
- 1SQL查找处理Tab、空格、回车等特殊字符_sql语句中查带有回车的数据
- 2linux文件从考到另一个机子上,Linux如何拷贝文件到其他用户?
- 3为什么鸿蒙内核是安卓,鸿蒙系统发布,为什么有人说其为安卓换壳?
- 4本科论文查重会检测AI辅写疑似度吗?从七个方面为你解答_国内论文查ai率吗
- 5【Linux】--- Linux编译器-gcc/g++、调试器-gdb、项目自动化构建工具-make/Makefile 使用
- 6Android Studio 新建文件时没有java文件解决_android studio新建没有java文件
- 7Django中缓存的使用_django cache
- 8使用嵌入式Linux和Qt编程实现数码相框的设计_qt相框
- 9支付宝沙箱模拟支付过程_支付宝沙箱环境支付下单
- 10群晖部署私人聊天服务器Vocechat并结合内网穿透实现公网远程访问_群晖搭建聊天平台
Elasticsearch_$.data.status 等于 sold | assertionerror: expected '
赞
踩
参照狂神说java和尚硅谷的ES视频以及官网和相关网上资料和自己个人学习心得整理
Elasticsearch
文档地址
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/_search_apis.html
Elasticsearch是什么
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
历史

ELK技术:elasticsearch+logstash+kibana
Lucene
Luncene是一套信息检索工具包!jar包!不包含搜索引擎系统
包含的:索引结构!读写索引的工具!排序,搜索规则…工具类!
Luncene和Elasticsearch关系:
Elasticsearch是基于Luncene做了一些封装和增强
ES和solr的差别
ES简介

Solr简介

Lucene简介

ES和Solr对比
-
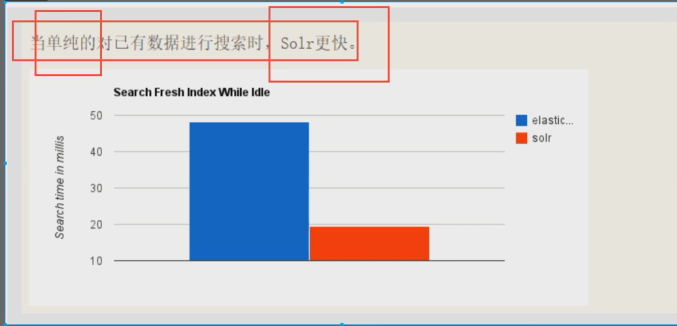
Solr在查询死数据时,速度相对Es更快一些。但是输入如果是实时改变的,solr的查询速度会降低很多 ES的查询的效率基本没有变化
-
Solr搭建基于需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入
-
solr文档在国内比较少,ES则很健全
-
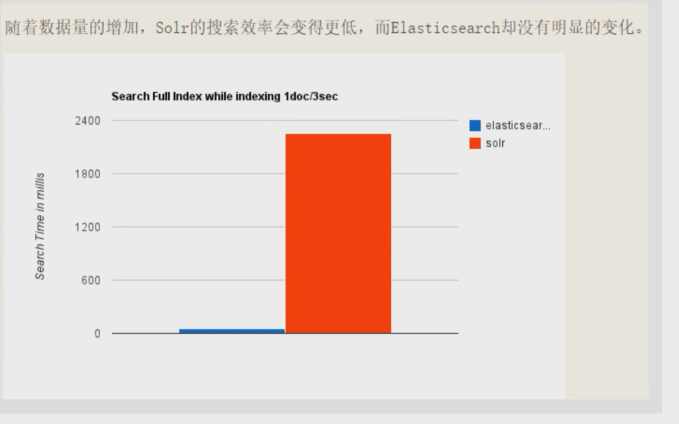
ES对现在云计算和大数据支持的特别好
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JP3jILEy-1632227343469)(E:\笔记\1md日常学习笔记\Elasticsearch.assets\image-20201215110026868.png)]
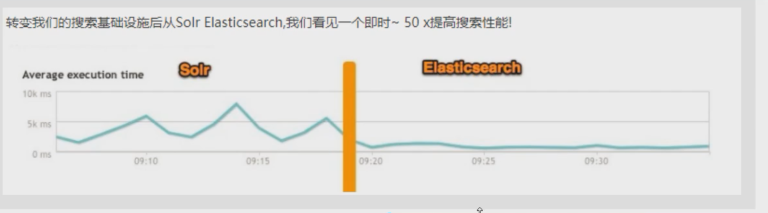
ElasticSearch vs Solr总结
- es基本是开箱即用,非常简单。Solr安装略微负责一点
- Solr利用Zookeeper进行分布式管理,而ES自身带有分布式协调管理功能
- Solr支持更多格式的数据,比如JSON、xml、CSV,而ES仅支持json文件格式
- Solr官方提供的功能更多,而ES本身更注重于核心功能,高级功能多有第三方插件提供、例如图形化界面需要kibana友好支撑
- Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用
- ES建立索引快(即查询慢),即实时查询快,用于facebook新浪等搜索
- Solr是传统搜索应用的有力解决方案,但是ElasticSearch更实用与新兴的实时搜索应用
- Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而ES相对开发维护者较少,更新太快,学习使用成本较高
TF/IDF
词频和逆词频
TF:某个词出现越多,表示它约重要。比如某篇新闻中,“剑术”出现了5次,“电视”出现了1次,很可能这是一个剑术赛事报道。
如果这篇新闻中,“中国”和“剑术”出现的次数一样多,是不是表示两者同等重要呢?答案是否定的,因为中国这个词很常见,它难以表达文档的特性。而剑术很少见,更能表达文章的特性。
某个词越少见,就越能表达一篇文章的特性,反之则越不能。像“的”、“了”这些词,在所有文档中出现的频率都特别高,以至于失去了表达文章特性的意义。人们干脆称它们为“停用词”,直接从统计中忽略掉
计算公式tf(t in d) = √frequency , 即 (某个词t在文档d中出现的次数) 的 平方跟
IDF
即逆文档频率,它是一个表达词语重要性的指标。
作用场景
国外
(1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,区,最近3年,每年消费金额呈现*100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化国内*
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
ES安装
访问地址
http://localhost:9200/
得到
{ "name" : "LAPTOP-6DDH57C5", "cluster_name" : "elasticsearch", #集群名字 "cluster_uuid" : "o59G-1wKQyeh8-6-5RIBqg", #集群里面的唯一的uuid "version" : { "number" : "7.6.1", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b", "build_date" : "2020-02-29T00:15:25.529771Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
安装可视化界面es : head插件
-
安装
-
启动
-
cnpm install #安装依赖 npm run start- 1
- 2
-
连接发现跨域了 去配置elasticsearch.yml
http.cors.enabled: true http.cors.allow-origin: "*"- 1
- 2
5、重启es服务
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QvbTgpjg-1632227343474)(E:\笔记\1md日常学习笔记\Elasticsearch.assets\image-20201215115220886.png)]
初学 时候的理解
注意:这个head我们就把它当做数据展示工具,后面我们所有的查询都是用kibana
了解ELK

收集清洗数据–>搜索,存储–>kibana
安装Kibana

kibana版本要和ES版本一致
配置kibana中文界面 去yml配置

ES核心概念
1、索引
2、字段类型(mapping)
3、文档(documents)
TF:在倒排索引文档里面 内容里面出现的次数 比如说"我是是是哈哈’’ 那么是的TF就是3
POS:在倒排索引里面 出现的位置
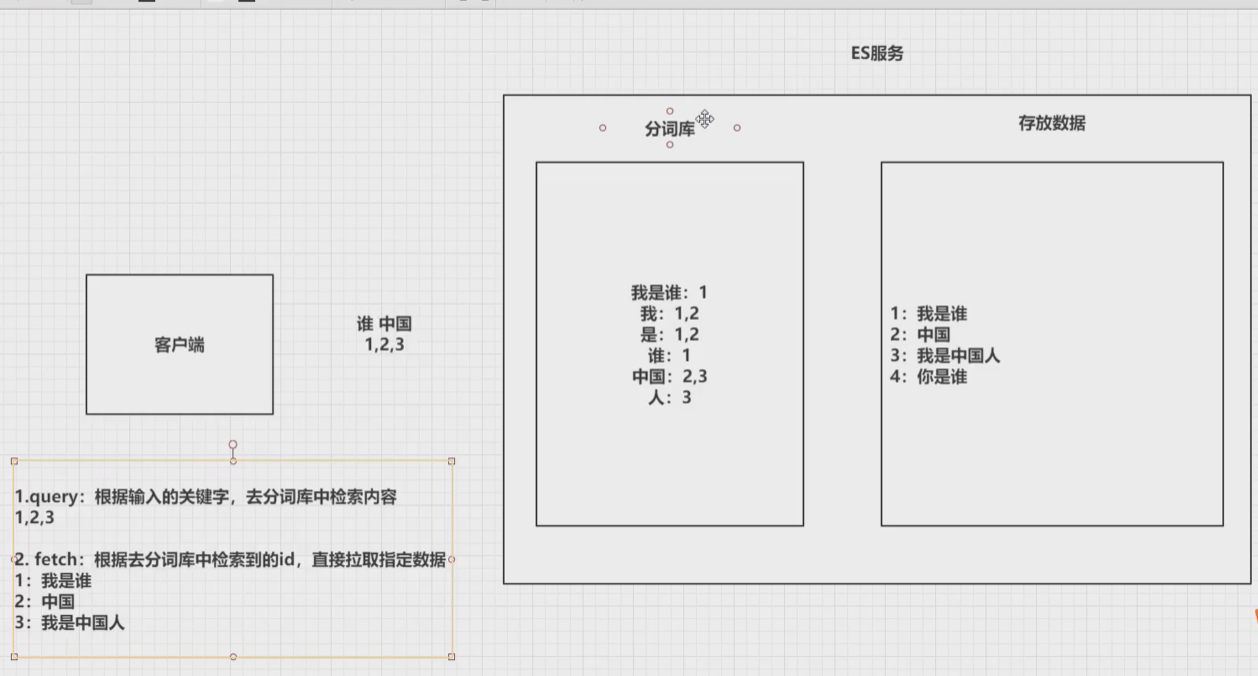
es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?
集群、节点、索引、类型、文档、分片、映射是什么?
elasticsearch是面向文档,关系行数据库和elasticsearch客观的对比(一切都是json)
| Relational DB | ES |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types (*7.0还在使用 8.0准备弃用了) |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)
物理设计:
elasticsearch在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器之间迁移
一个人就是一个集群!默认的集群名字就是elasticsearch
逻辑设计
一个索引类型中,包含多个文档,比如说文档1,文档2.当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引-》类型-》文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是一个字符串
ES的备份分片默认不会帮助检索数据,当ES检索压力特别大的时候,备份分片才会帮助检索数据。备份的分片必须放在不同的服务器中
文档
就是我们的一条条数据
user
1 zhangsan 18
2 li 2
- 1
- 2
- 3

类型
和关系型数据库里面的差不多

索引
可以类比成数据库


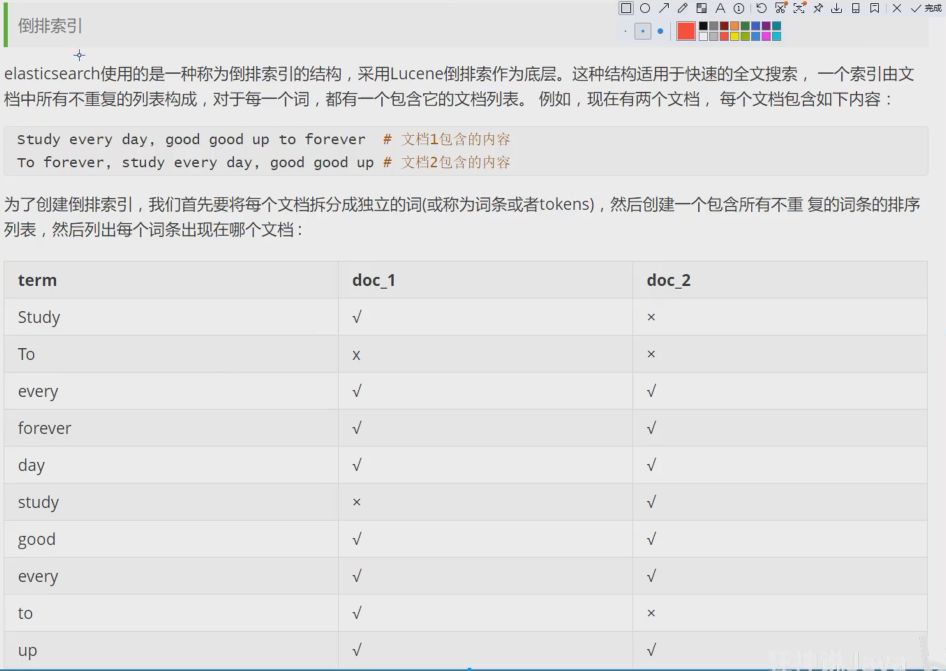
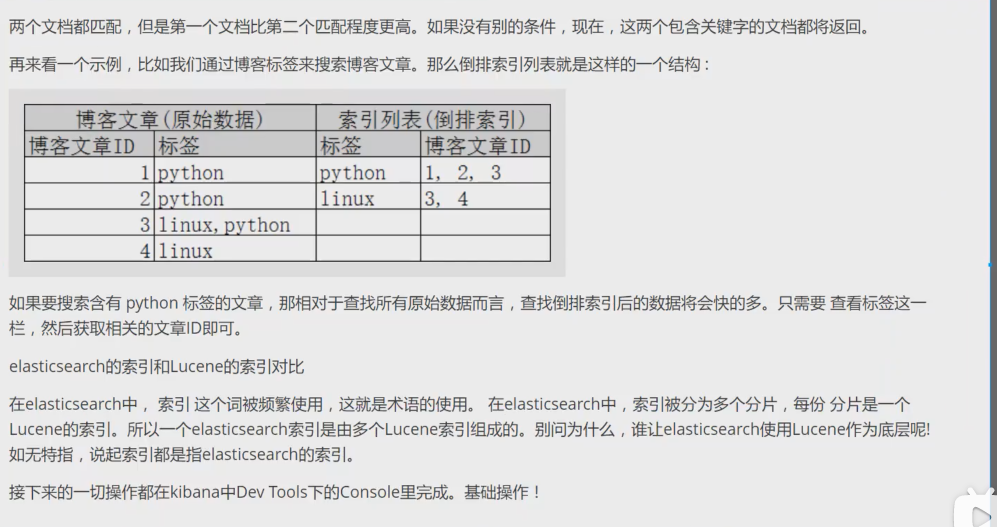
上图是一个有3个节点的集群,可以看到主分片对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。(倒排索引:)
倒排索引
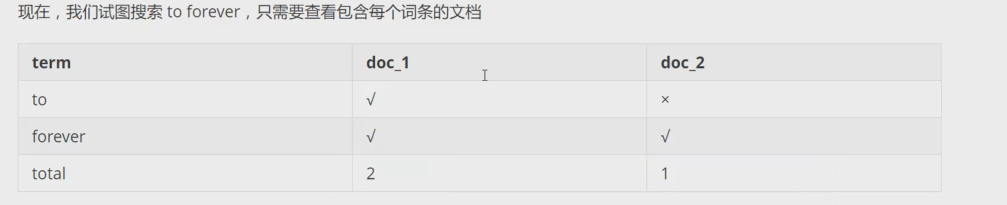
具体的例子

为什么不建议使用type了
1、为何要去除 type 的概念?
答: 因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。
但是,其搜索引擎是基于 Lucene 的,这种 “基因”决定了 type 是多余的。 Lucene 的全文检索功能之所以快,是因为 倒序索引 的存在。
而这种 倒序索引 的生成是基于 index 的,而并非 type。多个type 反而会减慢搜索的速度。
为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(去除 type)也是无可厚非的,也是值得的。
所以,Why not?!
2、为何不是在 6.X 版本开始就直接去除 type,而是要逐步去除type?
答:因为历史原因,前期 Elasticsearch 支持一个 index 下存在多个 type的,而且,有很多项目在使用 Elasticsearch 作为数据库。
如果直接去除 type 的概念,不仅是很多应用 Elasticsearch 的项目将面临 业务、功能和代码的大改,
而且对于 Elasticsearch 官方来说,也是一个巨大的挑战(很多涉及到 type 源码是要修改的)。
所以,权衡利弊,采取逐步过渡的方式,最终,推迟到 7.X 版本才完成 “去除 type” 这个 革命性的变革。
分片(Shards)
ES 支持 PB 级全文搜索,当索引上的数据量太大的时候,ES 通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个分片。
这类似于 MySQL 的分库分表,只不过 MySQL 分库分表需要借助第三方组件而 ES 内部自身实现了此功能。
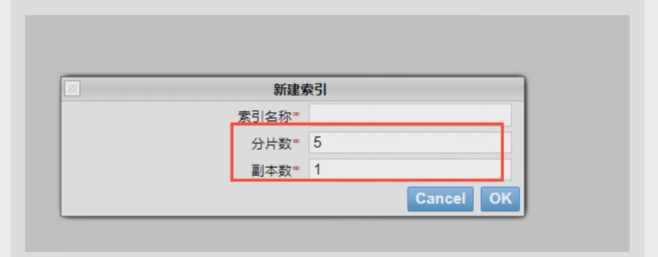
在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,所以在创建索引的时候需要指定分片的数量,并且分片的数量一旦确定就不能修改。
分片的数量和下面介绍的副本数量都是可以通过创建索引时的 Settings 来配置,ES 默认为一个索引创建 5 个主分片, 并分别为每个分片创建一个副本。

ES 通过分片的功能使得索引在规模上和性能上都得到提升,每个分片都是 Lucene 中的一个索引文件,每个分片必须有一个主分片和零到多个副本。
副本(Replicas)
副本就是对分片的 Copy,每个主分片都有一个或多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。
主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 N-1(其中 N 为节点数)。
对文档的新建、索引和删除请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片。
ES 为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,ES 通过乐观锁的方式控制**,每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。**
一旦所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
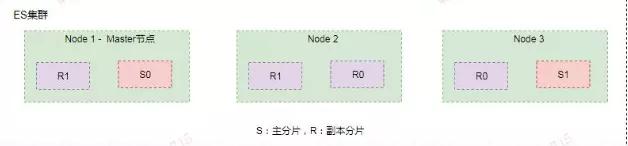
从上图可以看出为了达到高可用,Master 节点会避免将主分片和副本分片放在同一个节点上。
假设这时节点 Node1 服务宕机了或者网络不可用了,那么主节点上主分片 S0 也就不可用了。
幸运的是还存在另外两个节点能正常工作,这时 ES 会重新选举新的主节点,而且这两个节点上存在我们所需要的 S0 的所有数据。
我们会将 S0 的副本分片提升为主分片,这个提升主分片的过程是瞬间发生的。此时集群的状态将会为 Yellow。
为什么我们集群状态是 Yellow 而不是 Green 呢?虽然我们拥有所有的 2 个主分片,但是同时设置了每个主分片需要对应两份副本分片,而此时只存在一份副本分片。所以集群不能为 Green 的状态。0
如果我们同样关闭了 Node2 ,我们的程序依然可以保持在不丢失任何数据的情况下运行,因为 Node3 为每一个分片都保留着一份副本。
如果我们重新启动 Node1 ,集群可以将缺失的副本分片再次进行分配,那么集群的状态又将恢复到原来的正常状态。
如果 Node1 依然拥有着之前的分片,它将尝试去重用它们,只不过这时 Node1 节点上的分片不再是主分片而是副本分片了,如果期间有更改的数据只需要从主分片上复制修改的数据文件即可。
小结:
将数据分片是为了提高可处理数据的容量和易于进行水平扩展,为分片做副本是为了提高集群的稳定性和提高并发量。
副本是乘法,越多消耗越大,但也越保险。分片是除法,分片越多,单分片数据就越少也越分散。
副本越多,集群的可用性就越高,但是由于每个分片都相当于一个 Lucene 的索引文件,会占用一定的文件句柄、内存及 CPU。
并且分片间的数据同步也会占用一定的网络带宽,所以索引的分片数和副本数也不是越多越好。
映射(Mapping)
映射是用于定义 ES 对索引中字段的存储类型、分词方式和是否存储等信息,就像数据库中的 Schema ,描述了文档可能具有的字段或属性、每个字段的数据类型。
只不过关系型数据库建表时必须指定字段类型,而 ES 对于字段类型可以不指定然后动态对字段类型猜测,也可以在创建索引时具体指定字段的类型。
对字段类型根据数据格式自动识别的映射称之为动态映射(Dynamic Mapping),我们创建索引时具体定义字段类型的映射称之为静态映射或显示映射(Explicit Mapping)。
在讲解动态映射和静态映射的使用前,我们先来了解下 ES 中的数据有哪些字段类型?之后我们再讲解为什么我们创建索引时需要建立静态映射而不使用动态映射。
ES(v6.8)中字段数据类型主要有以下几类:

Text 用于索引全文值的字段,例如电子邮件正文或产品说明。这些字段是被分词的,它们通过分词器传递 ,以在被索引之前将字符串转换为单个术语的列表。
分析过程允许 Elasticsearch 搜索单个单词中每个完整的文本字段。文本字段不用于排序,很少用于聚合。
Keyword 用于索引结构化内容的字段,例如电子邮件地址,主机名,状态代码,邮政编码或标签。它们通常用于过滤,排序,和聚合。Keyword 字段只能按其确切值进行搜索。
通过对字段类型的了解我们知道有些字段需要明确定义的,例如某个字段是 Text 类型还是 Keyword 类型差别是很大的,时间字段也许我们需要指定它的时间格式,还有一些字段我们需要指定特定的分词器等等。
如果采用动态映射是不能精确做到这些的,自动识别常常会与我们期望的有些差异。
所以创建索引的时候一个完整的格式应该是指定分片和副本数以及 Mapping 的定义,如下:

