
- 1c语言 指针_c语言指针
- 2【MySQL 系列】在 CentOS 上安装 MySQL
- 3ConstraintLayout使用 笔记总结_layout_constraintbaseline_tobaselineof
- 4PYTHON-arcgis的开发:批量操作字段_arcpy.calculatefield_management 全部换成变量
- 5程序员的编程语言迁移路线:Go语言是最大赢家,Java 还在,Perl 灭亡了,Rust 做的相当不错。_rust perl
- 611月最值得关注的26个热点_krankygeek活动
- 7工厂模式:关于一个工厂的故事_海尔电视机工厂生产海尔电视机csdn
- 8大疆智图、CC生产了多份数据,如何合并为一份在图新地球进行加载_cc生成osgb瓦片怎么合并
- 9【论文精度】生成式预训练模型——BART(Bidirectional and Auto-Regressive Transformers)_bart模型
- 10Nginx实现网站发布_nginx发布网站
从 Elasticsearch 到 Apache Doris,统一日志检索与报表分析,360 企业安全浏览器的数据架构升级实践_apache doris 替换es
赞
踩
导读:随着 360 企业安全浏览器用户规模的不断扩张,浏览器短时间内会产生大量的日志数据。为了提供更好的日志数据服务,360 企业安全浏览器设计了统一运维管理平台,并引入 Apache Doris 替代了 Elasticsearch,实现日志检索与报表分析架构的统一,同时依赖 Doris 优异性能,聚合分析效率呈数量级提升、存储成本下降 60%…为日志数据的可视化和价值发挥提供了坚实的基础。
作者|360 企业安全浏览器 刘子健
近年来,随着网络攻击和数据泄露事件的增加,使得浏览器安全问题变得更加紧迫和严峻。漏洞一旦被利用,一个简单的链接就能达到数据渗透的目的,而传统浏览器在安全性和隐私保护方面存在一些限制,无法满足政企领域对于安全浏览的需求。在此背景下,360企业安全浏览器成为政企客户的首选,以提供统一管理、降本增效、安全可控的解决方案。
在 360 企业安全浏览器强大安全防护能力的背后,对海量安全日志进行深入分析和挖掘是及时发现潜在风险的重要手段。为了提供更好的日志数据服务,360 企业安全浏览器设计了统一运维管理平台,引入 Apache Doris 作为日志分析架构的核心组件,实现数据导入、计算和存储的统一,保障了数据的准确性和一致性,实现了低成本、高效的实时查询能力与同步能力,为日志数据的可视化和价值发挥提供了坚实的基础。
业务需求
