-4的模型,其定价比先前的gpt-3.5-turbo贵,对提问和回答都进行了定价,模型文本数在8k以内的,Prompt:1000个token为0.03美刀,Completion:1000个token为0.06美刀,是原先gpt-3.5-turbo模型的近六倍。
2.2、能力
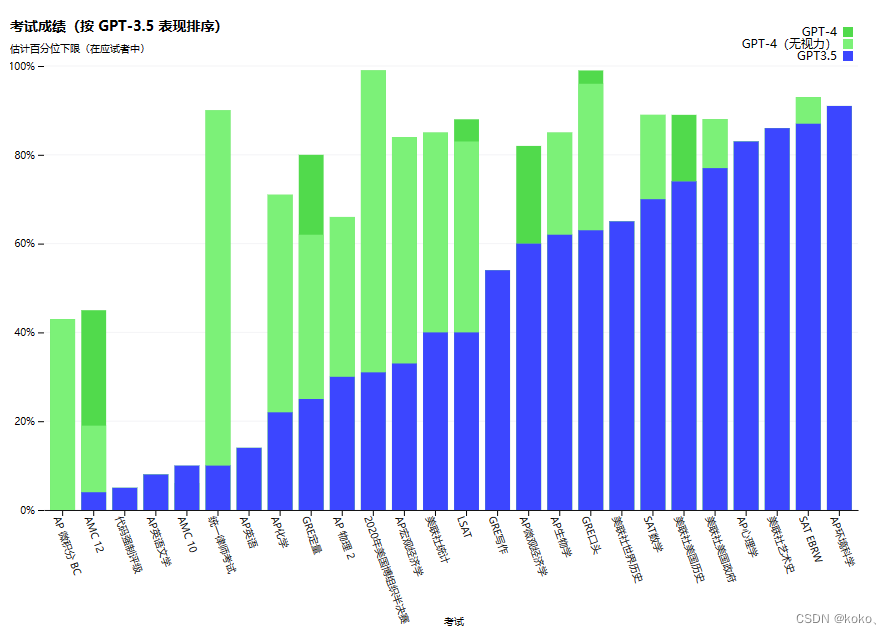
在随意的谈话中,GPT-3.5和GPT-4之间的区别可能很微妙。当任务的复杂性达到足够的阈值时,差异就出现了--GPT4比GPT3.5更可靠、更有创意,并且能够处理更细微的指令。在官网我们看到针对奥林匹克模拟考试的测试数据。

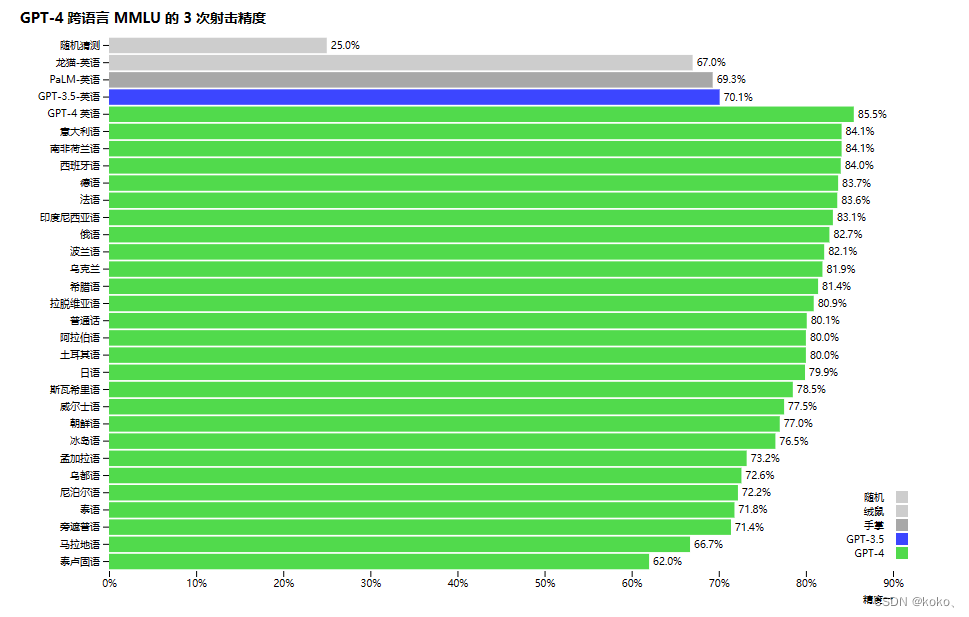
GPT-4 可以接受文本和图像的提示,这与纯文本设置并行,允许用户指定任何视觉或语言任务。具体来说,它生成文本输出(自然语言、代码等),给定由穿插文本和图像组成的输入。在一系列域(包括包含文本和照片的文档、图表或屏幕截图)上,GPT-4 表现出与纯文本输入类似的功能。此外,它可以通过为纯文本语言模型开发的测试时技术进行增强,包括少数镜头和思维链促使。图像输入仍然是研究预览,不公开可用。
我们可以看到OpenAI给出的一个分析报告,GPT-4 是一个预先训练的基于转换器的模型,用于预测文档中的下一个标记。
2.3、优势
GPT-4是严格意义上的多模态模型,可以支持图像和文字两类信息的同时输入,输出为文本。从学术界的分析来看,无论是知识/能力获取还是与显示物理世界的交互,多模态感知都是实现通用人工智能的必要条件。没有多模态,AI大概难以充分"理解"这个世界。之前的ChatGPT或GPT-3.5就像AI蒙上双眼在那里"盲答",而到了多模态的GPT-4,就是AI一边看一边思考。
在GPT-4中,多模态输入的图像和文本都基于Transformer作为通用模块/接口,图形感知模块与语言模块对接进行进一步融合计算。通过在多模态语料库上预训练模型,训练数据包含文本数据、任意交错的图像和文本,以及图像-字幕对,可以使模型获得原生支持多模态任务的能力。
一方面,多模态技术将大预言模型的应用拓展了更多高价值领域,例如多模态人机交互、文档处理和机器人交互技术。
另一方面,也更为重要的是,不同模态的模型内部融合产生了更多能力而不是简单的模态功能叠加。这一现象类似于视觉启发了更深层次的语言表达和理解。
2.4、官方模型案列
下面通过官方提供的gpt-3.5-turbo、DALL-E、Whisper、Moderation模型进行演示,当然,这一切一切能成功运行的前提是你需要会魔法。GPT-3及Embedding模型在上述代码中有,就不再演示了。

2.4.1、列出所有模型列表
列出当前可用的模型,并提供有关每个模型的基本信息,例如所有者和可用性。
示例请求
- # # 查看自己官网提供的模型
- openai.api_key = "YOUR_KEY"
- model = openai.Model.list()
- print(model)
响应-这里我只显示一个模型列表
- {
- "data": [
- {
- "created": 1677610602,
- "id": "gpt-3.5-turbo",
