
python学习第18天 csv和excel_import csv, re是什么意思
赞
踩
python 18 csv和excel
1. csv文件读
1.1 什么是csv文件?
csv文件是逗号分割值文件 - 每一行内容是通过逗号来区分不同的列
csv文件可以直接通过Excel打开,以行的形式保存和显示数据,但是,相对Excel文件,它只能存储数据,不能保存公式和函数。
1.2 csv读操作
导入csv — import csv
-
第一步:创建打开csv文件
#方法1 f=open('files/电影.csv','r',encoding='utf-8') #方法2 #带有自动关闭文件的功能 with open('files/电影.csv','r',encoding='utf-8') as f:- 1
- 2
- 3
- 4
-
第二步:创建reader获取文件内容
- 语法1:csv . reader(文件对象) - 获取文件内容返回一个迭代器,并且以列表为单位返回每一行内容
- 语法2:csv . DictReader(文件对象) - 获取文件内容返回一个迭代器,并且以字典为单位返回第2 行开始的每一行内容(字典的键是第一行内容)
f=open('files/电影.csv','r',encoding='utf-8')
reader2=csv.reader(f)
print(list(reader2))
f.close()
reader3=csv.DictReader(f)
print(list(reader3))
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 例题练习
2. csv写操作
数据存储成csv或Excel文件
2.1 打开文件
- 首先要导入 csv — import csv
f=open('files/data.csv','w',encoding='utf-8')
#因为是要进行写操作,选择mode是w or a.
- 1
- 2
2.2 创建writer对象
-
语法1:csv . writer( 文件对象 ) — 创建writer对象,这个对象在写入数据的时候,一行对应一个列表。
-
语法2:csv.Dictwriter ( 文件对象) — 创建writer对象,这个对象在写入数据的时候,一行对应一个字典。
-
案例说明
a . 以列表为单位写csv
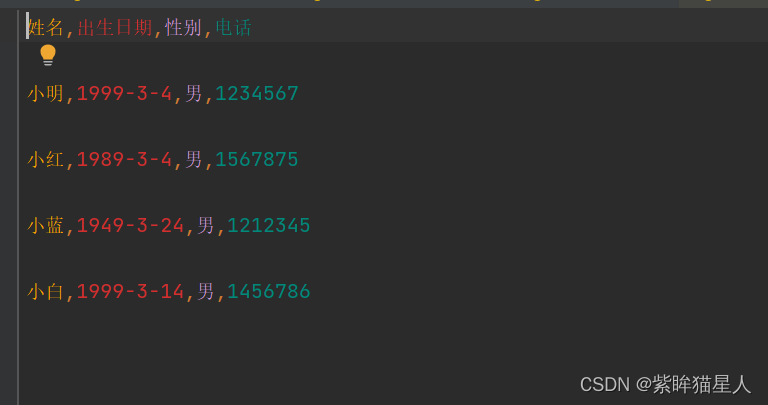
writer.writerow(['姓名','出生日期','性别','电话']) writer.writerow(['小明','1999-9-9','男','12345']) #b.以列表为单位,一次写入多行内容 writer.writerow([ ['姓名','出生日期','性别','电话'], ['小明','1999-9-9','男','12345'], ['小红','2001-9-23','女','65432324'], ['小颖','2003-4-7','女','76543345'] ]) ``` 结果显示 <img src="C:\Users\Lenovo\Pictures\Saved Pictures\0810csv读结果.png" style="zoom: 150%;" />
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
b . 以字典为单位写csv文件
```python
import csv
- 1
- 2
f=open(‘files/data.csv’,‘w’,encoding=‘utf-8’) #打开csv文件
writer=csv.DictWriter(f,[‘姓名’, ‘出生日期’, ‘性别’, ‘电话’]) #创建文件对象
writer.writeheader()
#写一行内容
writer.writerow({‘姓名’:‘小明’,‘出生日期’:‘1999-3-4’,‘性别’:‘男’,‘电话’:1234567})
#写多行内容:注意是以列表的形式,列表的每一个元素是字典
writer.writerows([
{‘姓名’:‘小红’,‘出生日期’:‘1989-3-4’,‘性别’:‘男’,‘电话’:1567875},
{‘姓名’:‘小蓝’,‘出生日期’:‘1949-3-24’,‘性别’:‘男’,‘电话’:1212345},
{‘姓名’:‘小白’,‘出生日期’:‘1999-3-14’,‘性别’:‘男’,‘电话’:1456786}
])
3. 虚拟环境
3.1 系统环境与虚拟环境
3.2 环境的作用
- 提供python解释器
- 提供第三方库(虚拟环境的存在可以让第三方库根据类别或者项目分开管理。)
3.3 使用虚拟环境的建议
- 工作的时候:一个项目一个虚拟环境,并且将虚拟环境直接放在项目中
- 学习的时候:一类项目一个虚拟环境,不同类别的虚拟环境全部放在一个地方
3.4 如何创建虚拟环境
-
方法1:使用pycharm创建
图片展示创建过程

- 方法2:使用指令创建()
4. excel 读操作
4.1 认识Excel文件
导入openpyxl 库 :import openpyxl
-
工作薄:一个excel就是一个一个工作薄
-
工作表:一个工作薄可以有多个工作表(至少一个)