随着 360 企业安全浏览器用户规模的不断扩张,浏览器短时间内会产生大量的日志数据,这些数据具有格式多样化、信息维度丰富、时效要求高、数据体量大和隐私安全性高等特点。如果能够对这些数据进行有效分析,可及时发现潜在威胁并提升网站使用体验,因此我们设计了统一运维管理平台。该平台旨在对终端层、应用层和安全层进行监控和分析,并进行多维度分析和可视化展示。
- 在应用层,提供应用总览、访问分析、性能分析、体验分析以及异常分析等功能,可全面了解应用的运行状况,及时发现并解决应用中存在的问题。
- 在终端层,提供终端导览和终端活跃分析功能,及时掌握终端设备状况,从而更好地管理和优化终端性能。
- 在安全层,提供策略预警和策略建议等功能,可及时发现和预防安全风险,提高系统的安全性。
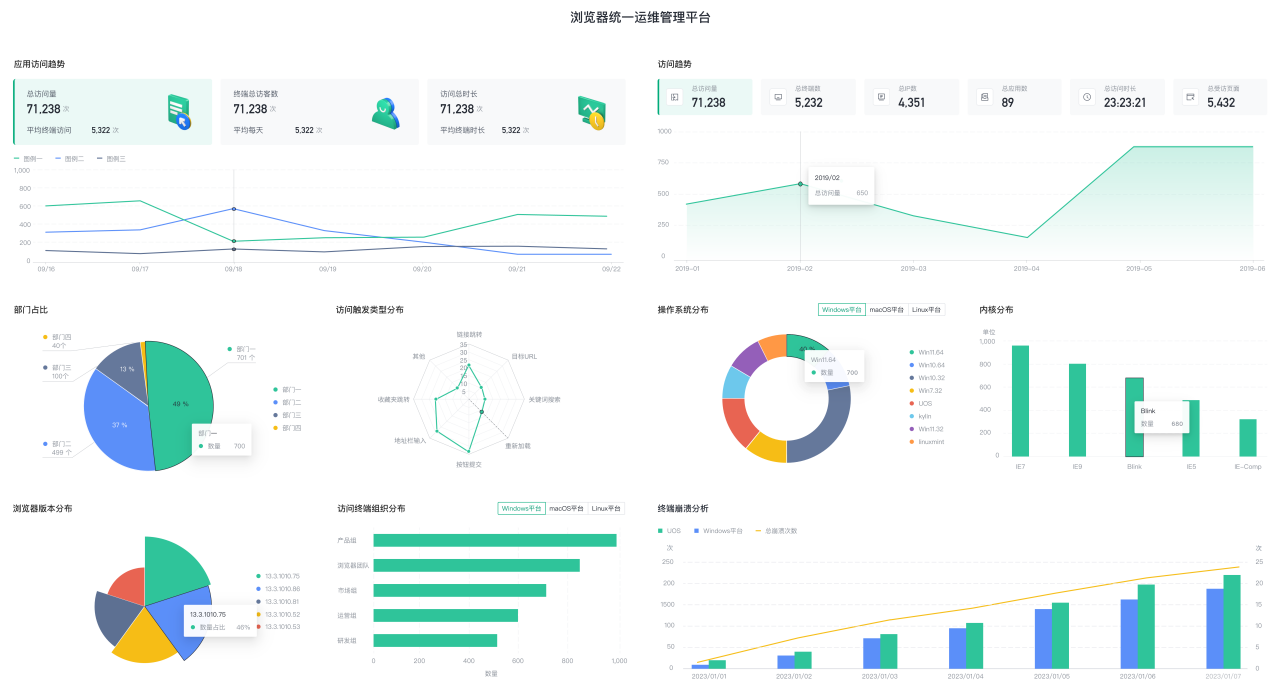
对于政企相关单位而言,浏览器受到攻击可能导致大量隐私数据泄露,给单位和个人带来难以预料的后果。因此,为保障客户信息的安全,统一运维管理平台应具备以下几个能力:
- 实时告警:部分客户对查询性能有较高的要求。比如:实时统计服务异常或系统崩溃的次数,并第一时间反馈给相关负责人解决。
- 导入性能:在业务运行过程中,生成的日志数据会被保存在服务器上。在高并发的情况下,日志数据量非常庞大,因此对导入性能有较高的要求。
- 数据一致性: 数据一致性对任何行业来说都是关键考虑因素,只有在数据一致的基础上进行指标计算,才能确保统计结果的准确性。
- 部署简单:因 360 企业安全浏览器主要为政企提供服务,通常采用私有化部署的方式,这意味着服务和客户端将完全集成在客户本地环境中。这就要求架构要足够精简,在确保在实现功能的同时,尽可能降低部署的复杂度。
架构 1.0 :基于 Elasticsearch 的简洁日志处理架构
为满足统一运维管理平台的要求,我们首先设计了一个简洁的日志处理架构。在该架构中,浏览器客户端发起请求后,经过业务层的服务 API 处理,日志数据在服务应用层进行处理,并最终存储于 MySQL、Elasticsearch 和 Redis 等数据存储系统中。
MySQL 主要存储业务相关数据以及少量计算完成的统计数据,用于管理平台中随查随用,Elasticsearch 主要用于存储日志类数据,以支持数据实时分析和检索需求。Redis 主要用于存储热数据和管理平台的配置信息,以提高接口性能。
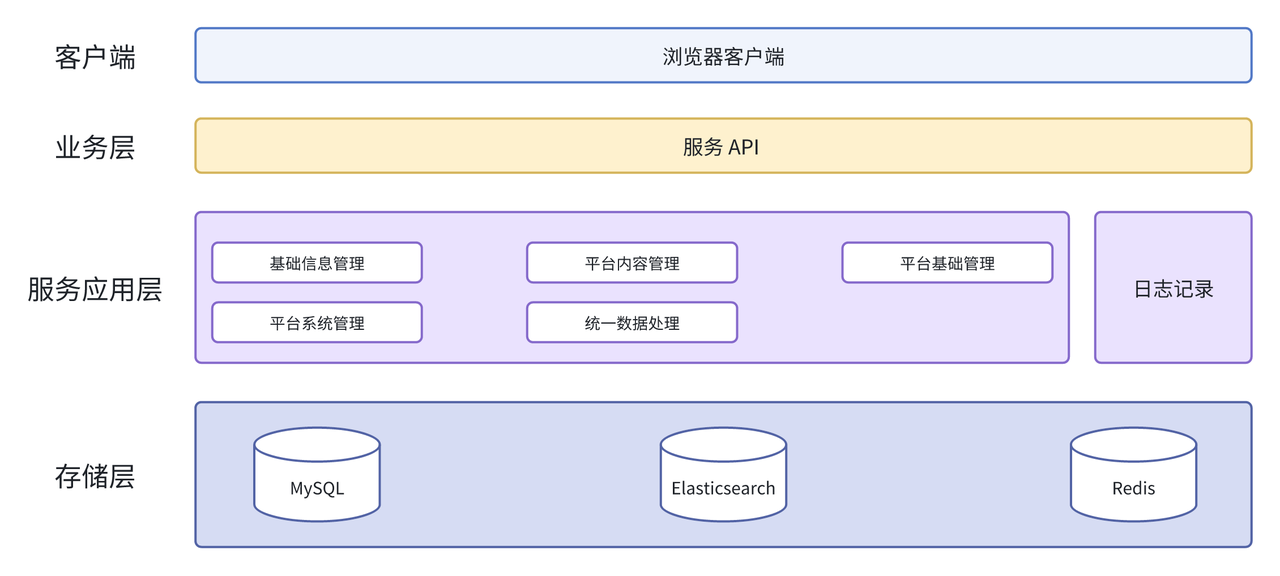
在架构 1.0 使用过程中,我们发现几个痛点问题:
- Elasticsearch 索引不支持变更:Elasticsearch 一旦创建索引,不再支持更改,分词参数和字段类型也无法修改。当提出新的业务需求时,就需要创建新的索引,并需要编写脚本将历史数据迁移至新索引中,这就带来较高的操作和开发成本。
- Elasticsearch 聚合性能差:当执行复杂的聚合查询或存在大量聚合任务时,Elasticsearch 需要为聚合操作分配大量的内存,如果计算资源不足,会造成聚合操作执行时间过长,从而影响查询效率。
