
- 1Android Studio在导入项目后编译出现java版本错误解决方法
- 2【华为OD机试真题 JS语言】477、路口最短时间问题 | 机试真题+思路参考+代码解析(C卷)
- 3堡垒机上内网 socket 访问端口_mobaxterm socket
- 4从 Elasticsearch 到 Apache Doris,统一日志检索与报表分析,360 企业安全浏览器的数据架构升级实践_elasticsearch apache doris
- 5位运算知识点 (& ^ | )_位运算中&
- 6【每日一题】2834. 找出美丽数组的最小和-2024.3.8
- 7彻底明白Java的IO系统(文摘)---JAVA之精髓IO流 _如果我们想实现“先把要写入文件的数据先缓存到存中,再把缓存中的数据写入文件中
- 8基于Pytorch框架的手写体识别_基于pytorch的字母识别系统0
- 92023年苹果MacBook清理软件哪个好用?CleanMyMac 怎么样?_官网下载的cleanmymac能用多久
- 10最全新手建站教程 如何搭建网站Windows服务器
Python数据分析案例17——电影人气预测(特征工程构建)
赞
踩
案例背景
本次案例是中国人民大学“人工智能与机器学习(2022年秋季)”课程的课堂竞赛。
比赛是根据有关电影的各种信息来预测电影的受欢迎程度,包括演员、工作人员、情节关键字、预算、收入、海报、上映日期、语言、制作公司、国家、TMDB 投票计数、平均投票等。
比赛是在kaggle上进行的,需要这代码演示数据的同学可以参考:数据
由于原始数据特征变量基本都是文本,本次案例最大价值在于特征工程的构建,即怎么把文本变为数值型变量。
数据读取
导入常用包
- #导入数据分析常用包
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
-
- %matplotlib inline
- plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
- plt.rcParams['axes.unicode_minus'] = False #负号
读取训练集和测试集
- data=pd.read_csv('movies_train.csv')
- data2=pd.read_csv('movies_test.csv')
查看数据前五行
data.head()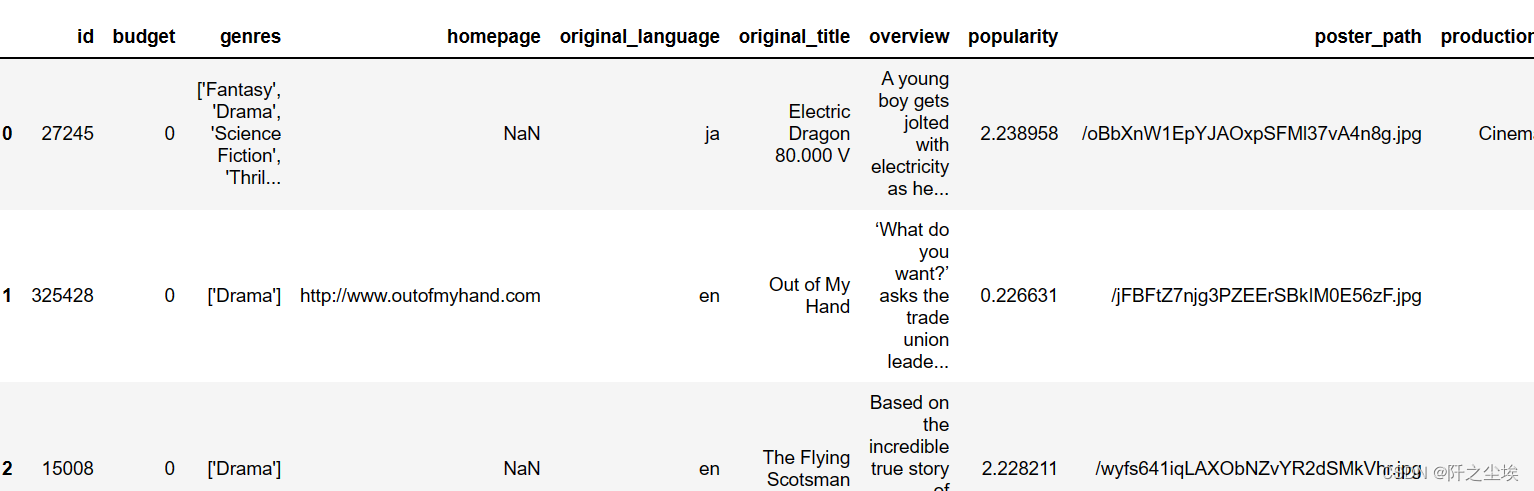
有点多就不展示完了
查看训练集和测试集数据基础信息
- data=data.infer_objects()
- data2=data2.infer_objects()
- data.info() ,data2.info()

可以看到大部分变量都不是数值型,需要进行处理
变量信息解释
id- 电影ID。
title- 电影名称 文本变量
homepage- 电影主页 文本变量
genres- 电影类型 分类型变量
overview- 电影概述 文本变量
poster_path- 电影海报的位置 图片文本
tagline- 电影标语 文本变量
runtime- 电影的运行时间 数值型变量
spoken_languages- 电影口语 分类型变量
original_language- 电影原文 分类型变量
original_title- 电影原名 文本变量
production_companies- 电影制作公司 分类型变量
production_countries- 电影的制作国家 分类型变量
release_date- 电影上映日期 时间变量
budget- 电影预算 数值型变量
revenue- 电影收入 数值型变量
status- 电影状态 分类型变量
vote_count- 电影票数 数值型变量
vote_average- 电影的平均票数 数值型变量
keywords- 电影关键词 文本变量
cast- 电影演员 字典变量
crew- 电影剧组 字典变量
popularity- 电影的人气评分 目标变量,数值型
数据预处理
特征筛选
由于数据的文本型变量较多,较难处理。将一些没用的文本变量和难以提取信息的文本特征选择删除
这里先选择删除电影ID,电影主页,电影概述,电影海报的位置,电影标语,电影关键词,电影制作公司,电影的制作国家
- #删除的变量
- col_drop=['id','homepage','overview','poster_path','tagline','keywords','production_companies','production_countries']
- #测试集ID留着后面提交
- ID=data2['id']
