
热门标签
热门文章
- 1无线传感器网络:物理层设计_无线通信物理层设计有哪些
- 2Django+Jquery+Bootstrap Modal+Iframe使用异步机制上传文件实现方法_django+bootstrap+jquery做一个上报数据网站
- 3Linux下 TCP 连接限制如何解除,解决socket高并发连接数限制,tcp默认1024个连接_socket 限制
- 4ConstraintLayout使用_constraintlayout root宽度0.7
- 5躺平不可取,躺赢不可能,最好的时代躺平,是最差的生存策略_躺赢不可能 躺平不可取
- 6python脚本自动合并手机端B站视频缓存_自动整合手机文件视频
- 7快速了解小程序中的点击事件bindtap和catchtap的区别?_小程序 点击列表中的单元格 bindtap
- 8Unity【Dynamic Bone】- 关于人物模型头发、衣物等细节的处理
- 9YDOOK:Android Studio: Gradle build.gradle 文件最初状态内容代码设置_build.gradle(my application)初始代码
- 10java实现超级玛丽游戏(附完整源码)_超级玛丽java源码
当前位置: article > 正文
CV-人脸识别03-疲劳检测_疲劳面部检测数据集
作者:盐析白兔 | 2024-03-14 23:26:22
赞
踩
疲劳面部检测数据集
1. 疲劳状态检测
1.1 根据嘴的状态检测
使用基于Haar特征的Adaboost算法训练分类器,实现嘴的正常状态和张嘴状态的区分,再针对区分结果实现二次处理,计算嘴的张开程度,判定是否处于疲劳状态
处理方法:
选取打哈欠及各种张嘴时的嘴部图像为正样本,选取脸部其他部分图像为负样本,正样本和负样本图像均从网上搜索得到,正样本图像250张,大小统一缩放为24×24,负样本图像550张。
1.2 驾驶员疲劳驾驶检测系统主要内容
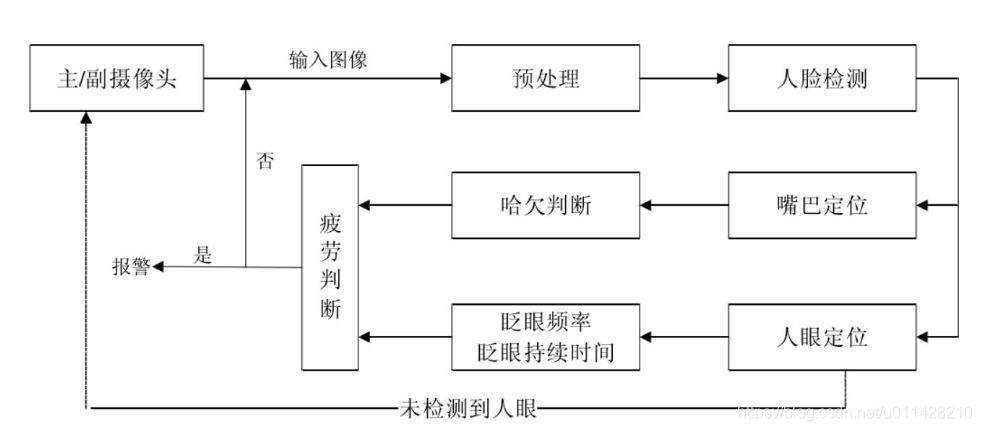
1.2.1 双眼位置精确定位
一般情况下,是在定位人眼之前先检测并定位出人脸,然后在人脸区域范围内进行人眼的检测和定位,这样可以有效减少算法在图像内搜素的面积,且可排除图像内的类人眼物体。
1.2.2 双眼位置跟踪
在完成初始的人眼定位后,如果仍按照常规途径实现每一帧图像的人眼位置精确定位,那么整个过程的计算量和计算复杂度都较高,这样无法满足系统实时性要求;而且虽然大多数情况下采集设备能够得到包含人眼的图像,但是,也不排除因为故障、驾驶员头部姿态等因素导致无法按初始时的人眼定位算法实现双眼的检测和定位。因此,为了保证算法的效率和准确性,应当在完成双眼位置的定位之后随即采用跟踪算法来完成对人眼的后续定位和跟踪,这样既能节省时间,还可以保证较复杂环境下人眼位置的准确定位
1.2.3 双眼状态信息分析
一旦实现驾驶员双眼的准确跟踪,就能够获得每一时刻驾驶员双眼的位置、张开幅度等信息,通过这些信息的统计及分析,结合多个具有代表性的疲劳状态评价指标建立疲劳状态评价模型,就能实现任意时刻对驾驶员精神状态的判断。
根据眼睛纵横比判断眼睛时张开还是闭合

嘴的判定和眼睛判定相同
2.人脸校准
人脸校准的方法及目的:
在做人脸识别的时候,前期的数据处理过程中可能会遇到一个问题,即将人脸从不同尺寸的图像中截取出来,再进行“对齐”操作。这样可以使每一个截取的人脸中的眼睛等位置处于同一位置,会对后面的识别算法起到一定的优化作用。
2.1 人脸数据集
- LFW人脸数据库(LFWfacedatabase)是在各类人脸检测和识别算法的研究中经常用到的数据集。
该数据集由15位志愿者组成,每位志愿者的具有表情,姿态和光照因素的人脸图像共11张。整个数据集有1653张图片。每张图片大小为100*100。整个数据集非常小,图片信息也较为简单。Yale人脸数据的扩展数据集TheextendedYaleFaceDatabaseB共有16178张图像。由28位志愿者组成,每位志愿者共有9中姿态,另外有64种不同光照。该数据集包括人脸检测对齐好的数据集和未对齐的数据集 - Yale人脸数据库是用作限制性环境下测试人脸识别算法的经典数据集
数据集中人脸数据已经标定,因此这并不是传统意义上的人脸识别任务,而是一个简单的图像多分类问题。另外,每个人包含了在不同表情、光照下的人脸图像,这就要求我们提取的图像特征要具有光照不敏感性,能够很好得体现人脸的轮廓信息 - FERET数据库同样是用来检测限制性环境下人脸相关算法的数据集
由200多位志愿者提供的不同姿态和表情的图像组成。该数据集最开始由美国国防部的CounterdrugTechnologyTransferProgram(CTTP)发起了一个人脸识别技术(FaceRecognitionTechnology简称FERET)工程创建的,现在已经成为人脸识别领域应用最多的人脸数据集。部分数据如图所示。③人脸校准
2.2 人脸校准的实现步骤
- 计算直线距离及倾斜角度
- 根据找到的角度旋转图片
- 寻找旋转后眼睛的位置
- 根据眼睛坐标找到包含面部的框的宽度和高度
- 裁剪图片
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/237782
推荐阅读
相关标签