对于已经存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移。
match和term区别
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term。
关于一个索引下是否能有多个type
从6.0开始一个索引下不允许有多个type,而7.0开始type已经是被废弃了的、8就完全弃用了。
所以如果是用6.0版本以后的es 则一个索引下不能有多个type
相关性
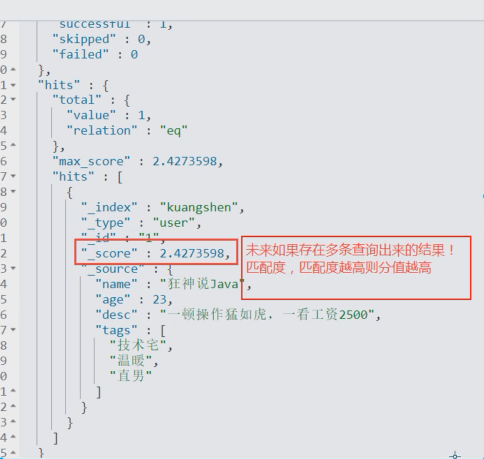
我们曾经讲过,默认情况下,返回结果是按相关性倒序排列的。 但是什么是相关性? 相关性如何计算?
每个文档都有相关性评分,用一个正浮点数字段 _score 来表示 。 _score 的评分越高,相关性越高。
查询语句会为每个文档生成一个 _score 字段。评分的计算方式取决于查询类型 不同的查询语句用于不同的目的: fuzzy 查询会计算与关键词的拼写相似程度,terms 查询会计算 找到的内容与关键词组成部分匹配的百分比,但是通常我们说的 relevance 是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
Elasticsearch 的相似度算法被定义为检索词频率/反向文档频率, TF/IDF ,包括以下内容:
-
检索词频率(TF)
检索词在该字段出现的频率?出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高。
-
反向文档频率(IDF)
每个检索词在索引中出现的频率?频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
-
字段长度准则
字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
单个查询可以联合使用 TF/IDF 和其他方式,比如短语查询中检索词的距离或模糊查询里的检索词相似度。
相关性并不只是全文本检索的专利。也适用于 yes|no 的子句,匹配的子句越多,相关性评分越高。
如果多条查询子句被合并为一条复合查询语句,比如 bool 查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中。
elasticsearch发现机制
ES 的集群搭建很简单,不需要依赖第三方协调管理组件,自身内部就实现了集群的管理功能。
ES 集群由一个或多个 Elasticsearch 节点组成,每个节点配置相同的 cluster.name 即可加入集群,默认值为 “elasticsearch”。
确保不同的环境中使用不同的集群名称,否则最终会导致节点加入错误的集群。
一个 Elasticsearch 服务启动实例就是一个节点(Node)。节点通过 node.name 来设置节点名称,如果不设置则在启动时给节点分配一个随机通用唯一标识符作为名称。
①发现机制
那么有一个问题,ES 内部是如何通过一个相同的设置 cluster.name 就能将不同的节点连接到同一个集群的?答案是 Zen Discovery。
Zen Discovery 是 Elasticsearch 的内置默认发现模块(发现模块的职责是发现集群中的节点以及选举 Master 节点)。
它提供单播和基于文件的发现,并且可以扩展为通过插件支持云环境和其他形式的发现。
Zen Discovery 与其他模块集成,例如,节点之间的所有通信都使用 Transport 模块完成。节点使用发现机制通过 Ping 的方式查找其他节点。
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。
如果集群的节点运行在不同的机器上,使用单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。
当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 Master 节点,并加入集群。
这意味着单播列表不需要包含集群中的所有节点, 它只是需要足够的节点,当一个新节点联系上其中一个并且说上话就可以了。
如果你使用 Master 候选节点作为单播列表,你只要列出三个就可以了。这个配置在 elasticsearch.yml 文件中:
单播发现依赖transport模块实现。注意port默认应该是9300,不是9200,因为使用的是tranposrt。
discovery.zen.ping.unicast.hosts: [“host1”, “host2:port”]
节点启动后先 Ping ,如果 discovery.zen.ping.unicast.hosts 有设置,则 Ping 设置中的 Host ,否则尝试 ping localhost 的几个端口。
Elasticsearch 支持同一个主机启动多个节点,Ping 的 Response 会包含该节点的基本信息以及该节点认为的 Master 节点。
选举开始,先从各节点认为的 Master 中选,规则很简单,按照 ID 的字典序排序,取第一个。如果各节点都没有认为的 Master ,则从所有节点中选择,规则同上。
这里有个限制条件就是 discovery.zen.minimum_master_nodes ,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举。
最后选举结果是肯定能选举出一个 Master ,如果只有一个 Local 节点那就选出的是自己。
如果当前节点是 Master ,则开始等待节点数达到 discovery.zen.minimum_master_nodes,然后提供服务。
如果当前节点不是 Master ,则尝试加入 Master 。Elasticsearch 将以上服务发现以及选主的流程叫做 Zen Discovery 。
由于它支持任意数目的集群( 1- N ),所以不能像 Zookeeper 那样限制节点必须是奇数,也就无法用投票的机制来选主,而是通过一个规则。
只要所有的节点都遵循同样的规则,得到的信息都是对等的,选出来的主节点肯定是一致的。
脑裂现象
但分布式系统的问题就出在信息不对等的情况,这时候很容易出现脑裂(Split-Brain)的问题。
大多数解决方案就是设置一个 Quorum 值,要求可用节点必须大于 Quorum(一般是超过半数节点),才能对外提供服务。
而 Elasticsearch 中,这个 Quorum 的配置就是 discovery.zen.minimum_master_nodes 。
②节点的角色
每个节点既可以是候选主节点也可以是数据节点,通过在配置文件 …/config/elasticsearch.yml 中设置即可,默认都为 true。

数据节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(Data 节点)对机器配置要求比较高,对 CPU、内存和 I/O 的消耗很大。
通常随着集群的扩大,需要增加更多的数据节点来提高性能和可用性。
候选主节点可以被选举为主节点(Master 节点),集群中只有候选主节点才有选举权和被选举权,其他节点不参与选举的工作。
主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的。
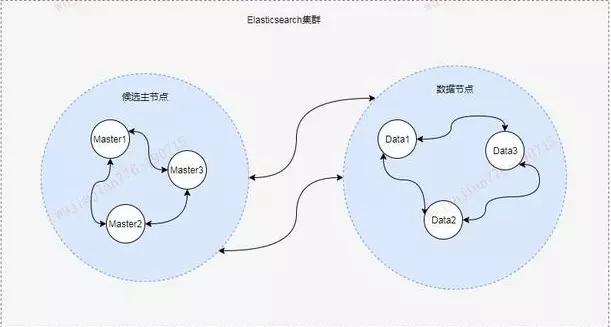
一个节点既可以是候选主节点也可以是数据节点,但是由于数据节点对 CPU、内存核 I/O 消耗都很大。
所以如果某个节点既是数据节点又是主节点,那么可能会对主节点产生影响从而对整个集群的状态产生影响。
因此为了提高集群的健康性,我们应该对 Elasticsearch 集群中的节点做好角色上的划分和隔离。可以使用几个配置较低的机器群作为候选主节点群。
主节点和其他节点之间通过 Ping 的方式互检查,主节点负责 Ping 所有其他节点,判断是否有节点已经挂掉。其他节点也通过 Ping 的方式判断主节点是否处于可用状态。
虽然对节点做了角色区分,但是用户的请求可以发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发。
这种节点可称之为协调节点,协调节点是不需要指定和配置的,集群中的任何节点都可以充当协调节点的角色。
脑裂现象
同时如果由于网络或其他原因导致集群中选举出多个 Master 节点,使得数据更新时出现不一致,这种现象称之为脑裂,即集群中不同的节点对于 Master 的选择出现了分歧,出现了多个 Master 竞争。
“脑裂”问题可能有以下几个原因造成:
**网络问题:**集群间的网络延迟导致一些节点访问不到 Master,认为 Master 挂掉了从而选举出新的 Master,并对 Master 上的分片和副本标红,分配新的主分片。
**节点负载:**主节点的角色既为 Master 又为 Data,访问量较大时可能会导致 ES 停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
**内存回收:**主节点的角色既为 Master 又为 Data,当 Data 节点上的 ES 进程占用的内存较大,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。
为了避免脑裂现象的发生,我们可以从原因着手通过以下几个方面来做出优化措施:
**适当调大响应时间,减少误判。**通过参数 discovery.zen.ping_timeout 设置节点状态的响应时间,默认为 3s,可以适当调大。
如果 Master 在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如 6s,discovery.zen.ping_timeout:6),可适当减少误判。
**选举触发。**我们需要在候选集群中的节点的配置文件中设置参数 discovery.zen.munimum_master_nodes 的值。
这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是 1,官方建议取值(master_eligibel_nodes/2)+1,其中 master_eligibel_nodes 为候选主节点的个数。
这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于 discovery.zen.munimum_master_nodes 个候选节点存活,选举工作就能正常进行。
当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。
**角色分离。**即是上面我们提到的候选主节点和数据节点进行角色分离,这样可以减轻主节点的负担,防止主节点的假死状态发生,减少对主节点“已死”的误判。
机制原理
它们内部是如何运行的?
主分片和副本分片是如何同步的?
创建索引的流程是什么样的?
ES 如何将索引数据分配到不同的分片上的?以及这些索引数据是如何存储的?
为什么说 ES 是近实时搜索引擎而文档的 CRUD (创建-读取-更新-删除) 操作是实时的?
以及 Elasticsearch 是怎样保证更新被持久化在断电时也不丢失数据?
还有为什么删除文档不会立刻释放空间?
写索引原理
下图描述了 3 个节点的集群,共拥有 12 个分片,其中有 4 个主分片(S0、S1、S2、S3)和 8 个副本分片(R0、R1、R2、R3),每个主分片对应两个副本分片,节点 1 是主节点(Master 节点)负责整个集群的状态。
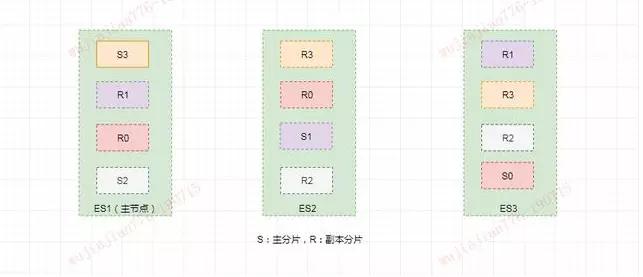
写索引是只能写在主分片上,然后同步到副本分片。这里有四个主分片,一条数据 ES 是根据什么规则写到特定分片上的呢?
这条索引数据为什么被写到 S0 上而不写到 S1 或 S2 上?那条数据为什么又被写到 S3 上而不写到 S0 上了?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。
实际上,这个过程是根据下面这个公式决定的:

Routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。
Routing 通过 Hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数。
这个在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
由于在 ES 集群中每个节点通过上面的计算公式都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
在一个写请求被发送到某个节点后,该节点即为前面说过的协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。
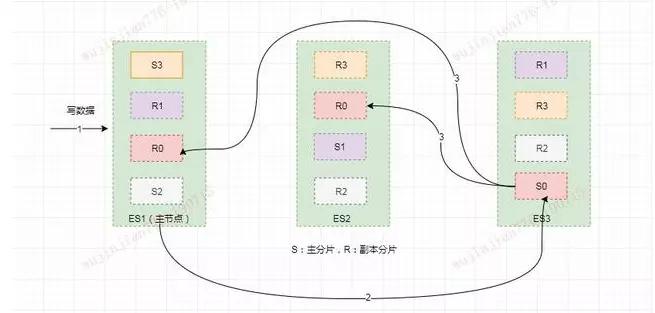
假如此时数据通过路由计算公式取余后得到的值是 shard=hash(routing)%4=0。
则具体流程如下:
客户端向 ES1 节点(协调节点)发送写请求,通过路由计算公式得到值为 0,则当前数据应被写到主分片 S0 上。
ES1 节点将请求转发到 S0 主分片所在的节点 ES3,ES3 接受请求并写入到磁盘。
并发将数据复制到两个副本分片 R0 上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 ES3 将向协调节点报告成功,协调节点向客户端报告成功。
存储原理(索引的存储 段形式)
上面介绍了在 ES 内部索引的写处理流程,这个流程是在 ES 的内存中执行的,数据被分配到特定的分片和副本上之后,最终是存储到磁盘上的,这样在断电的时候就不会丢失数据。
具体的存储路径可在配置文件 …/config/elasticsearch.yml 中进行设置,默认存储在安装目录的 Data 文件夹下。
建议不要使用默认值,因为若 ES 进行了升级,则有可能导致数据全部丢失:

