
- 1新书周榜:机器学习、Python、Linux成为最闪亮的星_linux设备驱动开发 刘寿永
- 2《ChatGPT原理与架构:大模型的预训练、迁移和中间件编程 》
- 3Azure系列2.1.11 —— CloudBlobContainer
- 43.15国际消费者权益日:消费者隐私威胁与保护
- 5获取docker镜像内文件_docker镜像提取文件
- 6浅谈集群和分布式的区别和联系_做了分布式部署还有必要做集群吗?
- 7MAC(适用于M1,M2芯片)下载Java8(官方 ARM64 JDK1.8)安装、配置环境,支持动态切换JDK_mac jdk1.8下载
- 8org/apache/commons/logging/LogFactory
- 9常见软件发布版本编号解释
- 10模拟电子技术------半导体_为什么 电子漂移运动是不利现象
支持向量机 SVM | 非线性可分:核函数
赞
踩
前面我们讲述了SVM算法的线性可分问题,即对应硬间隔模型和软间隔模型;下面我们来聊SVM算法的非线性可分问题
注意:对于完全不可分的数据,SVM硬间隔与软间隔都无法解决
- 1
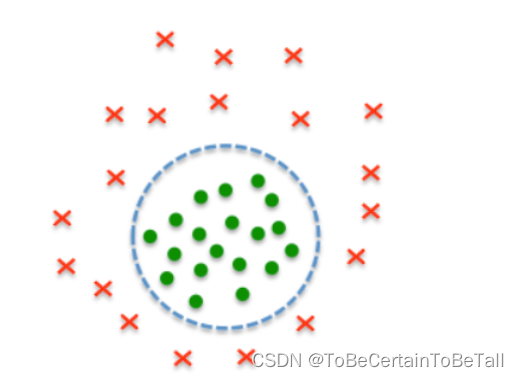
一. 情景引入
我们在线性回归:多项式扩展篇中,采用多项式扩展的方法,将低维度的数据扩展成为高维度的数据,从而使线性回归模型可以解决线性不可分的问题
以2维空间中的线性不可分为例子:
对于2维线性模型h θ ( x 1 , x 2 ) = θ 0 + x 1 θ 1 + x 2 θ 2 h_{\theta }(x_{1},x_{2})=\theta _{0} + x_{1}\theta _{1}+x_{2}\theta _{2} hθ(x1,x2)=θ0+x1θ1+x2θ2
对 ( x 1 , x 2 ) (x_{1},x_{2}) (x1,x2)进行2阶多项式扩展:
( x 1 , x 2 ) → 多项式扩展 ( x 1 , x 2 , x 1 2 , x 2 2 , x 1 x 2 ) {(x_{1},x_{2})\overset{多项式扩展}{\rightarrow} (x_{1},x_{2},x_{1}^{2},x_{2}^{2},x_{1}x_{2} )} (x1,x2)→多项式扩展(x1,x2,x12,x22,x1x2)
对于5维线性模型
h θ ( x 1 , x 2 ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 1 2 + θ 4 x 2 2 + θ 5 x 1 x 2 h_{\theta }(x_{1},x_{2})=\theta _{0} +\theta _{1}x_{1} +\theta _{2}x_{2} +\theta _{3}x_{1}^{2}+ \theta _{4}x_{2}^{2}+\theta _{5} x_{1}x_{2} hθ(x1,x2)=θ0+θ1x1+θ2x2+θ3x12+θ4x22+θ5x1x2
那么同理,在SVM算法中,我们依然希望通过一种方法,将低维特征数据映射到高维特征数据中,从而解决数据的线性不可分问题
于是我们首先尝试通过多项式扩展的方式解决低维度到高维度映射的问题,为了描述方便,我们来定义一个
ϕ
\phi
ϕ函数,该函数的作用将数据从低维度映射到高维度中,也就是做多项式扩展;那么对于SVM优化的目标函数,我们就可以得到:
{
min
1
2
∑
i
=
1
,
i
=
1
m
β
i
β
j
y
(
i
)
y
(
j
)
ϕ
(
x
(
j
)
)
⋅
ϕ
(
x
(
i
)
)
−
∑
i
=
1
m
β
i
s
.
t
:
∑
i
=
1
m
β
i
y
(
i
)
=
0
a
\left\{
0
≤
β
i
≤
C
,
i
=
1
,
2
,
.
.
.
,
m
0\le \beta _{i}\le C,i=1,2,...,m
0≤βi≤C,i=1,2,...,m
进一步解释 ϕ ( x ( j ) ) ⋅ ϕ ( x ( i ) ) \phi (x^{(j)})\cdot \phi( x^{(i)}) ϕ(x(j))⋅ϕ(x(i))
首先,明确 x ( j ) , x ( i ) x^{(j)},x^{(i)} x(j),x(i)是向量,这里是向量的点乘
下面我们来举例子:
是不是觉得3维数据的计算量还能接受?