架构 1.1:引入 Apache Doris 1.0 版本
据前文可知,Elasticsearch 聚合性能较差,而在实际的使用场景中存在大量需深度聚合的数据表,因此我们决定对架构进行升级改进。在正式升级之前,我们对多个数据分析组件进行调研,并发现 Apache Doris 具备许多特性符合我们的需求,有望解决当前存在的问题。以下列举我们较为关注的特点:
- 支持多种数据模型:支持 Aggregate、Unique、Duplicate 三种数据类型,其中 Aggregate Key 模型能够在快速且准确的写入数据的同时进行数据聚合,即通过提前聚合大幅提升查询性能。
- 采用列式存储:Doris 按列进行数据编码压缩和读取,从而实现极高压缩比,该存储方式也减少了大量非相关数据的扫描,提高 IO 和 CPU 资源的利用率。
- 支持物化视图:既能对原始明细数据进行任意维度的分析,也能快速对固定维度进行分析查询,对于查询性能的提升有显著的效果。
基于这些优势,我们在架构 1.0 的基础上先引入了 Apache Doris 1.0 版本,并将其作为数据存储层。Apache Doris 在架构中主要替代 Elasticsearch 进行实时计算,并将相关统计报表的计算和存储都迁移到 Doris 中来进行,由 Doris 提供统一数据服务。

不仅如此,Apache Doris 的引入也带来了许多性能和效率提升:
- 开发效率提升:相比之前需要编写复杂的 Elasticsearch 聚合代码,现在只需要创建聚合 Key,Doris Aggregate 模型即可完成聚合计算,极大提升了数据开发的效率。
- 数据一致性保证:Doris 提供了统一的数仓服务,数据的导入、计算和存储均可在 Doris 中实现,简化了数据处理的链路和复杂度,对数据一致性的保障起关键作用。
- 查询性能提升:当面对 4000 万条数据的聚合查询时,Elasticsearch 需要 6-7 秒才能返回查询结果,而 Doris 在 1 秒内就能完成查询并返回结果,查询性能显著提升。
除此之外,Apache Doris 在语法结构上也有明显的优势,这为客户在排查问题时提供了极大的便利、缩短了排查时间。为更直观体现其便捷性,我们对 Elasticsearch 和 Apache Doris 的语法结构进行对比。
在 Elasticsearch 中,聚合需要多层 group by,由于其语法与标准 MySQL 协议存在差异,因此语法结构相对复杂。
