
- 1Python学生管理系统
- 2计算机组成与设计实验二:单周期CPU设计_实验二:单周期cpu设计
- 3frp内网穿透搭建-宝塔版
- 4信息安全毕业设计题目汇总 网络安全毕设选题_信息安全选题
- 5k8s中 分布式存储器longhorn的安装_longhorn 安装
- 6git 报错--unable to access ‘https://XXX/imooc-visualization.git_git unable to access
- 7gensim提取一个句子的关键词_HanLP《自然语言处理入门》笔记--9.关键词、关键句和短语提取...
- 8Kubernetes 持久卷_volumeclaimtemplates
- 9如何在centos8中安装中文输入法(系统自带中文输入法)_centos8中文输入法
- 10signature=48af92c80b14d6f07db6ad0b6715c38e,api-sdk/yarn.lock at 45ab63baf852b160338d58e36cfed960ae7d...
机器学习——二分类、多分类的精确率和召回率_多分类的准确率和召回率
赞
踩
机器学习有很多评估的指标。有了这些指标我们就横向的比较哪些模型的表现更好。我们先从整体上来看看主流的评估指标都有哪些:

分类问题评估指标:
- 准确率 – Accuracy
- 精确率(差准率)- Precision
- 召回率(查全率)- Recall
- F1分数
- ROC曲线
- AUC曲线
回归问题评估指标:
- MAE
- MSE
接下来我们看看分类模型的评估指标:
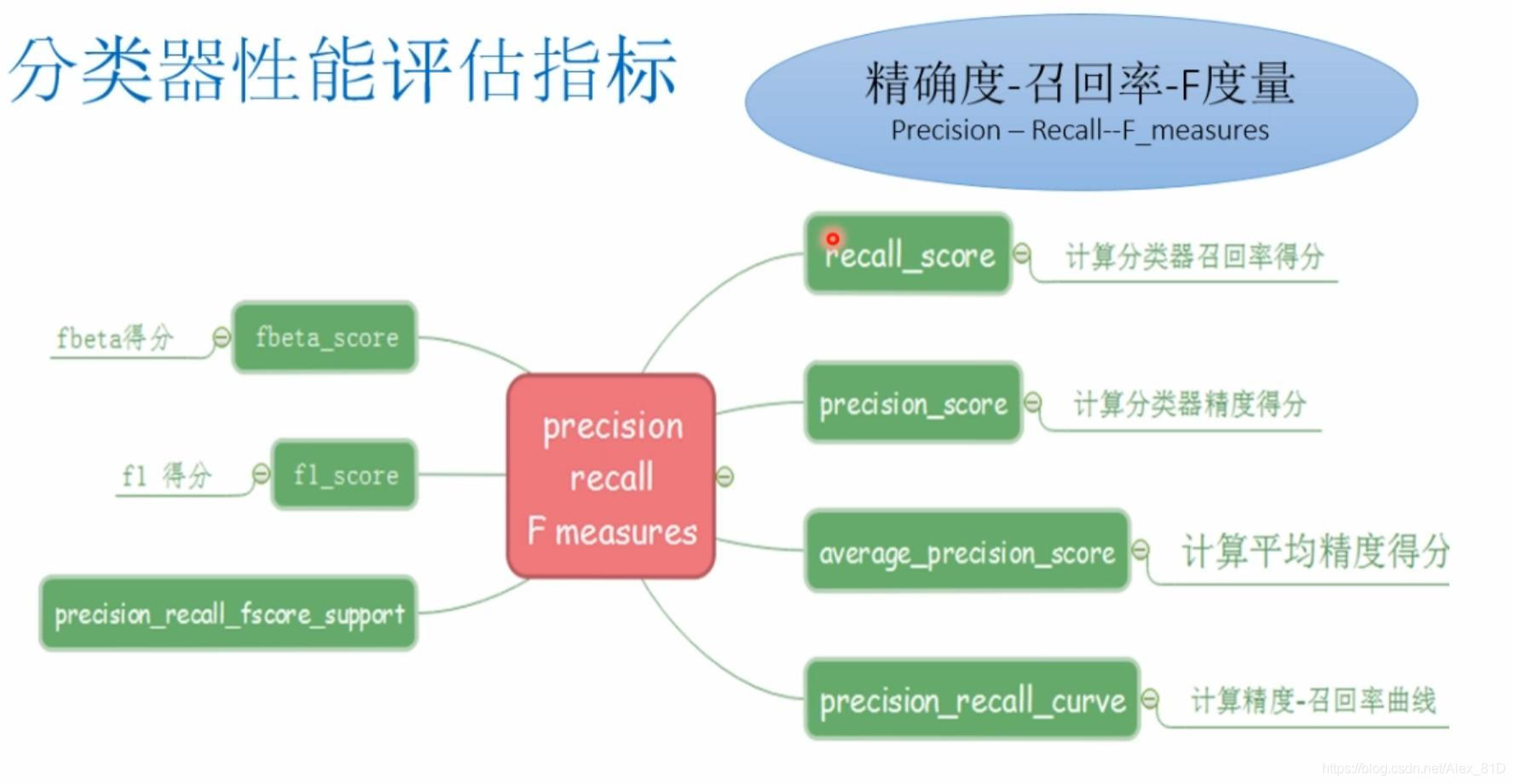
本文我们就来聊一聊准确率、召回率、精确率
1、混淆矩阵
了解上述概念前,我们先了解一下混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵(matching matrix)。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。

2、准确率 – Accuracy :预测正确的结果占总样本的百分比
准确率 =(TP+TN)/(TP+TN+FP+FN)
虽然准确率可以判断总的正确率,但是在样本不平衡 的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占 90%,负样本占 10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到 90% 的高准确率,但实际上我们并没有很用心的分类,只是随便无脑一分而已。这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
3、精确率(差准率)- Precision :所有被预测为正的样本中实际为正的样本的概率(只针对正样本)
精准率 =TP/(TP+FP)