- data.drop(col_drop,axis=1,inplace=True)
- data2.drop(col_drop,axis=1,inplace=True)
新特征构建
剩余的文本变量,一一进行处理,进行新的特征工程的构建。
- 首先对电影名称title和电影的原始名original_title称进行一个匹配,相同返回1,不相同返回0,从而构建一个新特征name_change。
- 通过对电影源语言spoken_languages是否含有英语(最通用的语言),构建一个虚拟变量spoken,语言里面包含语言返回1,不包含返回0。
- 同样我们对电影语言original_language是否为英语,构建虚拟变量original,是英语返回1,不是英语返回0。
- 通过对上映日期release_date计算,得到该影片的年龄movie_age。使用2022(今年)-发行年份得到,并转化为整形数。由于计算过程中发行存在缺失值,对缺失值采用均值进行填充。
- 对电影演员cast、电影剧组crew的字典变量进行简单处理,计算它们的个数,构建新的特征——电影知名演员个数cast_num,电影剧组成员个数crew_num。
- 对于电影类别,进行虚拟变量处理。通过代码发现总共有20种电影类别。由于每个电影可能涉及不止一个类别,所以整体构建20个虚拟变量,如果电影类别存在这一类就为1,不存在就为0。
- 剩下的变量status表示电影的状态,直接进行独立热编码处理就行,生成5个虚拟变量。
首先对电影名称和电影的原始名称进行一个匹配,相同返回1,不相同返回0,从而构建一个新特征
- data=data.assign(name_change=lambda d: (d.title==d.original_title)*1)
- data2=data2.assign(name_change=lambda d: (d.title==d.original_title)*1)
- def check_languages(txt):
- txt=eval(txt)
- if 'en'in txt:
- languages=1
- else:
- languages=0
- return languages
- data['spoken']=data['spoken_languages'].apply(check_languages)
- data2['spoken']=data2['spoken_languages'].apply(check_languages)
电影原文也是一样的处理
- def check_languages2(txt):
- if txt=='en':
- languages=1
- else:
- languages=0
- return languages
- data['original']=data['original_language'].apply(check_languages2)
- data2['original']=data2['original_language'].apply(check_languages2)
通过对发行日期计算,得到该影片的年龄, 缺失值采用均值填充
- data['movie_age']=(2022-pd.to_datetime(data['release_date']).dt.year).fillna((2022-pd.to_datetime(data['release_date']).dt.year).mean()).astype('int')
- data2['movie_age']=(2022-pd.to_datetime(data2['release_date']).dt.year).fillna((2022-pd.to_datetime(data2['release_date']).dt.year).mean()).astype('int')
对电影演员、电影剧组的字典变量进行简单处理,计算它们的个数,构建一个新的特征
- def check(d):
- return len(d)
- data['cast_num']=data['cast'].apply(check)
- data2['cast_num']=data2['cast'].apply(check)
-
- data['crew_num']=data['crew'].apply(check)
- data2['crew_num']=data2['crew'].apply(check)
对于电影类别,进行虚拟变量处理,由于一个电影可能属于多个类别,不能直接独立热编码,需要进行处理。
首先得到所有类别的名称列表
- all_kind=[]
