
- 1大数据平台CDH的介绍和5.16/6.3版本的搭建_cdh版本
- 2Docker 具名匿名挂载——Dockerfile创建数据卷——容器间数据共享_dockerfile volume 具名
- 3STM32实验环境搭建——基于NB-IoT实验_nb-lot云平台stm32
- 4day12_SpringCloud(Gateway,Nacos配置中心,Sentinel组件)
- 5图像质量评估算法-SAD SSD MAD MSD SSIM MS-SSIM的学习_去均值平均绝对差值 mad
- 6计算机毕业设计题目大全毕设课题
- 7阿里云服务器安全组宝塔端口8888开放教程_防火墙安全组放行8888端口
- 8在Mac电脑中忘记管理员密码了如何处理?如何安全的管理自己的密码?_mcsmanager忘记密码
- 9【愚公系列】2023年02月 .NET/C#知识点-区块链概念和实现_.net 区块链
- 10能上QQ但不能浏览网页的解决方法
通过增强PDF结构识别,革新检索增强生成技术(RAG)
赞
踩

写在前面:我们已在 arXiv 上发布了本篇文章的英文版本,如需阅读英文版,请点击此处的「阅读原文」跳转阅读。
/ 摘要 /
尽管大语言模型(LLM)在自然语言生成方面取得了巨大的进展,但对于专业知识问答领域来说,结合检索增强生成技术(RAG)可以更好地利用领域专家知识、提供解释性的优势,提高问答准确率。
目前,主流的基础模型公司已经开放了嵌入向量(Embedding)和聊天 API 接口,LangChain 等框架也已经集成了 RAG 流程,似乎 RAG 中的关键模型和步骤都已经得到解决。这就引出一个问题:目前专业知识的问答系统是否已经趋于完善?
本文指出当前的主要方法都是以获取高质量文本语料为前提的。然而,因为大部分的专业文档都是以 PDF 格式存储,低精度的 PDF 解析会显著影响专业知识问答的效果。
我们对来自真实场景的专业文档,其中的数百个问题进行了实证 RAG 实验。结果显示,配备了全景和精准 PDF 解析器的 RAG 系统的 ChatDOC(海外官网:chatdoc.com)可以检索到更准确和完整的文本段,因此能够给出更好的回答。
实验证明,ChatDOC 在近 47%的问题上表现优于 Baseline 模型,在 38%的问题上与 Baseline 模型表现持平,仅在 15%的问题上表现落后于 Baseline 模型。这表明,我们可以通过增强 PDF 结构识别来革新检索增强生成技术(RAG)。
1
引言
大语言模型的训练数据主要来源于公开互联网资源,包括网页、书籍、新闻和对话文本。这意味着大语言模型主要依赖互联网资源作为它们的训练数据,这些资源量级大、种类繁多且易于访问,支持大语言模型扩展其性能。
然而,在垂直领域应用中,专业任务需要大语言模型利用领域知识(Domain knowledge)。遗憾的是,这些知识是私有数据,并不属于它们预训练数据中的一部分。
为大语言模型配备领域知识的一种流行方法是检索增强生成(Retrieval-Augmented Generation,以下简称 RAG)。
RAG 框架回答一个问题需要四个步骤:用户提出问询;系统从私有知识库中检索相关内容;将相关内容与用户查询合并为上下文;最后请求大语言模型生成答案。
图 1 通过一个简单示例说明了这个过程。该过程反映了遇到问题时的典型认知过程,包括查阅相关参考资料,然后推导出答案。在这个框架中,关键部分是要准确地检索相关信息,这对 RAG 模型的效力至关重要。