- "object": "model",
- "owned_by": "openai",
- "parent": null,
- "permission": [
- {
- "allow_create_engine": false,
- "allow_fine_tuning": false,
- "allow_logprobs": true,
- "allow_sampling": true,
- "allow_search_indices": false,
- "allow_view": true,
- "created": 1682538796,
- "group": null,
- "id": "modelperm-le6F1Qusxwnxz4Lcc2trugLT",
- "is_blocking": false,
- "object": "model_permission",
- "organization": "*"
- }
- ],
- "root": "gpt-3.5-turbo"
- },
- ],
- "object": "list"
- }
Turbo 与支持 ChatGPT 的模型系列相同,它针对对话式聊天输入和输出进行了优化,但与 Davinci 模型系列相比,它在完成方面同样出色。在 ChatGPT 中可以很好地完成的任何用例都应该在 API 中与 Turbo 模型系列一起很好地执行。Turbo 模型家族也是第一个像 ChatGPT 一样接收定期模型更新的模型。
2.4.2、GPT-3.5-turbo模型
使用一个简单的案列,使用OpenAI的GPT-3.5-turbo模型进行聊天,设置OpenAI的API密钥,接着调用`openai.ChatCompletion.create()`方法,通过该方法向机器人发送"hello",传入的参数包括使用的模型和需要发送的消息,最后打印机器人的回复。
示例请求
- openai.api_key = "YOUR_KEY"
-
- completion = openai.ChatCompletion.create(
- model="gpt-3.5-turbo",
- messages=[
- {"role": "user", "content": "Hello!"}
- ]
- )
-
- print(completion)
响应
- {
- "choices": [
- {
- "finish_reason": "stop",
- "index": 0,
- "message": {
- "content": "Hi there! How can I assist you today?",
- "role": "assistant"
- }
- }
- ],
- "created": 1682582930,
- "id": "chatcmpl-79qyIQGu27x9NOi7FL6tJ3aHit3ia",
- "model": "gpt-3.5-turbo-0301",
- "object": "chat.completion",
- "usage": {
- "completion_tokens": 10,
- "prompt_tokens": 10,