-
单元格:单元格是excel文件保存数据的基本单位
-
行号和列号:可以确定单元格位置
-
要想获取一个单元格,要知道是工作薄的哪一个工作表哪一行哪一列
图片展示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uEw2hjeZ-1660152931500)(C:\Users\Lenovo\Pictures\Saved Pictures\excel认识.png)]
4.2 获取Excel文件的内容
1)打开excel文件创建工作薄对象
两种方法都可以
-
方法1:workbook=openpyxl . open(‘files/三国人物数据.xlsx’)
-
方法2 : workbook=openpyxl . load_workbook(‘files/三国人物数据.xlsx’)
-
获取工作薄中的所有工作表表的表名
workbook=openpyxl . open('files/三国人物数据.xlsx') result=workbook.sheetnames print(result) #['全部人物数据', '三个国家的武力', '三个国家武将的武力', '三国武将数据', '三国文官数据']- 1
- 2
- 3
- 4
2)获取工作表
-
方法1:工作薄对象.active - 获取活跃表(选中的表)
-
方法2: 工作薄对象[工作表名称] - 获取指定名字对应的工作表
sheet1=workbook.active print(sheet1) #<Worksheet "三个国家的武力"> sheet2=workbook['三国武将数据'] print(sheet2) #<Worksheet "三国武将数据">- 1
- 2
- 3
- 4
3)获取单元格
-
语法:工作表对象.cell(行号,列号)
cell1=sheet2.cell(8,1) cell2=sheet2.cell(12,1) print(cell1,cell2)- 1
- 2
- 3
4) 获取单元格内容
-
语法:单元格对象.value
print(cell1.value) #蔡瑁 print(cell2.value) #曹操- 1
- 2
5)获取最大行号和最大列号(保存了数据的有效行和有效列)
-
工作表对象.max_row
-
工作表对象.max_column
print(sheet1.max_column) #3 有效的3列 print(sheet1.max_row) #122 有效的122行- 1
- 2
-
练习
#获取第一列所有数据 column=[] for row in range(1,sheet2.max_row+1): cell=sheet2.cell(row,1) column.append(cell.value) print(column) #获取第一行的所有数据 row=[] for col in range(1,sheet2.max_column+1): cell=sheet2.cell(1,col) row.append(cell.value) print(row) #['姓名', '性别', '统御', '武力', '智力', '政治', '魅力', '寿命', '国家', '身分'] #获取第一列到底三列的内容 for col in range(1,4): column=[] for row in range(1,sheet2.max_row+1): cell=sheet2.cell(row,col) column.append(cell.value) print(column)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5. excel 文件写操作
5.1 新建工作薄对象
不管以什么样的方式对excel进行新建工作薄要在不存在的时候才新建,如果这个工作簿,在新建一个工作簿会覆盖原来的工作簿,工作簿就是空的
1)新建工作薄对象
import openpyxl #导入openpyxl库
workbook = openpyxl.Workbook()
workbook=openpyxl.open('files/student.xlsx') #存在不会报错
workbook=openpyxl.open('files/student1.xlsx') #报错,找不到FileNotFoundError: [Errno 2] No such file or directory: 'files/student1.xlsx'
- 1
- 2
实际中新建工作簿的时候,需要先判断工作簿对应的文件是否存在,存在就不需要新建,不存在再新建。有两种方法。
-
方法1 : 用异常捕获
try: workbook =openpyxl.open('files/student1.xlsx') except FileNotFoundError: workbook = openpyxl.Workbook() #新建 workbook.save('files/student1.xlsx') #保存- 1
- 2
- 3
- 4
- 5
-
方法2 : 使用os库
- 语法:os . path . exists (文件路径) - 判断指定文件是否存在,存在返回True,不存在返回False.