图 1 检索增强生成(RAG)的工作流
然而,检索 PDF 文档的过程充满挑战,经常会出现文本提取的不准确和 PDF 文档内表格的行列关系混乱等问题。
因此,在 RAG 之前,我们需要将大型文档转换为可检索内容。转换涉及以下几个步骤,如图 2 所示:
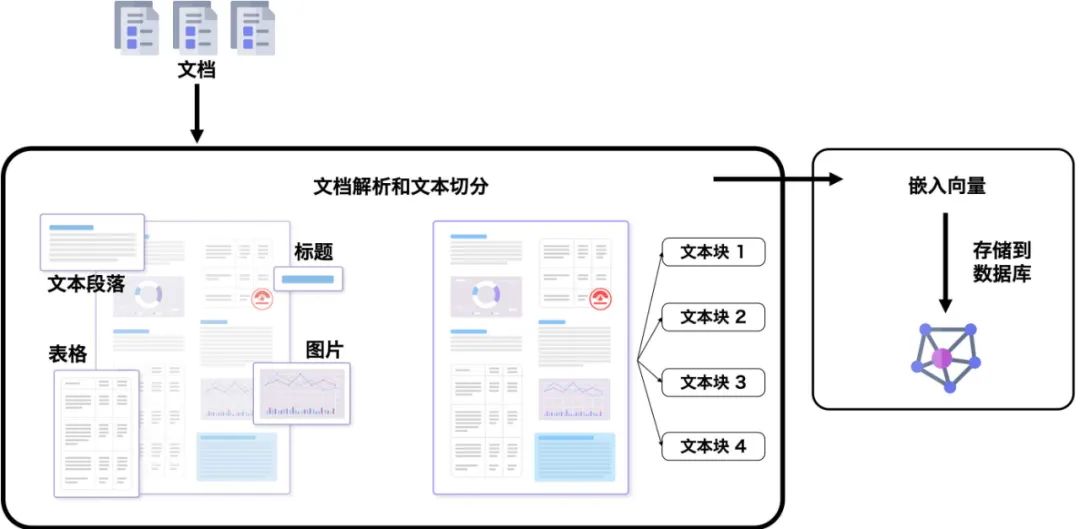
图 2 将 PDF 文档转换为可检索内容的过程
-
文档解析和文本切分(Document parsing & chunking)。这一步涉及到提取段落、表格和其他内容块,然后将提取的内容分块以进行后续检索。
-
嵌入向量(Embedding)生成。这一步将文本块转换为实值向量并存储在数据库中。
由于这些步骤中的每一步都可能导致信息损失,因此复合损失会显著影响 RAG 响应的效果。
本文主要讨论文档解析和文本切分质量是否会影响 RAG 系统的效果。我们将探讨与此问题相关的挑战、方法和实际案例。讨论将包括对该领域两种类型方法的考察,即基于规则(Rule-based)的方法和基于深度学习(Deep learning-based)的方法,然后通过实际案例对它们的效果进行实证评估。
2
PDF 解析和分块
2.1
难点和解决方法
对于人类来说,浏览任何文档页面的认知过程都是相似的。当我们阅读一个页面时,我们的视网膜会捕捉到字符。接着在我们的大脑中,这些字符被组织成段落、表格和图表,然后被理解或记忆。但计算机是以二进制码感知信息,所从计算机的角度看,文档可以分为两类,如图 3 所示:

图 3 计算机视角下的两种类型的文档
-
有标记文档(Tagged Documents):例如 Microsoft Word 和 HTML 文档,它们包含像<p>和<table>这样的特殊标记,用来将文本组织成段落、单元格和表格。
-
无标记文档(Untagged Documents):例如 PDF 文档,它存储了每个文档页面上字符、线条和其他内容元素放置位置的指令。
PDF 文档以人类可读的方式“绘制”这些基本内容元素,但它并没有存储文档的任何结构信息,如表格或段落。因此,无标记文档仅供人类阅读,但机器无法读取。当尝试将 PDF 表格复制到 Word 中时,这一点会很明显,因为在 Word 中原表格的结构通常会完全丢失。
然而,大语言模型擅长处理序列化的文本。因此,为了使大语言模型能够有效处理无标记文档,需要一个解析器将散乱的字符组织成具有其结构的连贯文本。理想情况下,PDF 解析器应具备以下关键特征:
-
文档结构识别:能够灵活地将页面划分为不同类型的内容块,如段落、表格和图表。这确保了划分的文本块是完整和独立的语义单元。
-
在复杂文档布局中保持鲁棒性(Robustness):即使是在文档页面布局复杂的情况下也能保证解析效果,如多列页面、无边框表格甚至合并单元格的表格。
当前,PDF 解析有两种主要类型的方法:基于规则(Rule-based)的方法和基于深度学习(Deep learning-based)的方法。
-
其中,PyPDF 是一个被普遍采用的基于规则的解析器,是 LangChain 中 PDF 解析的标准方法。
-
相反,我们的方法 ChatDOC PDF 解析器(pdflux.com)则基于深度学习模型。接下来,我们将通过介绍这两种方法并引用一些真实案例来说明两者的区别。
2.2
基于规则的方法:PyPDF
我们先介绍基于 PyPDF 的解析和分块工作流程。
首先,PyPDF 将 PDF 文档中的字符序列化为一个没有文档结构信息的长序列。然后,PyPDF 使用一些分割规则对该序列进行分割,如 LangChain 中的“RecursiveCharacterTextSplitter”函数。具体来说,该函数根据预定义的分隔符列表分割文档,如换行符“\n”。在此初始分割之后,仅当组合块的长度不超过预定限制 N 个字符时,才会合并相邻块。
以下内容中,在没有上下文歧义的情况下,我们使用“PyPDF”来指代使用 PyPDF + RecursiveCharacterTextSplitter 进行文档解析和分块的方法。下面将分块的最大长度设置为 300 个词元(Token)。
我们通过一个案例来观察 PyPDF 的固有特征。
如图 4 所示,案例 1 的文档页面中的表格与双列文本混合布局,两者的边界难以区分。表格中间的行没有水平线,因此表格中的行很难被识别。段落既有单列布局(表下的注释),也有双列布局(页面下部的段落)。