- "total_tokens": 20
- }
- }
2.4.3、DALL·E模型
使用 OpenAI 的 DALL·E 模型生成图片。通过设置 OpenAI 的 API 密钥进行身份验证。调用`openai.Image.create()`方法来创建图像,传入的参数包括提示(prompt)和生成的图像数量(n),以及所需图像的尺寸(size)。在这个例子中,提示为"一只可爱的猫",生成两张图像,尺寸为1024x1024像素。最后,打印出生成的图像url地址。
示例请求
- # 使用DALL*E模型绘制图片
- openai.api_key = "YOUR_KEY"
- image = openai.Image.create(
- prompt="一只可爱的猫",
- n=2,
- size="1024x1024"
- )
- print(image)
响应
- {
- "created": 1682583213,
- "data": [
- {
- "url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-UDLNj84RRb0XQzbaFD1nh1UP/user-Wtd7b3mc7ShdEKA5Ezhgu8hY/img-aeuXPycbvlANhDuheSjD2MfH.png?st=2023-04-27T07%3A13%3A32Z&se=2023-04-27T09%3A13%3A32Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2023-04-27T07%3A56%3A47Z&ske=2023-04-28T07%3A56%3A47Z&sks=b&skv=2021-08-06&sig=dFieU35KiyPnPFstYEu2is1BXgu/mi2qFQndS/Jz5QE%3D"
- },
- {
- "url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-UDLNj84RRb0XQzbaFD1nh1UP/user-Wtd7b3mc7ShdEKA5Ezhgu8hY/img-NitV7jO3MNDfeIDxazCeUqMU.png?st=2023-04-27T07%3A13%3A33Z&se=2023-04-27T09%3A13%3A33Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2023-04-27T07%3A56%3A47Z&ske=2023-04-28T07%3A56%3A47Z&sks=b&skv=2021-08-06&sig=ilZEA9UzOZH5vqQ3la4A8aydfPWV5WyiGG1CuX3zP5g%3D"
- }
- ]
- }

2.4.4、Whisper模型
使用 OpenAI 的 Whisper 语音转录模型将音频文件转换为文本。通过设置 OpenAI 的 API 密钥进行身份验证。打开指定路径下的音频文件