精准率和准确率看上去有些类似,但是完全不同的两个概念。精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本
4、召回率(查全率)- Recall : 实际为正的样本中被预测为正样本的概率(只针对正样本)
召回率=TP/(TP+FN)
召回率的应用场景: 比如拿网贷违约率为例,相对好用户,我们更关心坏用户,不能错放过任何一个坏用户。因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重偿失。召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
多分类计算也是一样的:

=====================================================================================
今天聊聊AUC,重点是公式和代码(20210331更新)
什么是AUC?
相信这个问题很多玩家都已经明白了,简单的概括一下,AUC(are under curve)是一个模型的评价指标,用于分类任务。
那么这个指标代表什么呢?这个指标想表达的含义,简单来说其实就是随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
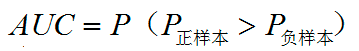
具体关于AUC含义的分析:
1.浅层:auc就是一个衡量模型好坏的指标,是roc下方的面积
2.浅层:auc就是一个衡量模型排序的指标,它可以用来针对正负样本失衡的场景下的,模型择优
3.深层:他衡量的是排完序之后,随机从正样本中抽一个它的分数大于随机从负样本中抽取一个分数的概率。roc怎么绘制的。
接下来用代码实现一下几种auc的计算方式,其中第三种是博主自己想的,结果是一样的(最终思路相同,仅供参考)
方式一:
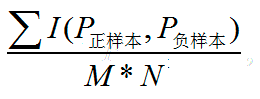
方式二:
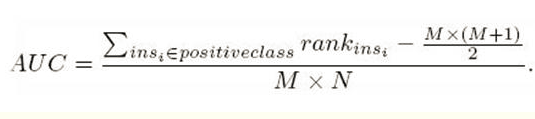
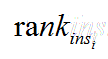
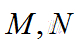
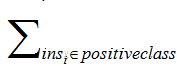
对于这个公式做如下解释和手推,如有不对请批评指正:

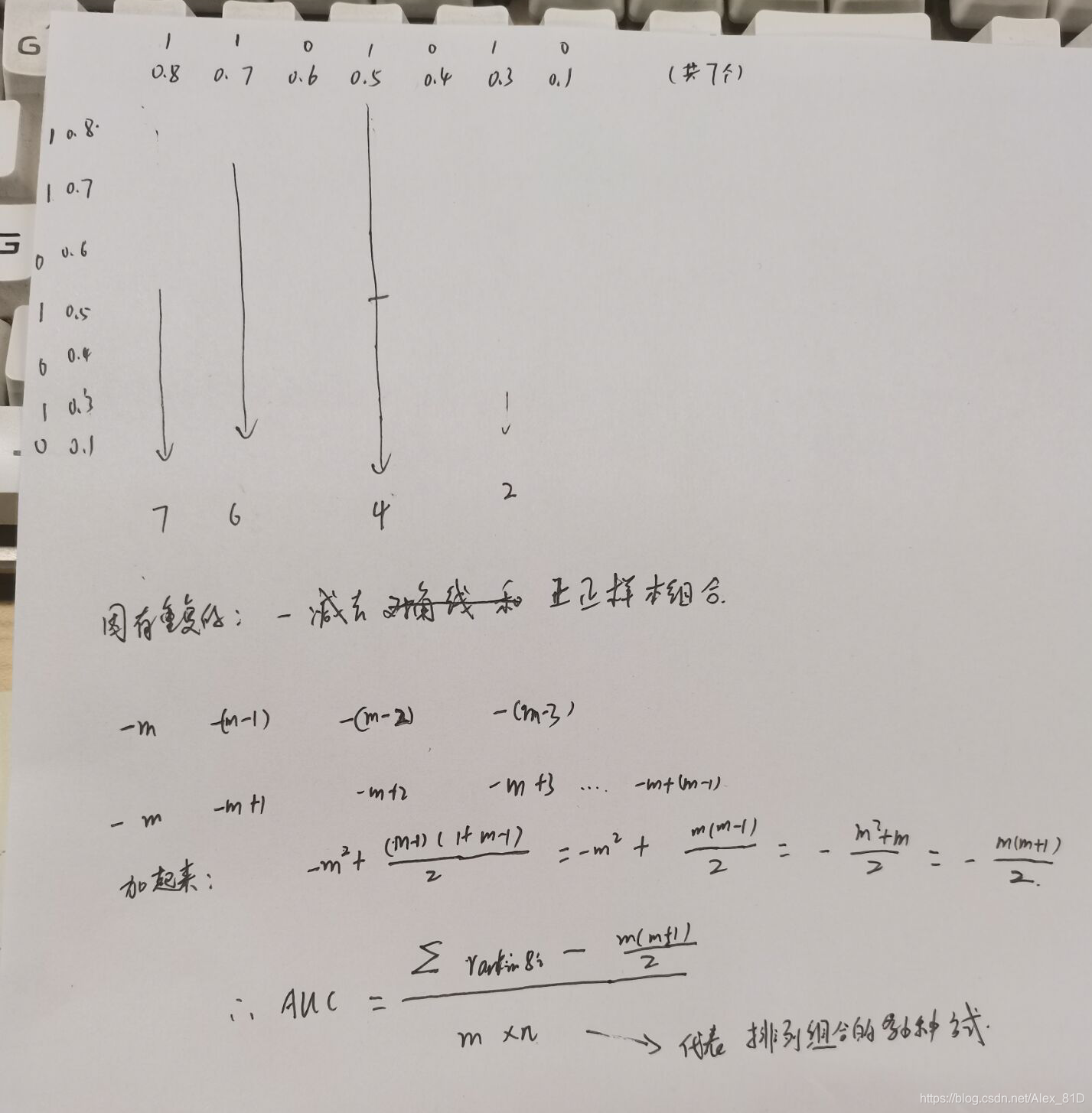
代码献上:
- #第一种方式计算AUC的方式,直接用
- import numpy as np
- from sklearn.metrics import roc_auc_score
-
-
- y_true = np.array([1,1,0,0,1,1,0])
- y_scores = np.array([0.8,0.7,0.6,0.4,0.5,0.3,0.1])
-
- print("y_true is ",y_true)
- print("y_scores is ",y_scores)