图 4 案例一中 PyPDF 的解析和分块结果(原文档:[4])。放大查看细节。
PyPDF 的解析和分块结果如图 4 所示。在“3 分块结果可视化”部分,我们可以看到 PyPDF 正确识别了页面的单列和双列布局部分。但是 PyPDF 存在以下三个缺点:
1. PyPDF 无法识别段落和表格的边界。
它错误地将表格分割成两部分,并将第二部分与后续段落合并为一个分块。
PyPDF 似乎擅于检测段落的边界,因为它不会将一个段落分割成多个分块。但实际上它并没有解析段落的边界。在“2 分块结果”部分我们可以看到,页面中的每个可视文本行在结果中都被解析为以“\n”结尾的一行,并且段落末尾没有特殊格式。
PyPDF 能够正确地划分段落,是因为我们使用了一个特殊的分隔符“.\n”,它会将一个以句点结尾的行视为可能是段落的结束。然而,这种启发式方法(Heuristic)在许多情况下可能不成立。
2. PyPDF 无法识别表格内的结构。
在“2 分块结果”部分,在分块 1 中,表格的上半部分表示为一系列短语,其中一个单元格可能被拆分成多行(例如单元格“China commerce(1)”),一些相邻的单元格可能被排列在一行中(例如第二行中的第三到第五个单元格,”services(1) Cainiao Cloud”)。
所以,表格的结构被完全破坏。如果此分块被检索用于 RAG,大语言模型无法从中辨别到任何有意义的信息。分块 2 的情况也是类似的。此外,表格的表头只存在于分块 1 中,因此分块 2 中的表格下半部分变得没有意义。
3. PyPDF 无法识别内容的阅读顺序。
分块 5 的最后一行“Management Discussion and Analysis”实际位于页面顶部,但在结果中被解析为最后一句。这是因为 PyPDF 按照字符的存储顺序解析文档,而非它们的阅读顺序。当面对复杂布局时,这可能导致解析结果混乱。
另一个案例 2 为复杂的跨页表格,其解析结果如附录中的图 15 所示。
2.3
基于深度学习的方法:ChatDOC PDF 解析器
接下来,我们转向基于深度学习的解析方法,以我们的 ChatDOC PDF 解析器为例。ChatDOC PDF 解析器(pdflux.com)在超过一千万份文档页面的语料库上进行了训练。按照引用[2]中的方法,它包含了一系列复杂的步骤:
OCR 进行文字定位和识别;
物理文档对象检测;
跨列和跨页调整;
阅读顺序确定;
表格结构识别;
文档逻辑结构识别。
读者可以参考引用[2]了解这些步骤的细节。解析后,我们用段落和表格作为基本块,然后合并相邻块,直到达到词元(Token)限制以形成一个分块。
ChatDOC PDF 解析器旨在始终以 JSON 或 HTML 格式提供解析结果,即使对于有挑战性的 PDF 文档也是如此。
它将文档解析为内容块,其中每个分块指代一个表格、段落、图表或其他类型的内容元素。对于表格,它会输出每个表格单元格中的文本,并告知哪些单元格被合并成一个新的单元格。此外,对于具有分级标题的文档,它会输出文档的分层结构。
总之,解析后的结果就像一个结构清晰的 Word 文件。图 5 展示了一个扫描复印页面及其解析结果。左侧展示了文档及识别的内容块(不同内容块用不同颜色的矩形表示)。右侧展示了 JSON 或 HTML 格式的解析结果。读者可以参考引用[3]查看这个解析结果的在线演示。