1.mp3并以二进制读取模式打开 ("rb")。调用openai.Audio.transcribe()方法将音频文件传递给 Whisper 模型进行转录,使用的模型版本为 "whisper-1"。转录结果将存储在变量transcript中。为了方便处理,将 OpenAI 对象transcript转换为字符串类型,并赋值给变量transcript_str。然后,使用json.loads()方法对字符串进行解码,将其转换为字典形式,并存储在变量decoded_transcript中。通过访问字典中的 "text" 键,输出转录的文本内容。
示例请求
- # 使用whisper语音转录模型,将音频文件转换为文本。
- openai.api_key = "YOUR_KEY"
- audio_file = open("./music/1.mp3", "rb")
- transcript = openai.Audio.transcribe("whisper-1", audio_file)
- # 将 OpenAI 对象转换为字符串类型
- transcript_str = str(transcript)
- # 解码并输出文本
- decoded_transcript = json.loads(transcript_str)
- print(decoded_transcript['text'])
响应
我还在想我还活着呢 这一点没关系 但是 是这样的 将近的晚风快吹干整条小巷 燃尽的灯光无法再将我们点亮 要明白有些事情不能总靠想象 大不了今晚继续喝到明天早上 看不到希望的人还在自言自语说着 遥远的不到温暖的人还在继续坐着 他对着电话那头说着自己过得很好 话断之后他又在被子里面偷偷哭了 不存在一番风顺偶尔也会去疯狂 尽管有好多人讨论着你是什么门户 慢慢也有了分寸不屑于那些争论 所以我大多数的时候都会选择沉默 付出的一切难免最后都会化为落成 就算整个世界空缺都剩我独自一人 感觉到奸相中了心里又再次痛了 把委屈抖的说好索性忘掉那些过程
2.4.5、Moderation模型
# 使用Moderation模型检测文本是否包含不适当的内容,例如涉及暴力、仇恨、色情等。
'''
返回的参数结果
id:该次审核请求的唯一ID
model:模型
result:审核结果
categories:包含不同类别的布尔值,用于表示文本是否被认为是该类别的内容
category_scores:包含每个类别的得分,得分越高表示该文本与该类别的匹配度越高
flagged:布尔值。返回true表示有暴力倾向,false表示安全
'''
示例请求
- openai.api_key = "YOUR_KEY"
- moderation = openai.Moderation.create(
- input="今天天气真好",
- )
- print(moderation)
响应
- {
- "id": "modr-79rI2GXPnI2GtgIq2Tpw3wkDq3Nrk",
- "model": "text-moderation-004",
- "results": [
- {
- "categories": {
- "hate": false,
- "hate/threatening": false,
- "self-harm": false,
- "sexual": false,
- "sexual/minors": false,