①分段存储
索引文档以段的形式存储在磁盘上,何为段?索引文件被拆分为多个子文件,则每个子文件叫作段,每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。
在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能。
段被写入到磁盘后会生成一个提交点,提交点是一个用来记录所有提交后段信息的文件。
一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。相反,当段在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。
段的概念提出主要是因为:在早期全文检索中为整个文档集合建立了一个很大的倒排索引,并将其写入磁盘中。
如果索引有更新,就需要重新全量创建一个索引来替换原来的索引。这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,所以对数据的更新不能过于频繁,也就不能保证时效性。
索引文件分段存储并且不可修改,那么新增、更新和删除如何处理呢?
**新增,**新增很好处理,由于数据是新的,所以只需要对当前文档新增一个段就可以了。
**删除,**由于不可修改,所以对于删除操作,不会把文档从旧的段中移除而是通过新增一个 .del 文件,文件中会列出这些被删除文档的段信息。
这个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
**更新,**不能修改旧的段来进行反映文档的更新,其实更新相当于是删除和新增这两个动作组成。会将旧的文档在 .del 文件中标记删除,然后文档的新版本被索引到一个新的段中。
可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就会被移除。
段被设定为不可修改具有一定的优势也有一定的缺点,优势主要表现在:
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
其它缓存(像 Filter 缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和需要被缓存到内存的索引的使用量。
段的不变性的缺点如下:
当对旧数据进行删除时,旧数据不会马上被删除,而是在 .del 文件中被标记为删除。而旧数据只能等到段更新时才能被移除,这样会造成大量的空间浪费。
若有一条数据频繁的更新,每次更新都是新增新的标记旧的,则会有大量的空间浪费。
每次新增数据时都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源例如文件句柄的消耗会非常大。
在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,这增加了查询的负担。
②延迟写策略
介绍完了存储的形式,那么索引写入到磁盘的过程是怎样的?是否是直接调 Fsync 物理性地写入磁盘?
答案是显而易见的,如果是直接写入到磁盘上,磁盘的 I/O 消耗上会严重影响性能。
那么当写数据量大的时候会造成 ES 停顿卡死,查询也无法做到快速响应。如果真是这样 ES 也就不会称之为近实时全文搜索引擎了。
为了提升写的性能,ES 并没有每新增一条数据就增加一个段到磁盘上,而是采用延迟写的策略。
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存。
当达到默认的时间(1 秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统 上,稍后再被刷新到磁盘中并生成提交点。
这里的内存使用的是 ES 的 JVM 内存,而文件缓存系统使用的是操作系统的内存。
新的数据会继续的被写入内存,但内存中的数据并不是以段的形式存储的,因此不能提供检索功能。
由内存刷新到文件缓存系统的时候会生成新的段,并将段打开以供搜索使用,而不需要等到被刷新到磁盘。
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 Refresh (即内存刷新到文件缓存系统)。
默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是近实时搜索,因为文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
我们也可以手动触发 Refresh,POST /_refresh 刷新所有索引,POST /nba/_refresh 刷新指定的索引。
**Tips:**尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产>环境下每次索引一个文档都去手动刷新。而且并不是所有的情况都需要每秒刷新。
可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是>近实时搜索。
这时可以在创建索引时在 Settings 中通过调大 refresh_interval = “30s” 的值 , 降低每个索引的刷新频率,设值时需要注意后面带上时间单位,否则默认是毫秒。当 refresh_interval=-1 时表示关闭索引的自动刷新。
虽然通过延时写的策略可以减少数据往磁盘上写的次数提升了整体的写入能力,但是我们知道文件缓存系统也是内存空间,属于操作系统的内存,只要是内存都存在断电或异常情况下丢失数据的危险。
为了避免丢失数据,Elasticsearch 添加了事务日志(Translog),事务日志记录了所有还没有持久化到磁盘的数据。
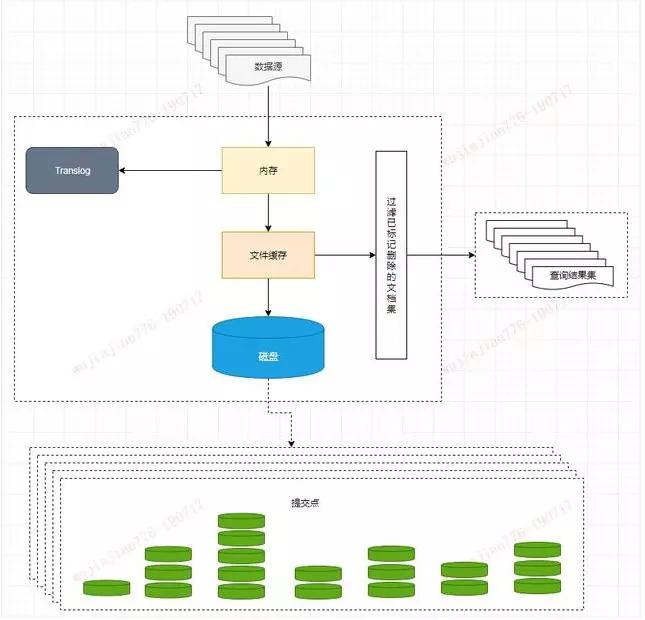
添加了事务日志后整个写索引的流程如上图所示:
一个新文档被索引之后,先被写入到内存中,但是为了防止数据的丢失,会追加一份数据到事务日志中。
不断有新的文档被写入到内存,同时也都会记录到事务日志中。这时新数据还不能被检索和查询。
当达到默认的刷新时间或内存中的数据达到一定量后,会触发一次 Refresh,将内存中的数据以一个新段形式刷新到文件缓存系统中并清空内存。这时虽然新段未被提交到磁盘,但是可以提供文档的检索功能且不能被修改。
随着新文档索引不断被写入,当日志数据大小超过 512M 或者时间超过 30 分钟时,会触发一次 Flush。
内存中的数据被写入到一个新段同时被写入到文件缓存系统,文件系统缓存中数据通过 Fsync 刷新到磁盘中,生成提交点,日志文件被删除,创建一个空的新日志。
通过这种方式当断电或需要重启时,ES 不仅要根据提交点去加载已经持久化过的段,还需要工具 Translog 里的记录,把未持久化的数据重新持久化到磁盘上,避免了数据丢失的可能。
③段合并
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。
每一个段都会消耗文件句柄、内存和 CPU 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段然后合并查询结果,所以段越多,搜索也就越慢。
Elasticsearch 通过在后台定期进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档不会被拷贝到新的大段中。合并的过程中不会中断索引和搜索。
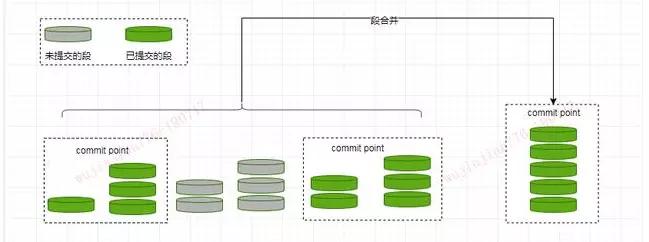
段合并在进行索引和搜索时会自动进行,合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这些段既可以是未提交的也可以是已提交的。
合并结束后老的段会被删除,新的段被 Flush 到磁盘,同时写入一个包含新段且排除旧的和较小的段的新提交点,新的段被打开可以用来搜索。
段合并的计算量庞大, 而且还要吃掉大量磁盘 I/O,段合并会拖累写入速率,如果任其发展会影响搜索性能。
Elasticsearch 在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
性能优化
存储设备
磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。
这里有一些优化磁盘 I/O 的技巧:
**使用 SSD。**就像其他地方提过的, 他们比机械磁盘优秀多了。
**使用 RAID 0。**条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。
**另外,使用多块硬盘,**并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面。
**不要使用远程挂载的存储,**比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
**如果你用的是 EC2,当心 EBS。**即便是基于 SSD 的 EBS,通常也比本地实例的存储要慢。
内部索引优化
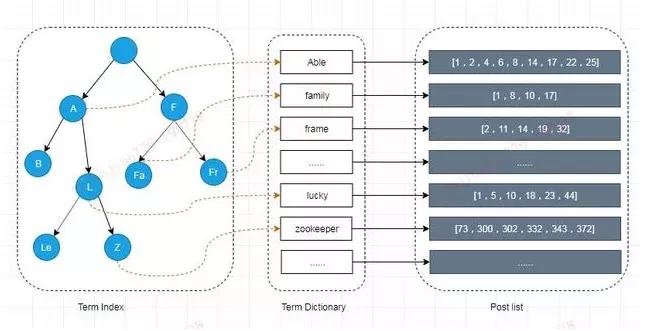
Elasticsearch 为了能快速找到某个 Term,先将所有的 Term 排个序,然后根据二分法查找 Term,时间复杂度为 logN,就像通过字典查找一样,这就是 Term Dictionary。
现在再看起来,似乎和传统数据库通过 B-Tree 的方式类似。但是如果 Term 太多,Term Dictionary 也会很大,放内存不现实,于是有了 Term Index。
就像字典里的索引页一样,A 开头的有哪些 Term,分别在哪页,可以理解 Term Index是一棵树。
这棵树不会包含所有的 Term,它包含的是 Term 的一些前缀。通过 Term Index 可以快速地定位到 Term Dictionary 的某个 Offset,然后从这个位置再往后顺序查找。
在内存中用 FST 方式压缩 Term Index,FST 以字节的方式存储所有的 Term,这种压缩方式可以有效的缩减存储空间,使得 Term Index 足以放进内存,但这种方式也会导致查找时需要更多的 CPU 资源。
对于存储在磁盘上的倒排表同样也采用了压缩技术减少存储所占用的空间。
调整配置参数
调整配置参数建议如下:
给每个文档指定有序的具有压缩良好的序列模式 ID,避免随机的 UUID-4 这样的 ID,这样的 ID 压缩比很低,会明显拖慢 Lucene。
对于那些不需要聚合和排序的索引字段禁用 Doc values。Doc Values 是有序的基于 document=>field value 的映射列表。
不需要做模糊检索的字段使用 Keyword 类型代替 Text 类型,这样可以避
免在建立索引前对这些文本进行分词。
如果你的搜索结果不需要近实时的准确度,考虑把每个索引的 index.refresh_interval 改到 30s 。
如果你是在做大批量导入,导入期间你可以通过设置这个值为 -1 关掉刷新,还可以通过设置 index.number_of_replicas: 0 关闭副本。别忘记在完工的时候重新开启它。
避免深度分页查询建议使用 Scroll 进行分页查询。普通分页查询时,会创建一个 from+size 的空优先队列,每个分片会返回 from+size 条数据,默认只包含文档 ID 和得分 Score 给协调节点。
如果有 N 个分片,则协调节点再对(from+size)×n 条数据进行二次排序,然后选择需要被取回的文档。当 from 很大时,排序过程会变得很沉重,占用 CPU 资源严重。
减少映射字段,只提供需要检索,聚合或排序的字段。其他字段可存在其他存储设备上,例如 Hbase,在 ES 中得到结果后再去 Hbase 查询这些字段。
创建索引和查询时指定路由 Routing 值,这样可以精确到具体的分片查询,提升查询效率。路由的选择需要注意数据的分布均衡。
JVM 调优
JVM 调优建议如下:
确保堆内存最小值( Xms )与最大值( Xmx )的大小是相同的,防止程序在运行时改变堆内存大小。
Elasticsearch 默认安装后设置的堆内存是 1GB。可通过 …/config/jvm.option 文件进行配置,但是最好不要超过物理内存的50%和超过 32GB。
GC 默认采用 CMS 的方式,并发但是有 STW 的问题,可以考虑使用 G1 收集器。
ES 非常依赖文件系统缓存(Filesystem Cache),快速搜索。一般来说,应该至少确保物理上有一半的可用内存分配到文件系统缓存。
索引别名和零停机
在前面提到的,重建索引的问题是必须更新应用中的索引名称。 索引别名就是用来解决这个问题的!
索引 别名 就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用。别名 带给我们极大的灵活性,允许我们做下面这些:
- 在运行的集群中可以无缝的从一个索引切换到另一个索引
- 给多个索引分组 (例如,
last_three_months) - 给索引的一个子集创建
视图
在后面我们会讨论更多关于别名的使用。现在,我们将解释怎样使用别名在零停机下从旧索引切换到新索引。
有两种方式管理别名: _alias 用于单个操作, _aliases 用于执行多个原子级操作。
在本章中,我们假设你的应用有一个叫 my_index 的索引。事实上, my_index 是一个指向当前真实索引的别名。真实索引包含一个版本号: my_index_v1 , my_index_v2 等等。
首先,创建索引 my_index_v1 ,然后将别名 my_index 指向它:
PUT /my_index_v1
PUT /my_index_v1/_alias/my_index
- 1
- 2
创建索引 my_index_v1 。 | |
|---|---|
设置别名 my_index 指向 my_index_v1 。 |
你可以检测这个别名指向哪一个索引:
GET /*/_alias/my_index
- 1
或哪些别名指向这个索引:
GET /my_index_v1/_alias/*
- 1
两者都会返回下面的结果:
{
"my_index_v1" : {
"aliases" : {
"my_index" : { }
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后,我们决定修改索引中一个字段的映射。当然,我们不能修改现存的映射,所以我们必须重新索引数据。 首先, 我们用新映射创建索引 my_index_v2 :
PUT /my_index_v2
{
"mappings": {
"my_type": {
"properties": {
"tags": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
然后我们将数据从 my_index_v1 索引到 my_index_v2 ,下面的过程在 重新索引你的数据 中已经描述过。一旦我们确定文档已经被正确地重索引了,我们就将别名指向新的索引。
一个别名可以指向多个索引,所以我们在添加别名到新索引的同时必须从旧的索引中删除它。这个操作需要原子化,这意味着我们需要使用 _aliases 操作:
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
你的应用已经在零停机的情况下从旧索引迁移到新索引了。
即使你认为现在的索引设计已经很完美了,在生产环境中,还是有可能需要做一些修改的。
做好准备:在你的应用中使用别名而不是索引名。然后你就可以在任何时候重建索引。别名的开销很小,应该广泛使用。
副本分片是否参与日常检索
并且当主分片出现物理故障时,从分片顶上去,负责数据的检索等只读请求。
从分片的数量可变,不用重新建库。
为了提升访问压力过大是单机无法处理所有请求的问题,Elasticsearch集群引入了副本策略replica。副本策略对index中的每个分片创建冗余的副本,处理查询时可以把这些副本当做主分片来对待(primary shard),此外副本策略提供了高可用和数据安全的保障,当分片所在的机器宕机,Elasticsearch可以使用其副本进行恢复,从而避免数据丢失。
综上所述 副本分片参与查询(暂时留有疑惑20210128)?然后是只能进行读操作,如果是写操作的话
召回率和精确率
全文搜索被称作是 召回率(Recall) 与 精确率(Precision) 的战场: 召回率 ——返回所有的相关文档; 精确率 ——不返回无关文档。目的是在结果的第一页中为用户呈现最为相关的文档。
为了提高召回率的效果,我们扩大搜索范围——不仅返回与用户搜索词精确匹配的文档,还会返回我们认为与查询相关的所有文档。如果一个用户搜索 “quick brown box” ,一个包含词语 fast foxes 的文档被认为是非常合理的返回结果。
如果包含词语 fast foxes 的文档是能找到的唯一相关文档,那么它会出现在结果列表的最上面,但是,如果有 100 个文档都出现了词语 quick brown fox ,那么这个包含词语 fast foxes 的文档当然会被认为是次相关的,它可能处于返回结果列表更下面的某个地方。当包含了很多潜在匹配之后,我们需要将最匹配的几个置于结果列表的顶部。
提高全文相关性精度的常用方式是为同一文本建立多种方式的索引,每种方式都提供了一个不同的相关度信号 signal 。主字段会以尽可能多的形式的去匹配尽可能多的文档。举个例子,我们可以进行以下操作:
- 使用词干提取来索引
jumps、jumping和jumped样的词,将jump作为它们的词根形式。这样即使用户搜索jumped,也还是能找到包含jumping的匹配的文档。 - 将同义词包括其中,如
jump、leap和hop。 - 移除变音或口音词:如
ésta、está和esta都会以无变音形式esta来索引。
尽管如此,如果我们有两个文档,其中一个包含词 jumped ,另一个包含词 jumping ,用户很可能期望前者能排的更高,因为它正好与输入的搜索条件一致。
为了达到目的,我们可以将相同的文本索引到其他字段从而提供更为精确的匹配。一个字段可能是为词干未提取过的版本,另一个字段可能是变音过的原始词,第三个可能使用 shingles 提供 词语相似性 信息。这些附加的字段可以看成提高每个文档的相关度评分的信号 signals ,能匹配字段的越多越好。
一个文档如果与广度匹配的主字段相匹配,那么它会出现在结果列表中。如果文档同时又与 signal 信号字段匹配,那么它会获得额外加分,系统会提升它在结果列表中的位置。
我们会在本书稍后对同义词、词相似性、部分匹配以及其他潜在的信号进行讨论,但这里只使用词干已提取(stemmed)和未提取(unstemmed)的字段作为简单例子来说明这种技术。
copy_to
#把这两个字段复制到一个字段里面 PUT /my_index/_mapping { "properties":{ "fist_name":{ "type":"text", "copy_to":"full_name" }, "last_name": { "type": "text", "copy_to": "full_name" }, "full_name": { "type": "text" } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
first_name 和 last_name 字段中的值会被复制到 full_name 字段。
有了这个映射,我们可以用 first_name 来查询名,用 last_name 来查询姓,或者直接使用 full_name 查询整个姓名。
first_name 和 last_name 的映射并不影响 full_name 如何被索引, full_name 将两个字段的内容复制到本地,然后根据 full_name 的映射自行索引。
桶
桶 简单来说就是满足特定条件的文档的集合:
当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件。如果匹配到,文档将放入相应的桶并接着进行聚合操作。
桶也可以被嵌套在其他桶里面,提供层次化的或者有条件的划分方案。例如,辛辛那提会被放入俄亥俄州这个桶,而 整个 俄亥俄州桶会被放入美国这个桶。
Elasticsearch 有很多种类型的桶,能让你通过很多种方式来划分文档(时间、最受欢迎的词、年龄区间、地理位置等等)。其实根本上都是通过同样的原理进行操作:基于条件来划分文档。
指标
桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶是一种达到目的的手段:它提供了一种给文档分组的方法来让我们可以计算感兴趣的指标。
大多数 指标 是简单的数学运算(例如最小值、平均值、最大值,还有汇总),这些是通过文档的值来计算。在实践中,指标能让你计算像平均薪资、最高出售价格、95%的查询延迟这样的数据。
聚合
聚合 是由桶和指标组成的。 聚合可能只有一个桶,可能只有一个指标,或者可能两个都有。也有可能有一些桶嵌套在其他桶里面。例如,我们可以通过所属国家来划分文档(桶),然后计算每个国家的平均薪酬(指标)。
由于桶可以被嵌套,我们可以实现非常多并且非常复杂的聚合:
1.通过国家划分文档(桶)
2.然后通过性别划分每个国家(桶)
3.然后通过年龄区间划分每种性别(桶)
4.最后,为每个年龄区间计算平均薪酬(指标)
最后将告诉你每个 <国家, 性别, 年龄> 组合的平均薪酬。所有的这些都在一个请求内完成并且只遍历一次数据
聚合时候出现的错误
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [color] in order to load field data by uninverting the inverted index. Note that this can use significant memory."
}
],
- 1
- 2
- 3
- 4
- 5
- 6
从异常信息中可以看出,是因为我要聚合的字段【color】没有进行优化,也类似没有加索引。没有优化的字段es默认是禁止聚合/排序操作的。所以需要将要聚合的字段添加优化
https://blog.csdn.net/prufeng/article/details/108929293
set fielddata=true,不过不推荐
match
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索
term
query/term
和match一样。匹配某个属性的值。
全文检索字段用match,
其他非text字段匹配用term。
不要使用term来进行文本字段查询
也就是说,全文检索字段用match,其他非text字段匹配用term
es默认存储text值时用分词分析,所以要搜索text值,使用match
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/query-dsl-term-query.html
原文链接:https://blog.csdn.net/hancoder/article/details/113922398
es扁平化处理
映射的时候一定要加nested
nested对象聚合
属性是"type": “nested”,因为是内部的属性进行检索
数组类型的对象会被扁平化处理(对象的每个属性会分别存储到一起)
比如说创建两个数据
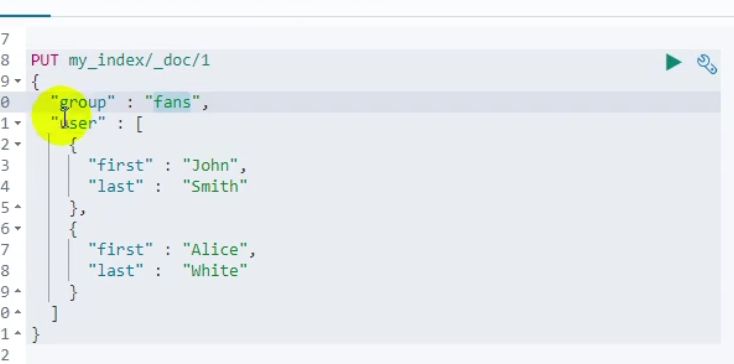
查询
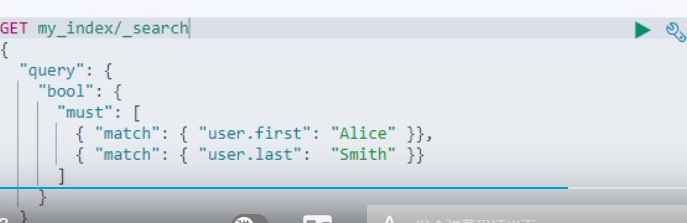
查询结果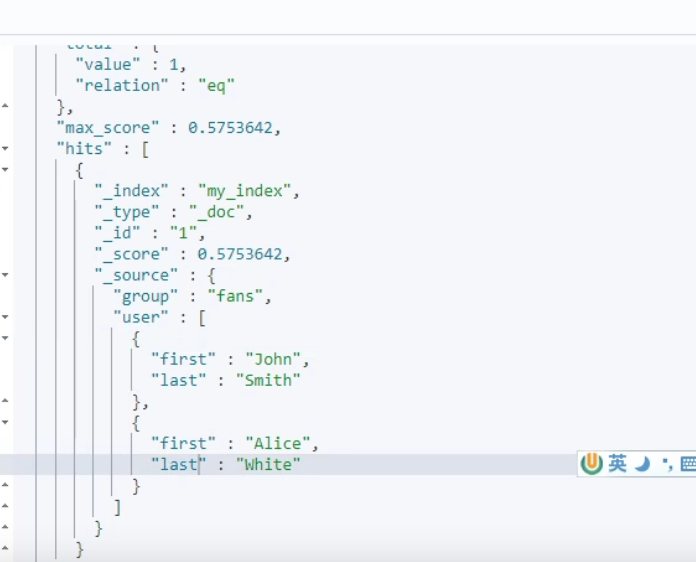
为什么会被找到了呢
因为ES的数组的扁平化处理
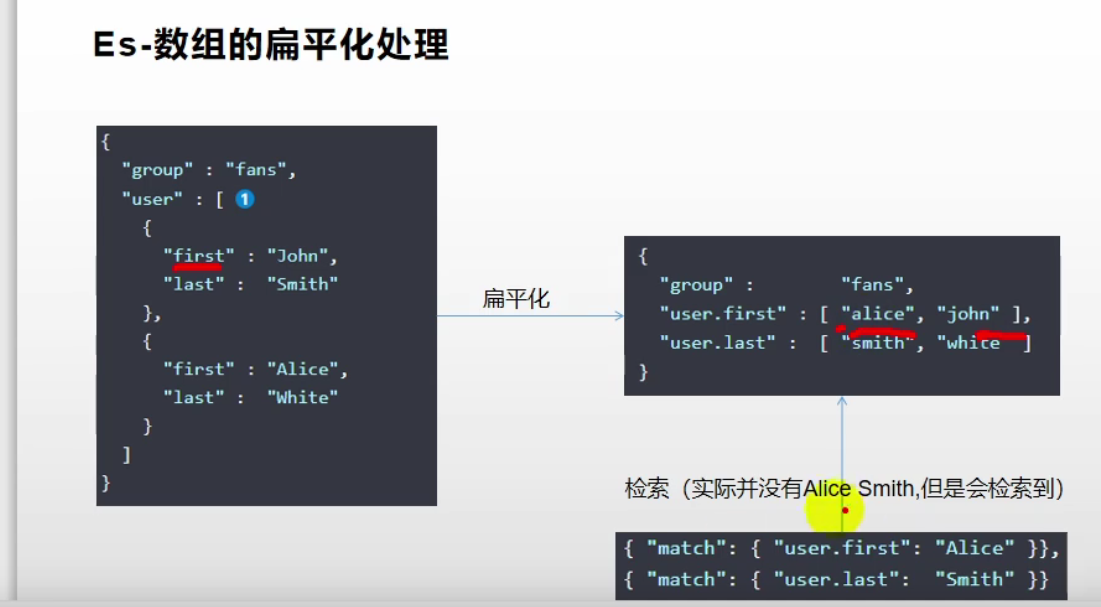
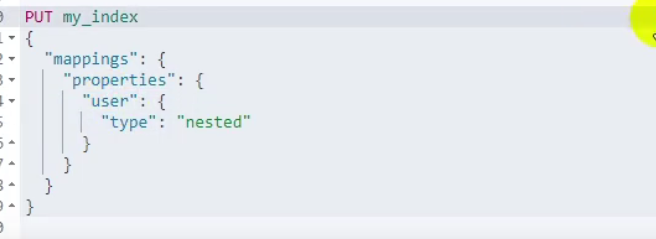
解决方法 在需要存的对象里面加入 “type”:“nested” 既嵌入式的处理
IK分词器插件
什么是IK分词器

安装 直接解压 放在对应的plugins下就行了
可以使用elasticsearch-plugin 命令行下的 elasticsearch-plugin list命令查看插件