如果原始数据是10维,20维度,30维呢?
如果有一百万条数据呢?
显然,这样的点乘计算量巨大
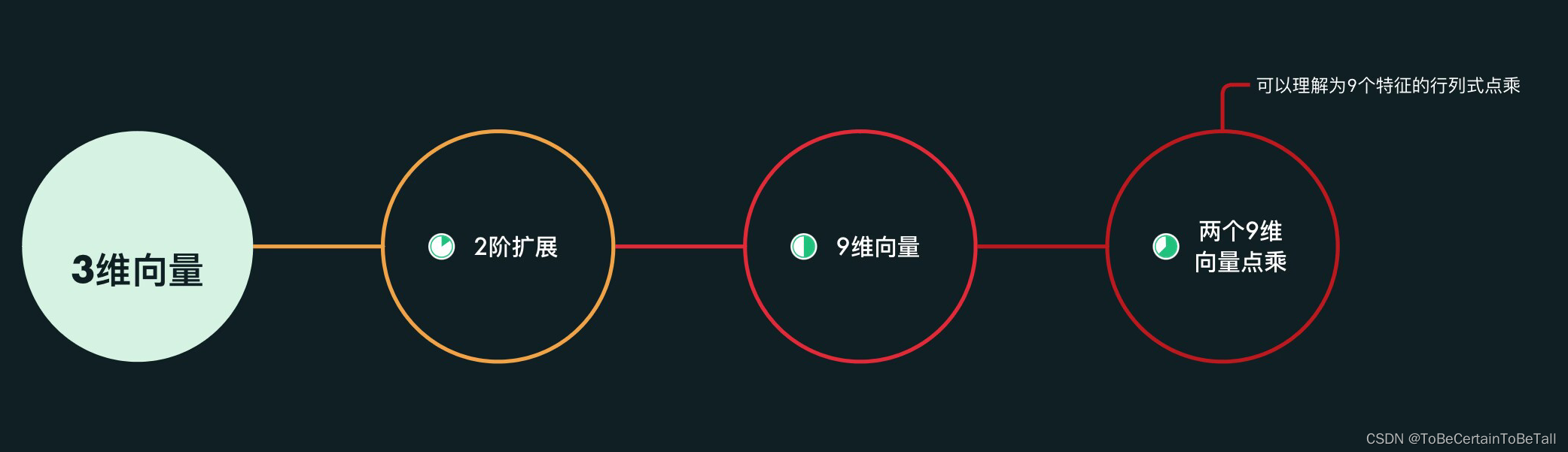
二. 核函数
SVM的发明者为了解决上述计算量的问题,发明了核函数
-
核函数定义
假设函数Ф是一个低维特征空间到高维特征空间的映射,那么如果存在函数K(x,z), 对于任意的低维特征向量x和z,都有:
K ( x , z ) = ϕ ( x ) ϕ ( z ) K(x,z) = \phi (x)\phi (z) K(x,z)=ϕ(x)ϕ(z)
则称函数K为核函数(kernal function) -
说人话版本:
核函数在低维空间上的计算量等价于特征做维度扩展后的点乘的结果;即核函数的作用相当于扩展后再点乘这里需要补充一点 对于Ф(从低位映射到高维)而言,多项式扩展只是其中的一种方法- 1
- 2
即,核函数用低维空间中少量的内积的计算量让模型具有高维空间中的线性可分的优点
首先我们用算式说明:
假设向量 x 1 = ( α 1 , α 2 ) T , x 2 = ( η 1 , η 2 ) T x_{1} =(\alpha _{1}, \alpha _{2})^{T},x_{2} =( \eta _{1}, \eta_{2})^{T} x1=(α1,α2)T,x2=(η1,η2)T
2阶扩展映射到五维空间中,我们可以得到:
ϕ
(
x
1
)
⋅
ϕ
(
x
2
)
=
α
1
η
1
+
α
2
η
2
+
α
1
2
η
1
2
+
α
2
2
η
2
2
+
α
1
α
2
η
1
η
2
\phi (x_{1})\cdot \phi (x_{2})=\alpha _{1}\eta _{1}+ \alpha _{2}\eta_{2}+\alpha _{1}^{2}\eta _{1}^{2}+\alpha _{2}^{2}\eta _{2}^{2}+\alpha _{1}\alpha _{2}\eta _{1}\eta _{2}
ϕ(x1)⋅ϕ(x2)=α1η1+α2η2+α12η12+α22η22+α1α2η1η2
而对于K函数的思想,我们可以得到:
(
x
1
⋅
x
2
+
1
)
2
=
2
α
1
η
1
+
2
α
2
η
2
+
α
1
2
η
1
2
+
α
2
2
η
2
2
+
2
α
1
α
2
η
1
η
2
+
1
(x_{1}\cdot x_{2}+1)^{2} = 2\alpha _{1}\eta _{1}+ 2\alpha _{2}\eta_{2}+\alpha _{1}^{2}\eta _{1}^{2}+\alpha _{2}^{2}\eta _{2}^{2}+2\alpha _{1}\alpha _{2}\eta _{1}\eta _{2}+1
(x1⋅x2+1)2=2α1η1+2α2η2+α12η12+α22η22+2α1α2η1η2+1
可以直观的发现,式子的主要区别在系数上
也就是说:
只需要乘上一个系数,就可以将五维空间的内积转换成两维空间的内积
- 1
- 2
- 3
下面,我们再用实际数据来具体说明核函数的作用:
假设向量
x
1
=
(
3
,
5
)
x_{1} =(3, 5)
x1=(3,5),二阶扩展后得到:3,5,9,25,15