- "violence": false,
- "violence/graphic": false
- },
- "category_scores": {
- "hate": 2.4146206101249845e-07,
- "hate/threatening": 5.3389445642260114e-11,
- "self-harm": 4.241532014503946e-09,
- "sexual": 2.980155113618821e-05,
- "sexual/minors": 1.5193745639408007e-07,
- "violence": 1.618448486340185e-08,
- "violence/graphic": 1.5399773678481665e-09
- },
- "flagged": false
- }
- ]
- }
2.5、搭建属于自己的ChatGPT
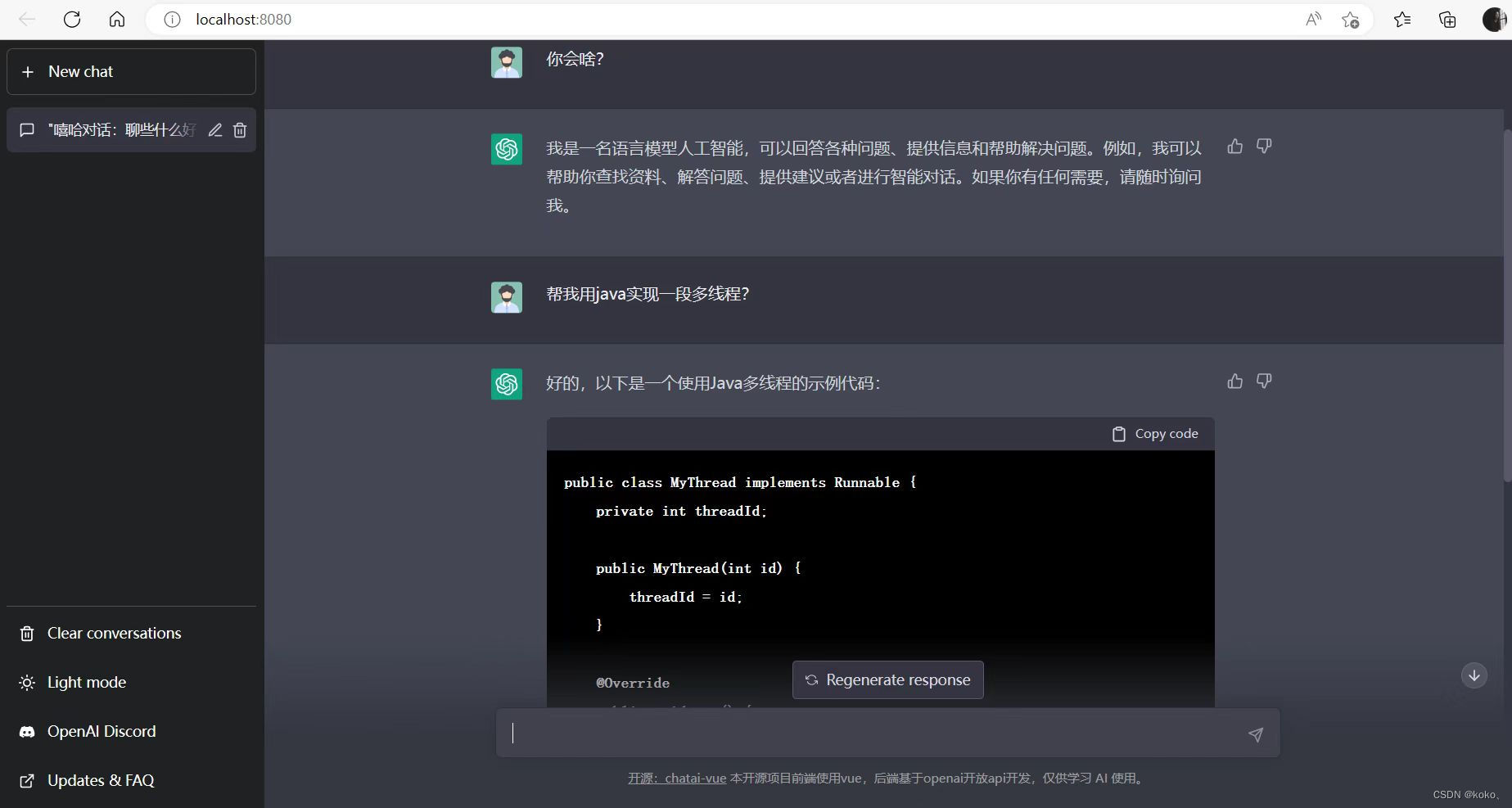
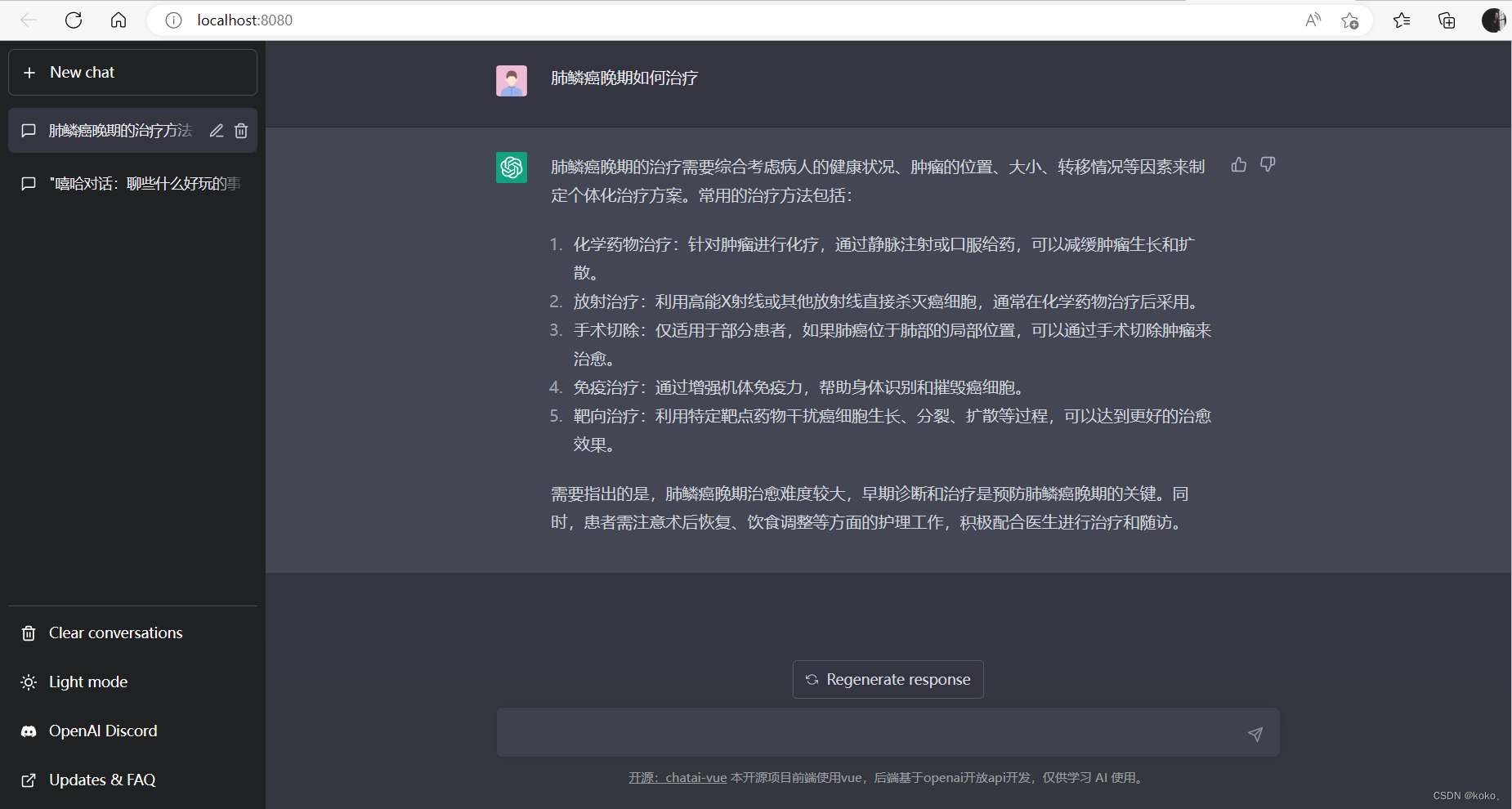
搭建属于自己的ChatGPT网页版,源码使用了第三方提供的模型(不需要魔法)及官方新型推出的gpt-3.5-turbo模型,如果不是购买的OpenAI账号,需要魔法。
效果图
3、百度智能云UNIT模型定制
3.1、介绍
百度智能云UNIT(Unified Natural Language Interface)是百度推出的自然语言处理(NLP)平台和开发工具套件。它旨在帮助开发者构建智能对话系统、聊天机器人和语音助手等人工智能应用。
百度智能云UNIT提供了以下功能和服务:
- 自然语言处理:包括自然语言理解、意图识别、实体识别、对话管理等功能,能够理解用户的输入并提供相应的回应和操作。
- 对话管理:支持多轮对话和上下文理解,能够处理复杂的对话流程和对话状态管理。
- 语义理解和生成:具备自动问答、智能推荐、文本分类、文本生成等功能,能够处理各种文本数据。
- 多模态处理:支持语音识别、语音合成和图像处理等多种模态数据的处理和应用,更贴近ChatGPT-4模型系列。
- 开发工具和API:提供了丰富的开发工具和API,开发者可以使用这些工具和API进行模型训练、对话管理、测试和部署等操作。
- 百度智能云UNIT(Unified Natural Language Interface)是百度推出的自然语言处理(NLP)平台和开发工具套件。它旨在帮助开发者构建智能对话系统、聊天机器人和语音助手等人工智能应用。
百度智能云UNIT的目标是提供一个简单易用且功能强大的平台,帮助开发者快速构建自然语言处理和对话系统应用,从而提升用户体验并实现智能化的交互体验。
3.2、优势
百度智能云UNIT在自然语言处理领域具有以下优势:
- 中文语境支持:百度智能云UNIT针对中文语境进行了优化和训练,对中文语言的理解和处理能力较强。对于需要处理中文对话或构建中文语音助手的项目,百度智能云UNIT提供了更适合的解决方案。
- 丰富的语义理解和对话管理功能:百度智能云UNIT提供了丰富的语义理解和对话管理功能,包括词法分析、句法分析、意图识别、实体识别、上下文管理等。这些功能是开发者能够更好地理解用户的意图和上下文,并进行更智能和自然的对话交互。