- print("auc is ",roc_auc_score(y_true,y_scores))
-
- #第二种方式计算AUC的方式
-
- label_all = y_true.reshape((-1,1))
- pred_all = y_scores.reshape((-1,1))
- posNum = len(list(filter(lambda s :s[0] == 1,label_all)))
- if(posNum>0):
- #负样本数量
- negNum = len(label_all) - posNum
- #对preall进行排序 [0.8,0.7,0.6,0.4,0.5,0.3,0.1]
- sortedq = sorted(enumerate(pred_all),key=lambda x:x[1])
- print(sortedq)
- posRankSum = 0
- #遍历预测序列
- for j in range(len(pred_all)):
- if(label_all[j][0] == 1):
- #print("+++++++++++",list(map(lambda x:x[0],sortedq)).index(j)+1)
- posRankSum += list(map(lambda x:x[0],sortedq)).index(j)+1
- #print("posRankSum------------",posRankSum)
- auc = (posRankSum-posNum*(posNum+1)/2)/(posNum*negNum)
- print(auc)
-
- #第三种方式,这种思路其实很简单,就是算正样本在负样本前面的个数
- concatAB = np.stack((y_true,y_scores),1).reshape(-1,2)
- sortAB = sorted(concatAB,key=lambda x:x[1],reverse=True)
- posNum2 = len(list(filter(lambda s :s[0] == 1,label_all)))
-
- if posNum>0:
- # 负样本数量
- negNum2 = len(y_true) - posNum2
- sum = 0
- for i in range(len(sortAB)):
- if (sortAB[i][0] == 1):
- for j in range(i+1, len(sortAB)):
- if (sortAB[j][0] == 0):
- sum +=1
- print(sum)
- auc = sum/(posNum2*negNum2)
- print("auc-zl:",auc)
多分类f1分数_一文看懂分类模型的评估指标:准确率、精准率、召回率、F1等..._遇见高中生的博客-CSDN博客
瞎聊机器学习——多分类的精确率和召回率_二哥不像程序员的博客-CSDN博客_多分类问题的召回率
下次有机会再写回归模型的指标