- for a in [eval(i)for i in data['genres'].unique()]:
- for a1 in a:
- all_kind.append(a1)
- set_kind=list(set(all_kind))
定义处理函数,生成虚拟变量
- def check2(txt):
- txt=eval(txt)
- dummys=[]
- for k in set_kind:
- if k in txt:
- dummys.append(1)
- else:
- dummys.append(0)
- return np.array(dummys)
- def check3(col,data):
- all_kind=[]
- for a in [eval(i)for i in data[col].unique()]:
- for a1 in a:
- all_kind.append(a1)
- set_kind=list(set(all_kind))
- print(f'{col}特征里面有{len(set_kind)}个类别,生成{len(set_kind)}个虚拟变量')
- dummys_max=np.array([np.array(arr) for arr in data[col].apply(check2).to_numpy()])
- for i,kind in enumerate(set_kind):
- data[f'{col}_{kind}']=dummys_max[:,i]

应用函数
- check3('genres',data)
- check3('genres',data2)

这样每个电影对应20个类别特征,如果它属于这个类别,取值为1,不属于取值为0。
将构建完的旧特征进行删除
- #删除的变量
- col_drop2=['original_title','title','release_date','cast','crew','genres','spoken_languages','original_language']
- data.drop(col_drop2,axis=1,inplace=True)
- data2.drop(col_drop2,axis=1,inplace=True)
剩下的变量status是典型的分类变量,可以直接进行虚拟变量独热处理
- data=pd.get_dummies(data)
- data2=pd.get_dummies(data2)
再次查看所有变量的信息
- data.info()
- data2.info()
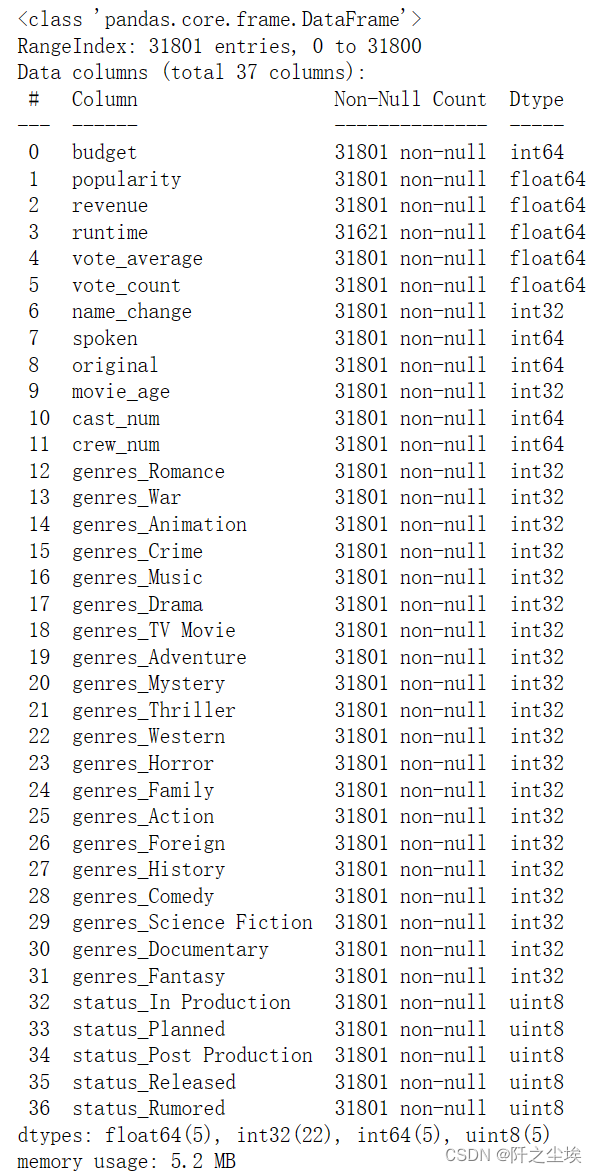
可以看到所有的特征变量都是数值型,可以进行模型运算了。
但是电影时间一列还有缺失值,需要填充,采用均值进行填充。
- data['runtime']=data['runtime'].fillna(data['runtime'].mean())
- data2['runtime']=data2['runtime'].fillna(data2['runtime'].mean())
status这个变量测试集独热出来多了一列,由于训练集的status没有status_Canceled这个情况,我们选择进行删除这个虚拟变量特征
data2.drop(columns=['status_Canceled'],inplace=True)最后我们将训练集的y——popularity作为响应变量提取出来,完成特征工程的构建。
取出y
- y=data['popularity']
- data.drop(columns=['popularity'],inplace=True)
取出X
- X=data.copy()
- X2=data2[data.columns]
查看训练集,测试集,y的形状
print(X.shape,y.shape,X2.shape)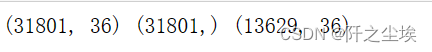
可以看到最终训练集和测试集都是36个变量,训练集31801条,测试集13629条,下面开始数据探索分析机器学习的模型构建。
数据探索
特征变量分布探索
- #查看特征变量的箱线图分布
- columns = data.columns.tolist() # 列表头
- dis_cols = 6 #一行几个
- dis_rows = len(columns)
- plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
-
- for i in range(len(columns)):
- plt.subplot(dis_rows,dis_cols,i+1)
- sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
- plt.xlabel(columns[i],fontsize = 20)
- plt.tight_layout()
- #plt.savefig('特征变量箱线图.jpg',dpi=512)
- plt.show()
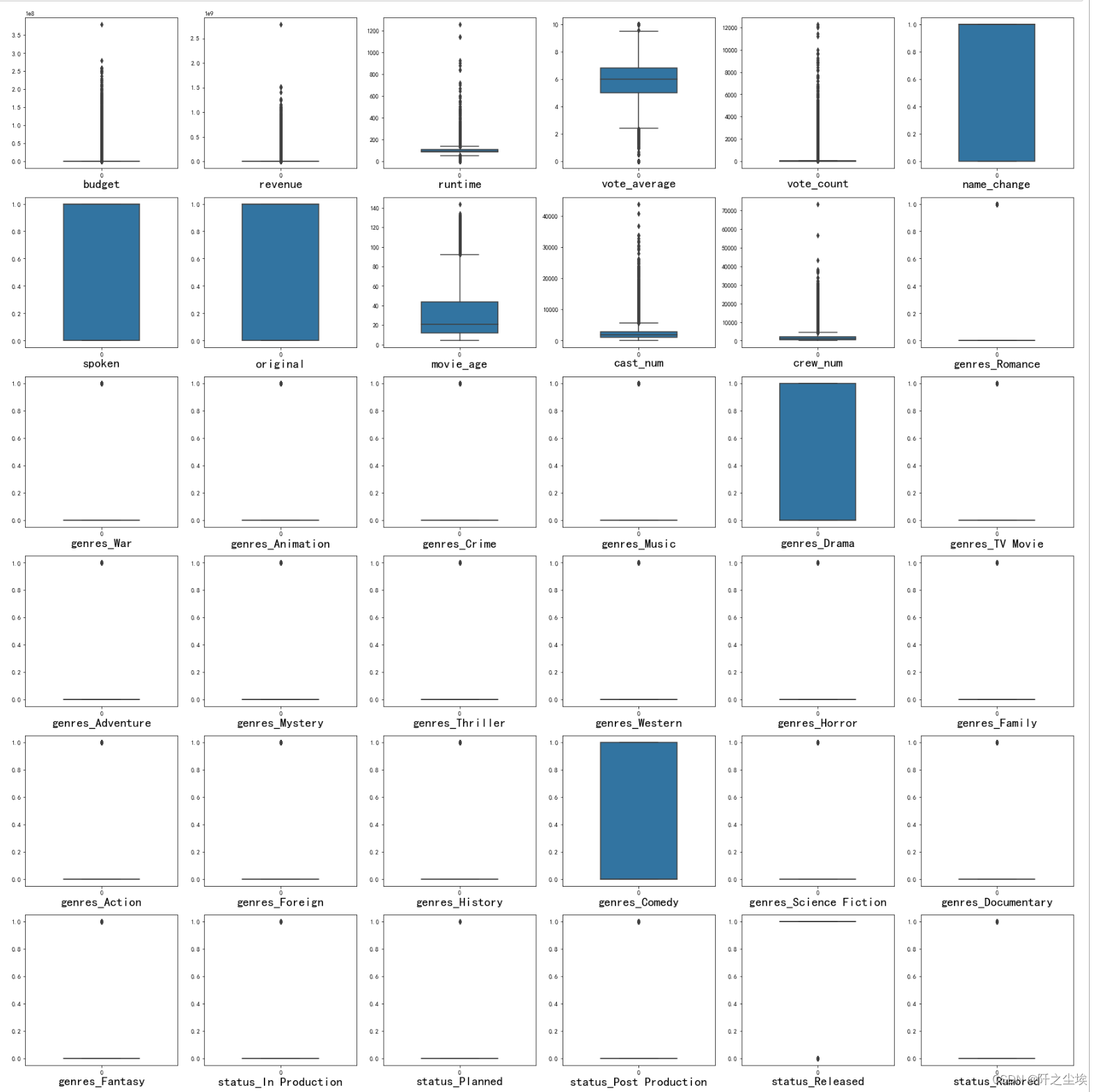
可以看到分类型的虚拟变量较多,数值型变量——budget,revenue,runtime的极大值较多
#画密度图,训练集和测试集对比
- dis_cols = 6 #一行几个
- dis_rows = len(columns)
- plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
-
- for i in range(len(columns)):
- ax = plt.subplot(dis_rows, dis_cols, i+1)
- ax = sns.kdeplot(data[columns[i]], color="Red" ,shade=True)
- ax = sns.kdeplot(data2[columns[i]], color="Blue",warn_singular=False,shade=True)
- ax.set_xlabel(columns[i],fontsize = 20)
- ax.set_ylabel("Frequency",fontsize = 18)
- ax = ax.legend(["train", "test"])
- plt.tight_layout()
- #plt.savefig('训练测试特征变量核密度图.jpg',dpi=500)
- plt.show()
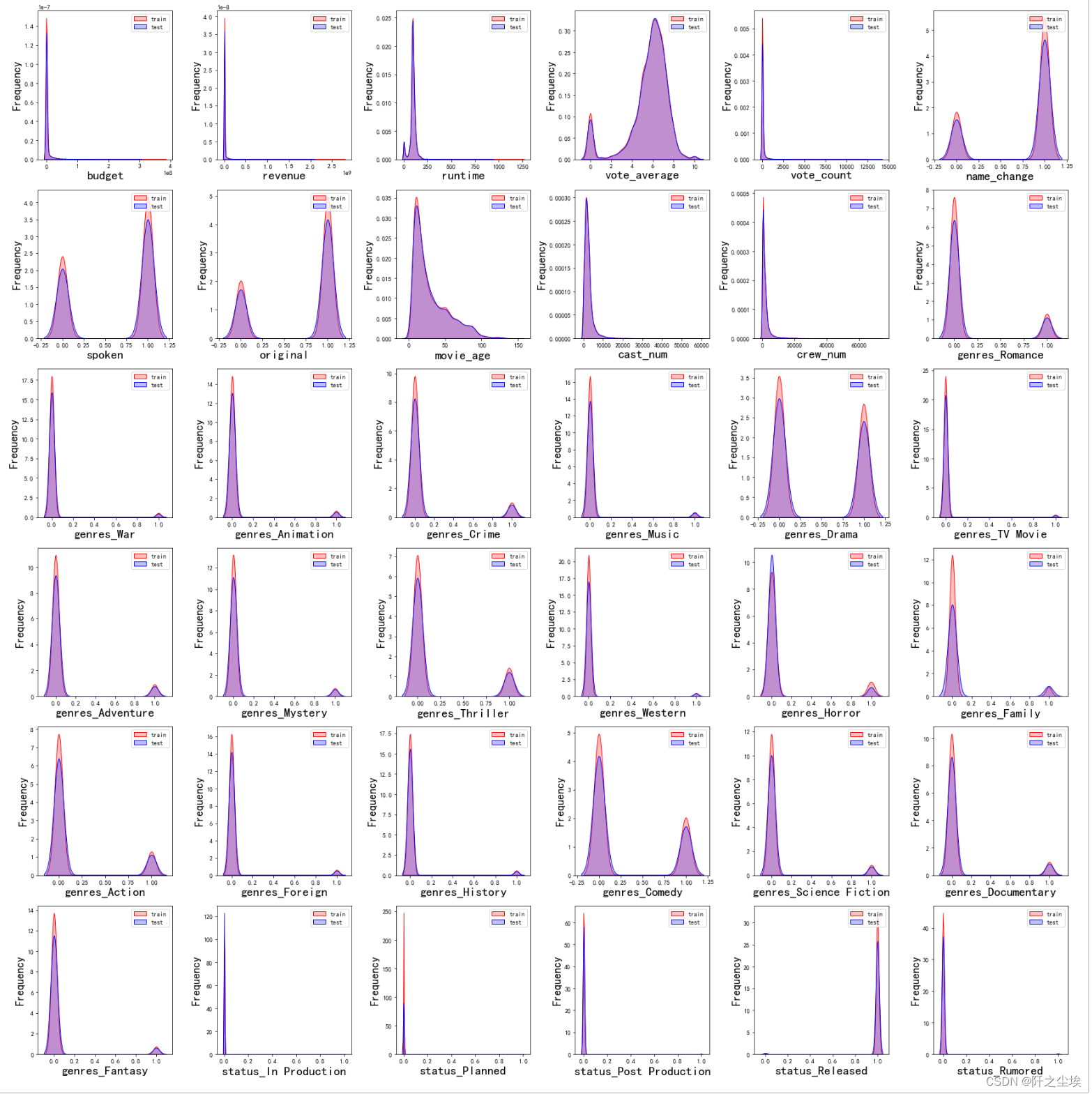
训练集和测试集数据的分布还是较为一致
异常值处理
y异常值处理
y是数值型变量,画其箱线图直方图密度图
- # 查看y的分布
- #回归问题
- plt.figure(figsize=(6,2),dpi=128)
- plt.subplot(1,3,1)
- y.plot.box(title='响应变量箱线图')
- plt.subplot(1,3,2)
- y.plot.hist(title='响应变量直方图')
- plt.subplot(1,3,3)
- y.plot.kde(title='响应变量核密度图')
- #sns.kdeplot(y, color='Red', shade=True)
- #plt.savefig('处理前响应变量.png')
- plt.tight_layout()
- plt.show()
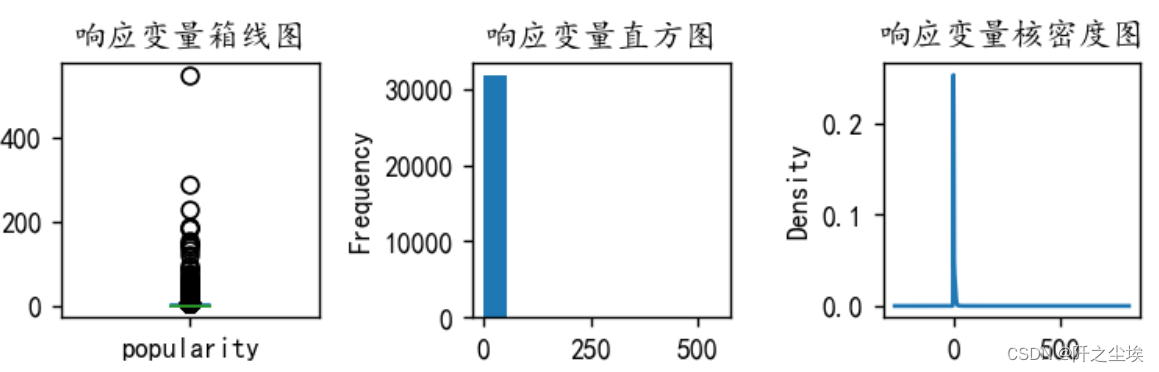
可以看到y有很严重的异常值,要筛掉,将y大于50的样本都筛掉
- #处理y的异常值
- y=y[y <= 50]
- plt.figure(figsize=(6,2),dpi=128)
- plt.subplot(1,3,1)
- y.plot.box(title='响应变量箱线图')
- plt.subplot(1,3,2)
- y.plot.hist(title='响应变量直方图')
- plt.subplot(1,3,3)
- y.plot.kde(title='响应变量核密度图')
- #sns.kdeplot(y, color='Red', shade=True)
- #plt.savefig('处理后响应变量.png')
- plt.tight_layout()
- plt.show()
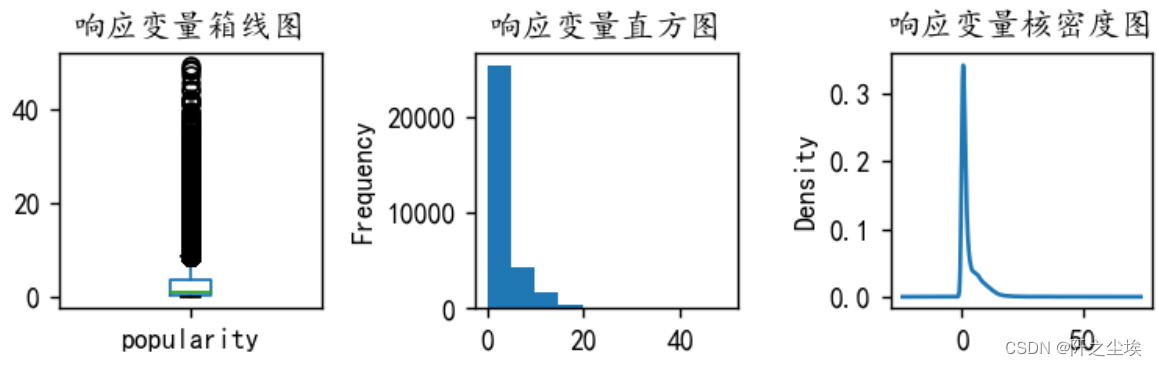
可以看到极端值情况好了一些,然后将筛出来的样本赋值给x
- #筛选给x
- X=X.iloc[y.index,:]
- X.shape
![]()
31801数据变成了31771条。
X异常值处理
#X异常值处理,先标准化
- from sklearn.preprocessing import StandardScaler
- scaler = StandardScaler()
- X_s = scaler.fit_transform(X)
- X2_s = scaler.fit_transform(X2)
#然后画图查看
- plt.figure(figsize=(20,8))
- plt.boxplot(x=X_s,labels=data.columns)
- plt.hlines([-20,20],0,len(columns))
- plt.xticks(rotation=40)
