
- 1如何通过IIS设置301重定向_重定义iis服务路径
- 2SSH框架学习之Hibernate ---- 4、Hibernta的查询操作API_hibanate异步查询
- 3vLLM部署推理及相关重要参数_vllm prompt 参数
- 4二叉搜索树 和 哈希表 (JAVA)
- 5signature=31b14d6b78c312a19862874a7a48a87e,webpack-spritesmith/package-lock.json at a87bd0845ca4e83c...
- 6python3 - AES 加密实现java中SHA1PRNG 算法
- 7C++登录系统
- 8谁说专科学历找不到Java工作?自学Java,第一份工作13k。_学历低java找不到工作怎么办
- 9Ubuntu16.04下ssh和samba服务器安装与配置_简述使用openssh和samba的服务安装配置过程
- 10Githack下载安装教程 windows_githack安装过程
Python深度学习03——Keras卷积神经网络(CNN)实现_from keras.layers import
赞
踩
参考书目:陈允杰.TensorFlow与Keras——Python深度学习应用实战.北京:中国水利水电出版社,2021
本系列基本不讲数学原理,只从代码角度去让读者们利用最简洁的Python代码实现深度学习方法。
卷积神经网络
卷积神经网络其实是做互相关运算,和概率论里面的卷积公式不是一个东西。理论就不过多介绍了,记住卷积神经网络是用于图像处理的,并且接受的输入不再是机器学习或者多层感知机里面的二维输入,由于图片本身就是二维数据了,再加上样本的个数这个维度,图片起码都是三维数据,并且考虑颜色通道不一样,四维的数据也很常见。
Keras里面的卷积层主要是Conv1(一维卷积层),Conv2(二维卷积层),UpSampling2D(1D)上采样层,MaxPooling2D(1D)最大池化层,AveragePooling2D(1D)平均池化层。
一般的卷积案例都采用MNIST手写数字集,这个数据集是黑白的,而且太简单了,MLP就能取得很好的分类效果。因此本次案例采用Cifar-10彩色数据集,其官网为:https://www.cs.toronto.edu/~kriz/cifar.html
该数据集为10分类的问题,物品为飞机汽车鸟狗青蛙等.......下面开始案例
卷积神经网络Python案例
Keras内置数据集,导入包导入数据:(若是有同学想学怎么把图片变成数据,可以看后面章节)
- from keras.datasets import cifar10
- import matplotlib.pyplot as plt
- # 载入 Cifar10 数据集, 如果是第一次载入会自行下载数据集
- (X_train, Y_train), (X_test, Y_test) = cifar10.load_data()
- print("X_train.shape: ", X_train.shape)
- print("Y_train.shape: ", Y_train.shape)
- print("X_test.shape: ", X_test.shape)
- print("Y_test.shape: ", Y_test.shape)

展示结果为训练数据为5w张,测试集数据为1w。每个数据都是32*32的图片,并且*3表示是三种颜色,下面打印前9张图片看看
- #绘出9张图片
- sub_plot= 330
- for i in range(0, 9):
- ax = plt.subplot(sub_plot+i+1)
- ax.imshow(X_train[i], cmap="binary")
- ax.set_title("Label: " + str(Y_train[i]))
- ax.axis("off")
-
- plt.subplots_adjust(hspace = .5)
- # 显示数字图片
- plt.show()

下面开始构建神经网络,首先将数据归一化,y是10分类问题,所以要独热编码
- import numpy as np
- import pandas as pd
- from keras.models import Sequential
- from keras.layers import Dense
- from keras.layers import Flatten
- from keras.layers import Conv2D
- from keras.layers import MaxPooling2D
- from keras.layers import Dropout
- from tensorflow.keras.utils import to_categorical
-
- # 指定随机数种子
- seed = 10
- np.random.seed(seed)
-
- # 因为是固定范围, 所以执行正规化, 从 0-255 至 0-1
- X_train = X_train.astype("float32") / 255
- X_test = X_test.astype("float32") / 255
- # One-hot编码
- Y_train = to_categorical(Y_train)
- Y_test = to_categorical(Y_test)