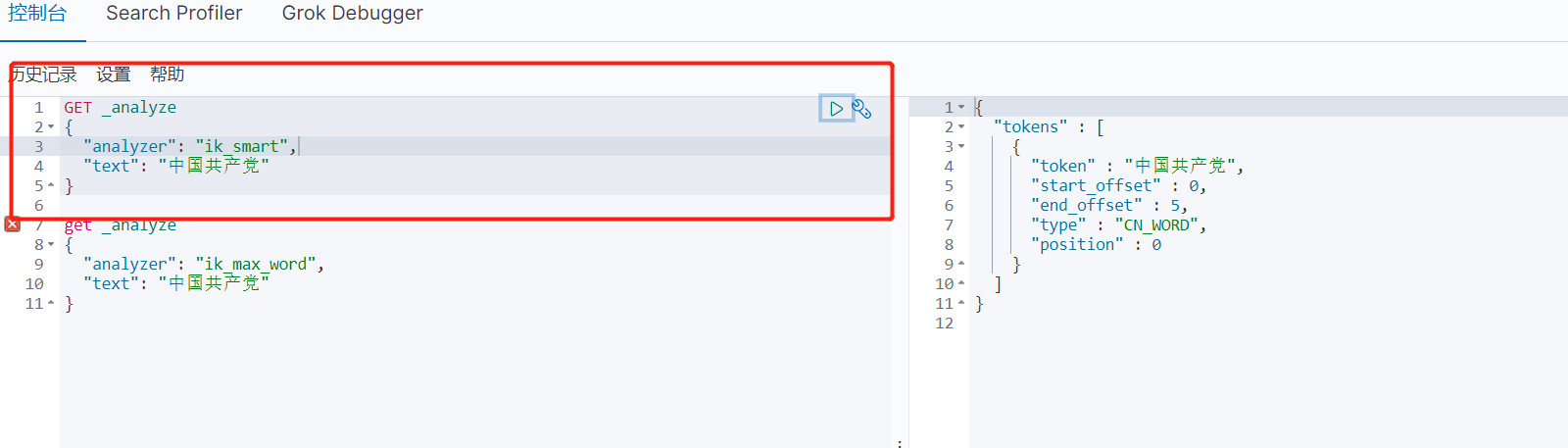
查看不同的分词效果
Ik_smart 和 ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
Ik_smart
ik_max_word 为最细粒度划分!穷尽词库的可能(那么它肯定是有一定的依据分的,那这个依据就来自一个字典)
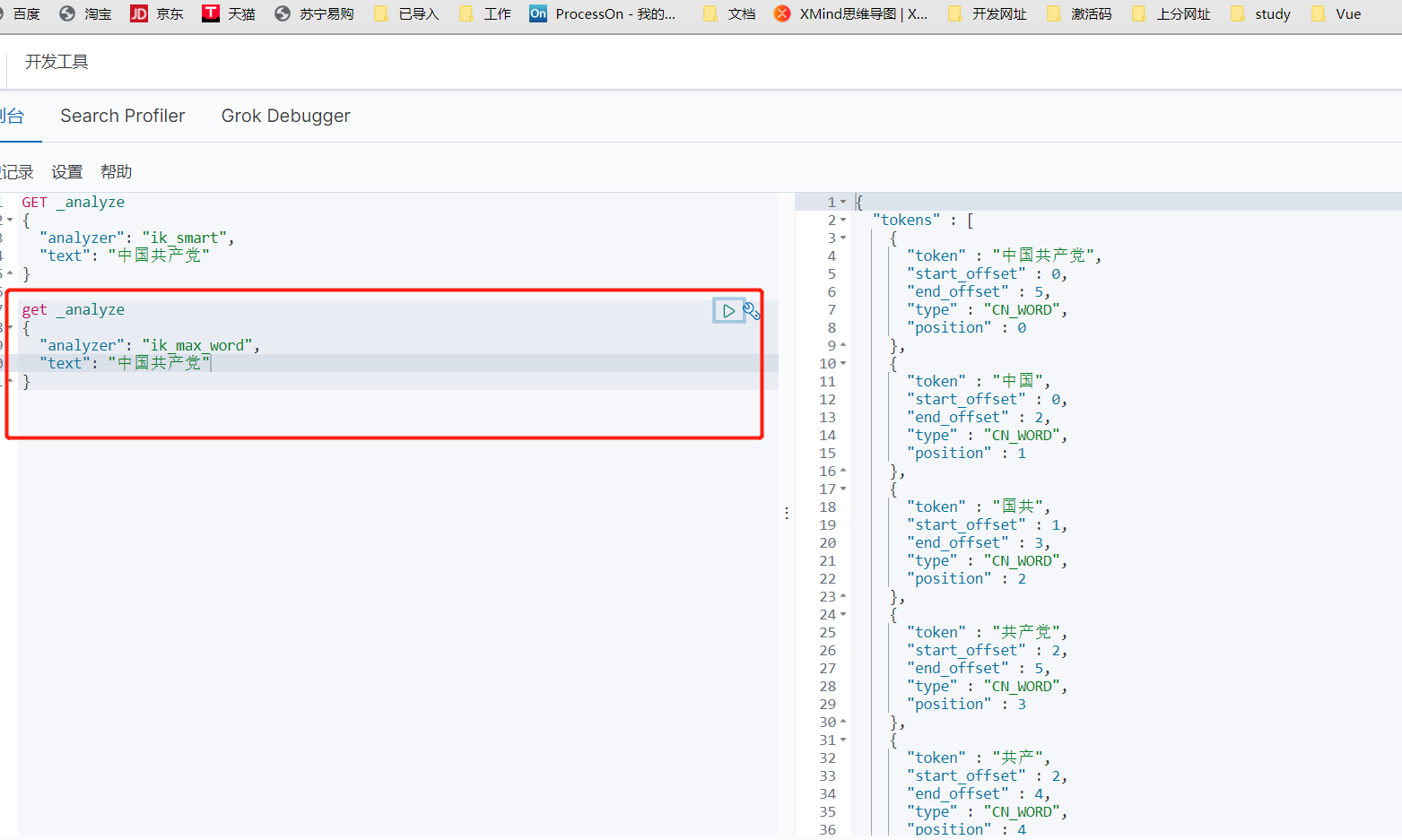
分一个 超级喜欢狂神说java这个词 发现都被拆分了
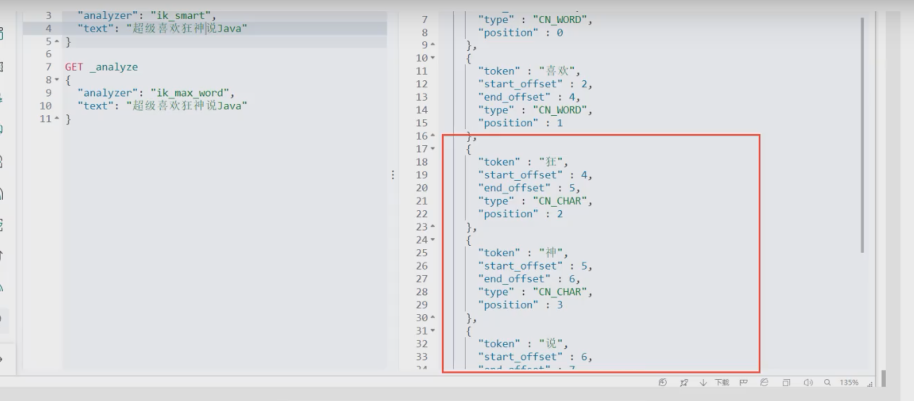
说明这种自己需要的词,需要自己加到我们的分词器的字典中
IK分词器增加自己的配置(例如特定词)
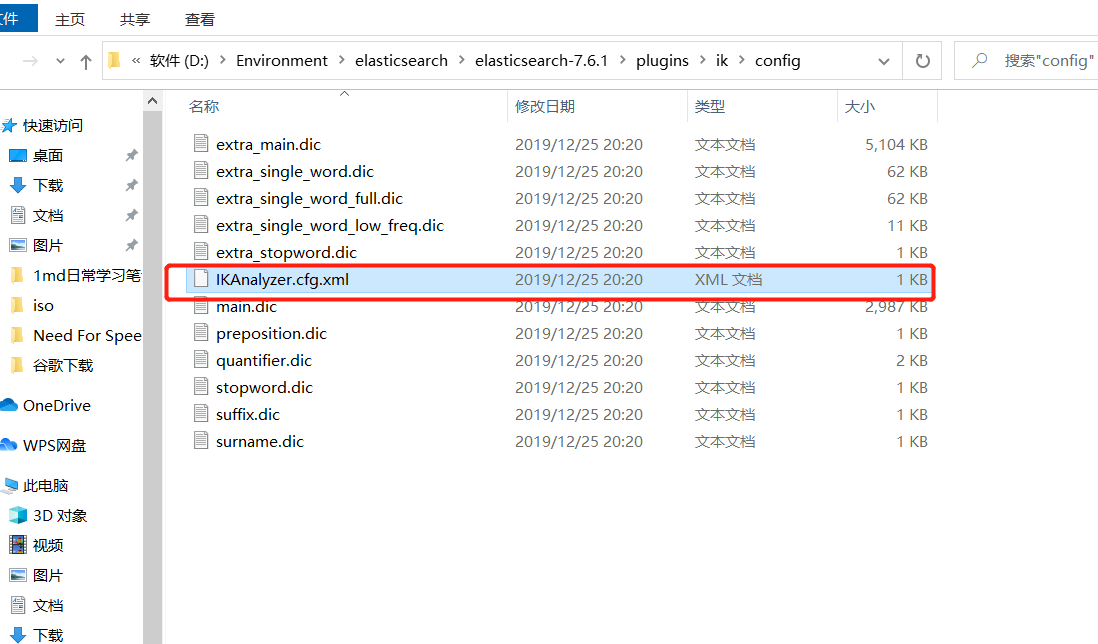
配置自己的字典
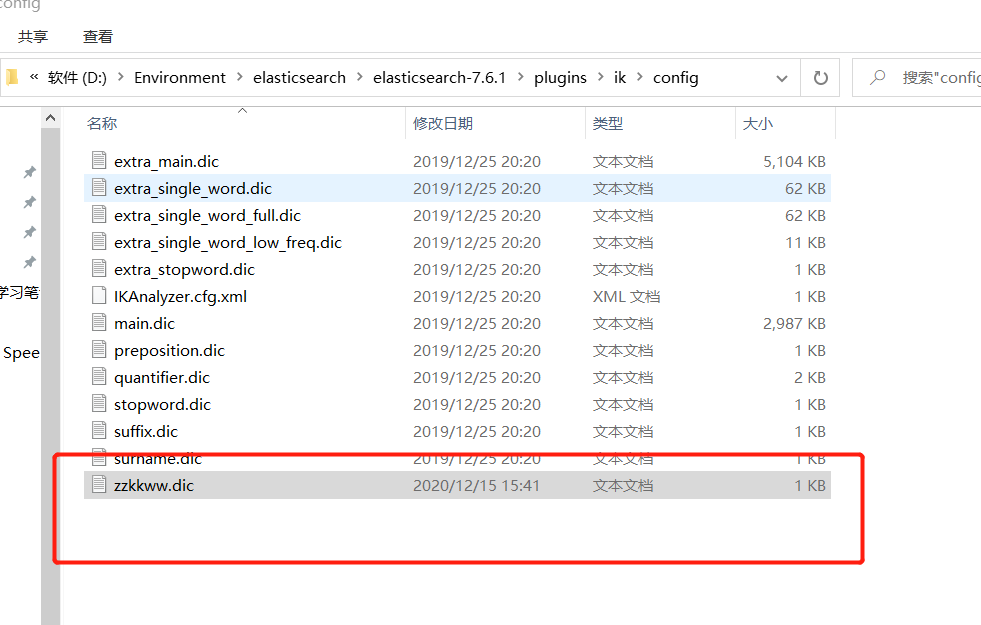
然后引用
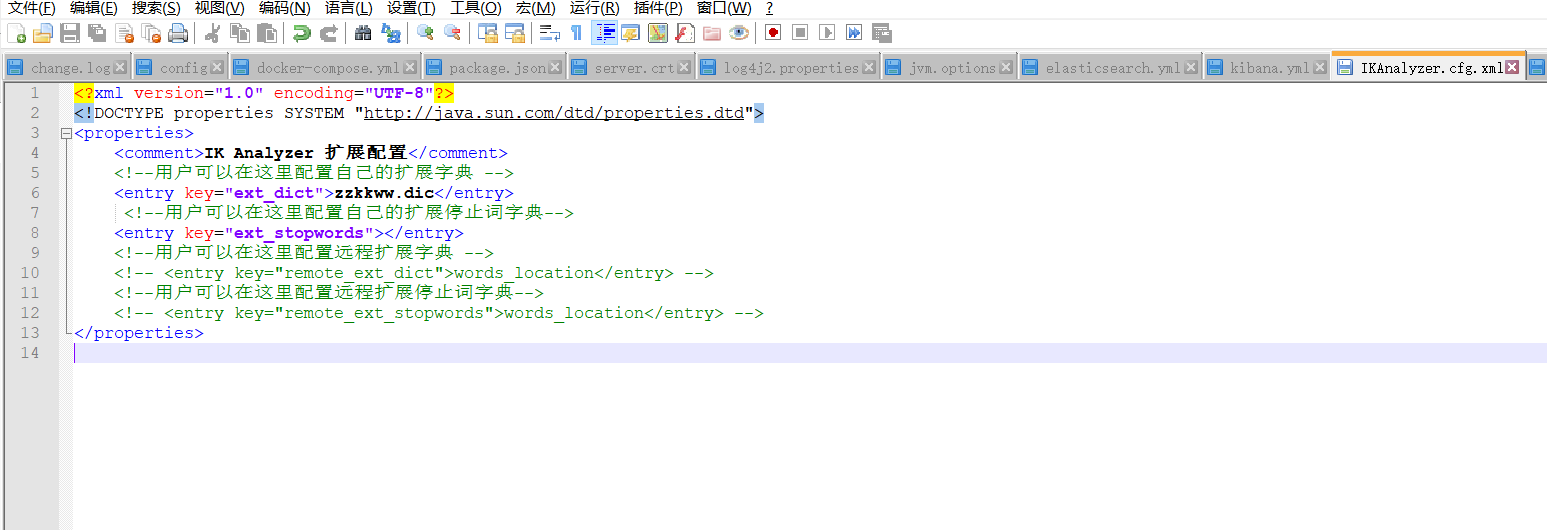
重启es 这里我们自定义的字典就已经加载进来了
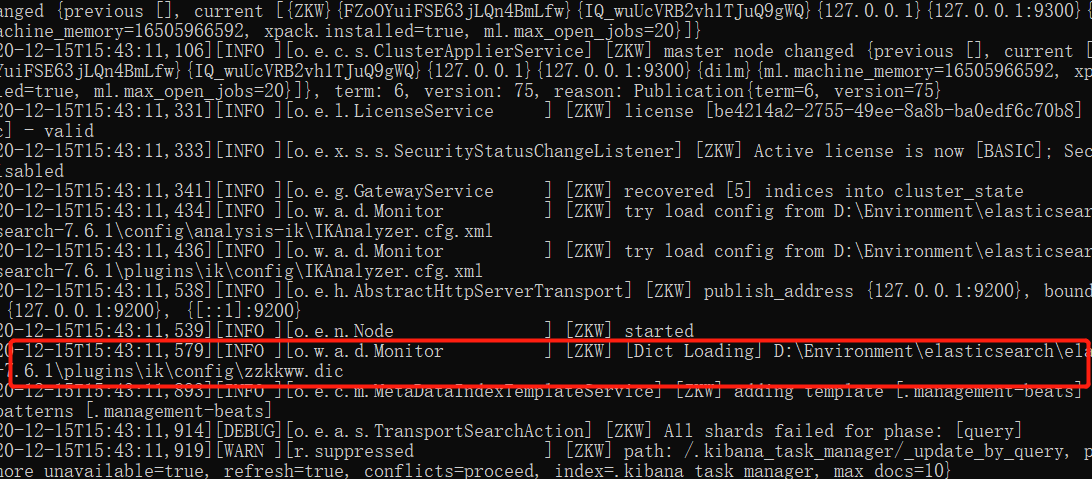
以后,我们需要自己配置 分词就在自己自定义的dic文件中进行配置即可
Rest风格说明
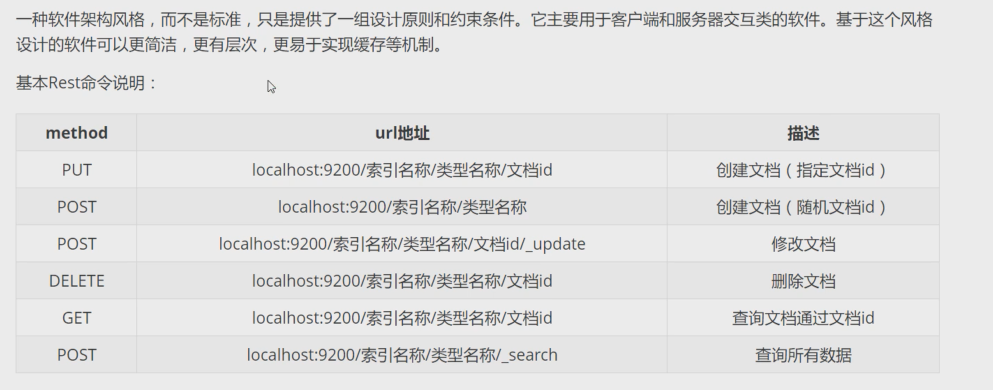
基础测试
关于索引的基本操作
增
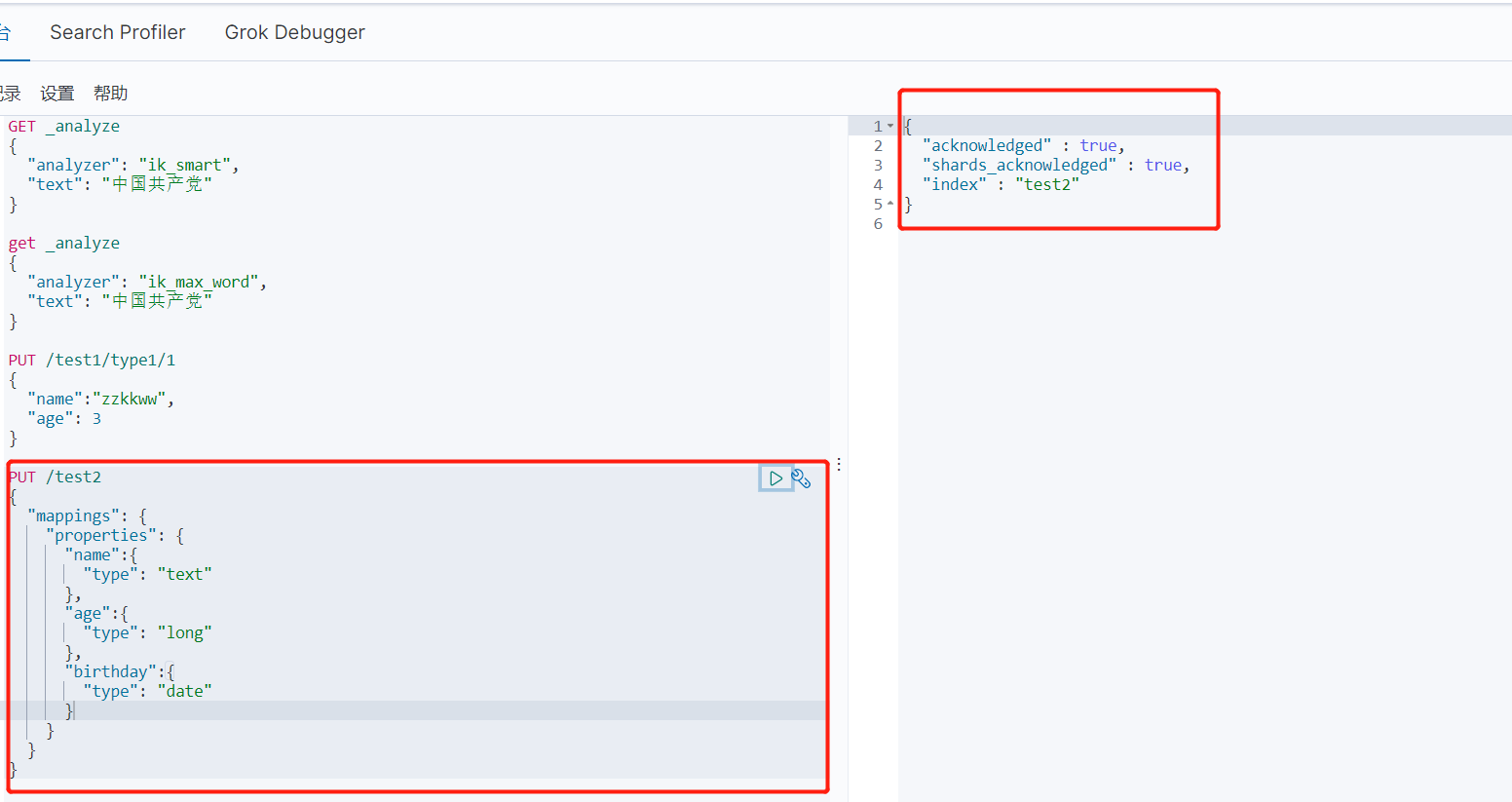
1、创建一个索引 (类型名未来会没有 8.0版本后)
PUT /索引名/~类型名~/文档id
{请求体}
- 1
- 2
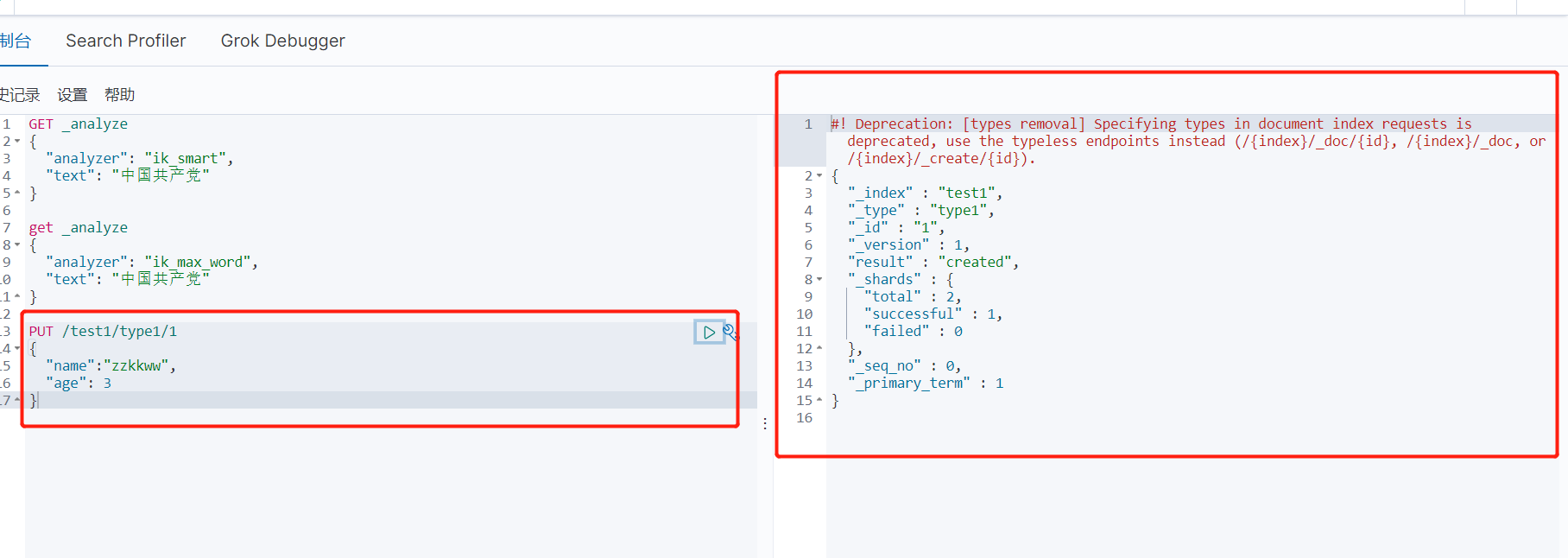
创建成功后可以在 elasticsearch-head中看到
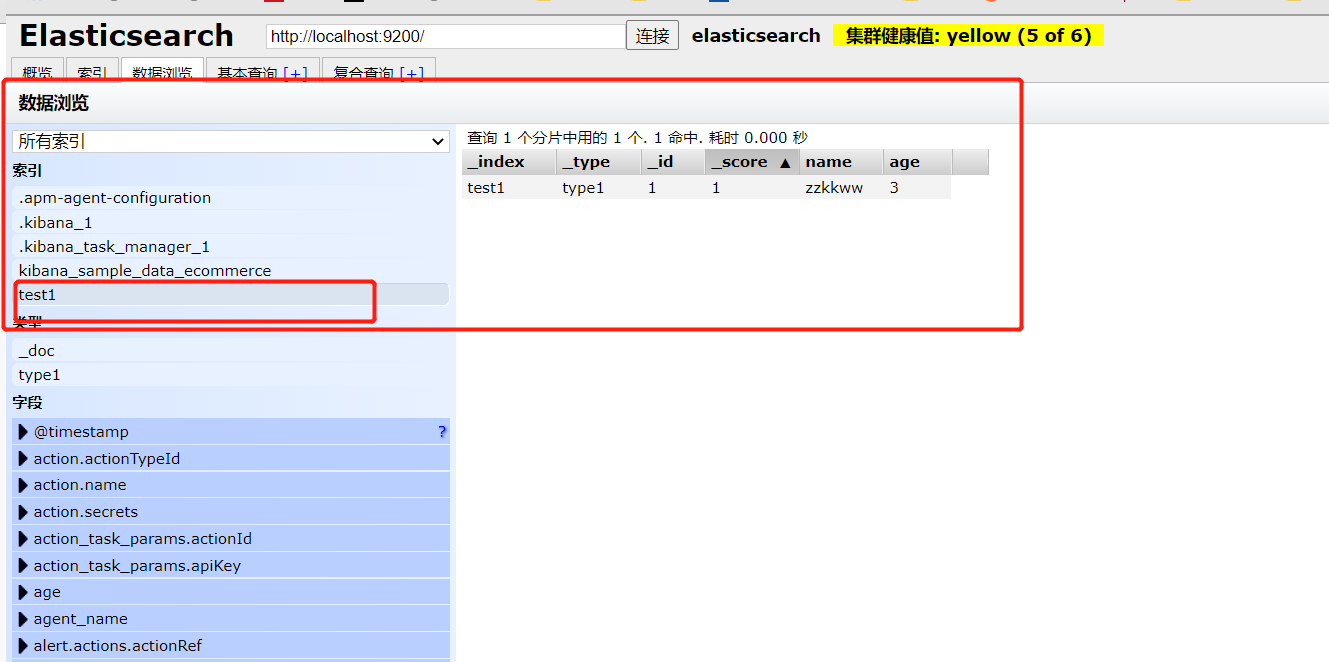

