
热门标签
热门文章
- 1行人重识别简介+数据集+核心论文点_清华大学夏季行人vana77
- 2一文读懂MEMS技术4大主要分类及应用领域
- 3百度墨斗鱼文库创作中心源码分析_百度墨斗鱼源码
- 4基于FPGA的哈希表设计_fpga hash表
- 5GPT-3.5 接口教程 | 实现计数窗口的大数据处理_android 如果和接入gpt3.5
- 6OpenCV实现SfM(三):多目三维重建_cv:: solvepnpransac ( object_points , image_points
- 7Unity 图片序列帧动画的三种方法(个人总结,若有其它方法欢迎交流)_unity如何把多张图片变成序列帧
- 8FastAdmin中RequireJs是如何调用的_fastadmin js文件中定义的方法如何调用
- 9Http与Https区别及404状态码
- 10华为“老司机”亲身经历告诉你,华为硬件究竟是如何开发?
当前位置: article > 正文
【Hudi】Upsert原理
作者:盐析白兔 | 2024-02-22 06:10:59
赞
踩
【Hudi】Upsert原理
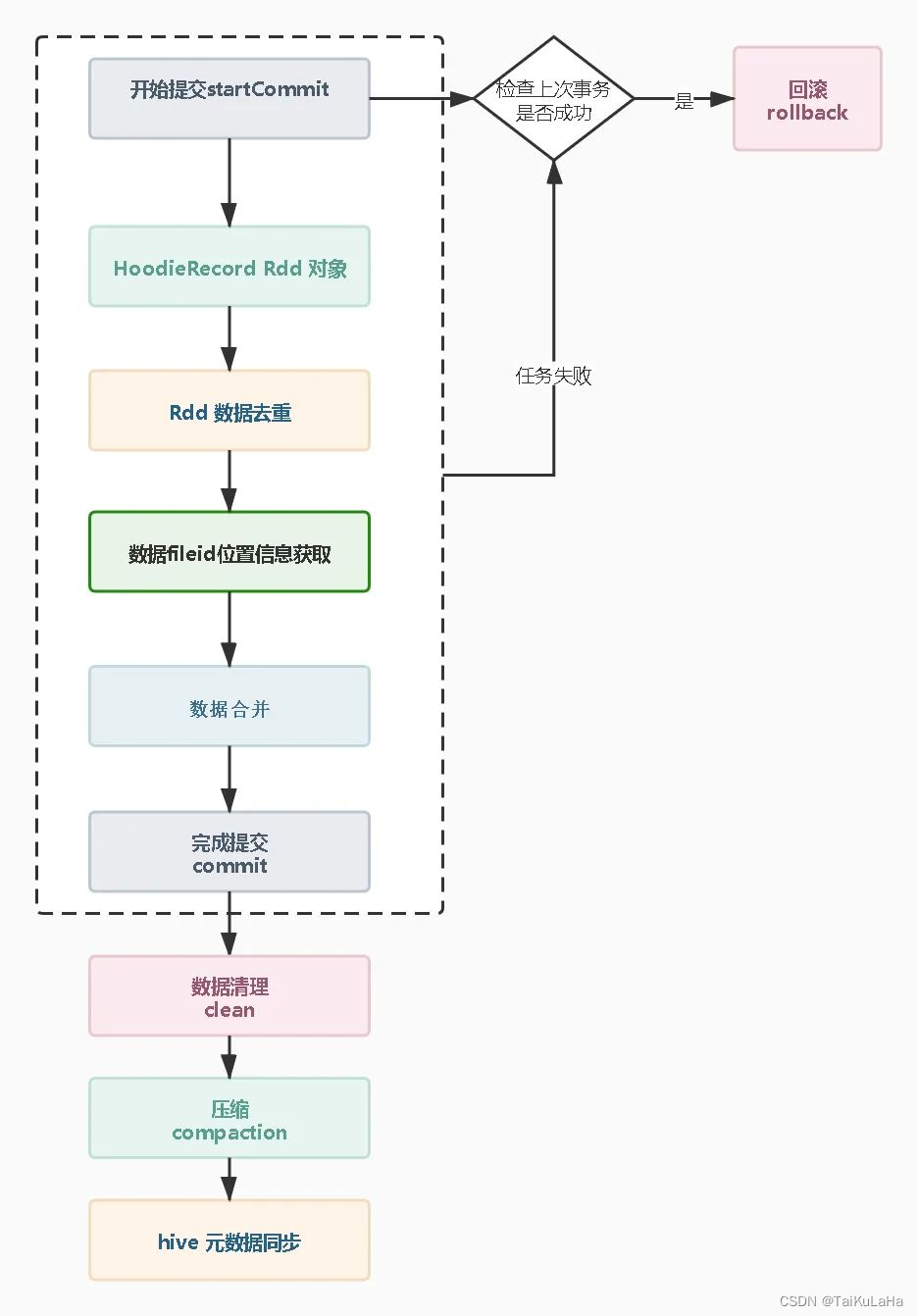
1.开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。2.构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd 对象,方便后续数据去重和数据合并。3.