- 高可定制性:百度智能云UNIT提供了丰富的定制功能,开发者可以根据自己的需求进行模型定制和训练,以适应特定的应用场景和业务需求。这使得百度智能云UNIT能够灵活应用于不同行业和领域的项目。
- 强大的生态系统和技术支持:百度智能云具有完善的技术支持和丰富的开发者社区,提供详细的文档、示例代码和技术指导。开发者可以获得来自百度智能云的全面支持,以解决问题并加速开发进程。
- 高效的部署和集成:百度智能云UNIT作为云服务提供,具备高效的部署和集成能力。开发者可以轻松地将百度智能云UNIT集成到自己的应用中,快速搭建智能对话系统或聊天机器人。
总体而言,百度智能云UNIT在中文语境下具备强大的语义理解和对话管理能力,并提供了定制性、技术支持和高效的部署和集成能力,适合于构建中文语言处理应用的开发者使用。
3.3、百度智能云UNIT使用步骤
插曲
文心一言是百度智能云打造出来的人工智能大语言模型。体验文心一言的大语言模型,需要获取内测资格,反正我是没有资格,但我们可以利用百度智能云UNIT搭建自己的私有模型语料库,虽然没有文心一言的大语言模型强大,但我们可以体验模型构建的整个流程及文心一言背后的语料库到底有多强大。
3.3.1、登录理解与交互平台UNIT官网
3.3.2、文档中心
这里就不在这里演示操作步骤了,UNIT官方提供了详细的文档。
3.3.3、添加技能和训练自己的模型
如果要训练自己的模型,添加自己的意图与词槽语料库,需要新建自己的技能。详细看UNIT官方提供的文档,我这里只演示部分截图。
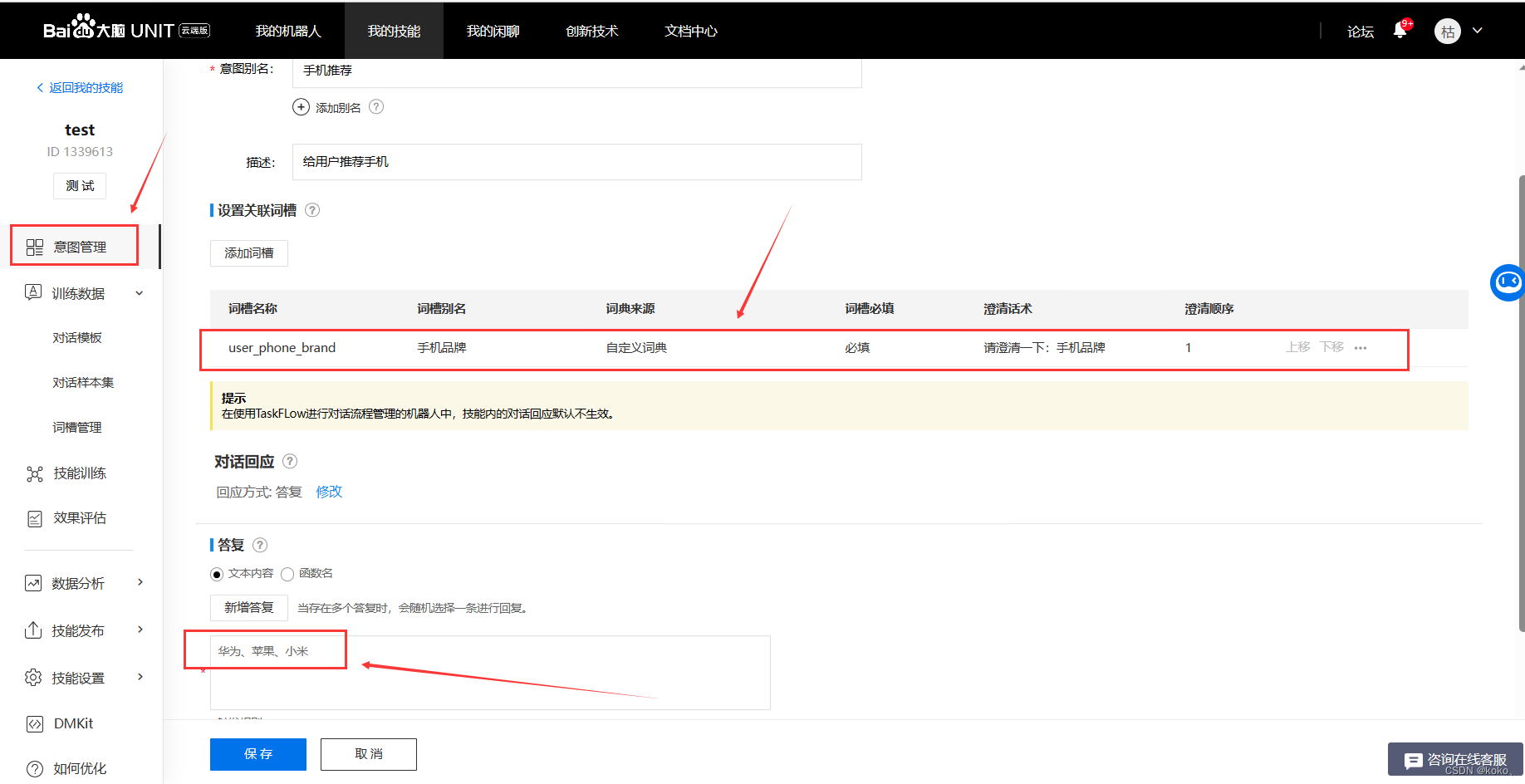
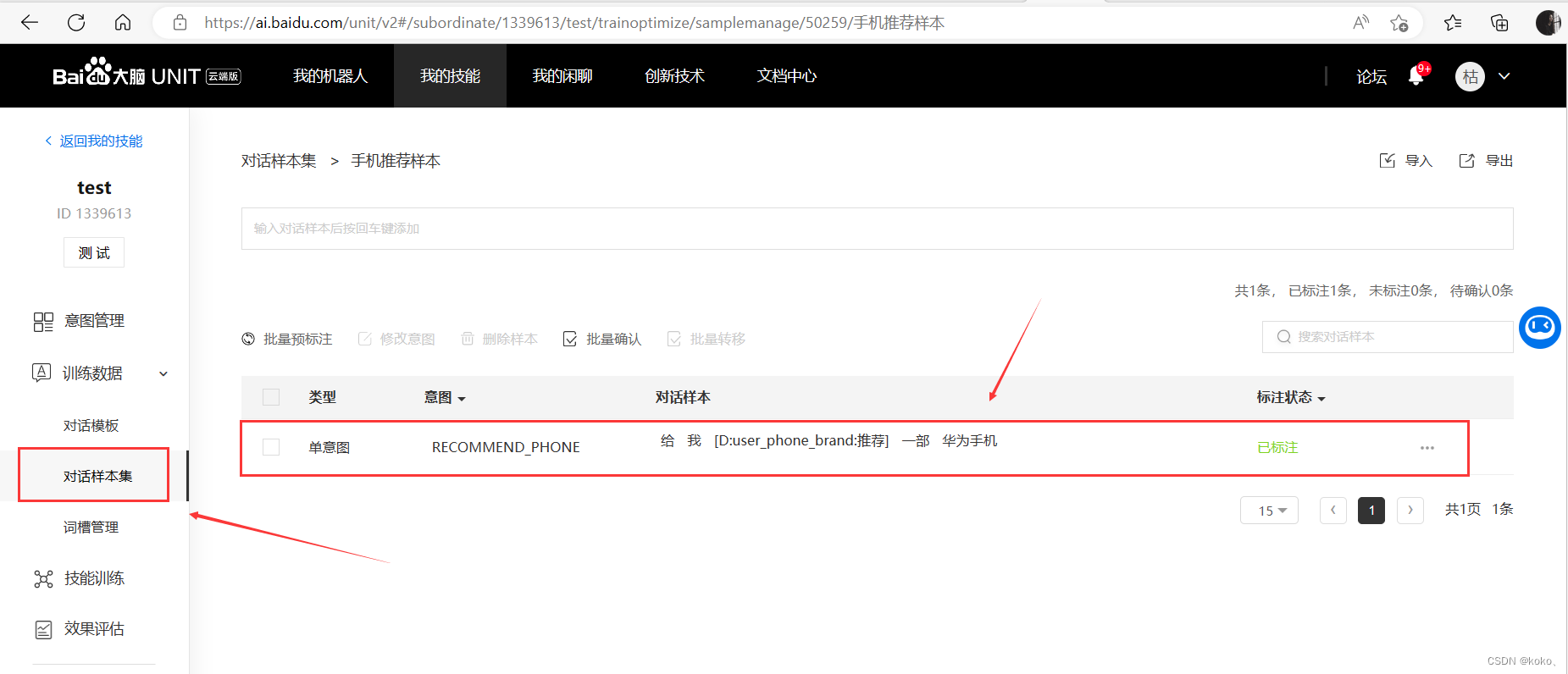
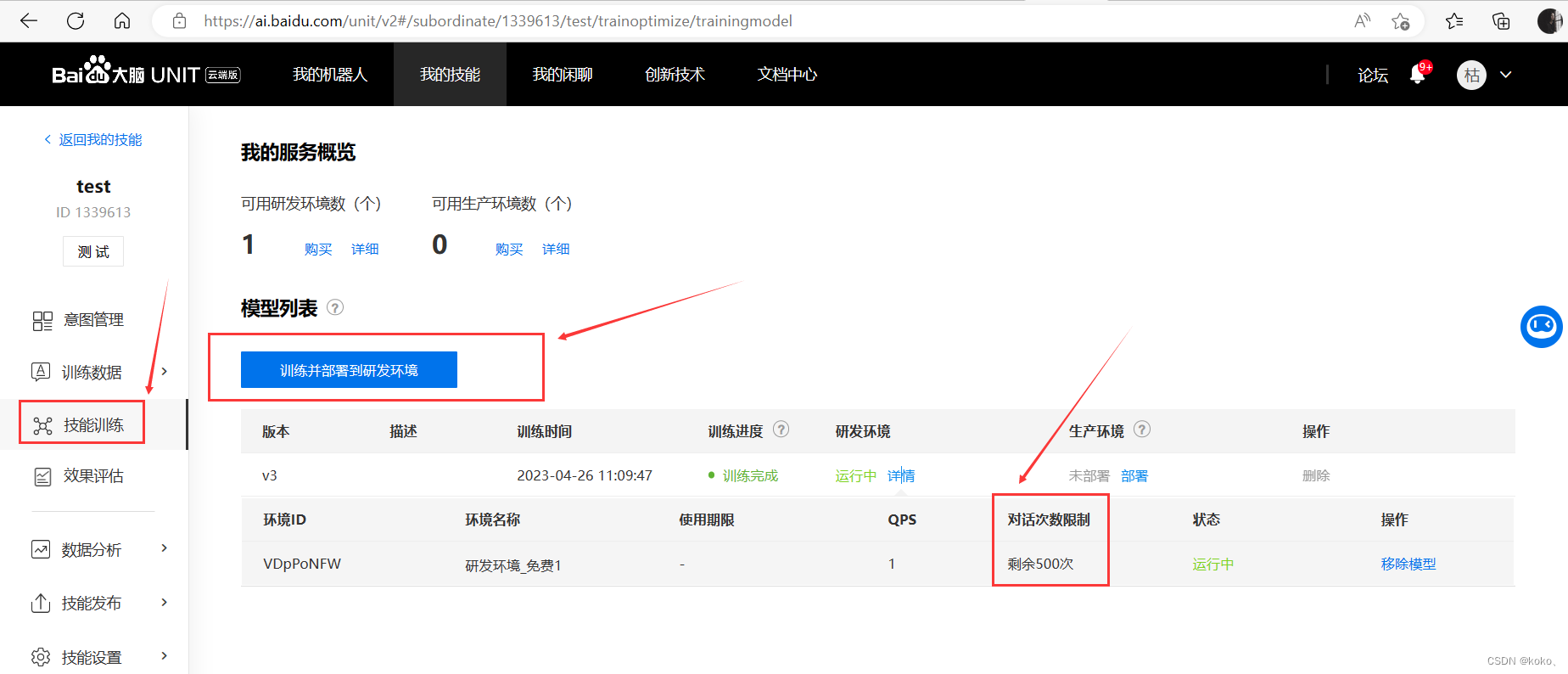
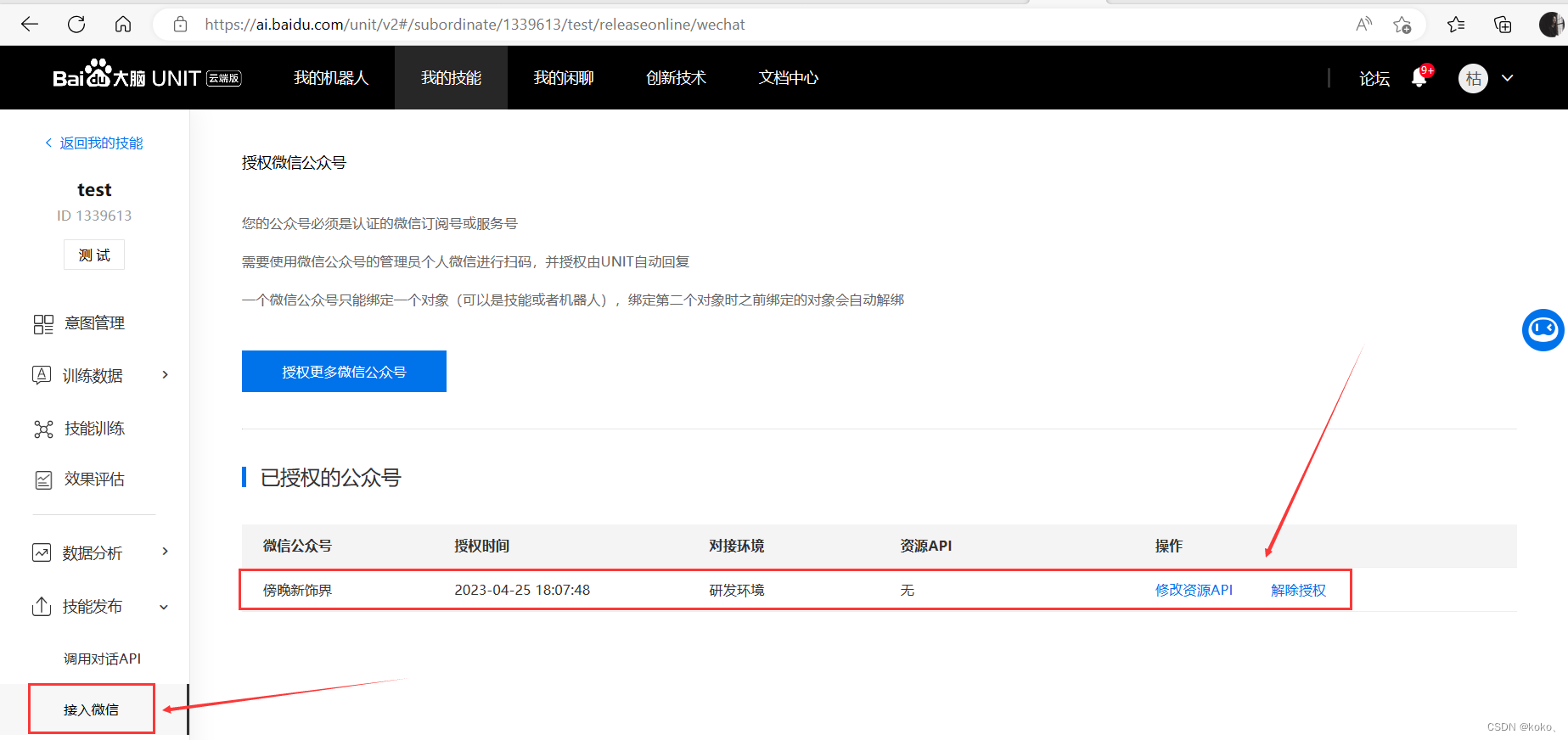
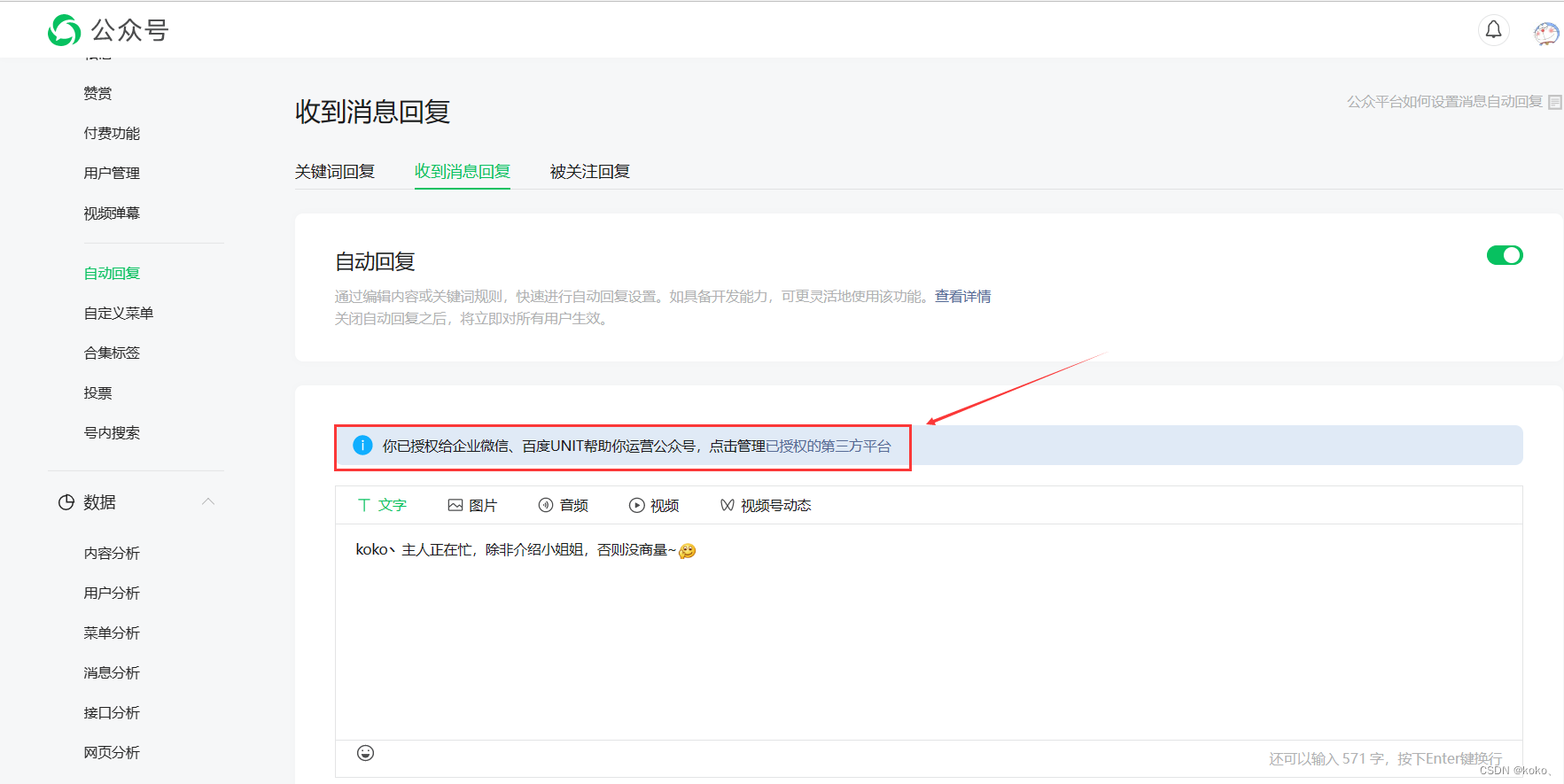
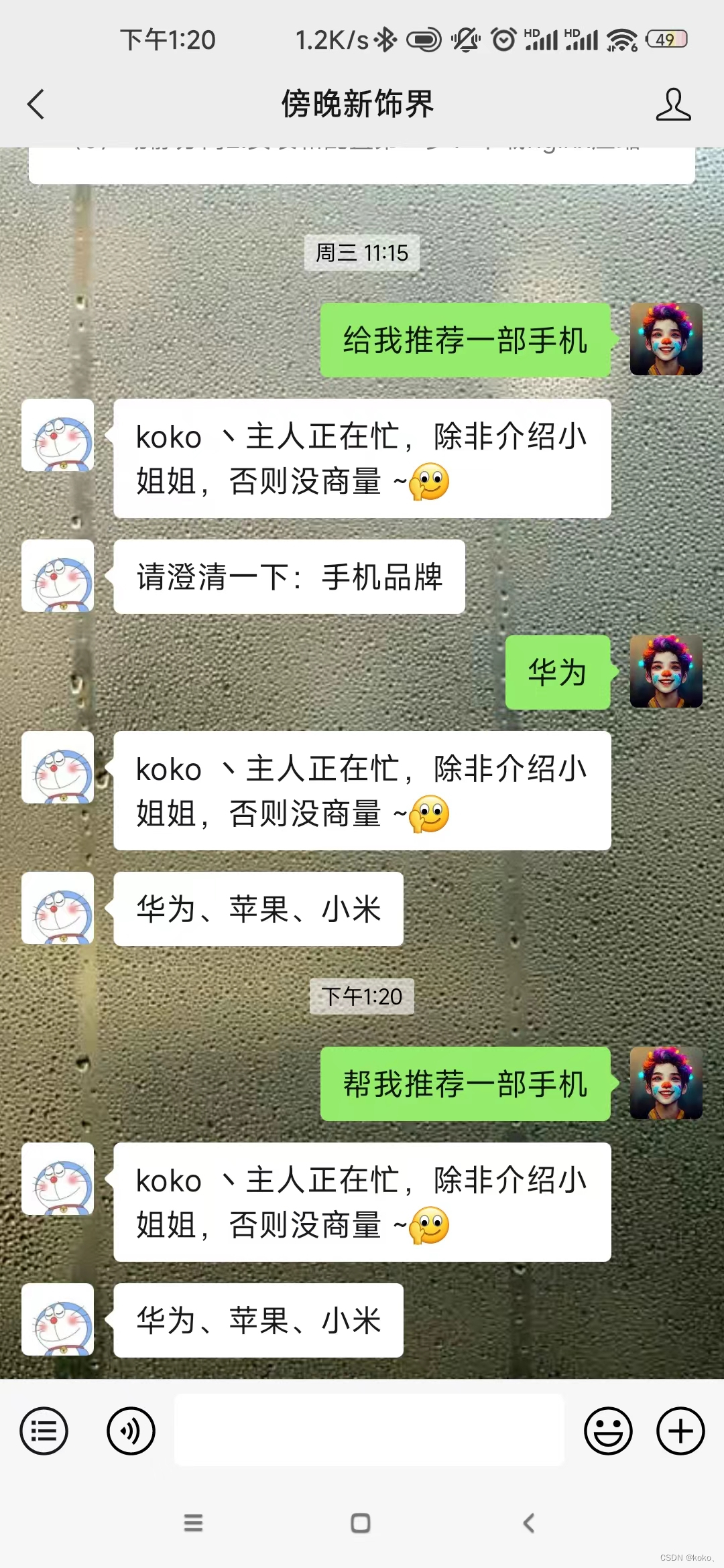
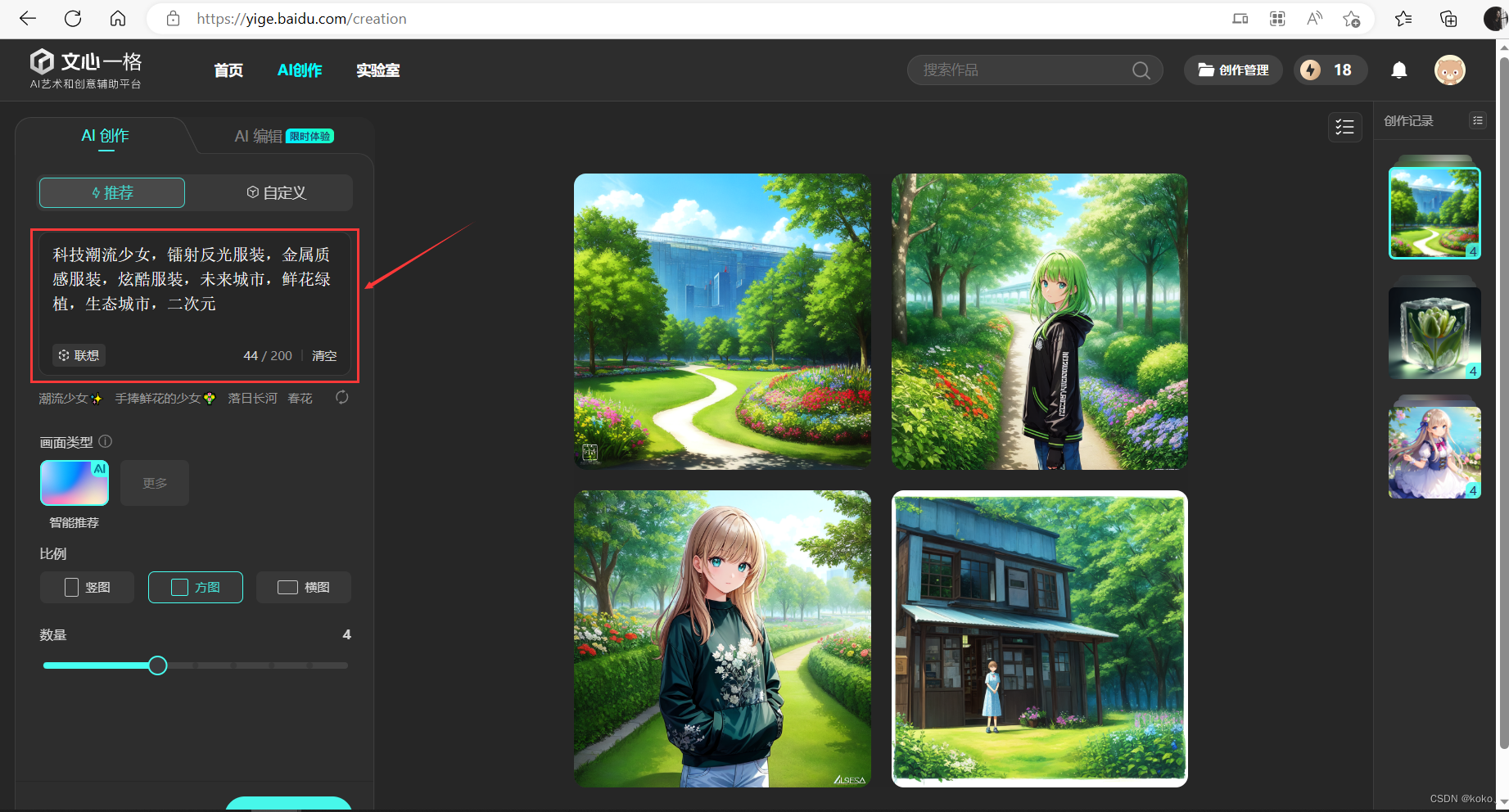
3.3.4、文心一格图片生成
4、OpenAI私有模型、ChatGPT官方模型、百度智能云UNIT模型定制三者区别
百度智能云UNIT和ChatGPT(GPT-3.5)是两个不同的自然语言处理(NLP)平台,由不同的公司开发和提供。
- 功能和服务:百度智能云UNIT主要专注于提供自然语言理解和对话管理的功能,帮助开发者构建智能对话系统和聊天机器人。它提供了丰富的语义理解和生成功能,支持多轮对话、上下文理解和对话状态管理等。ChatGPT(GPT-3.5)则是OpenAI开发的大型语言模型,其主要目标是生成自然语言文本,可以用于生成文章、回答问题、写作辅助等。
- 数据和训练:百度智能云UNIT的训练基于百度海量的中文语料库和对话数据,针对中文语境进行了优化和训练。而ChatGPT(GPT-3.5)的训练则基于英文语料库,并且在大量的英文文本数据上进行了训练和优化。