4、指定字段类型
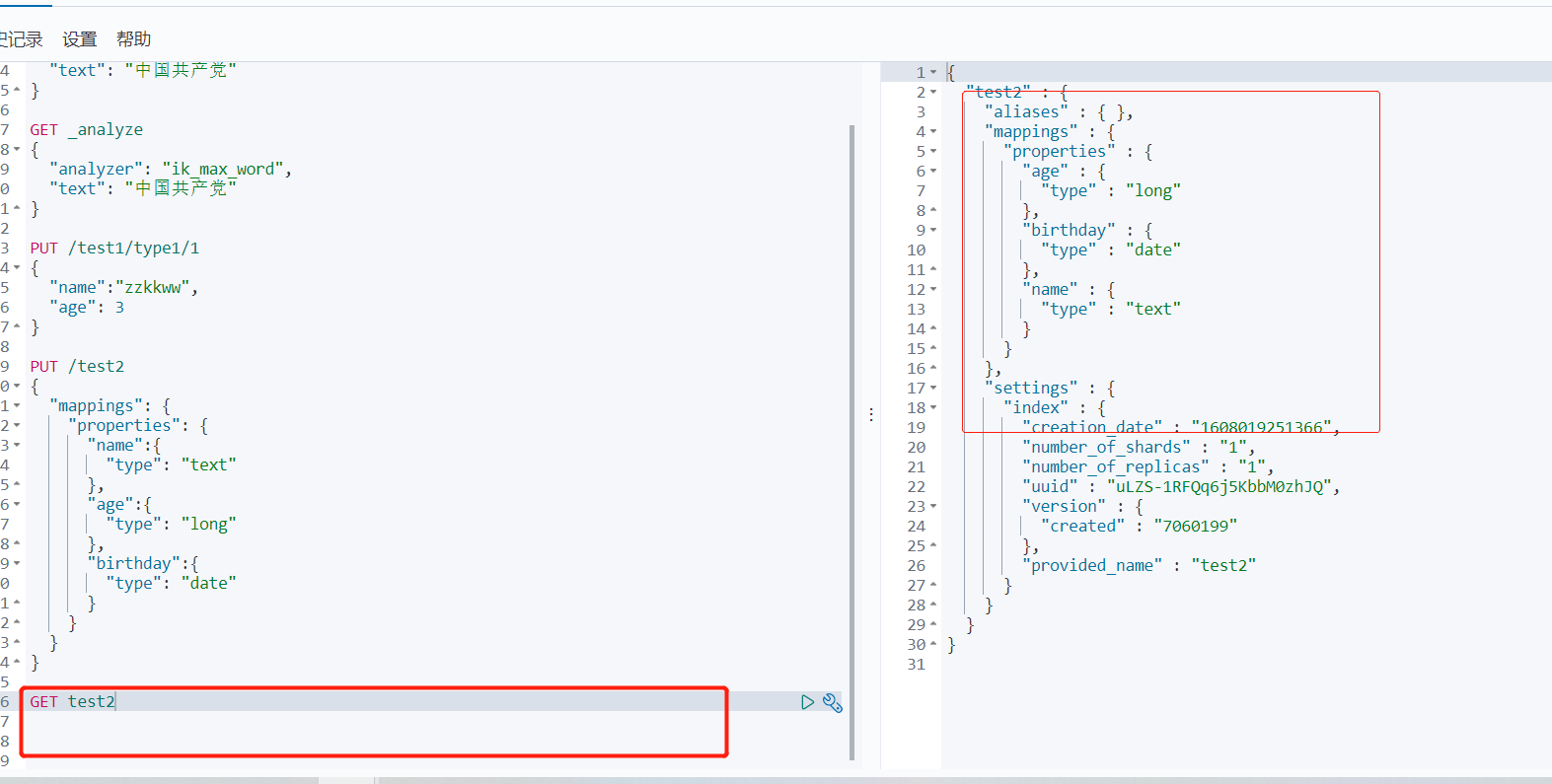
获得规则
GET 索引
- 1
5、
_doc 默认类型
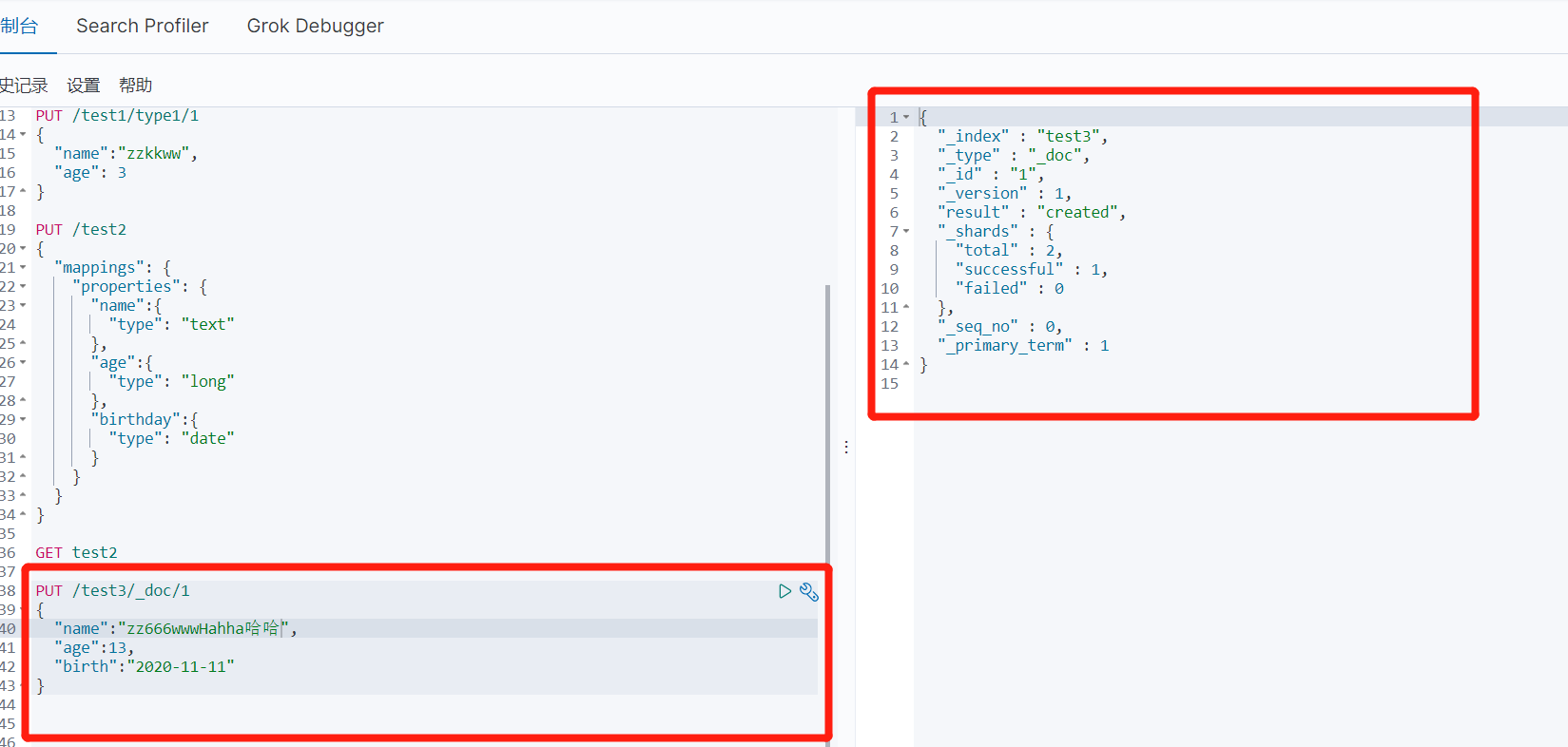
如果自己的文档字段没有指定,那么es就会给我们默认配置字段类型
扩展:通过命令elasticsearch 索引情况
GET _cat/health 查看节点的健康信息
GET _cat/indices 查看索引库
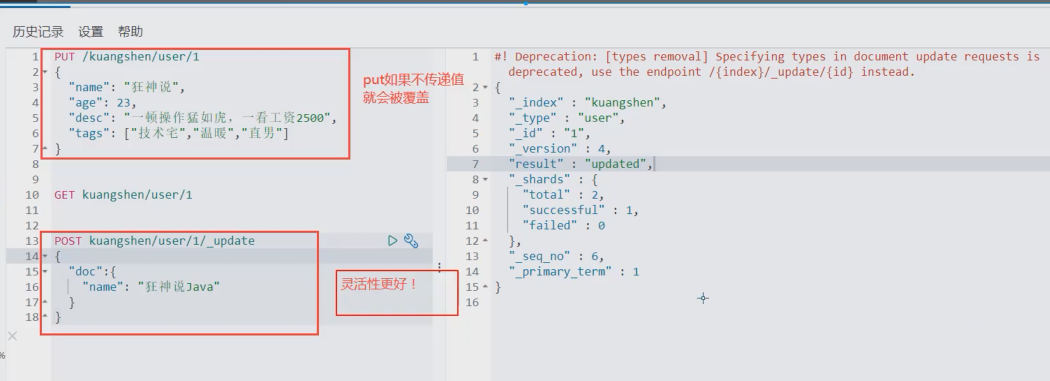
改
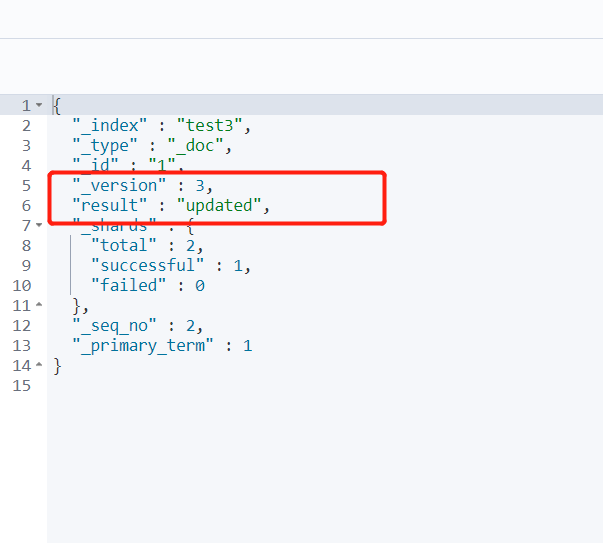
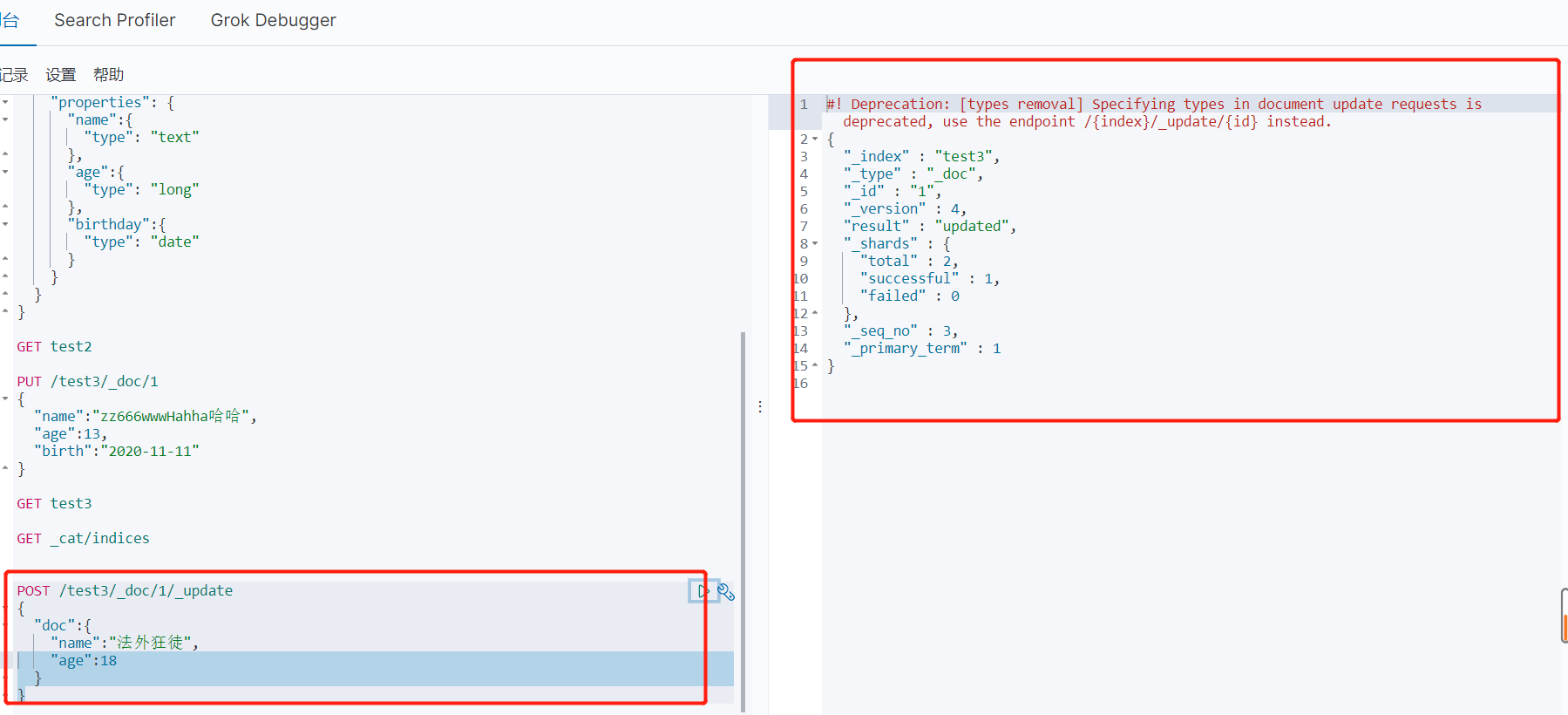
提交还是使用PUT即可!然后覆盖(曾经的方法)