- #plt.savefig('特征变量标准化箱线图.png',dpi=256)
- plt.show()
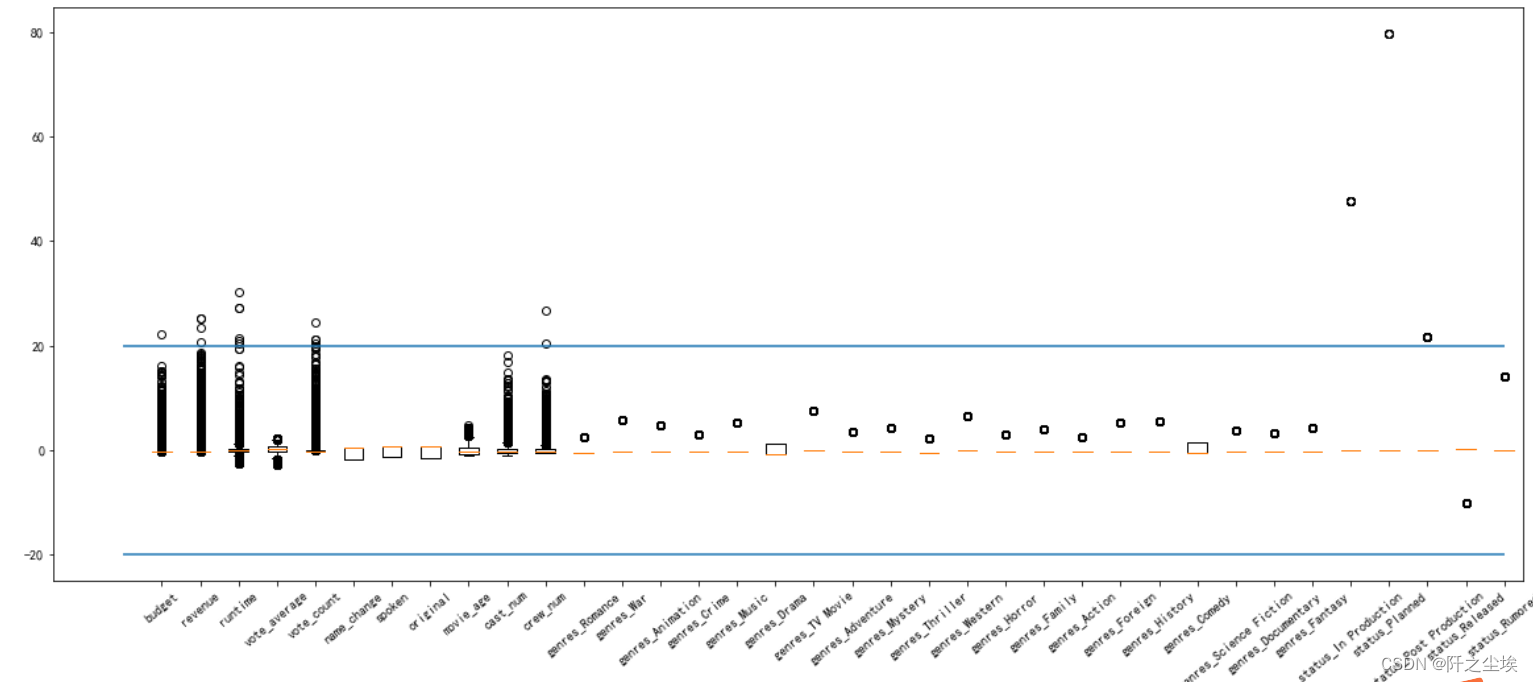
可以看到budget,revenue,runtime,vote_count,genres_Family,status_In Production,status_Planned这几个特征都有严重的异常值,超过了20倍的方差,需要进行筛除。
#异常值多的列进行处理
- def deal_outline(data,col,n): #数据,要处理的列名,几倍的方差
- for c in col:
- mean=data[c].mean()
- std=data[c].std()
- data=data[(data[c]>mean-n*std)&(data[c]<mean+n*std)]
- #print(data.shape)
- return data
超过10倍方差进行删除
- X=deal_outline(X,['budget','revenue','runtime','vote_count','genres_Family','status_In Production','status_Planned'],10)
- y=y[X.index]
- X.shape,y.shape

还剩31536个样本
相关系数矩阵
- corr = plt.subplots(figsize = (18,16),dpi=128)
- corr= sns.heatmap(data.assign(Y=y).corr(method='spearman'),annot=True,square=True)
- #plt.savefig('训练集特征热力图.png',dpi=512)
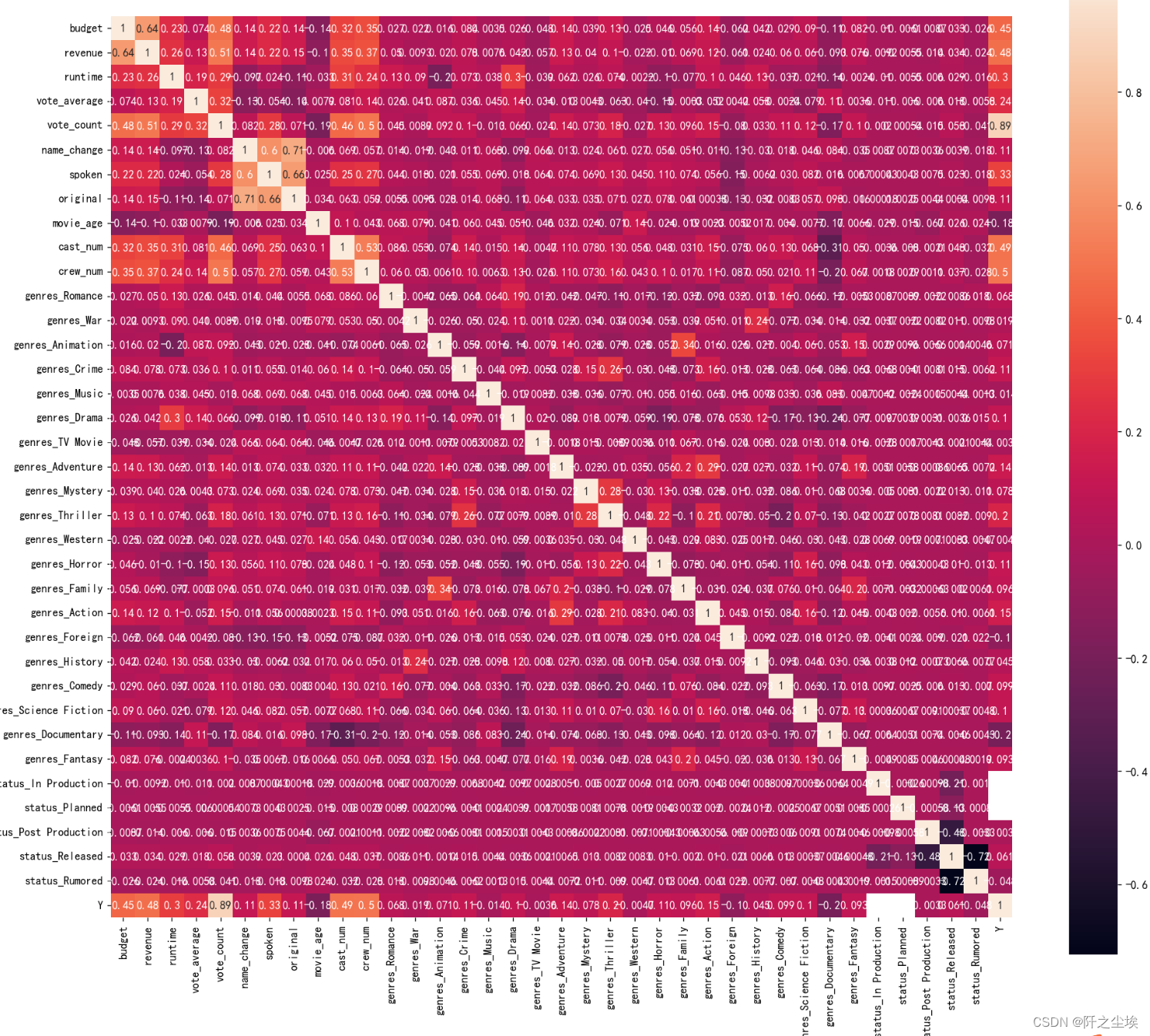
特征有点多,可能不是很清楚
可以看到y与budget,revenue,cast_num,crew_num,vote_count这几个变量的相关性高,说明这几个变量对于y的影响较大。
机器学习
划分训练集和验证集,80%训练,20%进行验证
- from sklearn.model_selection import train_test_split
- X_train,X_val,y_train,y_val=train_test_split(X,y,test_size=0.2,random_state=0)
数据标准化
- from sklearn.preprocessing import StandardScaler
- scaler = StandardScaler()
- scaler.fit(X_train)
- X_train_s = scaler.transform(X_train)
- X_val_s = scaler.transform(X_val)
- X2_s=scaler.transform(X2)
- print('训练数据形状:')
- print(X_train_s.shape,y_train.shape)
- print('验证测试数据形状:')
- (X_val_s.shape,y_val.shape,X2_s.shape)

模型选择
采用十种模型,对比验证集精度
- from sklearn.linear_model import LinearRegression
- from sklearn.linear_model import ElasticNet
- from sklearn.neighbors import KNeighborsRegressor
- from sklearn.tree import DecisionTreeRegressor
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.ensemble import GradientBoostingRegressor
- from xgboost.sklearn import XGBRegressor
- from lightgbm import LGBMRegressor
- from sklearn.svm import SVR
- from sklearn.neural_network import MLPRegressor

定义评估函数
- from sklearn.metrics import mean_absolute_error
- from sklearn.metrics import mean_squared_error,r2_score
-
- def evaluation(y_test, y_predict):