数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重避免重复数据写入Hudi 表。4.数据fileId位置信息获取:在修改记录中可以根据索引获取当前记录所属文件的fileid,在数据合并时需要知道数据update操作向那个fileId文件写入新的快照文件。5.数据合并:Hudi 有两种模式cow和mor。在cow模式中会重写索引命中的fileId快照文件;在mor 模式中根据fileId 追加到分区中的log 文件。6.完成提交:在元数据中生成xxxx.commit文件,只有生成commit 元数据文件,查询引擎才能根据元数据查询到刚刚upsert 后的数据。7.compaction压缩:主要是mor 模式中才会有,他会将mor模式中的xxx.log 数据合并到xxx.parquet 快照文件中去。8.hive元数据同步:hive 的元素数据同步这个步骤需要配置非必需操作,主要是对于hive 和presto 等查询引擎,需要依赖hive 元数据才能进行查询,所以hive元数据同步就是构造外表提供查询。
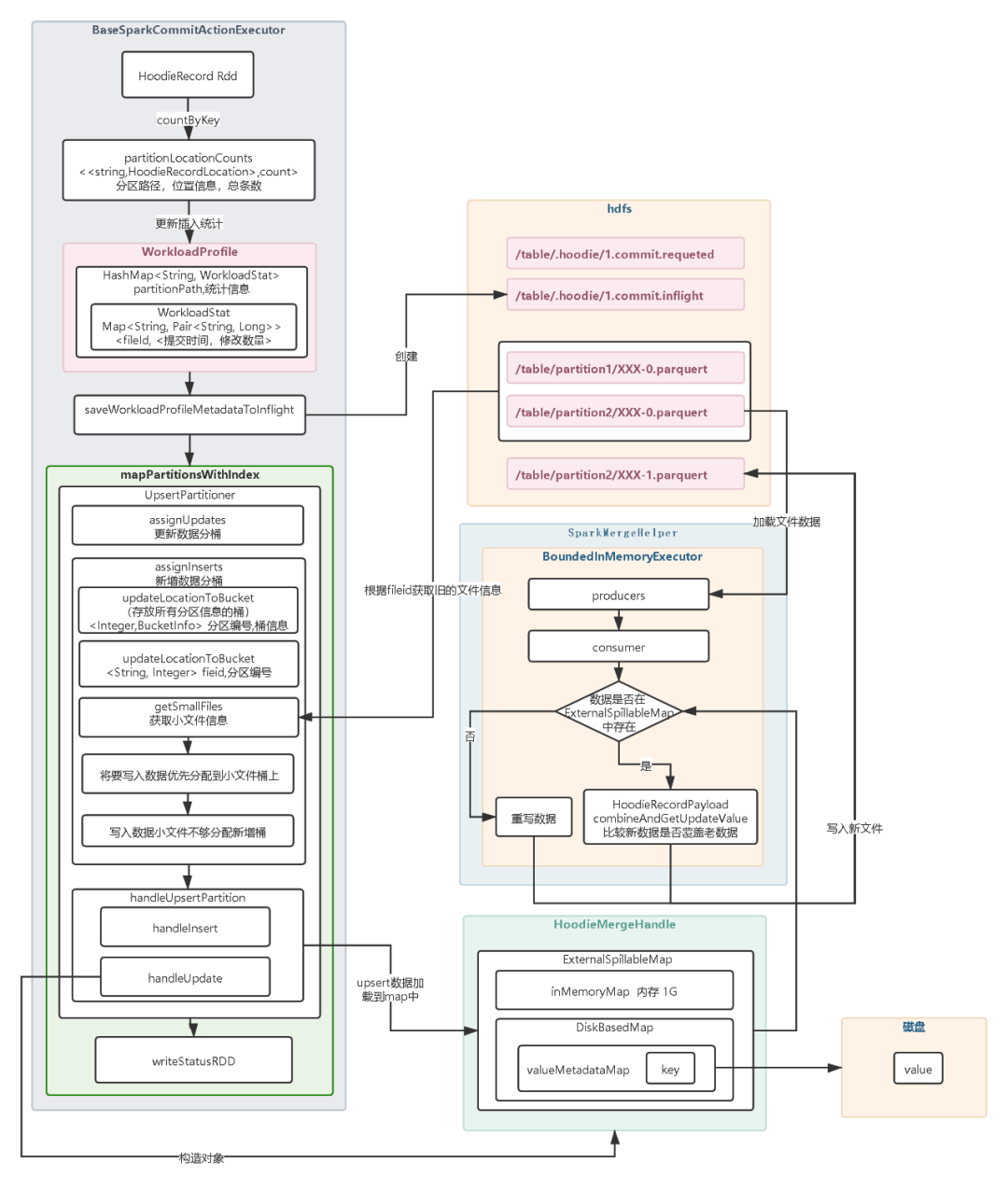
2.5.1 Copy on Write模式
COW模式数据合并实现逻辑调用BaseSparkCommitActionExecutor#excute方法,实现步骤如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/128860
推荐阅读
相关标签