版本号会变更 result会变成 “updated‘
现在的方法
删
关于文档的基本操作
基本操作
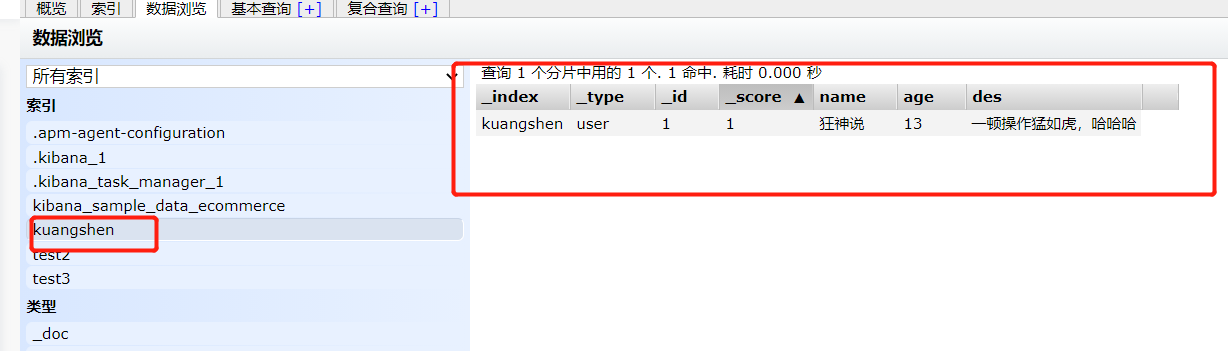
1、添加数据
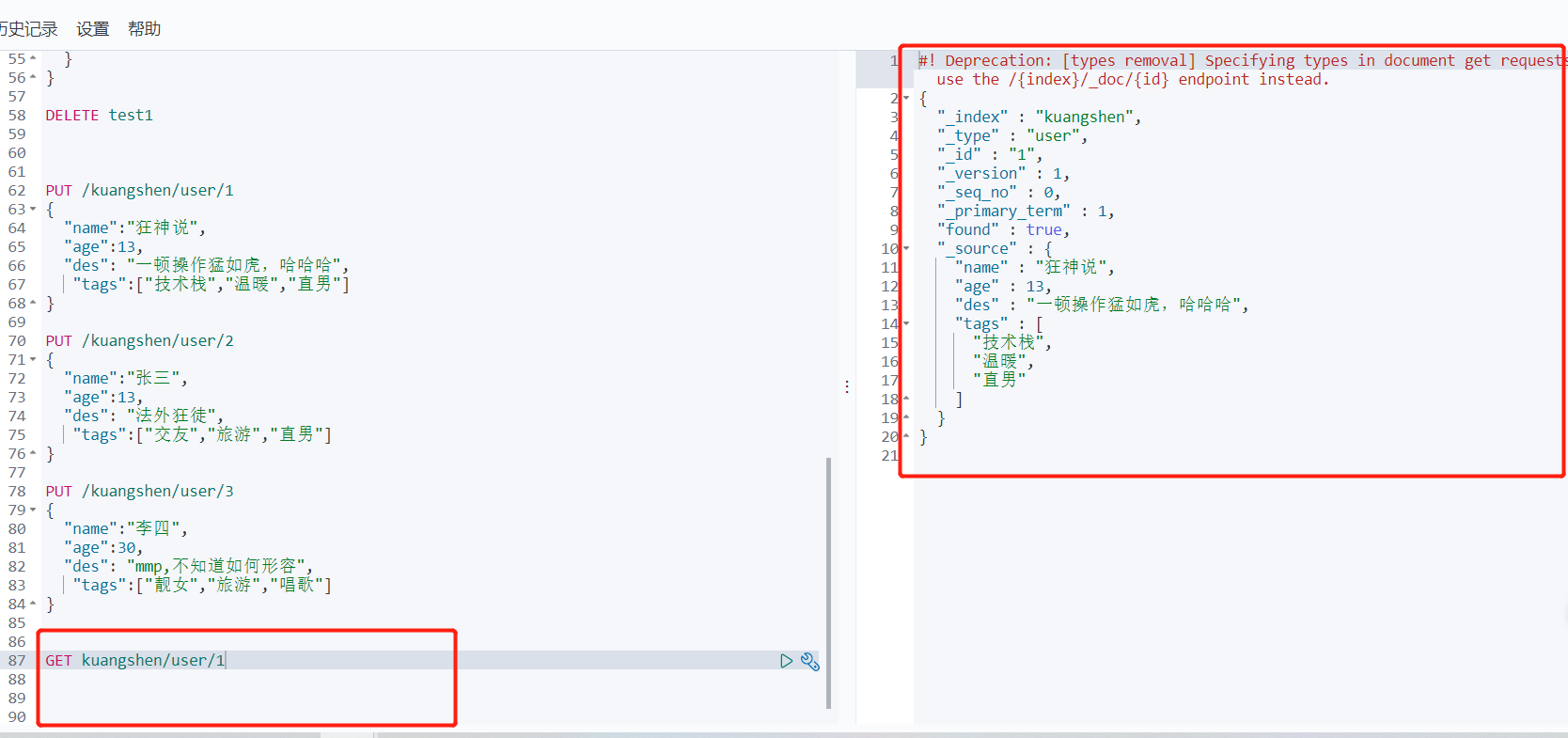
PUT /kuangshen/user/1
{
"name":"狂神说",
"age":13,
"des": "一顿操作猛如虎,哈哈哈",
"tags":["技术栈","温暖","直男"]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
put 和post _update
简单的搜索
GET kuangshen/user/1
- 1
按值匹配
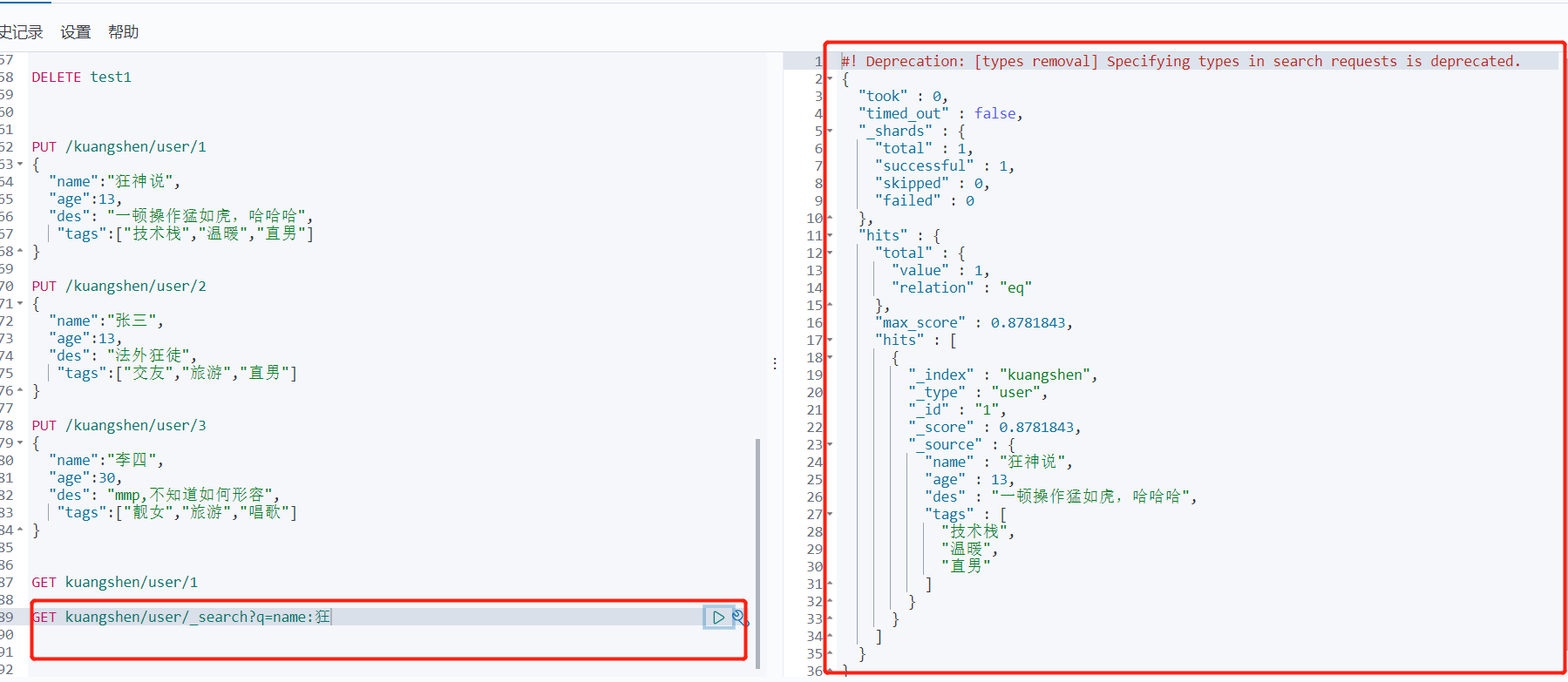
GET kuangshen/user/_search?q=name:狂神说
GET kuangshen/user/_search?q=name:狂
只要有一个关键字匹配了 都能显示结果 ,所以这是类似于mysql的模糊查询
- 1
- 2
- 3
- 4
简单的条件查询,可以根据默认的映射规则,产生基本的查询
复杂操作
GET kuangshen/user/_search
{
"query":{
"match": {
"name": "狂神"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
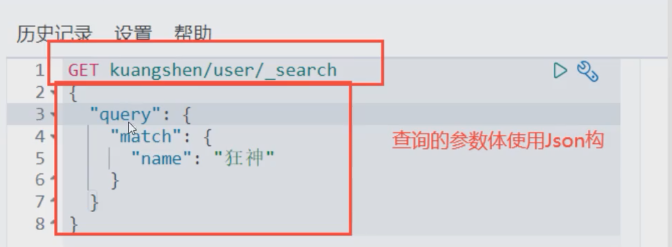
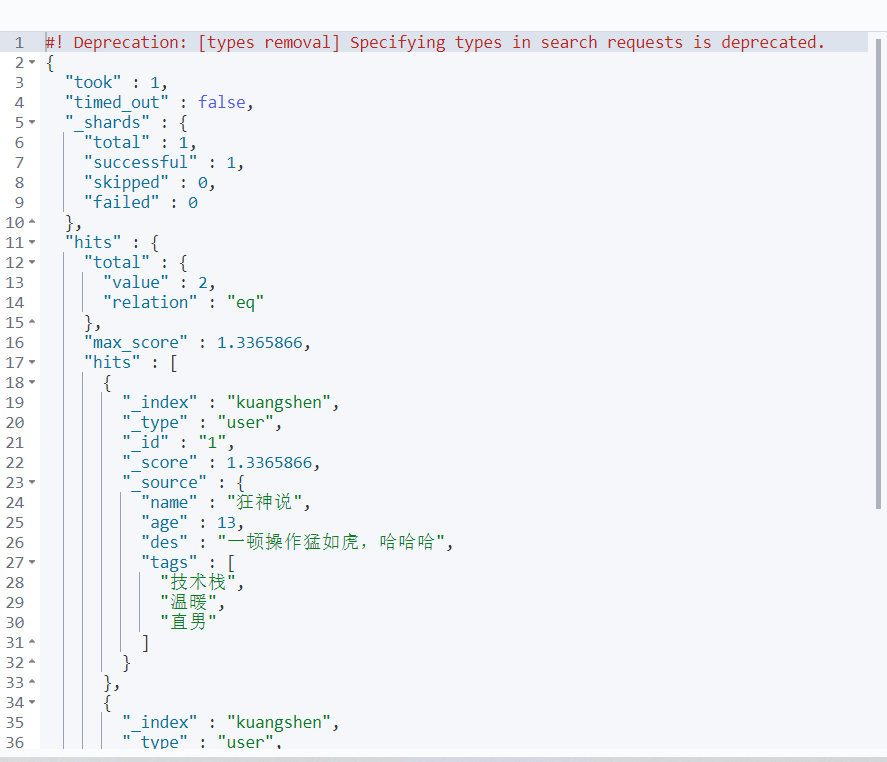
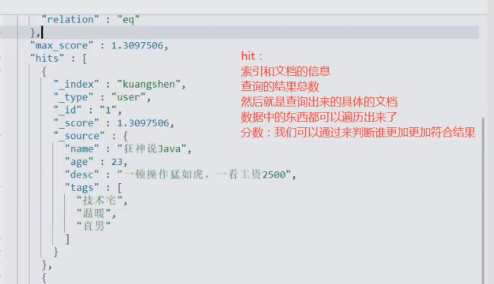
条件查询
根据条件查询,如果有多个字段 可以选择自己想要的字段得到 (结果过滤 相当于 select a ,b )而不是select *
GET kuangshen/user/_search
{
"query":{
"match": {
"name": "狂神"
}
},
"_source": ["name","des"]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
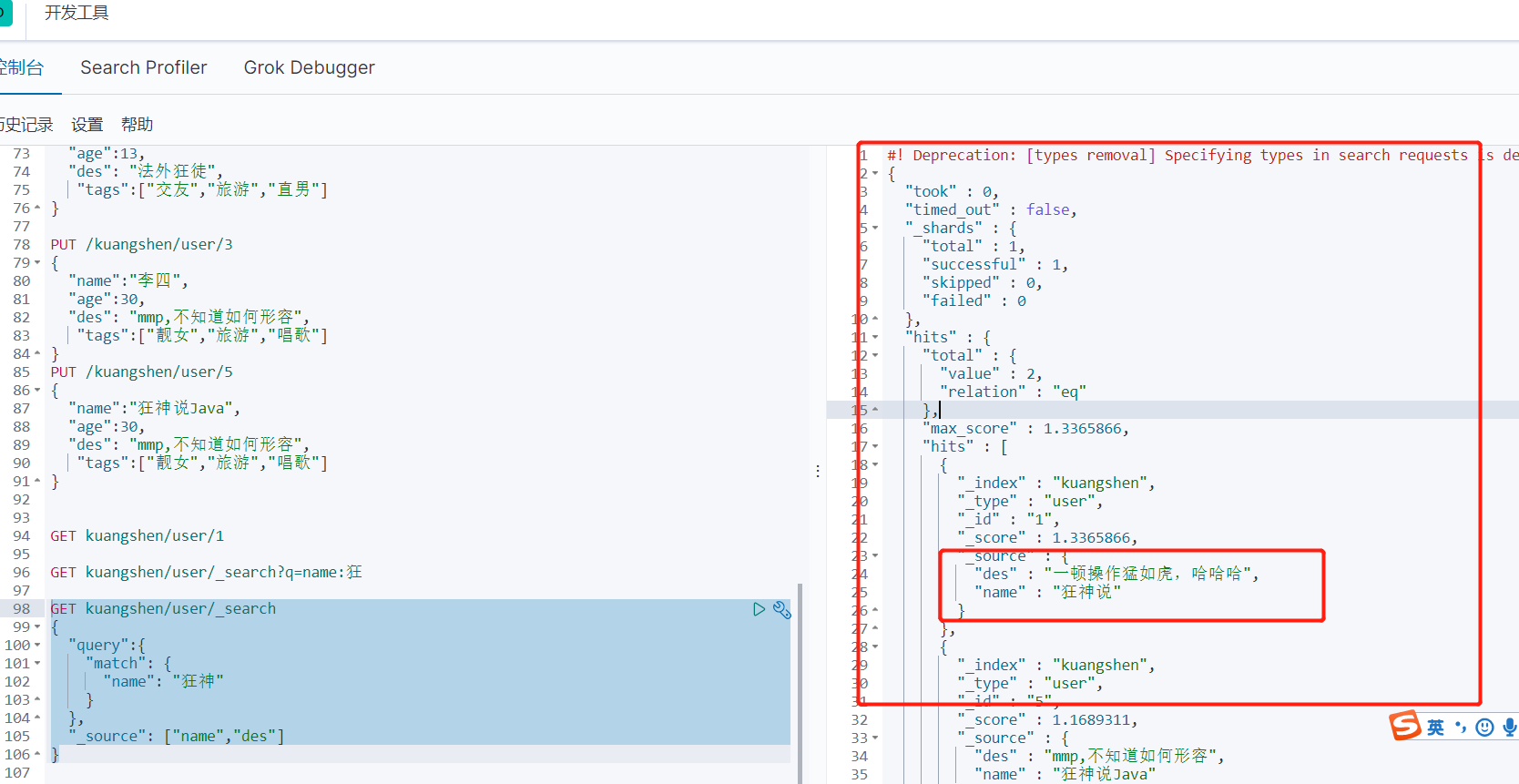
我们之后使用java操作es,所有的方法和对象就是这里面的key!
排序
GET kuangshen/user/_search
{
"query":{
"match": {
"name": "狂神"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这样就能通过某个字段来进行排序 注意了如果是排序的话 那么它的_score就会为null了没有对应的分数了
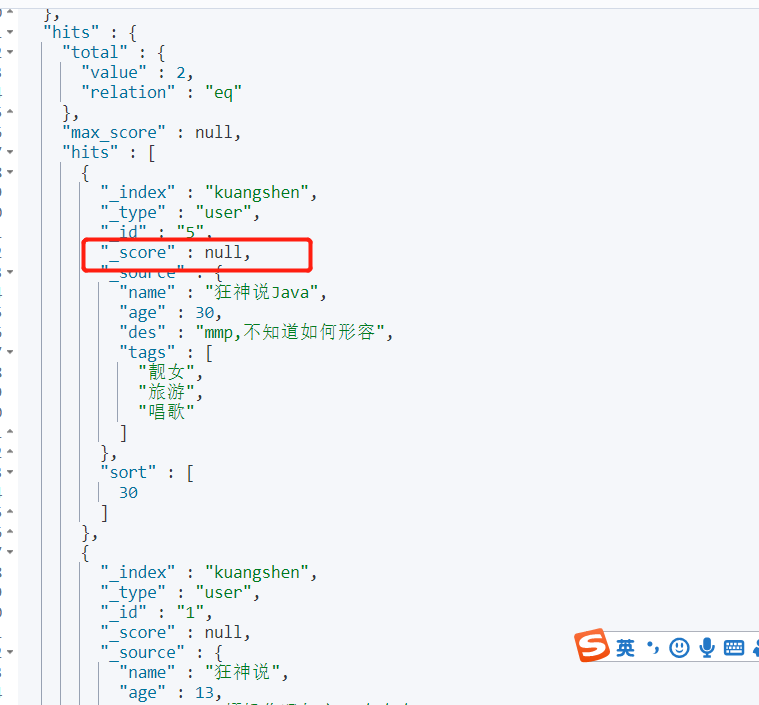
分页
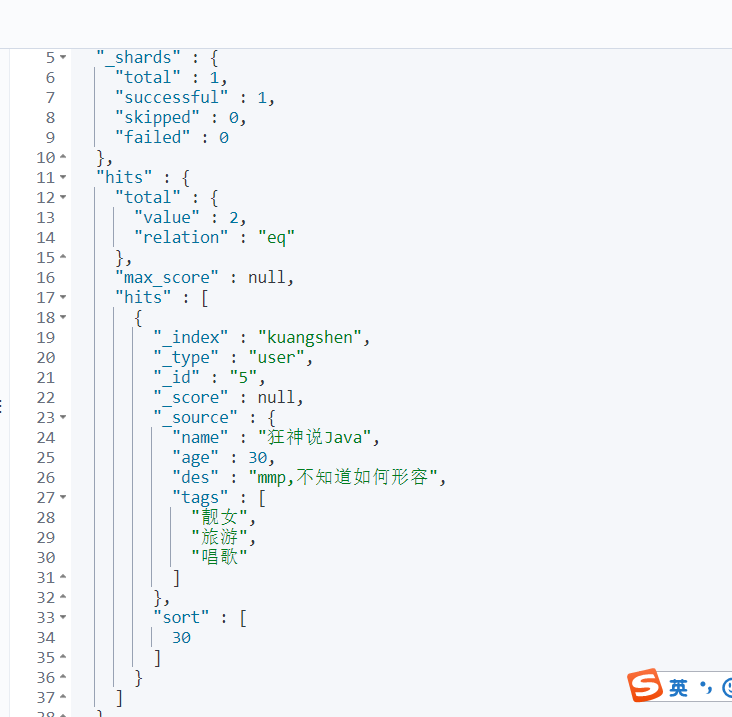
GET kuangshen/user/_search { "query":{ "match": { "name": "狂神" } }, "sort": [ { "age": { "order": "desc" } } ], "from": 0, 相当于mysql的limit 分页 "size": 1 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
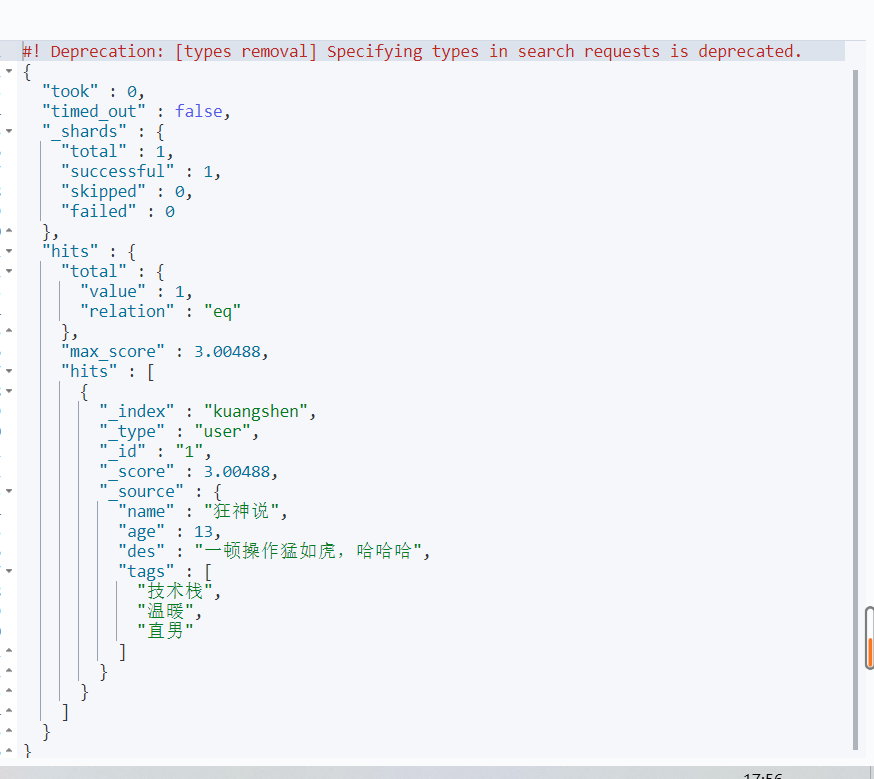
布尔值查询
布尔值查询
must命令 相当于mysql 中的(and),所有的条件都要符合 where id =1 and name=xxx
GET kuangshen/user/_search { "query": { "bool": { "must": [ { "match": { "name": "狂神说" } }, { "match": { "age": 13 } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
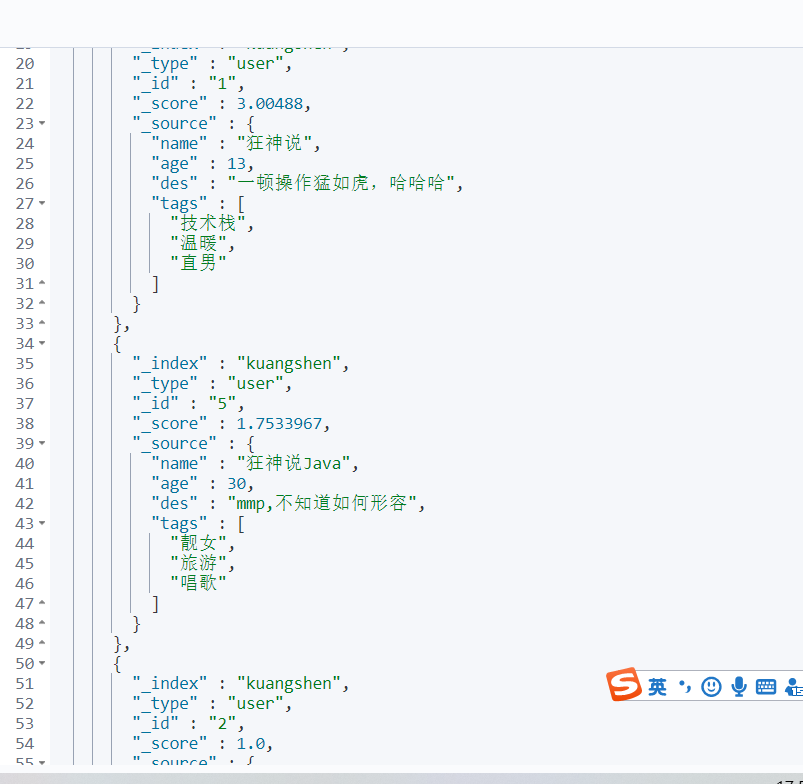
should命令 相当于mysql 中的(or),所有的条件都要符合 where id =1 and name=xxx
GET kuangshen/user/_search { "query": { "bool": { "should": [ { "match": { "name": "狂神说" } }, { "match": { "age": 13 } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
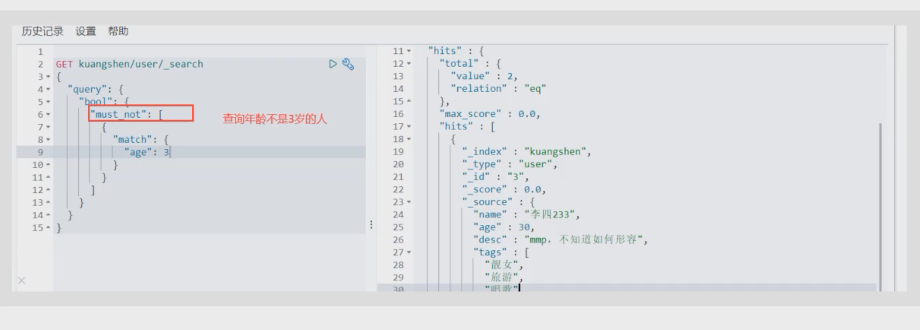
must_not
GET kuangshen/user/_search { "query": { "bool": { "must_not": [ { "match": { "name": "狂神说" } }, { "match": { "age": 13 } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
过滤
GET kuangshen/user/_search { "query": { "bool": { "must": [ { "match": { "name": "狂神" } } ], "filter": { "range": { "age": { "gte": 10, "lte": 20 } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
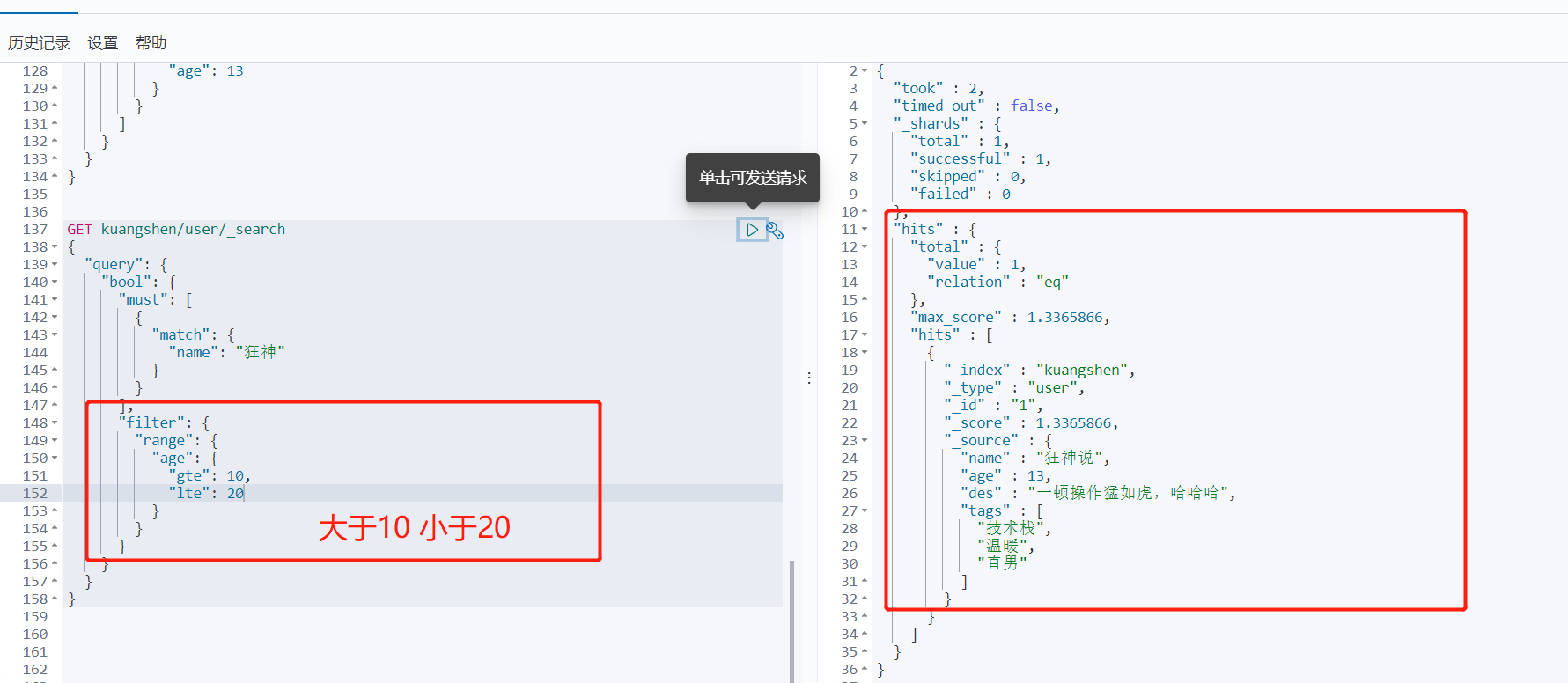
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
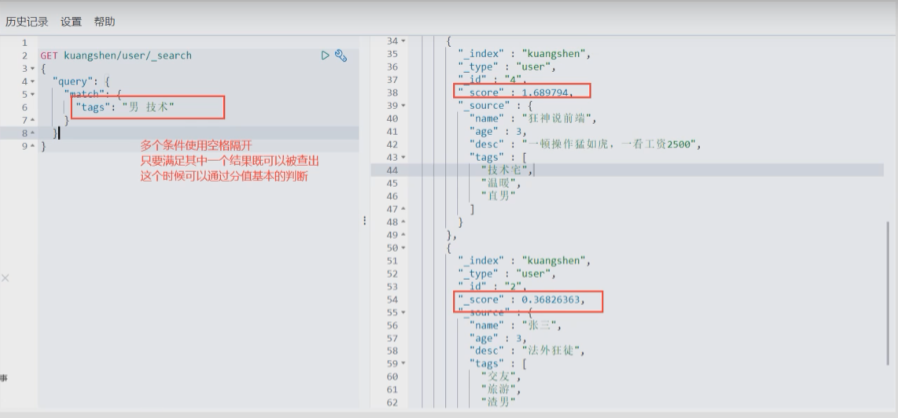
多值匹配
多值匹配
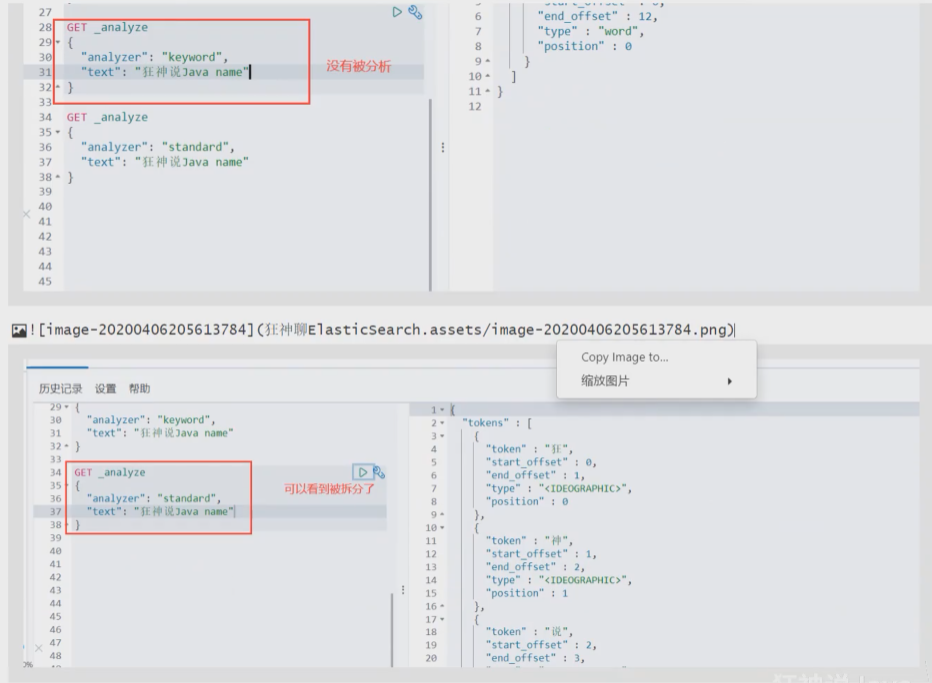
精确查询
term查询是直接通过倒排索引指定的词条进行精确的查找的!
关于分词:
- term,直接查询精确的
- match,会使用分词器解析!(先分析文档,然后再通过分析的文档进行查询)
两个类型 text keyword
text是可以被分词器解析的 而keyword是不会被分词解析的
#先创建索引先 PUT testdb { "mappings": { "properties": { "name":{ "type": "text" }, "desc":{ "type":"keyword" } } } } #插入值 PUT testdb/_doc/1 { "name":"狂神说Java name", "desc":"狂神说Java desc" } PUT testdb/_doc/2 { "name":"狂神说Java name", "desc":"狂神说Java desc2" } #调用分词器 GET _analyze { "analyzer": "keyword", "text": ["狂神说Java name"] } GET _analyze { "analyzer": "standard", "text": ["狂神说Java desc2"] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
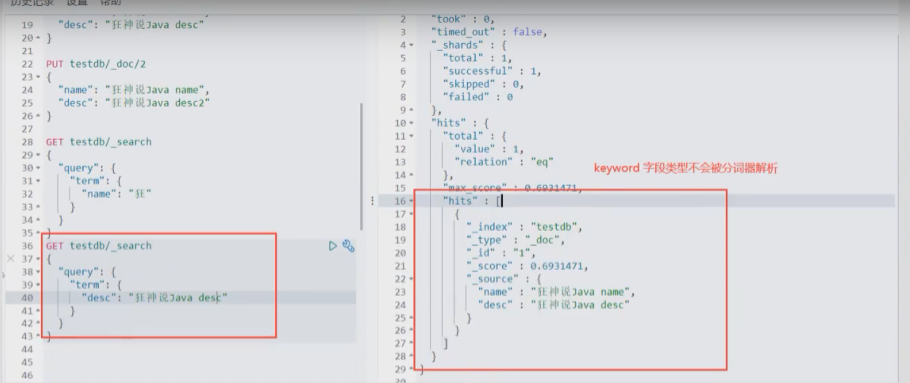
多个值匹配的精确查询
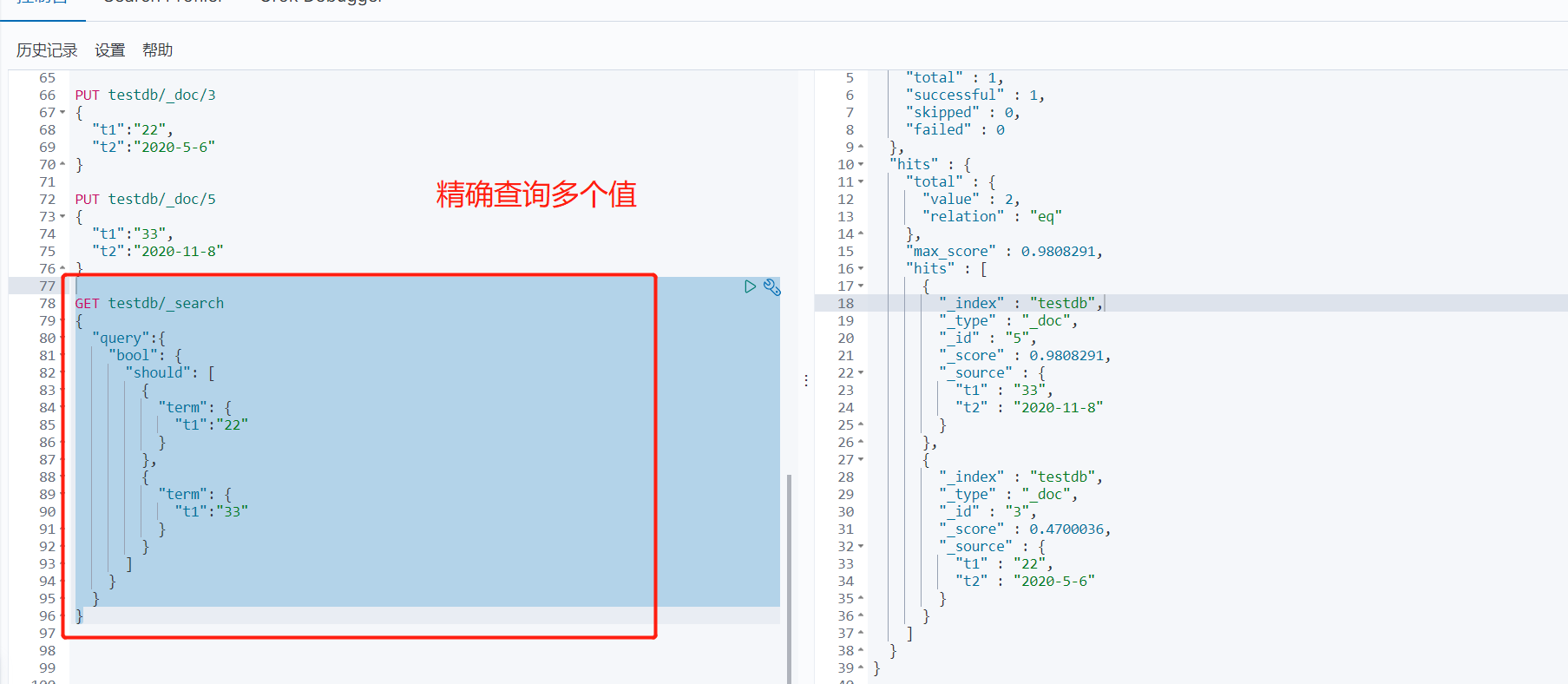
GET testdb/_search { "query":{ "bool": { "should": [ { "term": { "t1":"22" } }, { "term": { "t1":"33" } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
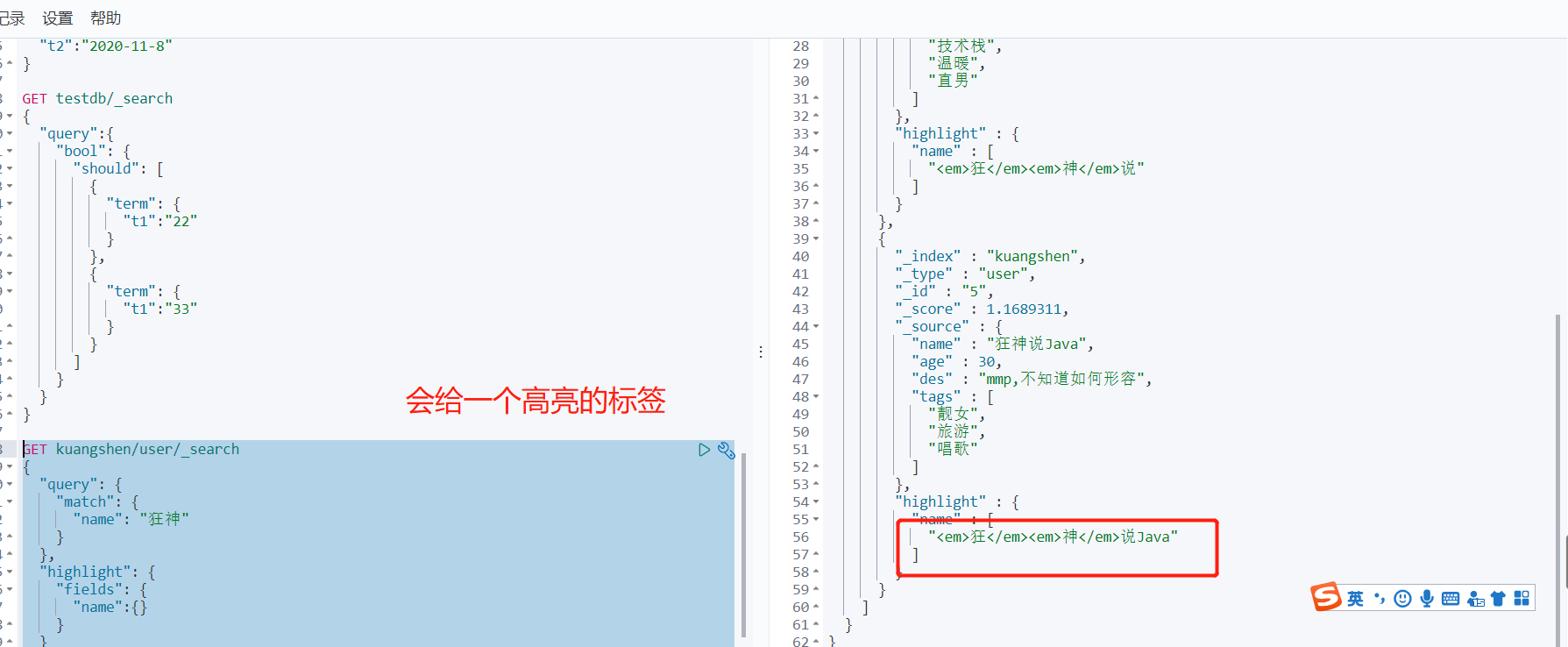
高亮查询
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
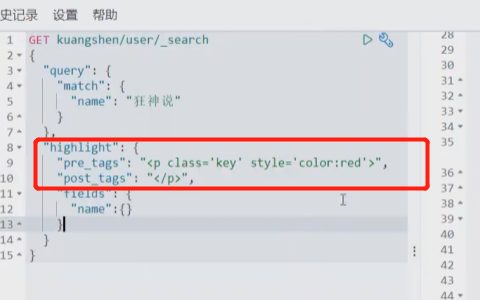
也可以自定义高亮的提示
聚合查询
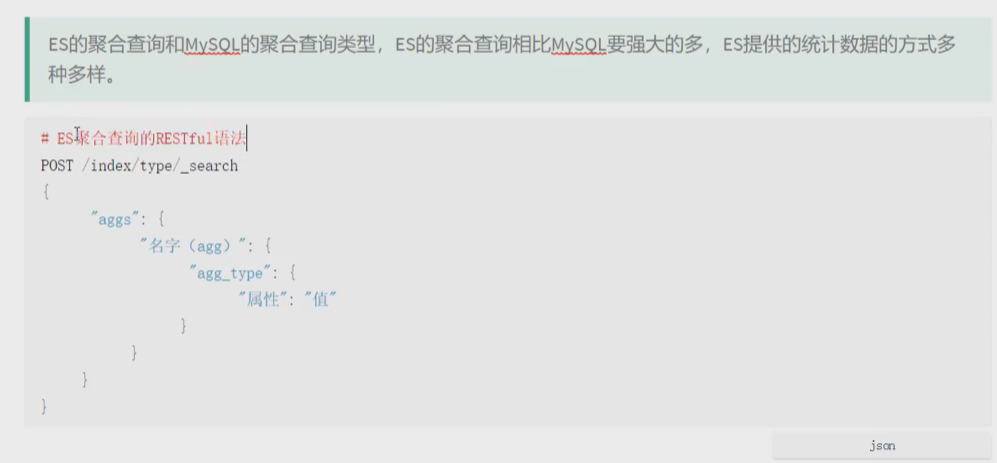
GET /cars/_mapping GET /cars/_search #不加.keyword就会报错 因为会被分词了 所以我们需要把他弄成不是分词的 #可能会注意到我们将 size 设置成 0 。我们并不关心搜索结果的具体内容,所以将返回记录数设置为 #来提高查询速度。 设置 size: 0 与 Elasticsearch 1.x 中使用 count 搜索类型等价。 #popular_colors 聚合是作为 aggregations 字段的一部分被返回的 #每个桶的 key 都与 color 字段里找到的唯一词对应。它总会包含 doc_count 字段,告诉我们包含该词项的文档数量。 #每个桶的数量代表该颜色的文档数量。 GET /cars/_search { "size": 0, "aggs": { "popular_colors": { "terms": { "field": "color.keyword" } } } } #多重聚合 GET /cars/_search { "size": 0, "aggs": { "colors": { "terms": { "field": "color.keyword" }, "aggs":{ "avg_price":{ "avg": { "field": "price" } } } } } } #不同颜色的车不同的价钱以及汽车制造厂商的聚合信息如下 #多重聚合 GET /cars/_search { "size": 0, "aggs": { "colors": { "terms": { "field": "color.keyword" }, "aggs":{ "avg_price":{ "avg": { "field": "price" } }, "make":{ "terms": { "field": "make.keyword" } } } } } } #红色车有四辆。 #红色车的平均售价是 $32,500 美元。 #其中三辆是 Honda 本田制造,一辆是 BMW 宝马制造
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
聚合生成条形图(histogram )
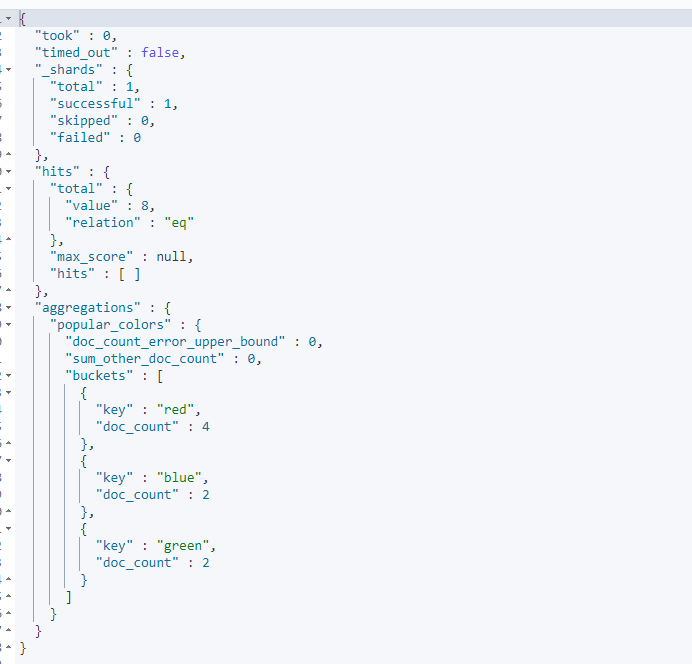
聚合还有一个令人激动的特性就是能够十分容易地将它们转换成图表和图形。本章中, 我们正在通过示例数据来完成各种各样的聚合分析,最终,我们将会发现聚合功能是非常强大的。
直方图 histogram 特别有用。 它本质上是一个条形图,如果有创建报表或分析仪表盘的经验,那么我们会毫无疑问的发现里面有一些图表是条形图。 创建直方图需要指定一个区间,如果我们要为售价创建一个直方图,可以将间隔设为 20,000。这样做将会在每个 $20,000 档创建一个新桶,然后文档会被分到对应的桶中。
对于仪表盘来说,我们希望知道每个售价区间内汽车的销量。我们还会想知道每个售价区间内汽车所带来的收入,可以通过对每个区间内已售汽车的售价求和得到。
可以用 histogram 和一个嵌套的 sum 度量得到我们想要的答案:
#条形图 interval 间隔(设置步长) revenue收益 GET /cars/_search { "size": 0, "aggs": { "price": { "histogram": { "field": "price", "interval": 20000 }, "aggs": { "revenue": { "sum": { "field": "price" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RCnT4tPI-1632227343533)(https://www.elastic.co/guide/cn/elasticsearch/guide/current/images/elas_28in01.png)]
详细地址
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_building_bar_charts.html#barcharts-histo1
使用date_histogram(进行时间分析生成直方图)
虽然通常的 histogram 都是条形图,但 date_histogram 倾向于转换成线状图以展示时间序列。 许多公司用 Elasticsearch 仅仅 只是为了分析时间序列数据。 date_histogram 分析是它们最基本的需要。
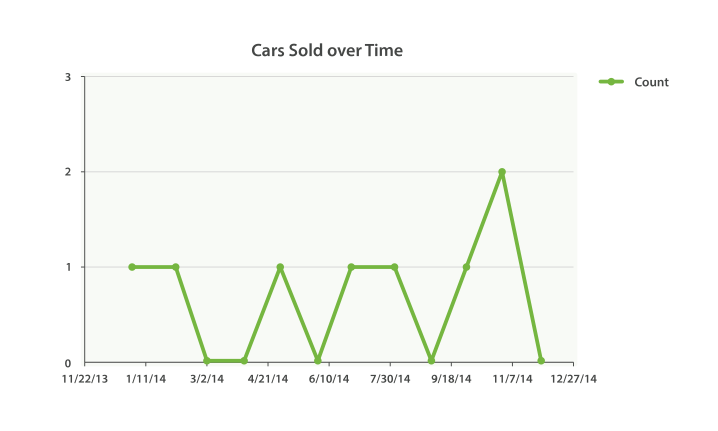