- mae = mean_absolute_error(y_test, y_predict)
- mse = mean_squared_error(y_test, y_predict)
- rmse = np.sqrt(mean_squared_error(y_test, y_predict))
- #mape=(abs(y_predict -y_test)/ y_test).mean()
- r_2=r2_score(y_test, y_predict)
- return mae, rmse, r_2 #mse
模型实例化
- #线性回归
- model1 = LinearRegression()
-
- #弹性网回归
- model2 = ElasticNet(alpha=0.05, l1_ratio=0.5)
-
- #K近邻
- model3 = KNeighborsRegressor(n_neighbors=10)
-
- #决策树
- model4 = DecisionTreeRegressor(random_state=77)
-
- #随机森林
- model5= RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)
-
- #梯度提升
- model6 = GradientBoostingRegressor(n_estimators=500,random_state=123)
-
- #极端梯度提升
- model7 = XGBRegressor(objective='reg:squarederror', n_estimators=1000, random_state=0)
-
- #轻量梯度提升
- model8 = LGBMRegressor(n_estimators=1000,objective='regression', # 默认是二分类
- random_state=0)
-
- #支持向量机
- model9 = SVR(kernel="rbf")
-
- #神经网络
- model10 = MLPRegressor(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)
-
- model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
- model_name=['线性回归','惩罚回归','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']
拟合训练模型,计算模型误差指标
- df_eval=pd.DataFrame(columns=['MAE','RMSE','R2'])
- for i in range(10):
- model_C=model_list[i]
- name=model_name[i]
- model_C.fit(X_train_s, y_train)
- pred=model_C.predict(X_val_s)
- s=evaluation(y_val,pred)
- df_eval.loc[name,:]=list(s)
查看不同模型的评价指标
df_eval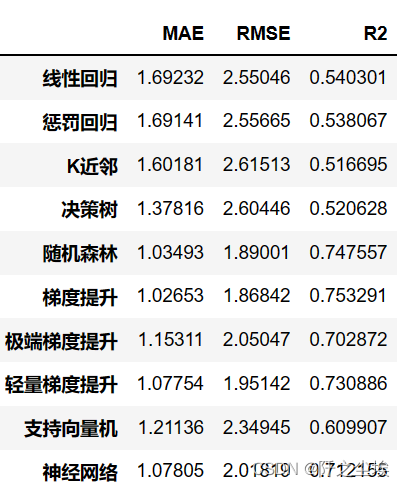
画图查看
- bar_width = 0.4
- colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan']
- fig, ax = plt.subplots(3,1,figsize=(6,12))
- for i,col in enumerate(df_eval.columns):
- n=int(str('31')+str(i+1))
- plt.subplot(n)
- df_col=df_eval[col]
- m =np.arange(len(df_col))
-
- #hatch=['-','/','+','x'],
- plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
-
- #plt.xlabel('Methods',fontsize=12)
- names=df_col.index
- plt.xticks(range(len(df_col)),names,fontsize=14)
- plt.xticks(rotation=40)
-
- if col=='R2':
- plt.ylabel(r'$R^{2}$',fontsize=14)
- else:
- plt.ylabel(col,fontsize=14)
- plt.tight_layout()