定义卷积模型
- # 定义模型
- model = Sequential()
- model.add(Conv2D(32, kernel_size=(3, 3), padding="same",input_shape=X_train.shape[1:], activation="relu"))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Dropout(0.25))
- model.add(Conv2D(64, kernel_size=(3, 3), padding="same",activation="relu"))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Dropout(0.25))
- model.add(Flatten())
- model.add(Dense(512, activation="relu"))
- model.add(Dropout(0.5))
- model.add(Dense(10, activation="softmax"))
- model.summary() #显示模型摘要资讯
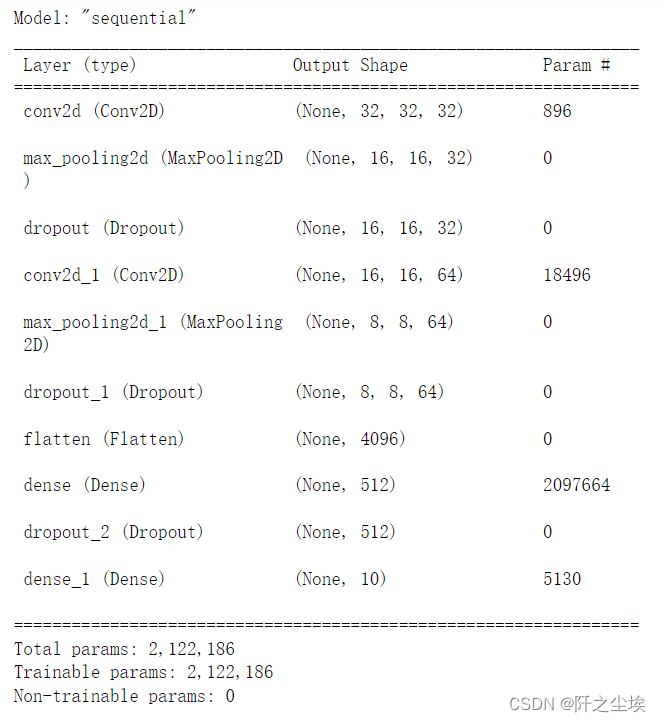
32表示卷积核的格式,kernel_size表示卷积核大小,padding表示补零为相同尺寸(填充),strides表示填充步幅。最大池化层里面的pool_size=(2, 2)表示缩小比例。
编译模型,然后开始训练拟合,因为数据太大,只训练个20轮吧
- # 编译模型
- model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
- # 训练模型
- history = model.fit(X_train, Y_train, validation_split=0.2, epochs=20, batch_size=128, verbose=2)

在训练集和测试集上评估模型
- # 评估模型
- print("\nTesting ...")
- loss, accuracy = model.evaluate(X_train, Y_train)
- print("训练数据集的准确度 = {:.2f}".format(accuracy))
- loss, accuracy = model.evaluate(X_test, Y_test)
- print("测试数据集的准确度 = {:.2f}".format(accuracy))

储存模型
- #存储Keras模型
- print("Saving Model: cifar10.h5 ...")
- model.save("cifar10.h5")
画出损失变化
- # 显示训练和验证损失
- loss = history.history["loss"]
- epochs = range(1, len(loss)+1)
- val_loss = history.history["val_loss"]
- plt.plot(epochs, loss, "bo-", label="Training Loss")
- plt.plot(epochs, val_loss, "ro--", label="Validation Loss")
- plt.title("Training and Validation Loss")
- plt.xlabel("Epochs")
- plt.ylabel("Loss")
- plt.legend()
- plt.show()