图 5 ChatDOC PDF 解析器的解析结果。放大查看细节。
然后,我们查看了 ChatDOC PDF 解析器在案例 1 中的结果,如图 6 所示。它成功解决了 PyPDF 的三个缺点。

图 6 案例一中 ChatDOC 的解析和分块结果(原文档:[4])。放大查看细节。
1. 如“3 分块结果可视化”部分所示,ChatDOC PDF 解析器识别了混合布局,并正确地将整个表格设置为一个单独的分块。
对于段落,如“2 分块结果”部分中的分块 2 所示,同一段落中的文本行会被合并到一起,使其更易于理解。
2. 在“2 分块结果”部分的分块 1 中,我们可以看到表格以 Markdown 格式表示,保留了表格的内部结构。
此外,ChatDOC PDF 解析器可以识别表格内的合并单元格。由于 Markdown 格式不能表示合并单元格,我们在 Markdown 格式中将合并单元格中的全部文本放入每个原始单元格中。如图所示,在分块 1 中,文本“Year ended March 31, 2021”重复了 9 次,表示该合并单元格合并了 9 个原始单元格。
3. 此外,“Management Discussion and Analysis”和“112 Alibaba Group Holding Limited”被识别为页眉和页脚,它们被分别放置在解析结果的顶部和底部,与阅读顺序一致。
另一个案例 2 为复杂的跨页表格,其解析结果如附录中的图 16 所示。
3
PDF 识别对 RAG 影响的实验研究
回到本文的主题,文档的解析和分块方式是否会影响 RAG 系统的回答质量?为了回答这个问题,我们进行了一个系统的实验来评估影响。
3.1
RAG 回答质量的定量评估
3.1.1 设置
我们比较了两个 RAG 系统,如表 1 所示:

