
热门标签
热门文章
- 1基于Pytorch做深度学习,但是代码水平很低,应该如何学习呢?
- 2关于fastDFS断点续传的问题
- 3tcp连接 本地端口_最大65535TCP连接是怎么回事
- 4单片机毕设 STM32智能手环_stm32智能手表数据手机同步
- 5解决selenium启动IE浏览器报错:org.openqa.selenium.SessionNotCreatedException: Unexpected error launching Inter...
- 6k8s之PV以及PVC_pvc k8s
- 7【修改yolov5】给yolov5更换主干网络ShuffleNetv2_yolov5更换轻量化主干
- 8多视图点云配准算法综述_点云配准与图形学相关吗
- 9springBoot基础_JPA中的一些关键字(小白篇)_jpa 常用关键字
- 10Python模块:re模块(正则表达式)_python re
当前位置: article > 正文
python爬虫:使用scrapy框架对链家租房深度爬取,并存入redis、mysql、mongodb数据库_链家爬取杭州数据写入mysql数据库
作者:盐析白兔 | 2024-03-06 06:30:56
赞
踩
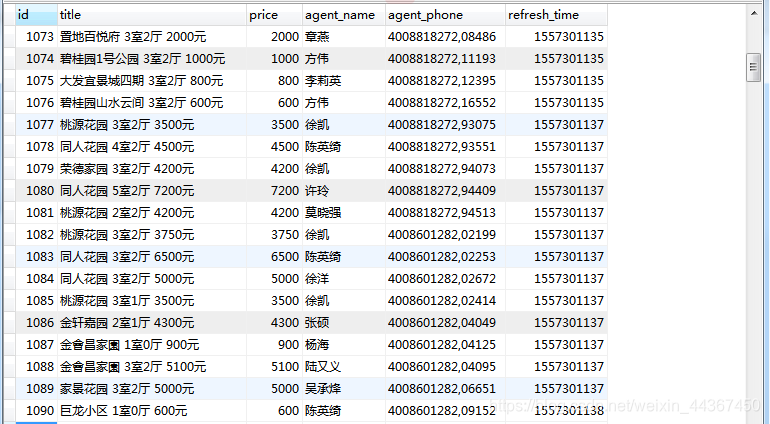
链家爬取杭州数据写入mysql数据库
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class LianjiaItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pic = scrapy.Field() title = scrapy.Field() detail_url = scrapy.Field() price = scrapy.Field() publish_info = scrapy.Field() pic_list = scrapy.Field() house_code = scrapy.Field() ucid = scrapy.Field() agent_name = scrapy.Field() agent_phone = scrapy.Field()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
# -*- coding: utf-8 -*- import scrapy from LianJia.items import LianjiaItem import re import json import requests class LianjiaSpider(scrapy.Spider): name = 'lianjia' allowed_domains = ['lianjia.com'] start_urls = ['https://www.lianjia.com/city/'] def parse(self, response): # 获取到的是新房的url city_url_list = response.xpath("//div[@class='city_province']//li/a/@href").extract() # print(city_url_list) city_name_list = response.xpath("//div[@class='city_province']//li/a/text()").extract() for index in range(len(city_url_list)): city_name = city_name_list[index] city_url = city_url_list[index] # print(city_url) # 城市首字母 city_alp = re.findall(r"https://(\w*).", city_url)[0] # print(city_alp) # 拼接租房城市url city_url = "https://" + city_alp + ".lianjia.com/zufang/" # print("--------------------{}开始下载-------------------------------".format(city_name)) yield scrapy.Request(url=city_url, callback=self.get_area_url) def get_area_url(self, response): # print(response.body.decode("utf-8")) # 获取城区url area_url_list = response.xpath("//li[@data-type='district'][position()>1]/a/@href").extract() for area_url in area_url_list: area_url = re.findall(r"(.*)/zufang/", response.url)[0] + area_url # print(area_url) yield scrapy.Request(url=area_url, callback=self.get_business_url) def get_business_url(self, response): # 获取商圈url business_url_list = response.xpath("//li[@data-type='bizcircle'][position()>1]/a/@href").extract() # print(business_url_list) for business_url in business_url_list: business_url = re.findall(r"(.*)/zufang/", response.url)[0] + business_url # print(business_url) yield scrapy.Request(url=business_url, callback=self.get_page_url) def get_page_url(self, response): # 获取最大页码 max_page = response.xpath("//div[@class='content__pg']/@data-totalpage").extract() max_page = int(max_page[0]) if max_page else 0 # print(max_page) # 遍历最大页 拼接完整的page_url # ---------page=0时 不会执行下面---------- for page in range(max_page): page_url = response.url + "pg{}/#contentList".format(page + 1) # print(page_url) yield scrapy.Request(url=page_url, callback=self.get_page_data) def get_page_data(self, response): # 缩小范围 fang_xml_list = response.xpath("//div[@class='content__list']/div") # print(fang_xml_list) for fang_xml in fang_xml_list: # 获取图片 pic = fang_xml.xpath(".//img/@data-src").extract() pic = pic[0] if pic else '' # print(pic) # 获取标题 title = fang_xml.xpath(".//p[@class='content__list--item--title twoline']/a/text()").extract()[0].strip() # 获取详情url detail_url = fang_xml.xpath(".//p[@class='content__list--item--title twoline']/a/@href").extract()[0] detail_url = "https://bj.lianjia.com" + detail_url # print(title) # 获取价格 price = fang_xml.xpath(".