- #plt.savefig('柱状图.jpg',dpi=512)
- plt.show()
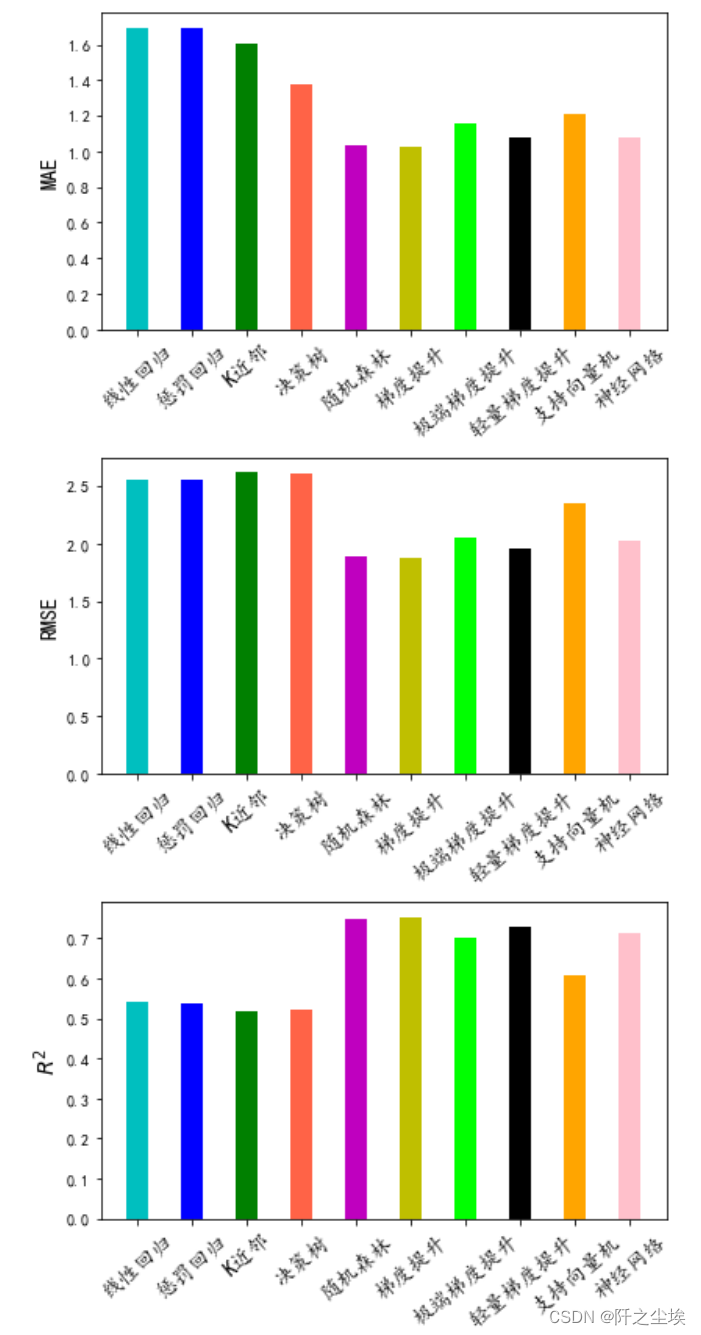
我们采用三种最优的模型进一步搜索最优超参数:随机森林,梯度提升,轻量梯度,然后进行预测和存储。
超参数搜索
轻量梯度超参数优化
- #利用K折交叉验证搜索最优超参数
- from sklearn.model_selection import KFold, StratifiedKFold
- from sklearn.model_selection import GridSearchCV,RandomizedSearchCV
- # Choose best hyperparameters by RandomizedSearchCV
- #随机搜索决策树的参数
- param_distributions = {'max_depth': range(4, 10), 'subsample':np.linspace(0.5,1,5 ),'num_leaves': [15, 31, 63, 127],
- 'colsample_bytree': [0.6, 0.7, 0.8, 1.0]}
- # 'min_child_weight':np.linspace(0,0.1,2 ),
- kfold = KFold(n_splits=3, shuffle=True, random_state=1)
- model =RandomizedSearchCV(estimator= LGBMRegressor(objective='regression',random_state=0),
- param_distributions=param_distributions, n_iter=200)
- model.fit(X_train_s, y_train)

- #查看最优参数
- model.best_params_
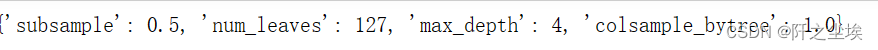
最优参数赋值给模型,然后拟合评价
- model = model.best_estimator_
- model.score(X_val_s, y_val)
![]()
可以看到拟合优度上升了一点
#利用找出来的最优超参数在所有的训练集上训练,然后预测
- model=LGBMRegressor(objective='regression',subsample=0.625,learning_rate= 0.01,n_estimators= 1000,num_leaves=15,
- max_depth= 4,colsample_bytree=1.0,random_state=0)
- model.fit(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val])
- print(model.score(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val]))
- pred=model.predict(X2_s)
储存预测结果
- df=pd.DataFrame(ID)
- df['popularity']=pred
- df.to_csv('LGBM预测结果.csv',index=False)
#梯度提升和随机森林也是一样搜索超参数,然后训练和预测
- #梯度提升
- param_distributions = {'max_depth': range(4, 10), 'subsample':np.linspace(0.5,1,5 ),'learning_rate': np.linspace(0.05,0.3,6 ), 'n_estimators':[100,500,1000,1500, 2000]}
- # 'min_child_weight':np.linspace(0,0.1,2 ),
- kfold = KFold(n_splits=3, shuffle=True, random_state=1)
- model =RandomizedSearchCV(estimator= GradientBoostingRegressor(n_estimators=500,random_state=123),param_distributions=param_distributions, n_iter=5)
- model.fit(X_train_s, y_train)
- model = model.best_estimator_
- model.fit(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val])