"aggregations": { "group_day_time": { "aggregations": { "group_urltitle": { "aggregations": { "group_app_id": { "aggregations": { "group_url_host": { "aggregations": { "group_org_id": { "terms": { "field": "org_id", "size": 200000 } } }, "terms": { "field": "url_host", "size": 200000 } } }, "terms": { "field": "app_id", "size": 10000 } } }, "terms": { "field": "urltitle", "size": 100000 } } }, "date_histogram": { "calendar_interval": "day", "field": "day_time" } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
当用户遇到问题时,我们需要向客户发送大量的 Curl 命令来排查问题。然而,对于没有 Elasticsearch 使用经验的用户来说,语法调试难度非常高。
curl -u elastic:elastic 'http://127.0.0.1:9200/user_log*/_search?ignore_unavailable=true&pretty=true' -H 'Content-Type: application/json' -d '{"aggregations":{"group_day_time":{"aggregations":{"group_sysname":{"aggregations":{"group_app_id":{"aggregations":{"group_url_host":{"aggregations":{"group_org_id":{"terms":{"field":"org_id","size":200000}}},"terms":{"field":"url_host","size":200000}}},"terms":{"field":"app_id","size":10000}}},"terms":{"field":"sysname","size":100000}}},"date_histogram":{"calendar_interval":"day","field":"day_time"}}},"query":{"bool":{"filter":[{"range":{"day_time":{"from":"2022-06-02T00:00:00+08:00","include_lower":true,"include_upper":true,"to":null}}},{"range":{"day_time":{"from":null,"include_lower":true,"include_upper":false,"to":"2022-06-03T00:00:00+08:00"}}}]}}}'