if os.path.exists('files/student2.xlsx'):
workbook = openpyxl.open('files/student2.xlsx')
else:
workbook = openpyxl.Workbook()
workbook.save('files/student2.xlsx')
- 1
- 2
- 3
- 4
- 5
2)保存
-
语法:工作簿对象.save( 文件路径)
workbook.save('files/student.xlsx')- 1
5.2 工作表的写操作
1) 新建工作表
-
方法1 :工作簿对象.create_sheet() #只是新建表
-
方法2 : 工作簿对象.create_sheet(表名) #新建表的时候,给出表名。
-
方法3 : 工作簿对象.create_sheet(表名,下标) #新建工作表,并给出新建表的位置
-
工作表保存:workbook.save(文件保存的路径)
-
备注:创建一个表打开之后,要及时关闭,如果不关,就会报错,没有权限
-
实际中,新建表:没有的时候才新建,有的时候直接打开
#创建工作表 python if 'python' in workbook.sheetnames: sheet=workbook['python'] else: sheet=workbook.create_sheet('python') workbook.save('files/student2.xlsx') # 创建工作表 python if 'java' in workbook.sheetnames: sheet=workbook['java'] else: sheet=workbook.create_sheet('java') workbook.save('files/student2.xlsx')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3)单元格的写操作
-
语法:单元格对象.value=数据 (可以用来处理单元格的增,删,改)
python_sheet=workbook['python'] python_sheet.cell(3,3).value='噢噢噢噢噢噢噢噢' python_sheet.cell(5,6).value='beautiful' python_sheet.cell(2,6).value=None workbook.save('files/student2.xlsx')- 1
- 2
- 3
- 4
- 5
- 6
今日练习:
制作一个工作薄,建工作表保存薪资大于13k的公司名,教育程度,工作年限,薪资.
import openpyxl import os from re import split import csv with open('files/lagou.csv', 'r', encoding='utf-8') as f: rea_result = csv.DictReader(f) rea_res_list=list(rea_result) bj_list=[x for x in rea_res_list if x['city'] == '北京' and split(r'k',x['salary'],1)[0] >= '13'] #找出在北京的薪资高于13k的所有公司的列表 if os.path.exists('files/analysis1.xlsx'): workbook = openpyxl.open('files/analysis1.xlsx') else: workbook = openpyxl.Workbook() workbook.save('files/analysis1.xlsx') #创建好了工作薄 if '薪资职位一览表' in workbook.sheetnames: sheet1 = workbook['薪资职位一览表'] else: sheet1 = workbook.create_sheet('薪资职位一览表') workbook.save('files/analysis1.xlsx') lenth_bj_list = len(bj_list) sheet1.cell(1, 1).value = '公司名称' sheet1.cell(1, 2).value = '学历' sheet1.cell(1, 3).value = '工作年限' sheet1.cell(1, 4).value = '薪资范围' workbook.save('files/analysis.xlsx') for row in range(2,lenth_bj_list+2): for col in range(1,5): sheet1.cell(row, col).value = bj_list[row-2]['companyFullName'] sheet1.cell(row,2).value = bj_list[row-2]['education'] sheet1.cell(row,3).value = bj_list[row-2]['workYear'] sheet1.cell(row,4).value = bj_list[row-2]['salary'] workbook.save('files/analysis.xlsx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 结果显示

`