- print(model.score(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val]))
- pred=model.predict(X2_s)
- df['popularity']=pred
- df.to_csv('梯度提升预测结果.csv',index=False)
![]()
- #随机森林
- param_distributions = {'max_depth': range(4, 10), 'n_estimators':[100,500,1000,1500, 2000]}
- kfold = KFold(n_splits=3, shuffle=True, random_state=1)
- model =RandomizedSearchCV(estimator=RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0),param_distributions=param_distributions, n_iter=5)
- model.fit(X_train_s, y_train)
- model = model.best_estimator_
- model.fit(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val])
- print(model.score(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val]))
- pred=model.predict(X2_s)
- df['popularity']=pred
- df.to_csv('随机森林提升预测结果.csv',index=False)

下面就可以将这三个预测结果题kaggle提交了!!!
变量重要性
以LGBM为例,画出每个特征变量对响应变量影响程度的图。
- model=LGBMRegressor(objective='regression',subsample=0.5,learning_rate= 0.01,n_estimators= 1000,num_leaves=127,
- max_depth= 4,colsample_bytree=1.0,random_state=0)
- model.fit(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val])
- plt.figure(figsize=(4,8))
- sorted_index = model.feature_importances_.argsort()
- plt.barh(range(data.shape[1]), model.feature_importances_[sorted_index])
- plt.yticks(np.arange(data.shape[1]), data.columns[sorted_index])
- plt.xlabel('Feature Importance')
- plt.ylabel('Feature')
- plt.show()
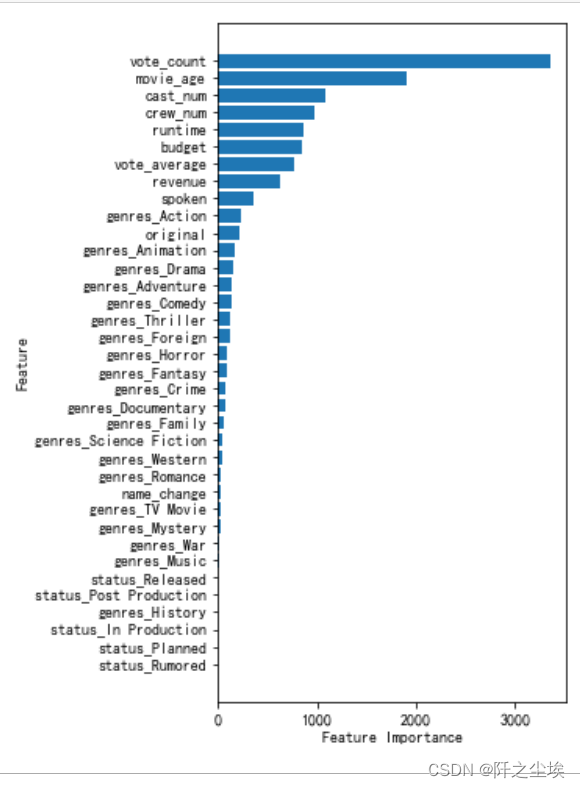
可以看到影响y变量最重要的是vote_count,movie_age,cast_num,crew_num等变量,
movie_age,cast_num,crew_num变量是自己构建的变量,说明这几个特征还是很有效的。
目前在kaggle上能得到最好的预测结果的最好的模型参数。
- model=LGBMRegressor(objective='regression',subsample=0.65,learning_rate= 0.01,n_estimators= 800,num_leaves=127,
- max_depth= 5,colsample_bytree=0.75,random_state=10)
- model.fit(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val])
- print(model.score(np.r_[X_train_s,X_val_s],np.r_[y_train,y_val]))
- pred=model.predict(X2_s)
- df['popularity']=pred
- df.to_csv('LGBM2.csv',index=False)
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)