- 1
**引入 Apache Doris 后,**在创建表时可以使用 Aggregate Key 模型来定义聚合条件。且 Apache Doris 支持标准 MySQL ,不仅语法更加简洁、查询也更加方便,如出现问题,只要熟悉 MySQL 的基本语法,便可以快速进行问题排查。
CREATE TABLE user_log ( day_time datetime DEFAULT NULL COMMENT ‘时间', org_id int(10) DEFAULT ‘0’ COMMENT ‘组织id', app_id int(10) DEFAULT ‘0’ COMMENT ‘应用id', url_host varchar(255) DEFAULT NULL COMMENT 'url地址‘, urltitle varchar(255) DEFAULT '' COMMENT 'title', pv_count BIGINT SUM DEFAULT "0" COMMENT "总数" ) Aggregate KEY(day_time,org_id,app_id, url_host, urltitle) PARTITION BY RANGE (day_time) () DISTRIBUTED BY HASH(day_time) BUCKETS 10 SELECT day_time,org_id,app_id,url_host,urltitle,sum(pv_count) as pv FROM user_log WHERE day_time >= "2022-06-02" and day_time <= "2022-06-03" GROUP BY day_time,org_id,app_id,url_host,urltitle ORDER BY uv desc;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
而在架构 1.1 版本中,我们仍然面临一些挑战和问题:
- Bitmap 问题:在处理大规模数据时,对于字符串类型基数很高的数据,如果直接使用 Bitmap ,计算性能无法很好满足。
- 数据准确性问题:当对 75 万基础数据测试时,Bitmap 哈希冲突可能导致数据准确性问题。
- 存储空间:由于 Elasticsearch 还未被 Apache Doris 全部替换,目前系统仍存在存储资源消耗较大的问题。
架构 2.0 :引入 Apache Doris 2.0,全面替代 Elasticsearch
针对上述问题,我们积极寻找下一步的解决方案。在与 Apache Doris 社区技术同学沟通过程中,我们得知 Apache Doris 2.0 版本在日志分析场景上有了全面加强:
- 支持 JOSN 格式:Apache Doris 2.0 支持 JSON 格式,在我们的数据中有大量采用 JSON 格式的数据,该能力使我们能够更方便地进行数据存储。
- 支持部分列更新:2.0 版本支持了部分列更新功能,无需对整个数据集进行更新,这种精确的更新方式大大降低了计算资源的消耗,提高了数据更新效率。
- 支持倒排索引:2.0 版本支持倒排索引,可以满足字符串类型的全文检索和普通数值/日期等类型的等值、范围检索,更加符合日志数据分析的场景的查询需求。
基于此,我们引入了 Apache Doris 2.0 版本,实现了从架构 1.1 到架构 2.0 的升级。在架构 2.0 中,我们对整体架构进行了调整, 以区分日志服务、基础服务与其他服务,这也使得系统更加清晰和易于管理。
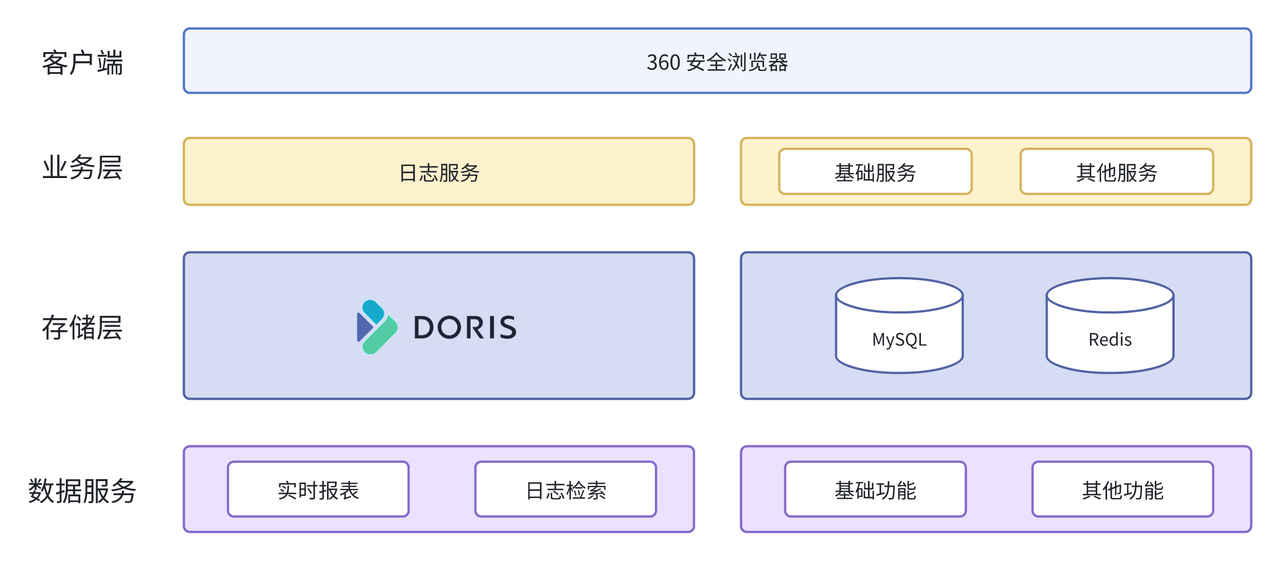
在新架构中,我们使用 Apache Doris 完全替代了 Elasticsearch ,由 Apache Doris 统一提供日志检索和实时报表服务。此外,我们还对报表导入方式进行了改进,早期的做法是通过 Insert Into 拼接 MySQL 的方式进行导入,而新架构中引入了 FileBeat 工具,使报表数据的导入和导出更加高效便捷。
具体数据导入流程为:当用户在浏览器中访问应用网址时,需要采集的信息会被记录在本地,当采集时间或数量达到设定阈值时,这些信息将通过接口上报给日志服务。日志服务的主要任务是对数据进行清洗和填充,以补充浏览器空缺数据,并生成一条 JSON 存到服务器的日志文件。当轮询脚本触发时,将对日志文件进行读取,数据通过 Stream Load 将数据同步到 Doris 中。
01 简单易用,提升开发效率
Apache Doris 学习成本低、轻松上手。Apache Doris 兼容 MySQL 协议,支持使用标准 SQL 语言进行数据查询和操作,使得开发人员可以方便地进行复杂的数据查询和聚合操作。相比之下,Elasticsearch 的 DSL 是一种基于 JSON 的查询语言,对于不熟悉 DSL 开发人员来说,完全掌握该语法需要一定的学习曲线,具有较高的学习和使用门槛。
我们通过以下示例代码来展示使用 GOM 实现 Doris 查询功能的代码实现。从代码示例可知,对于熟悉代码管理、代码规范、代码质量和后期维护等方面的人来说,这种写法非常方便。对于新加入的同事来说,进行代码审查也变得非常容易,相较于以前的 Elasticsearch ,使用 Apache Doris 可以节省大量的开发时间。
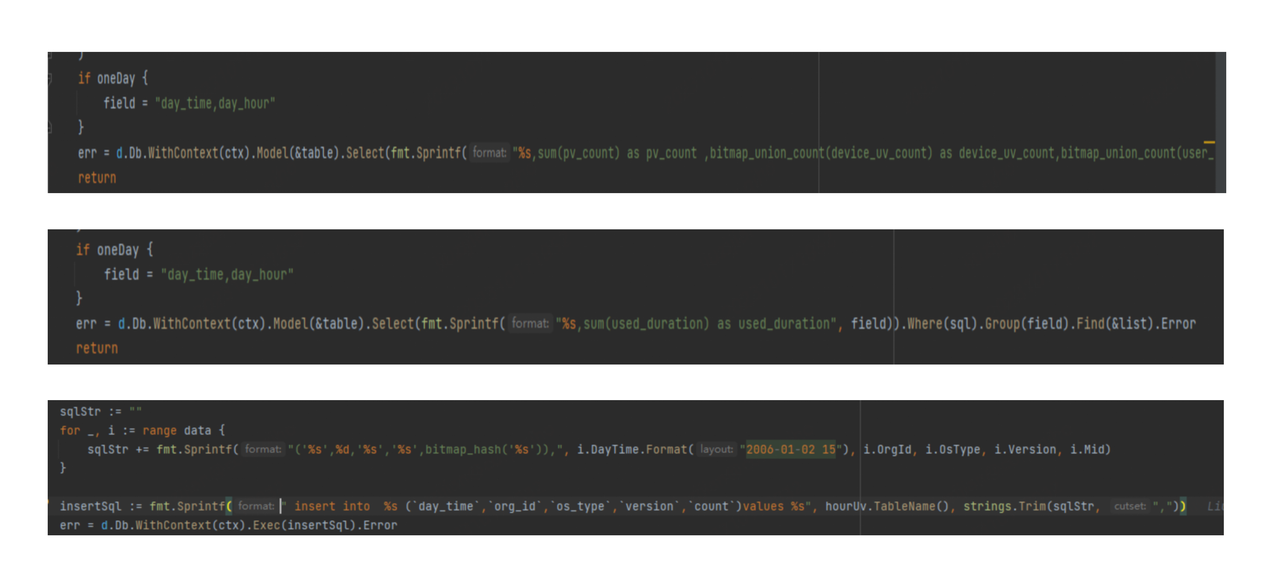
02 合理进行表设计,满足查询秒级响应