- 公司背景和支持:百度智能云是百度公司推出的云计算和人工智能服务平台,提供了多种云服务和开发工具。ChatGPT则是OpenAI开发的语言模型,OpenAI是一家专注于人工智能研究和开发的公司。
- 开放性和使用方式:百度智能云UNIT主要作为云服务提供给开发者使用,开发者可以通过百度智能云平台进行调用和集成。ChatGPT(GPT-3.5)则以API方式提供给开发者使用,开发者可以通过调用API接口于模型进行交互。
总体而言,百度智能云UNIT注重于中文语境下的语义理解和对话管理,提供丰富的功能和定制性;而ChatGPT则是一个通用的聊天型语言模型,用于生成自然语言文本,对英文支持更为强大。百度智能云UNIT和ChatGPT(GPT-3.5)都是为了帮助开发者构建自然语言处理应用,而OpenAI私有模型更贴近百度智能云UNIT的模型定制,搭建自己的意图和词槽语料库,但针对的语言和训练数据不同,并且由不同的公司提供和支持。选择使用哪个平台取决于具体的需求、语言环境和开发者的偏好。
5、ChatGPT的利与弊
ChatGPT是一种人工智能工具,有利有弊。它可以作为学习工具,用来扩展思维开拓写论文的思路或者用来进行知识的学习和知识解答。如果学生使用ChatGPT,在学业上一定是弊大于利。ChatGPT可以化繁为简,缩短耗时,进行自动化生产,但是ChatGPT会生成一些看似很通顺、很有可信度的文本,但其实可能是编造出来的,虽然底层采用了算法实现,真实性还是无法得到论证。ChatGPT目前的知识库主要还是2021年9月之前的数据,并且ChatGPT没有互联网的能力,所有的训练都是基于预先的数据集,这样导致其缺乏新数据,这与企业做数据分析决策的及时性要求完全不符。
5.1、利
5.1.1、提升教学效率
ChatGPT作为一种AI语言模型,可以自动生成语言表达,能够在大幅度节省教师准备课程的时间的同时,保证课程的质量。这对于传统的教学方式来说,是一种非常大的改进。
例如,在教授数学等需要大量练习的学科时,ChatGPT 可以根据学生所学习的阶段,自动生成大量的题目,使学生能够更好地掌握知识点。
5.1.2、普及教育资源
ChatGPT可以通过自然语言理解的方式,帮助学生理解复杂的知识点,从而帮助他们更好地学习。ChatGPT还可以将大量的教育资源整合起来,为每个学生提供个性化的学习资源。
例如,在学习外语时,学生可以通过 ChatGPT 的翻译功能来学习外语,同时,也可以利用 ChatGPT 整合各种语言学习资源,让学生更好地学习。
5.1.3、促进教育公平
ChatGPT能够提供个性化的教育资源,为每个学生提供公平的学习机会。这种方式不仅能够帮助优秀的学生更好地学习,也能够帮助那些本来在学习上存在障碍的学生更好地掌握知识。
例如,在较为贫困的地区,由于缺少资源,教育条件相对较差, ChatGPT 可以为这些学生提供更多的学习资源,让他们能够得到更好的教育。
5.2、弊
5.2.1、可能加剧教育差距
虽然 ChatGPT 可以为每个学生提供个性化的学习资源,但是对于一些家庭条件不好的学生来说,可能无法获得 ChatGPT 提供的服务。这会导致一些学生与其他学生之间的教育差距进一步扩大,导致社会不公平现象的加剧。此外,如果 ChatGPT 技术过于依赖,会导致学生对于自主学习的能力和意愿下降,从而产生消极影响。因此,在应用 ChatGPT 技术时,需要考虑如何解决教育差距和自主学习的问题,以保证教育公平和学生能力的全面发展。