表 1 ChatDOC 和 Baseline 模型的各步骤设置
ChatDOC:使用 ChatDOC PDF 解析器解析文档,利用结构信息进行分块。
Baseline 模型:使用 PyPDF 解析文档,利用 RecursiveCharacterTextSplitter 函数进行分块。
除了文档解析和分块之外,其它组件如嵌入向量(Embedding)、检索和问答都是相同的。
3.1.2 数据准备
我们为实验收集了一个非常接近真实环境的数据集,它包含来自各个领域的 188 份文档。具体而言,该数据集包括 100 篇学术论文、28 份财务报告和 60 份其他类别的文档,如教科书、课件和立法材料。
然后,我们通过众包收集了 800 个手动生成的问题。经过仔细筛选后,我们删除了低质量的问题,得到了 302 个可用于评估的问题。这些问题分为两类(如表 2 所示):
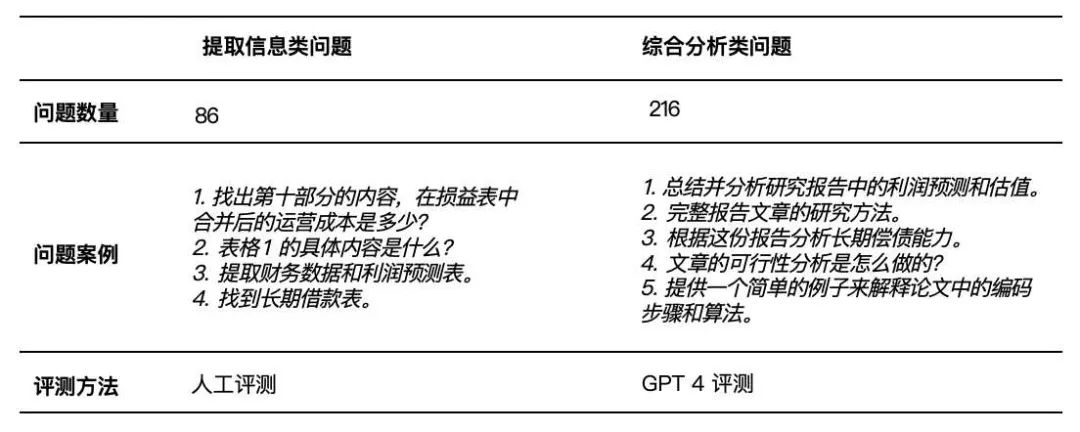
表 2 数据集中的问题被分类为提取信息类和综合分析类,采用不同的评测方法。
-
提取信息类问题(Extractive questions)是指可以直接从文档摘录回答的问题。
由于这类问题需要特定的信息,因此通常需要精确的答案。我们发现,在使用大语言模型进行评估时,它可能无法区分答案之间微妙但重要的差异,因此我们采取人工评估。
我们使用 0-10 的量表对结果进行评级。评估人员会同时看到两种方法检索的内容和答案,并同时对两种方法进行评级。我们给出了检索到的内容,因为通常无法在没有文档内容的情况下评估答案,并同时展示了两种方法以便详细对比,特别是在部分正确的结果上。
-
综合分析类问题(Comprehensive analysis questions)需要从多个源头和方面综合信息,并进行总结。
由于答案冗长且需要全面理解给定的文档内容,我们发现人工评估困难且耗时。因此,我们使用 GPT-4 对答案质量进行评估,在同一请求中对两种方法的结果进行评级,从 1-10 进行打分。
但我们只给出检索的内容,不给出答案,因为与提取信息类问题相比,综合分析类问题的答案较长(因此成本较高),并且更好的检索内容就意味着更好的答案(因为使用的大语言模型是相同的)。
一对要比较的结果需要进行 4 次打分以避免偏差[5],然后取其平均值。具体而言,对于同一问题的一对要进行比较的内容(A,B),我们将A和B同时输入给 GPT-4 进行两次比较和评分。我们还将颠倒它们的顺序,将B和A输入给 GPT-4 请求比较和评分,并同样重复两次。
3.1.3 结果
提取信息类问题的结果
提取信息类问题的结果如表 3 所示。在 86 个提取信息类问题中,ChatDOC 在 42 个案例中表现优于 Baseline 模型,有 36 例与 Baseline 模型表现持平,仅有 8 例表现不如 Baseline 模型。

表 3 ChatDOC 和 Baseline 模型的比较结果
评分的分布情况详见图 7。在分布表中,
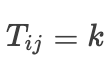
表示有k个问题,其中 ChatDOC 的答案评分为i,Baseline 模型的答案评分为j。ChatDOC 得分高于 Baseline 模型(ChatDOC 胜出)的情况表示在左下角,而 Baseline 模型得分较高的情况表示在右上角。
值得注意的是,大多数有明确胜负结果的样本位于左下角部分,这表明了 ChatDOC 的优势。令人印象深刻的是,ChatDOC 在近一半的案例中获得满分(10 分),总计 40 个。
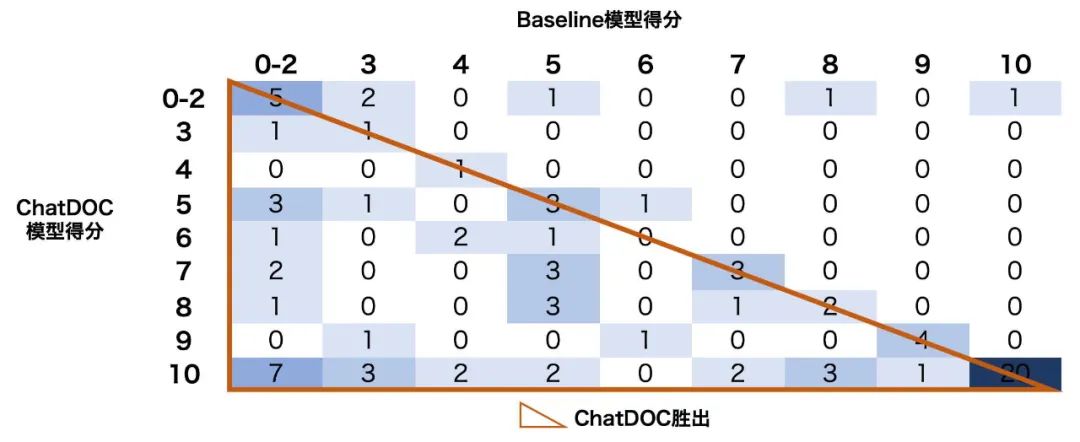
图 7 提取信息类问题的评分分数分布表
综合分析类问题的结果
综合分析类问题的结果如表 3 所示。在 216 个综合分析类问题中,ChatDOC 在 101 个案例中表现优于 Baseline 模型,有 79 例与 Baseline 模型表现持平,仅有 36 例表现不如 Baseline 模型。
如图 8,这些问题的分数分布表显示,左下角的分数集中程度更高。这表明 ChatDOC 的表现经常优于 Baseline 模型。
值得注意的是,ChatDOC 的大多数检索结果得分在 8.5 到 9.5 之间,表明其检索质量很高。