x
2
=
(
4
,
2
)
x_{2} =( 4,2)
x2=(4,2),二阶扩展后得到:4,2,16,4,8
进行二阶扩展时,我们会得到:
ϕ
(
x
1
)
⋅
ϕ
(
x
2
)
=
3
∗
4
+
5
∗
2
+
9
∗
16
+
25
∗
4
+
15
∗
8
=
386
\phi (x_{1})\cdot \phi (x_{2})=3*4+5*2+9*16+25*4+15*8=386
ϕ(x1)⋅ϕ(x2)=3∗4+5∗2+9∗16+25∗4+15∗8=386
(
x
1
⋅
x
2
+
1
)
2
=
(
3
∗
4
+
5
∗
2
+
1
)
2
=
529
(x_{1}\cdot x_{2}+1)^{2} =(3*4+5*2+1)^{2}=529
(x1⋅x2+1)2=(3∗4+5∗2+1)2=529
[
0.8476
(
x
1
⋅
x
2
)
+
1
]
2
=
[
0.8476
(
3
∗
4
+
5
∗
2
)
+
1
]
2
=
386.01
[0.8476(x_{1}\cdot x_{2})+1]^{2} =[0.8476(3*4+5*2)+1]^{2}=386.01
[0.8476(x1⋅x2)+1]2=[0.8476(3∗4+5∗2)+1]2=386.01
1. 核函数的分类
这里我们明确下SVM使用时,需要包含核函数和松弛因子
1.1 线性核函数(Linear Kernel)
该核函数针对线性可分数据
即:不需要做扩展,只点乘,其他什么都没做
- 1
- 2
K ( x , z ) = x ∙ z K(x,z)=x\bullet z K(x,z)=x∙z
1.2 多项式核函数(Polynomial Kernel)
γ、r、degree扩展阶数 属于超参,需要调参
- 1
K ( x , z ) = ( γ x ∙ z + r ) d K(x,z)=(\gamma x\bullet z+r)^{d} K(x,z)=(γx∙z+r)d
1.3 高斯核函数(Radial Basis Function Kernel)
径向基函数核
γ属于超参,要求大于0,需要调参
常用核函数
- 1
- 2
- 3
K ( x , z ) = e − γ ∥ x − z ∥ 2 K(x,z)=e^{-\gamma\left \| x-z \right \|^{2} } K(x,z)=e−γ∥x−z∥2
1.4 Sigmoid核函数(Sigmoid Kernel)
γ、r属于超参,需要调参
- 1
K ( x , z ) = tanh ( γ x ∙ z + r ) K(x,z)=\tanh (\gamma x\bullet z+r) K(x,z)=tanh(γx∙z+r)
2. 核函数小节
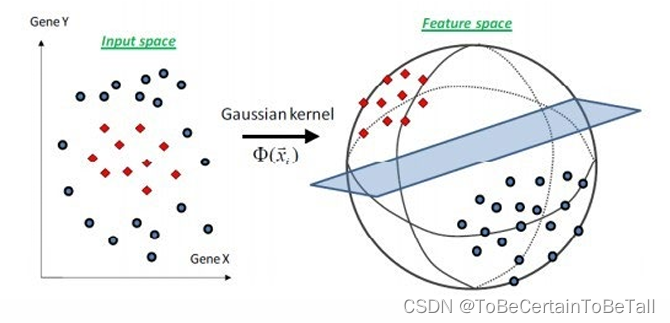
虽然核函数计算输出的结果与二阶扩展的结果一致,但核函数的价值在于,通过在低维上进行计算,从而达到高维上的分类效果,避免了直接在高维空间中的复杂计算
核函数的作用:将非线性可分的数据转换为线性可分数据
核函数可以自定义
核函数必须是正定核函数,任何半正定的函数都可以作为核函数
Gram矩阵是半正定矩阵:
- 1
- 2
- 3
- 4
- 5


