
热门标签
热门文章
- 15分钟JavaScript快速入门
- 2C语言实现TCP服务器与客户端通信_c语言设计程序,要求当客户端连接到服务器一端时,服务器会显示连接的提示信息,并反
- 3417. 太平洋大西洋水流问题
- 4【Python】如何通过官网下载和安装Python&PyCharm(Windows系统)_python官网怎么下载pycharm
- 5从零开始的React之旅:React 18和函数式组件入门_安装react 18
- 6从专业到大众:Sora如何颠覆传统视频制作模式
- 7Python yield 使用浅析
- 8Computer Vision Conference
- 9临时和永久关闭 Selinux和防火墙_rocky 关闭防火墙
- 10技术动态 | 知识图谱遇上RAG行业问答:回顾知识检索增强范式、挑战及与知识图谱的结合...
当前位置: article > 正文
【AIGC】Baichuan2-13B-Chat模型微调_baichuan2-13b-chat-4bits微调
作者:盐析白兔 | 2024-02-28 04:00:03
赞
踩
baichuan2-13b-chat-4bits微调
环境
微调框架:LLaMA-Efficient-Tuning
训练机器:4*RTX3090TI (24G显存)
python环境:python3.8, 安装requirements.txt依赖包
一、Lora微调
1、准备数据集
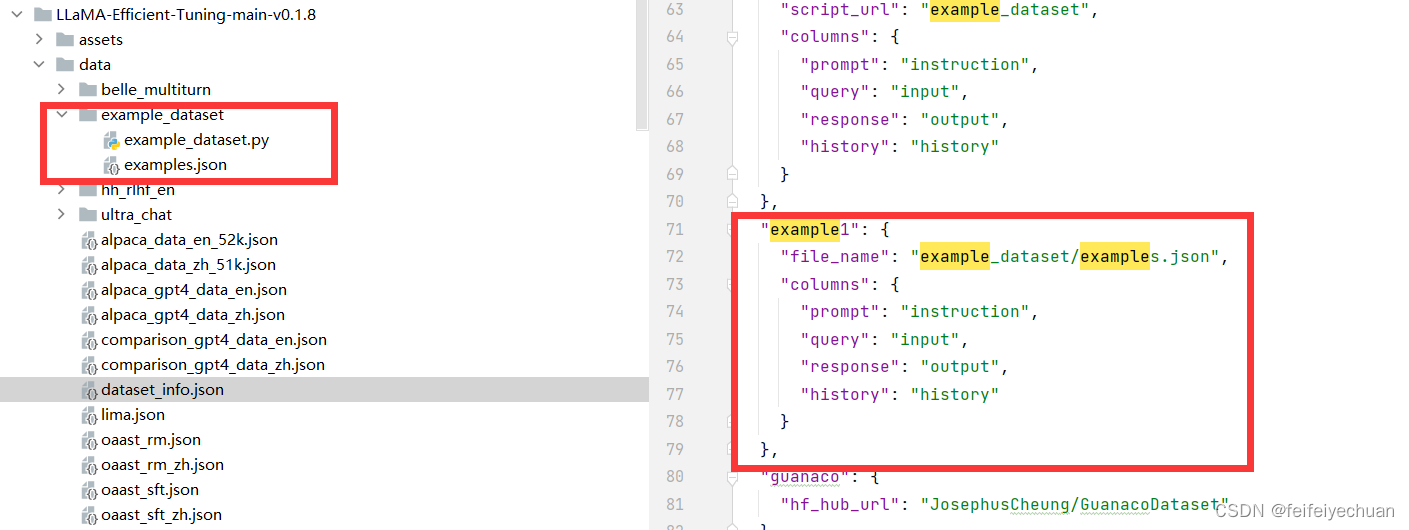
2、训练及测试
1)创建模型输出目录
mkdir -p models/baichuan2_13b_chat/train_models/baichuan2_13b_chat_multi_gpus_03_epoch100/train_model
- 1
2)创建deepspeed配置文件目录
mkdir -p models/baichuan2_13b_chat/deepspeed_config
- 1
3)创建deepspeed配置文件
vi models/baichuan2_13b_chat/deepspeed_config/ds_config_baichuan2_13b_chat_multi_gpus_03_epoch100.json
- 1
{ "bf16": { "enabled": true }, "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "scheduler": { "type": "WarmupDecayLR", "params": { "last_batch_iteration": -1, "total_num_steps": "auto", "warmup_min_lr": "auto", "warmup_max_lr": "auto", "warmup_num_steps": "auto" } }, "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 2e9, "stage3_max_reuse_distance": 2e9, "stage3_gather_16bit_weights_on_model_save": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
4)训练模型
deepspeed --num_nodes 1 --num_gpus 4 --master_port=9901 src/train_bash.py \ --stage sft \ --model_name_or_path baichuan-inc/Baichuan2-13B-Chat \ --do_train \ --dataset example1 \ --template baichuan2 \ --finetuning_type lora \ --lora_rank 16 \ --lora_target W_pack,o_proj,gate_proj,down_proj,up_proj \ --output_dir models/baichuan2_13b_chat/train_models/baichuan2_13b_chat_multi_gpus_03_epoch100/train_model \ --overwrite_cache \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 4 \ --preprocessing_num_workers 4 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 100 \ --learning_rate 5e-3 \ --max_grad_norm 0.5 \ --num_train_epochs 300.0 \ --evaluation_strategy steps \ --plot_loss \ --bf16 \ --deepspeed models/baichuan2_13b_chat/deepspeed_config/ds_config_baichuan2_13b_chat_multi_gpus_03_epoch100.json