//em/text()").extract()[0] # print(price) item = LianjiaItem() item["pic"] = pic item["title"] = title item["detail_url"] = detail_url item["price"] = price # print(item) yield scrapy.Request(url=detail_url, callback=self.get_detail_data, meta={"data": item}, dont_filter=True) def get_detail_data(self, response): item = response.meta["data"] # 获取发布信息 publish_info = response.xpath("//ul/li[contains(text(), '发布')]/text()").extract() publish_info = publish_info[0] if publish_info else '' # print(publish_info) # 获取图片信息 pic_list = response.xpath("//ul[@class='content__article__slide__wrapper']/div/img/@data-src").extract() # print(pic_list) # 获取房源编号 house_code = re.findall(r"/zufang/(.*?).html", response.url)[0] # print(house_code) # 获取ucid ucid = response.xpath("//span[@class='contact__im im__online']/@data-im_id").extract() # print(ucid) if ucid: ucid = ucid[0] # 拼接完整的经纪人接口 brokers_url = "https://bj.lianjia.com/zufang/aj/house/brokers?" agent_api = brokers_url + "house_codes={}&position=bottom&ucid={}".format(house_code, ucid) # print(agent_api) item["publish_info"] = publish_info item["pic_list"] = pic_list item["house_code"] = house_code item["ucid"] = ucid yield scrapy.Request(url=agent_api, callback=self.get_agent_data, meta={"data": item}, dont_filter=True) # 获取经纪人信息 def get_agent_data(self, response): # 将response对象转成json对象 result = response.body.decode("utf-8") json_data = json.loads(result) # print(json_data) item = response.meta["data"] house_code = item.get("house_code") # 经纪人姓名 agent_name = json_data.get("data").get(house_code).get(house_code).get("contact_name") # print(agent_name) # 经纪人电话 agent_phone = json_data.get("data").get(house_code).get(house_code).get("tp_number") # print(agent_phone) item["agent_name"] = agent_name item["agent_phone"] = agent_phone yield item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo import pymysql import redis import json # class LianjiaPipeline(object): # def __init__(self): # self.count = 1 # # def process_item(self, item, spider): # print(self.count, dict(item)) # self.count += 1 # return item # 插入redis数据库 class RedisPipeline(object): def __init__(self): self.count = 1 self.r = redis.Redis(host="localhost", port="6379", db=3) def process_item(self, item, spider): # print(item) item_dict = dict(item) print(self.count, item_dict) item_str = json.dumps(item_dict) self.r.lpush("lianjia", item_str) # print("insert successfully") self.count += 1 return item # 插入mongodb class MongodbPipeline(object): def __init__(self): mongo_client = pymongo.MongoClient("localhost", 27017) self.db = mongo_client.lianjia def process_item(self, item, spider): item = dict(item) self.db.lianjia.insert(item) return item # 插入mysql class MysqlPipeline(object): def __init__(self): self.conn = pymysql.connect("localhost", "root", "123456", "lianjia") self.cursor = self.conn.cursor() def process_item(self, item, spider): title = item["title"] # print(title) price = item["price"] agent_name = item["agent_name"] agent_phone = item["agent_phone"] import time # 时间戳 数据监控时用 refresh_time = int(time.time()) sql = "insert into fang(title, price, agent_name, agent_phone, refresh_time) values('{}', '{}', '{}', '{}', '{}')"\ .format(title, price, agent_name, agent_phone, refresh_time) try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def __del__(self): self.cursor.close() self.conn.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
4.main.py (项目执行脚本)
from scrapy import cmdline
cmdline.execute("scrapy crawl lianjia --nolog".split())
# cmdline.execute("scrapy crawl lianjia".split())
- 1
- 2
- 3
- 4
- 5
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/196506
推荐阅读
相关标签