5.2.2、隐私和数据安全问题
在利用ChatGPT的过程中,学生的个人信息和数据会被收集和使用,这会涉及到隐私和数据安全问题。如果相关的数据管理措施不足,这些信息和数据可能会被泄露或被用于其他不良目的,从而对学生的权益产生不利影响。
5.2.3、算法的不透明性
ChatGPT的算法过于复杂,导致其决策过程难以理解和解释。这会使得学生难以理解学习内容的生成过程,从而难以评估内容的准确性和可靠性。同时,这也会使得相关的决策者难以监督和控制ChatGPT的生成过程,从而可能导致一些不良影响的产生。
6、总结
ChatGPT强大的内容生成能力,引起了业界普遍关注,也加速了人工智能行业从决策式/分析式AI到生成式AI的演化。
比如:
(1)12月初左右,纽约市禁止学生和教师使用ChatGPT,其原因是针对内容和准确性的担忧,担心对学生学习的负面影响,它不能培养批判性思维和解决问题的能力,而这些技能对于学术和成功至关重要。参考该链接:由 Michael Elsen-Rooney 在 Chalkbeat 发表的一篇内容。
(2)2月17日,港大禁用ChatGPT等AI工具,为全港大学首例,香港内部邮件明确表示,禁止在港大所有课堂、作业和评估中使用ChatGPT或其它AI工具,除非学生事先获得有关课程讲师的书面同意豁免,否则将被校方视为剽窃案。参考该链接: 港大禁用ChatGPT等AI工具
(3)3月31日,意大利国家的数据监管机构已下令开发聊天机器人的OpenAI停止运营,其原因是OpenAI可能违反隐私和数据法;该监管机构还提到OpenAI的安全漏洞,用户可以暂时看到彼此的搜索和支付细节,并且缺乏对儿童的保护;ChatGPT面向13岁以上的用户,但网站上没有年龄检查。参考该链接:暂停巨型人工智能实验:一封公开信 - 生命未来研究所
当然,推动历史及未来的发展,不得不更近时代的脚步。GPT时代,国内学界和企业也相继基于大语言模型推出自研的大模型。
比如:
| 自研单位 | 大模型 | 芯片 | 深度学习框架 | AI大模型 | ChatGPT自应用场景 | AIGC应用场景 |
| 百度 | 文心一言 | 昆仑芯 | 飞桨 | 文心-NLP大模型 文心-CV大模型 文心-跨境态大模型 文心-生物计算大模型 文心-行业大模型 | 智能搜索 智能云 自动驾驶 智能地图汽车智能化 智能家居 | AI作画 AI写作 AI编剧 AI语音 AI视频创作 |
| 科大讯飞 | 星火 | CSK400X | / | 中文预训练模型 | 同声传译 内容审核 内容分发 | 智慧音效 |
| 腾讯 | HunYuan | 紫霄 | PocketFlow | 混元大模型 | 内容创作 检索 推荐 | AI写稿 |
| 阿里 | 通义千问 | 含光800 | EPL XDL | AI模型 M6 | 阿里云 钉钉 | AI海报设计 |
| 微软 | Microsoft XiaoIce | / | CNTK | MT-NLG | 智能搜索 智能办公 | AI歌词创作系统 定制语音技术 |