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
[INFO|trainer.py:1686] 2023-09-19 04:07:47,607 >> ***** Running training *****
[INFO|trainer.py:1687] 2023-09-19 04:07:47,607 >> Num examples = 94
[INFO|trainer.py:1688] 2023-09-19 04:07:47,608 >> Num Epochs = 300
[INFO|trainer.py:1689] 2023-09-19 04:07:47,608 >> Instantaneous batch size per device = 4
[INFO|trainer.py:1692] 2023-09-19 04:07:47,608 >> Total train batch size (w. parallel, distributed & accumulation) = 64
[INFO|trainer.py:1693] 2023-09-19 04:07:47,608 >> Gradient Accumulation steps = 4
[INFO|trainer.py:1694] 2023-09-19 04:07:47,608 >> Total optimization steps = 300
[INFO|trainer.py:1695] 2023-09-19 04:07:47,612 >> Number of trainable parameters = 55,787,520
{'loss': 7.7023, 'learning_rate': 0.00488255033557047, 'epoch': 6.67}
{'loss': 7.0675, 'learning_rate': 0.004714765100671141, 'epoch': 13.33}
8%|█████████▊ | 25/300 [17:10<3:07:01, 40.81s/it]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 测试模型
python src/cli_demo.py \
--model_name_or_path baichuan-inc/Baichuan2-13B-Chat \
--template baichuan2 \
--finetuning_type lora \
--checkpoint_dir models/baichuan2_13b_chat/train_models/baichuan2_13b_chat_multi_gpus_03_epoch100/train_model
- 1
- 2
- 3
- 4
- 5
3、注意事项:
1)我用的是3090TI显卡,使用fp16精度时,训练结果始终没有效果,而且训练到后面有(loss为0)的问题。这个不清楚时什么原因。所以需要采用bf16,deepspeed配置文件中要将bf16配置为true。训练时添加参数–bf16 。
所以如果显卡不是 3090TI ,可以尝试用 --fp16。
Refer:
- 使用baichuan2-13B进行微调时出现loss全为0的情况
- Deepspeed zero3对Baichuan系的13b-chat进行微调,微调效果失效(Baichuan-13b-chat和Baichuan2-13b-chat都尝试过)
2)deepspeed中 stage 需要选择 3 。尝试过 2 ,内存会溢出。
3) 报错:AttributeError: 'Parameter' object has no attribute 'ds_status' ; 解决办法:关闭验证集,比如 --val_size 0.01, --load_best_model_at_end
Refer:
- 此次训练,loss还没降下去,测试效果不太理想。但是知识库微调成功,只是表达凌乱。所以建议如果知识库不大的话,尽量用单卡训练,效果更好。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/157585
推荐阅读
相关标签