在表设计中,我们主要使用了 Aggregate Key 聚合模型和 Duplicate Key 明细模型。 聚合模型用于统计浏览器相关指标,如用户 PV(页面访问量)和 UV(独立访客数)以及应用访问 PV 和 UV 等数据;明细模型主要用于存储日志数据,以便进行用户或设备的留存分析。
在实际的应用中,大部分报表选择聚合模型进行实时计算,SUM 和 BITMAP 为常用的聚合计算,其中,SUM 约有 100+ 个聚合维度,BITMAP 约有 20-30 个维度,因涉及维度较多,我们将它们分布在不同的表中。小部分报表采用明细模型,我们也在明细模型上建了 Rollup 来提高查询速度。
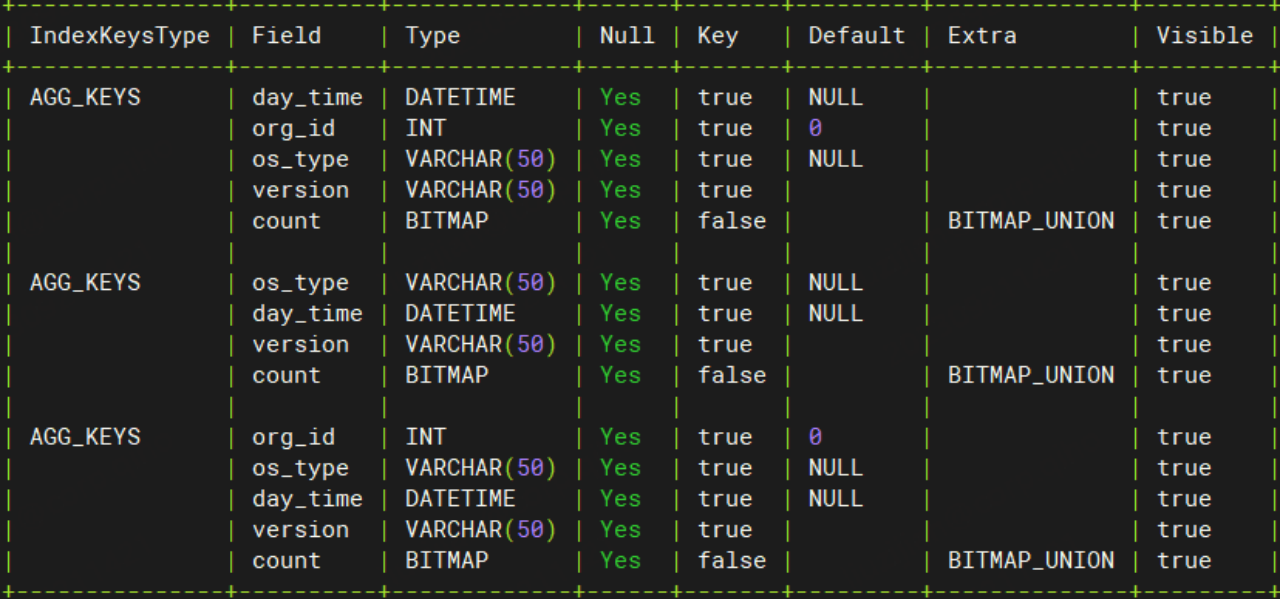
具体字段设置为:
- UV 采用 BITMAP 聚合模型,聚合函数
BITMAP_UNION - PV 采用 BIGINT 类型,聚合函数
SUM - 留存:
BITMAP_INTERSECT - 众数:TOPN
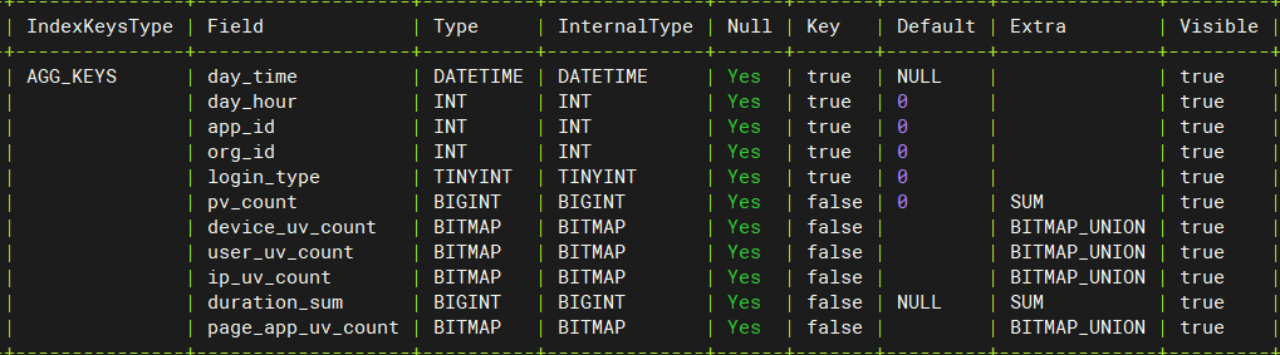
SUM 性能评估
如上所述,我们在表创建过程中广泛使用了 Bitmap 和 SUM 函数。为了评估 SUM 函数的性能,我们对一张约有 54 亿行数据的表进行测试,并在创建 Rollup 后进行查询,**结果显示查询耗时为 0.32 秒,**这表明 SUM 函数在处理大规模数据里表现出良好的性能,满足我们对查询时延的要求。
select count(*) from testorg; # 5400179000
select org_id,sum(app_pv_count) from org_stats where os_type="windows" and day_time > "2023-07-01" and org_id >0 group by org_id; # 0.32s
- 1
- 2
- 3

Bitmap 性能评估
对于 Bitmap 而言,Bitmap 的长度相对于数据行数更为重要。随着 Bitmap 数据量的增大,Bitmap Union Count 的执行速度可能变慢。
为验证其性能,我们对一张包含 9 万行数据的表进行 IP 测试,IP 数量始终保持在 75 万以上,即每个 Bitmap 的长度大于等于 75 万。在这个 9 万*75 万的数据集上,我们进行 Bitmap Union Count 计算,将 IP 转换为整数类型,查询时间约为 0.5 秒,总体而言查询性能较好,符合性能要求。
select count(*) from testlog; # 90000
select app_id,day_time,bitmap_union_count(ip_pv_count) from test group by app_id,day_time ; #0.5s
- 1
- 2
- 3

03 相较 Elasticseach,存储成本降低 60%