#每月销售多少台汽车
GET /cars/_search
{
"size": 0,
"aggs":{
"sales":{
"date_histogram": {
"field": "sold",
"interval": "month",
"format": "yyyy-MM-dd"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
还可以使用用通常的 histogram 进行时间分析吗?
从技术上来讲,是可以的。 通常的 histogram bucket(桶)是可以处理日期的。 但是它不能自动识别日期。 而用 date_histogram ,你可以指定时间段如 1 个月 ,它能聪明地知道 2 月的天数比 12 月少。 date_histogram 还具有另外一个优势,即能合理地处理时区,这可以使你用客户端的时区进行图标定制,而不是用服务器端时区。
通常的 histogram 会把日期看做是数字,这意味着你必须以微秒为单位指明时间间隔。另外聚合并不知道日历时间间隔,使得它对于日期而言几乎没什么用处
extended_stats
可以对聚合更进一步的分析(例如把min 、sum、avg等都计算出来)
GET /cars/_search { "size": 0, "aggs": { "makes": { "terms": { "field": "make.keyword" }, "aggs": { "stas": { "extended_stats": { "field": "price" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
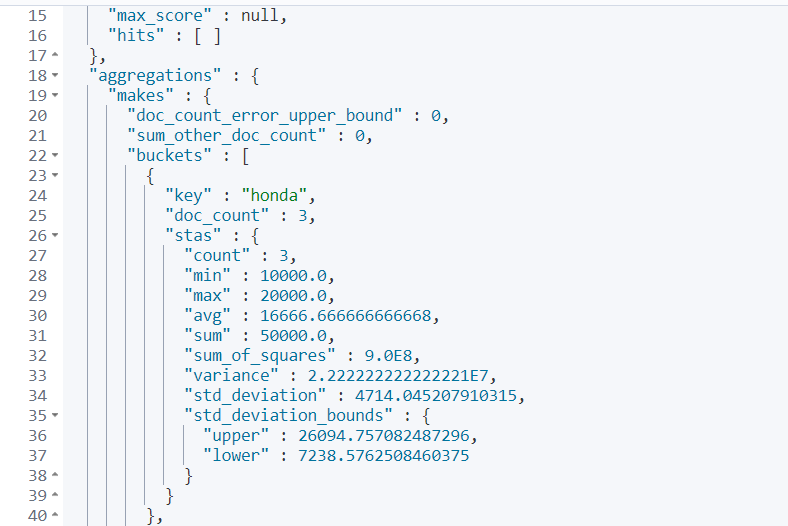
去重计数查询
POST /zkw_index/_doc/_search
{
"aggs": {
"agg":{
"cardinality":{
"field":"age"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
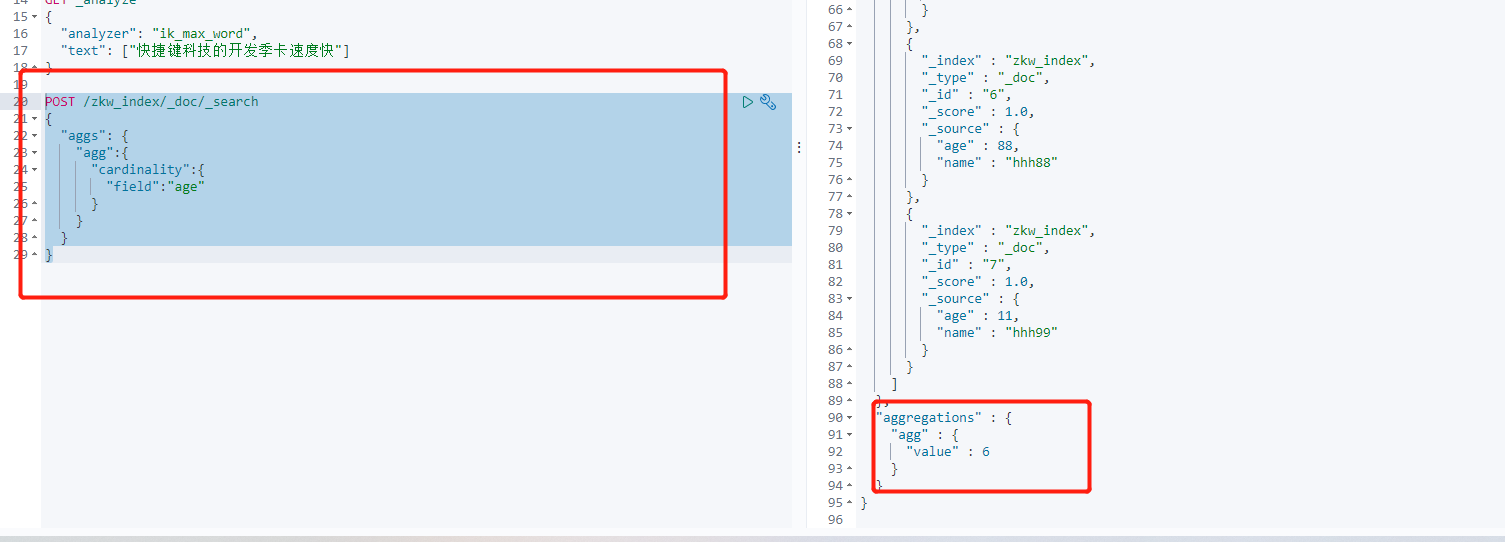
/** * 聚合查询方式 去重统计有多少数量 */ @Test void testCardinality() throws IOException { //先创建一个 SearchRequest request = new SearchRequest("zkw_index"); //指定使用的聚合查询方式 SearchSourceBuilder builder = new SearchSourceBuilder(); // builder.aggregation(AggregationBuilders.cardinality("统计结果").field("age")); request.source(builder); SearchResponse response = client.search(request, RequestOptions.DEFAULT); //获取返回结果 Cardinality agg = response.getAggregations().get("统计结果"); System.out.println(agg.getValue()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
范围统计
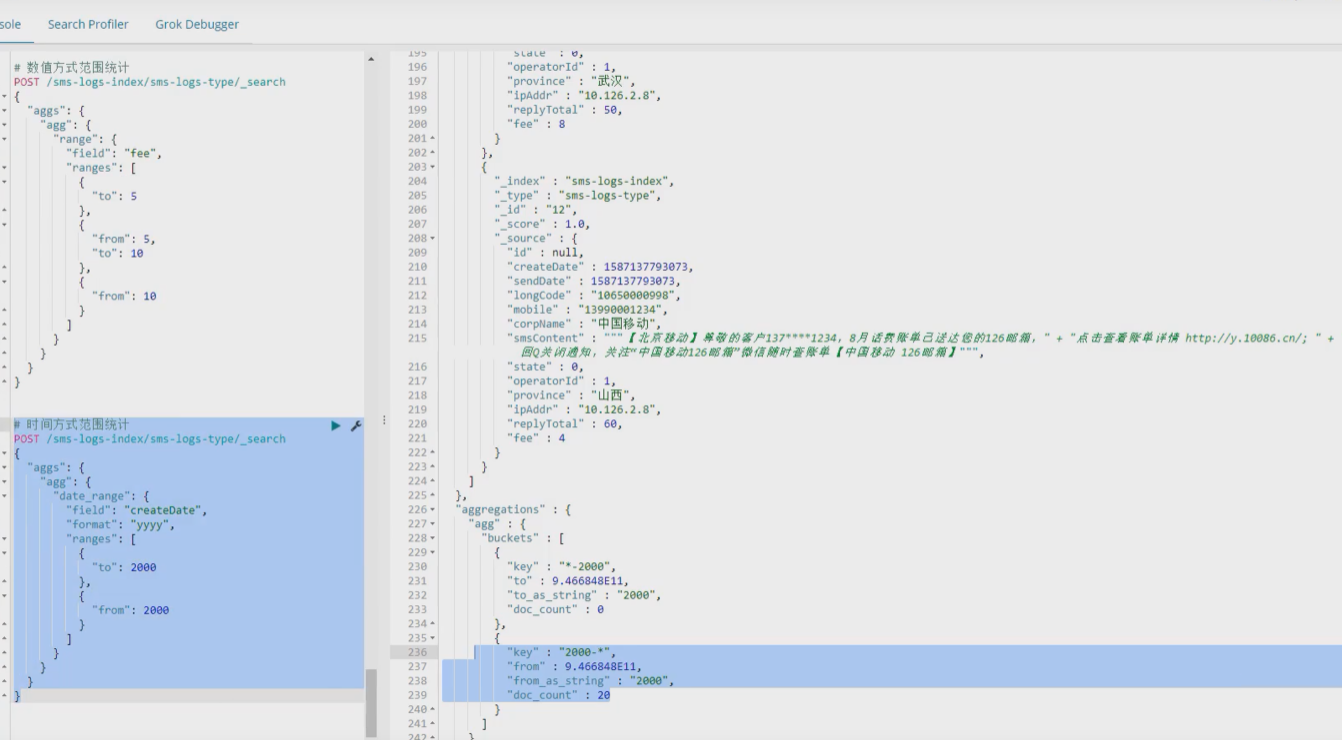
/** * 聚合查询 范围查询 */ @Test void testBbAA() throws IOException { //先创建一个 SearchRequest request = new SearchRequest("zkw_index"); //指定使用的聚合查询方式 SearchSourceBuilder builder = new SearchSourceBuilder(); // builder.aggregation(AggregationBuilders.range("统计结果").field("age") .addUnboundedTo(5) .addRange(5,10) .addUnboundedFrom(10) ); request.source(builder); SearchResponse response = client.search(request, RequestOptions.DEFAULT); //获取返回结果 Range agg = response.getAggregations().get("统计结果"); for (Range.Bucket bucket : agg.getBuckets()) { String keyAsString = bucket.getKeyAsString(); Object from = bucket.getFrom(); Object to = bucket.getTo(); long docCount = bucket.getDocCount(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
统计聚合查询
POST /zkw_index/_doc/_search
{
"aggs": {
"agg":{
"extended_stats":{
"field":"age"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
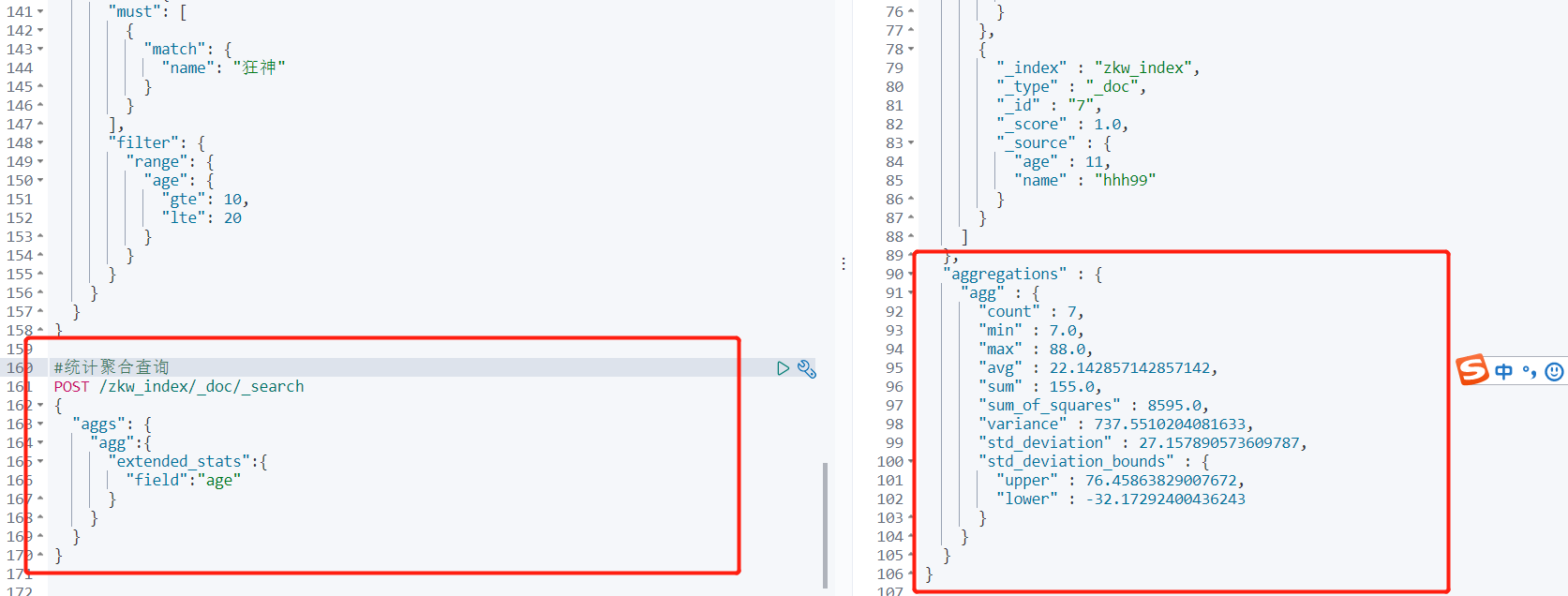
/** * 聚合查询方式 统计聚合查询某一个字段 */ @Test void testExtendedStats() throws IOException { //先创建一个 SearchRequest request = new SearchRequest("zkw_index"); //指定使用的聚合查询方式 SearchSourceBuilder builder = new SearchSourceBuilder(); // builder.aggregation(AggregationBuilders.extendedStats("统计结果").field("age")); request.source(builder); SearchResponse response = client.search(request, RequestOptions.DEFAULT); //获取返回结果 ExtendedStats agg = response.getAggregations().get("统计结果"); System.out.println(agg.getMax()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
经纬度检索