图 8 综合分析类问题的评分分数分布表
总之,ChatDOC 的表现明显优于 Baseline 模型,而这主要归功于其卓越的 PDF 解析方法。
3.2
RAG 案例研究
为了使对比更加具体,我们列举了一些 ChatDOC 展现其优势的案例。
用户手册中的具体信3.2.1 案例 A——查询特斯拉息
案例 A 涉及特斯拉用户手册的查询,具体查询的是有关货物体积的信息。
对于这个查询,ChatDOC 和 Baseline 模型的表现分别如图 9 和图 10 所示。
这两张图展示了检索到的最相关的分块和大语言模型的答案,还展示了包含相关分块的文档页面,并高亮显示这些分块。
在这个案例中,两个模型都定位到了表格,但他们提供给大语言模型的文本不同,因此答案也不同。具体而言:
-
ChatDOC 识别到表格结构,以 Markdown 格式解释文本(如“检索到的文本块”部分所示),这使语言模型更容易理解。
-
Baseline 模型错误地将目标表格和上面的表格合并为一个分块,且没有表格结构。因此,分块中的文本不可被理解(如“检索到的文本块”部分所示),大语言模型只能回答“没有明确提到”。

图 9 ChatDOC 模型在特斯拉用户手册中查找信息的结果(原始文档:[6])

图 10 Baseline 模型在特斯拉用户手册中查找信息的结果(原始文档:[6])
此案例突出了 ChatDOC 解析方法的有效性,特别是在处理表格和以易于大语言模型理解的方式呈现表格方面。
3.2.2 案例 B——研究论文
案例 B 中,用户要查询的是一篇特定的研究论文。该查询要求系统识别论文中的“表格 8”,并列举它所列出的所有因变量。表格的标题和内容对于识别这些变量都是必需的。
图 11 和图 12 显示了 ChatDOC 和 Baseline 模型在该案例中的表现。

图 11 ChatDOC 模型在研究论文中定位特定表格的结果(原始文档:[7])

图 12 Baseline 模型在研究论文中定位特定表格的结果(原始文档:[7])
-
ChatDOC 有效地检索了整个表格,包括其标题和内容。这种全面的检索使其能够准确地响应查询。
-
Baseline 模型没有检索到真正的“表格 8”,而只检索到“表格 7”下面的文本块(因为它包含“表格 8”的文本)。
由于 Baseline 模型的分割策略,“表格 8”的内容和同一页面上的其他内容被合并为一个大的分块。这个分块中混合了不相关的内容,与查询的相关性系数较低,因此不会出现在检索结果中。
这个案例突出了 ChatDOC 处理复杂文档结构的卓越能力,以及它在检索特定片段以获得准确响应方面的作用。
3.3
关于局限性的讨论
虽然 ChatDOC 的表现总体很好,但在某些案例下其检索质量不如 Baseline 模型。我们观察到这些案例有两种模式。
-
排序(Ranking)和词元(Token)限制问题。如果 ChatDOC 首先检索到一个大但不相关的表格,它会耗尽上下文窗口,从而无法访问相关的信息,如图 13 的示例所示。
这主要是因为嵌入向量模型(Embedding model)没有将相关的分块排在最上面。这可能需要通过一个更好的嵌入向量模型来解决,或者是一种更精细的处理大表格/段落的方法,比如只保留表格的相关部分给大语言模型。