在引入 Apache Doris 之后,我们对 Doris 和 Elasticseach 的存储空间占用进行了对比。
我们以一天数据量为例进行测试,大约 606 GB 的 JSON 日志数据。当我们将这些数据存储到 Doris 中时,其所占用存储空间仅为 170 GB,压缩比达到 1:3.6。
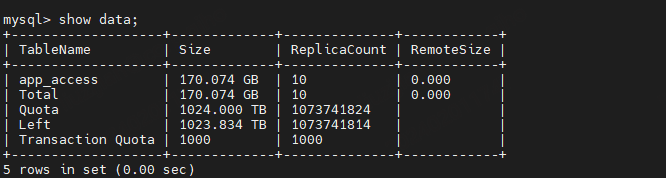
与此相比,相同规模的数据存储到 Elasticsearch 中则需要 391 GB 的存储空间,远超过 Apache Doris 所需的空间,升级后存储成本降低 60%。
收益总结
我们将系统架构从 Elasticsearch 升级为 Apache Doris 之后,具体取得的收益如下:
- 将日志检索和报表分析统一到一个系统中,Doris 2.0 版本在增加倒排索引后,能同时满足这两个场景,从而缩短了数据处理的链路和复杂度,显著提高了数据处理的效率。
- 聚合分析性能得到数量级的提升,之前在 Elasticseach 中需要近 10 秒才能完成聚合查询,而在 Doris 中不到 1 秒就能完成,聚合分析效率至少提升 100%。
- Doris 提供了高效的数据压缩效率,相较于 Elasticseach,同一份数据的存储资源成本降低了 60%。
- Doris SQL 相比 Elasticseach DSL 更加简单易用,能够大幅提升开发效率和问题排查的效率。
不仅如此,Apache Doris 的引入帮助我们实现了运营可视化管理,提供了浏览器多种指标的实时监控,以指导业务部门下一步动作:
- 在安全方面,当崩溃次数达到设定阈值时,系统会通过邮件通知相关人员,以便排查浏览器崩溃的原因。还可对登录次数进行统计,有效监测是否存在外部人员试图攻击接口。
- 在绩效统计方面,可对应用访问数据进行统计,以帮助我们评估工作情况,从而更好地安排工作。
- 优化流量损耗和磁盘占用:通过对页面中 JS、CSS、Image 等资源的统计,可有效地发现访问流量和资源大小并进行优化,以减少流量损耗和磁盘空间使用,从而实现降本提效。
- 提供业务系统健康报告:可准确监测应用 Web 页面所引用的资源、资源加载时长以及异常情况等关键信息,并根据这些信息生成应用健康报告,基于报告能够帮助企业完成业务系统的优化。
未来规划
由于 360 企业安全浏览器面向企业提供服务,未来我们着重关注并探索以下方向,以更好地满足客户的需求。
- 冷热数据分离:冷热数据分离能够在降低成本的同时提高效率,未来我们计划将客户的冷数据存储到 S3 等存储介质,将热数据存储在相应的数据磁盘,以提高存储空间的利用率。
- Doris Manager 部署集成:未来我们计划集成 Doris Manager ,以便客户能够直观便捷地排查和发现问题,监控集群的使用情况。