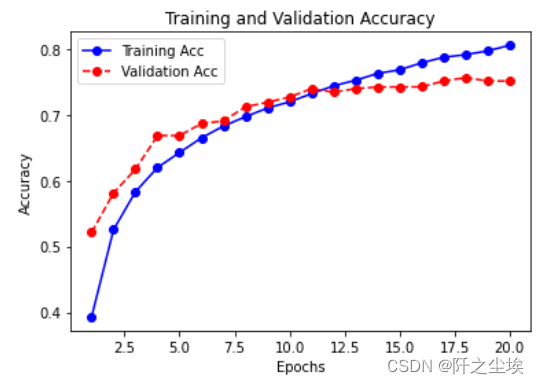
画出准确率变化
- # 显示训练和验证准确度
- acc = history.history["accuracy"]
- epochs = range(1, len(acc)+1)
- val_acc = history.history["val_accuracy"]
- plt.plot(epochs, acc, "bo-", label="Training Acc")
- plt.plot(epochs, val_acc, "ro--", label="Validation Acc")
- plt.title("Training and Validation Accuracy")
- plt.xlabel("Epochs")
- plt.ylabel("Accuracy")
- plt.legend()
- plt.show()
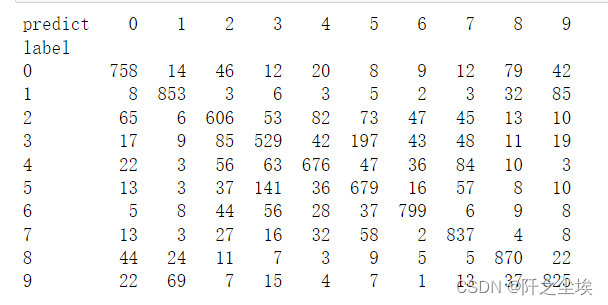
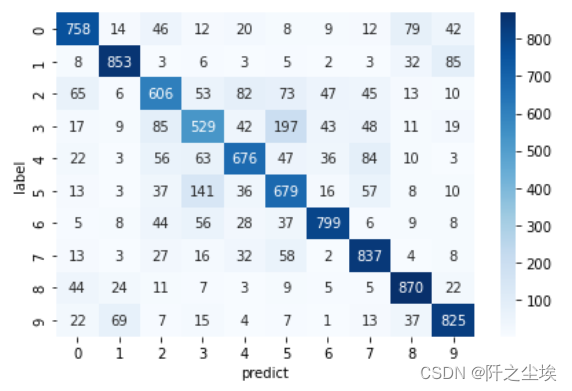
计算预测结果的评价
- # 计算分类的预测值
- print("\nPredicting ...")
- predict=model.predict(X_test)
- Y_pred=np.argmax(predict,axis=1)
- #重新加载Y_test
- (X_train, Y_train), (X_test, Y_test) = cifar10.load_data()
-
- #计算混淆矩阵
- #显示混淆矩阵
- tb = pd.crosstab(Y_test.astype(int).flatten(),
- Y_pred.astype(int),
- rownames=["label"], colnames=["predict"])
- print(tb)
-
画热力图
- import seaborn as sns
- sns.heatmap(tb,cmap='Blues',fmt='.20g',annot=True)
- #fmt='.20g'不使用科学计数法,annot=True表示增加注释
- plt.tight_layout()
随便选一个图片,看模型预测其概率准不准
- #重新归一化
- X_train = X_train.astype("float32") / 255
- X_test = X_test.astype("float32") / 255
-
- #选第10张图片
- i = 10
- img = X_test[i]
- # 将图片转换成 4D 张量
- X_test_img = img.reshape(1, 32, 32, 3).astype("float32")
-
- # 绘出图表的预测结果
- plt.figure()
- plt.subplot(1,2,1)
- plt.title("Example of Image:" + str(Y_test[i]))
- plt.imshow(img, cmap="binary")
- plt.axis("off")
 这是个飞机
这是个飞机
看模型预测的种类概率
- #预测结果的概率
- print("Predicting ...")
- probs = model.predict(X_test_img, batch_size=1)
- plt.subplot(1,2,2)
- plt.title("Probabilities for Each Image Class")
- plt.bar(np.arange(10), probs.reshape(10), align="center")
- plt.xticks(np.arange(10),np.arange(10).astype(str))
- plt.show()

模型几乎38%认为是飞机,35%认为是鹿....(差点就错了)
下面查看分类错误对象的记录
- Y_probs=model.predict(X_test) # 概率
- Y_pred=np.argmax(predict,axis=1)# 分类
- # 建立分类错误的 DataFrame 物件
- Y_test = Y_test.flatten()
- df = pd.DataFrame({"label":Y_test, "predict":Y_pred})
- df = df[Y_test!=Y_pred] # 筛选出分类错误的资料
- print(df.shape)
- print(df.head())
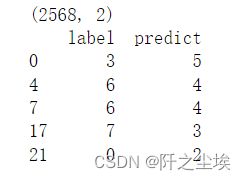 有2568个分类错误了
有2568个分类错误了
随机选一张看看
- #随机选 1 个错误分类的数字索引
- i = df.sample(n=1).index.values.astype(int)[0]
- print("Index: ", i)
- img = X_test[i]
-
- # 绘出图表的预测结果
- plt.figure()
- plt.subplot(1,2,1)
- plt.title("Example of Image:" + str(Y_test[i]))
- plt.imshow(img, cmap="binary")
- plt.axis("off")
- plt.subplot(1,2,2)
- plt.title("Probabilities for Each Image Class")
- plt.bar(np.arange(10), Y_probs[i].reshape(10), align="center")
- plt.xticks(np.arange(10),np.arange(10).astype(str))
- plt.show()

这是一个船,但是模型几乎90%认为它是一个汽车....
再选一个看看

这是一个猫,但是模型几乎60%认为它是一只马....
还是很有意思的,同学们可以调整模型参数让其准确率更高,再来进行测评
下一章介绍自编码器去处图片噪声。