图 13 ChatDOC 模型遇到排序和词元限制问题的例子
-
精细分段(Fine Segmentation)的缺点。图 14 展示的案例需要检索带标题的整个表格。然而,ChatDOC 错误地将标题识别为普通段落,因此标题和表格被存储在不同的分块中。
这导致只检索到所需信息的一部分,即表格的标题和脚注,但没有表格中的关键内容。改进表格标题识别可以解决这些问题。

图 14 ChatDOC 模型检索相关表失败的例子(原文档:[8])
4
在 ChatDOC 上的应用
我们将增强的 PDF 结构识别框架(pdflux.com)应用于 ChatDOC(海外官网:chatdoc.com)。ChatDOC 是一个 AI 文档阅读助手,可以在数秒内总结长文档、解释复杂概念和查找关键信息。
在可靠性和准确性方面,它是所有 ChatPDF 类的产品之首。
和同类型产品相比,ChatDOC 的优势主要体现在:
精通表格理解:只需选择任何表格或文本,即可立即深入获取其详细信息。
多文档对话:同时与多个文档对话,且不用担心每个文档的页数限制。
每个回答均可溯源至原文:所有答案都有来自原文档中的直接引用支持。
支持多种文档类型:可以丝滑处理扫描件、ePub、HTML 和 docx 格式文档。
5
结论
一些初步实验表明,一些开源的 PDF 解析方法可能无法达到高质量 RAG 的要求。
通过上述分析,我们能够发现:当辅以可以有效提取文档中的结构化信息并将其整合为提示词(Prompt)的 PDF 解析器时,大语言模型能够作出更准确的响应。这个过程提高了提供给模型的数据质量和相关性,从而提高了模型输出的质量。
未来,我们将研究分享更多基于深度学习的文档解析方法,以便更全面地理解 RAG 质量和文档解析质量之间的关系。
参考文献
[1] Alibaba Group Holding Limited. Fiscal year annual report 2023. https://static.alibabagroup.com/reports/fy2023/ar/ebook/en/index.html, 2023.
[2] Rongyu Cao, Hongwei Li, Ganbin Zhou, and Ping Luo. Towards document panoptic segmentation with pinpoint accuracy: Method and evaluation. In 16th International Conference on Document Analysis and Recognition, pages 3–18, 2021.
[3] https://pdflux.com/.
[4] Daisho Microline Holdings Limited. Fiscal year annual report 2022. https://www1.hkexnews.hk/listedco/listconews/sehk/2022/0626/2022062600094.pdf, 2022.
[5] Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators, 2023.
[6] Tesla Inc. Model 3 owner’s manual. https://manual-directory.com/manual/2023-tesla-model-3-owners-manual/, 2023.
[7] Flávio Cunha, Fatih Karahan, and Ilton Soares. Returns to skills and the college premium. Journal of Money, Credit and Banking, 43:39–86, 2011. https://sci-hub.hkvisa.net/https://doi.org/10.1111/j.1538-4616.2011.00410.x.
[8] Tom S. Vogl. Height, skills, and labor market outcomes in mexico. NBER Working Paper Series,2012. https://www.nber.org/system/files/working_papers/w18318/w18318.pdf.
6
附录 关于 PDF 解析和分块的更多案例
如图 15 所示,案例 2 中的表格没有边框且跨越两页。
图 15 展示了 PyPDF 的结果,仔细检查发现,表格仅被表示为文本序列,使其难以解释和理解,且该表格分散在三个分块中。
这两个案例的结果表明,基于规则的方法,如 PyPDF,倾向于不加区分地拆分文档,而没有真正理解其内容结构。因此,表格经常被拆散,段落变得杂乱,从而导致原始文档的脱节和混乱。

图 15 案例二中 PyPDF 的解析和分块结果(原文档:[4])。放大查看细节。
如图 16 所示,ChatDOC PDF 解析器的解析结果明显不同。它不仅保留了文档结构,而且保留了文档内容的原始含义,有效分割了文档。
在这个案例中,跨越两页的表格被设置为一个分块,其标题位于分块的开头。因此,这个分块中的信息是完整的。如果检索这个分块用于 RAG,那么大语言模型是可以从中获得有用信息的。
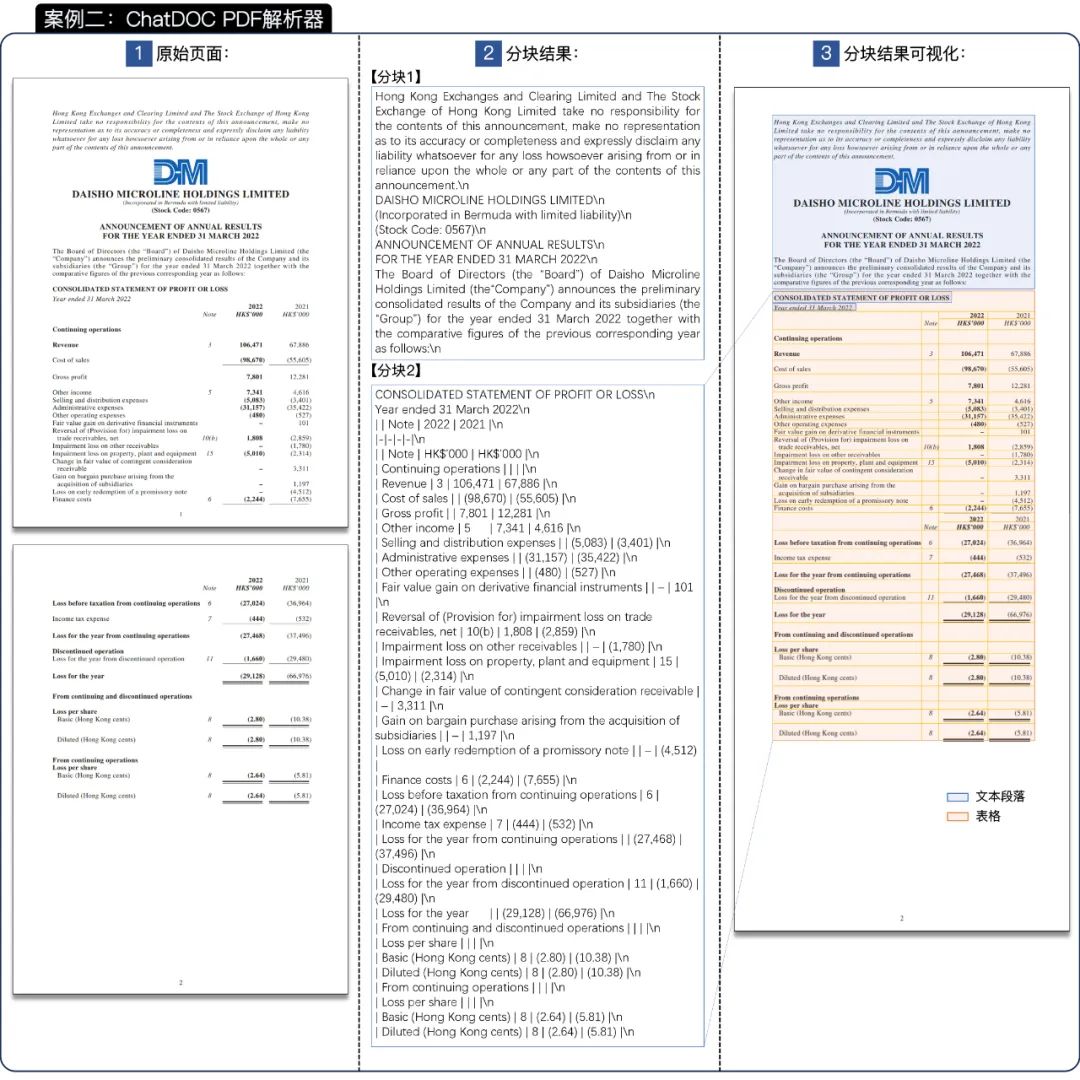
图 16 案例二中 ChatDOC 的解析和分块结果(原文档:[4])。放大查看细节。
如需试用ChatDOC:
请访问 ChatDOC海外官网(chatdoc.com)直接进行注册。
如需ChatDOC企业版本或进一步了解我们的 PDF 解析器,请访问官网直接试用或者联系庖丁科技的解决方案专家:
ChatDOC国内企业版:https://paodingjiewen.com/
PDF解析器:https://pdflux.com/
邮箱:contact@paodingai.com
电话:010-58426539