注意 得到数据都用GET 不要用post
geo_distance

geo_bounding_box

geo_polygon

match和term区别
匹配查询 match 是个 核心 查询。无论需要查询什么字段, match 查询都应该会是首选的查询方式。它是一个高级 全文查询 ,这表示它既能处理全文字段,又能处理精确字段。
上面这个是官方的原话,那么match也能进行精确的查询
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term。
举个例子说明一下:
{
"match": { "title": "my cat"}
}
{
"bool": {
"should": [
{ "term": { "title": "my" }},
{ "term": { "title": "cat" }}
]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
match 会将关键词进行分词分成“my”和“cat”,查找时包含其中任一均可被匹配到。
term结合bool使用,不进行分词,但是有2个关键词,并且使用“或”匹配,也就是会匹配关键字一“my”或关键字“cat”,效果和上面的match是相同的。如果要想精确的匹配“my cat”而不匹配“my lovely cat”,则可以如下方式匹配:
{
"bool": {
"should": [
{ "term": { "title": "my cat" }}
]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
是不是还挺简单的,有一点需要注意一下,term结合bool使用时:should是或,must是与,must_not是非(还有一种filter,不说了这个)
{ "match": { "title": { "query": "my cat", "operator": "and" } } } { "bool": { "must": [ { "term": { "title": "my" }}, { "term": { "title": "cat" }} ] } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上面这两个查询就是等效的,match的与对应bool的must,也就是说my和cat需要都出现才算匹配上。
模糊查询(fuzzy)
那么它可以显示搜索的结果,这是因为我们能够容许两个编辑的错误。
模糊性是拼写错误的简单解决方案,但具有很高的CPU开销和非常低的精度。
PUT fuzzyindex/_doc/1 { "content": "I like blue sky" } #这样查询不出来任何结果 GET fuzzyindex/_search { "query": { "match": { "content": "ski" } } } #那么它可以显示搜索的结果,这是因为我们能够容许两个编辑的错误。 #模糊性是拼写错误的简单解决方案,但具有很高的CPU开销和非常低的精度。 GET fuzzyindex/_search { "query": { "match": { "content": { "query": "ski", "fuzziness": "auto" } }} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
bool查询
GET /_search { "query": { "bool": { "should": [ { "match": { "title": "War and Peace" }}, { "match": { "author": "Leo Tolstoy" }}, { "bool": { "should": [ { "match": { "translator": "Constance Garnett" }}, { "match": { "translator": "Louise Maude" }} ] }} ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
为什么将译者条件语句放入另一个独立的 bool 查询中呢?所有的四个 match 查询都是 should 语句,所以为什么不将 translator 语句与其他如 title 、 author 这样的语句放在同一层呢?
答案在于评分的计算方式。 bool 查询运行每个 match 查询,再把评分加在一起,然后将结果与所有匹配的语句数量相乘,最后除以所有的语句数量。处于同一层的每条语句具有相同的权重。在前面这个例子中,包含 translator 语句的 bool 查询,只占总评分的三分之一。如果将 translator 语句与 title 和 author 两条语句放入同一层,那么 title 和 author 语句只贡献四分之一评分。
dis_max查询
不使用 bool 查询,可以使用 dis_max 即分离 最大化查询(Disjunction Max Query) 。分离(Disjunction)的意思是 或(or) ,这与可以把结合(conjunction)理解成 与(and) 相对应。分离最大化查询(Disjunction Max Query)指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回 :
实例地址:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_best_fields.html#dis-max-query
multi_match
跨字段的匹配可以使用这个 eg:比如说我想match “你好啊java”, 但是这个内容有可能在多个字段中存在 那如果重复bool 就会冗余了代码,那为什么不直接使用multi_match 让他跨字段来查询,而这个字段可以让我们自己控制。比如说在text 、content、blog 这三个字段下面查就能使用这个
multi_match 查询为能在多个字段上反复执行相同查询提供了一种便捷方式。
默认情况下,查询的类型是 best_fields ,这表示它会为每个字段生成一个 match 查询,然后将它们组合到 dis_max 查询的内部,如下:
{ "dis_max": { "queries": [ { "match": { "title": { "query": "Quick brown fox", "minimum_should_match": "30%" } } }, { "match": { "body": { "query": "Quick brown fox", "minimum_should_match": "30%" } } }, ], "tie_breaker": 0.3 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
上面这个查询用 multi_match 重写成更简洁的形式:
{
"multi_match": {
"query": "Quick brown fox",
"type": "best_fields",
"fields": [ "title", "body" ],
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
best_fields 类型是默认值,可以不指定。 | |
|---|---|
如 minimum_should_match 或 operator 这样的参数会被传递到生成的 match 查询中。 |
mult_match可以设置type 就是一种匹配的策略
这个类型可以有:(最佳字段)best_fields 、(跨字段)cross_fields、(多数字段)most_fields
https://www.cnblogs.com/bonelee/p/6827068.html
查询字段名称的模糊匹配
字段名称可以用模糊匹配的方式给出:任何与模糊模式正则匹配的字段都会被包括在搜索条件中,例如可以使用以下方式同时匹配 book_title 、 chapter_title 和 section_title (书名、章名、节名)这三个字段:
{
"multi_match": {
"query": "Quick brown fox",
"fields": "*_title"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
提升单个字段的权重
可以使用 ^ 字符语法为单个字段提升权重,在字段名称的末尾添加 ^boost ,其中 boost 是一个浮点数:
{
"multi_match": {
"query": "Quick brown fox",
"fields": [ "*_title", "chapter_title^2" ]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
chapter_title 这个字段的 boost 值为 2 ,而其他两个字段 book_title 和 section_title 字段的默认 boost 值为 1 。 | |
|---|---|
copy_to
copy来提高搜索的效率。比如在我们的搜索中,经常我们会遇到如下的文档:
{
"user" : "双榆树-张三",
"message" : "今儿天气不错啊,出去转转去",
"uid" : 2,
"age" : 20,
"city" : "北京",
"province" : "北京",
"country" : "中国",
"address" : "中国北京市海淀区",
"location" : {
"lat" : "39.970718",
"lon" : "116.325747"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在这里,我们可以看到在这个文档中,我们有这样的几个字段:
"city" : "北京",
"province" : "北京",
"country" : "中国",
- 1
- 2
- 3
它们是非常相关的。我们在想是不是可以把它们综合成一个字段,这样可以方便我们的搜索。假如我们要经常对这三个字段进行搜索,那么一种方法我们可以在must子句中使用should子句运行bool查询。这种方法写起来比较麻烦。有没有一种更好的方法呢?
我们其实可以使用Elasticsearch所提供的copy_to来提高我们的搜索效率。我们可以首先把我们的index的mapping设置成如下的项(这里假设我们使用的是一个叫做twitter的index)。
PUT twitter { "mappings": { "properties": { "address": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "age": { "type": "long" }, "city": { "type": "keyword", "copy_to": "region" }, "country": { "type": "keyword", "copy_to": "region" }, "province": { "type": "keyword", "copy_to": "region" }, "region": { "type": "text", "store": true }, "location": { "type": "geo_point" }, "message": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "uid": { "type": "long" }, "user": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
在这里,我们特别注意如下的这个部分:
"city": {
"type": "keyword",
"copy_to": "region"
},
"country": {
"type": "keyword",
"copy_to": "region"
},
"province": {
"type": "keyword",
"copy_to": "region"
},
"region": {
"type": "text"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们把city, country及province三个项合并成为一个项region,但是这个region并不存在于我们文档的source里。当我们这么定义我们的mapping的话,在文档被索引之后,有一个新的region项可以供我们进行搜索。
前缀匹配prefix
为了支持前缀匹配,查询会做以下事情:
- 扫描词列表并查找到第一个以
W1开始的词。 - 搜集关联的文档 ID 。
- 移动到下一个词。
- 如果这个词也是以
W1开头,查询跳回到第二步再重复执行,直到下一个词不以W1为止。
GET /my_index/_search
{
"query": {
"prefix": {
"postcode": {
"value": "W1"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这也意味着需要同样注意前缀查询存在性能问题,对有很多唯一词的字段执行这些查询可能会消耗非常多的资源,所以要避免使用左通配这样的模式匹配(如: *foo 或 .*foo 这样的正则式)。
通配符查询wildcard
与 prefix 前缀查询的特性类似, wildcard 通配符查询也是一种底层基于词的查询,与前缀查询不同的是它允许指定匹配的正则式。它使用标准的 shell 通配符查询: ? 匹配任意字符, * 匹配 0 或多个字符。
GET /my_index/_search
{
"query": {
"wildcard": {
"postcode": {
"value": "W?F*HW"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
即时性搜索
这里它会对他最后一个token就是字符类进行匹配
把邮编的事情先放一边,让我们先看看前缀查询是如何在全文查询中起作用的。用户已经渐渐习惯在输完查询内容之前,就能为他们展现搜索结果,这就是所谓的 即时搜索(instant search) 或 输入即搜索(search-as-you-type) 。不仅用户能在更短的时间内得到搜索结果,我们也能引导用户搜索索引中真实存在的结果。
例如,如果用户输入 johnnie walker bl ,我们希望在它们完成输入搜索条件前就能得到:Johnnie Walker Black Label 和 Johnnie Walker Blue Label 。
生活总是这样,就像猫的花色远不只一种!我们希望能找到一种最简单的实现方式。并不需要对数据做任何准备,在查询时就能对任意的全文字段实现 输入即搜索(search-as-you-type) 的查询。
在 短语匹配 中,我们引入了 match_phrase 短语匹配查询,它匹配相对顺序一致的所有指定词语,对于查询时的输入即搜索,可以使用 match_phrase 的一种特殊形式, match_phrase_prefix 查询:
{
"match_phrase_prefix" : {
"brand" : "johnnie walker bl"
}
}
- 1
- 2
- 3
- 4
- 5
拷贝为 cURL在 Sense 中查看
这种查询的行为与 match_phrase 查询一致,不同的是它将查询字符串的最后一个词作为前缀使用,换句话说,可以将之前的例子看成如下这样:
johnnie- 跟着
walker - 跟着以
bl开始的词
如果通过 validate-query API 运行这个查询查询,explanation 的解释结果为:
"johnnie walker bl*"
- 1
与 match_phrase 一样,它也可以接受 slop 参数(参照 slop )让相对词序位置不那么严格:
{
"match_phrase_prefix" : {
"brand" : {
"query": "walker johnnie bl",
"slop": 10
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
尽管词语的顺序不正确,查询仍然能匹配,因为我们为它设置了足够高的 slop 值使匹配时的词序有更大的灵活性。 | |
|---|---|
但是只有查询字符串的最后一个词才能当作前缀使用。
在之前的 前缀查询 中,我们警告过使用前缀的风险,即 prefix 查询存在严重的资源消耗问题,短语查询的这种方式也同样如此。前缀 a 可能会匹配成千上万的词,这不仅会消耗很多系统资源,而且结果的用处也不大。
可以通过设置 max_expansions 参数来限制前缀扩展的影响,一个合理的值是可能是 50 :
{
"match_phrase_prefix" : {
"brand" : {
"query": "johnnie walker bl",
"max_expansions": 50
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
参数 max_expansions 控制着可以与前缀匹配的词的数量,它会先查找第一个与前缀 bl 匹配的词,然后依次查找搜集与之匹配的词(按字母顺序),直到没有更多可匹配的词或当数量超过 max_expansions 时结束。
不要忘记,当用户每多输入一个字符时,这个查询又会执行一遍,所以查询需要快,如果第一个结果集不是用户想要的,他们会继续输入直到能搜出满意的结果为止。
按受欢迎程度提升权重
https://www.elastic.co/guide/cn/elasticsearch/guide/current/boosting-by-popularity.html
Ngrams
之前提到:“只能在倒排索引中找到存在的词。” 尽管 prefix 、 wildcard 、 regexp 查询告诉我们这种说法并不完全正确,但单个词的查找 确实 要比在词列表中盲目挨个查找的效率要高得多。在搜索之前准备好供部分匹配的数据可以提高搜索的性能。
在索引时准备数据意味着要选择合适的分析链,这里部分匹配使用的工具是 n-gram 。可以将 n-gram 看成一个在词语上 滑动窗口 , n 代表这个 “窗口” 的长度。如果我们要 n-gram quick 这个词 —— 它的结果取决于 n 的选择长度:
- 长度 1(unigram): [
q,u,i,c,k] - 长度 2(bigram): [
qu,ui,ic,ck] - 长度 3(trigram): [
qui,uic,ick] - 长度 4(four-gram): [
quic,uick] - 长度 5(five-gram): [
quick]
朴素的 n-gram 对 词语内部的匹配 非常有用,即在 Ngram 匹配复合词 介绍的那样。但对于输入即搜索(search-as-you-type)这种应用场景,我们会使用一种特殊的 n-gram 称为 边界 n-grams (edge n-grams)。所谓的边界 n-gram 是说它会固定词语开始的一边,以单词 quick 为例,它的边界 n-gram 的结果为:
qququiquicquick
可能会注意到这与用户在搜索时输入 “quick” 的字母次序是一致的,换句话说,这种方式正好满足即时搜索(instant search)!
补全提示(Completion Suggester)
使用边界 n-grams 进行输入即搜索(search-as-you-type)的查询设置简单、灵活且快速,但有时候它并不够快,特别是当试图立刻获得反馈时,延迟的问题就会凸显,很多时候不搜索才是最快的搜索方式。
Elasticsearch 里的 completion suggester 采用与上面完全不同的方式,需要为搜索条件生成一个所有可能完成的词列表,然后将它们置入一个 有限状态机(finite state transducer) 内,这是个经优化的图结构。为了搜索建议提示,Elasticsearch 从图的开始处顺着匹配路径一个字符一个字符地进行匹配,一旦它处于用户输入的末尾,Elasticsearch 就会查找所有可能结束的当前路径,然后生成一个建议列表。
本数据结构存于内存中,能使前缀查找非常快,比任何一种基于词的查询都要快很多,这对名字或品牌的自动补全非常适用,因为这些词通常是以普通顺序组织的:用 “Johnny Rotten” 而不是 “Rotten Johnny” 。
当词序不是那么容易被预见时,边界 n-grams 比完成建议者(Completion Suggester)更合适。即使说不是所有猫都是一个花色,那这只猫的花色也是相当特殊的。
基于深度优先或者广度优先的聚合
collect_mode 开启这两种模式只需要添加一个这样的参数
GET /cars/_search { "aggs" : { "actors" : { "terms" : { "field" : "actors", "size" : 10, "collect_mode": "breadth_first" }, "aggs" : { "costars" : { "terms" : { "field" : "actors", "size" : 5 } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_preventing_combinatorial_explosions.html
集成springboot
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/index.html
1、依赖
原生的依赖
<dependency>
<groupId> org.elasticsearch.client </ groupId>
<artifactId > elasticsearch -rest-high-level-client </ artifactId>
<version> 7.6.1 </ version>
</ dependency>
- 1
- 2
- 3
- 4
- 5
- 6
2、对象
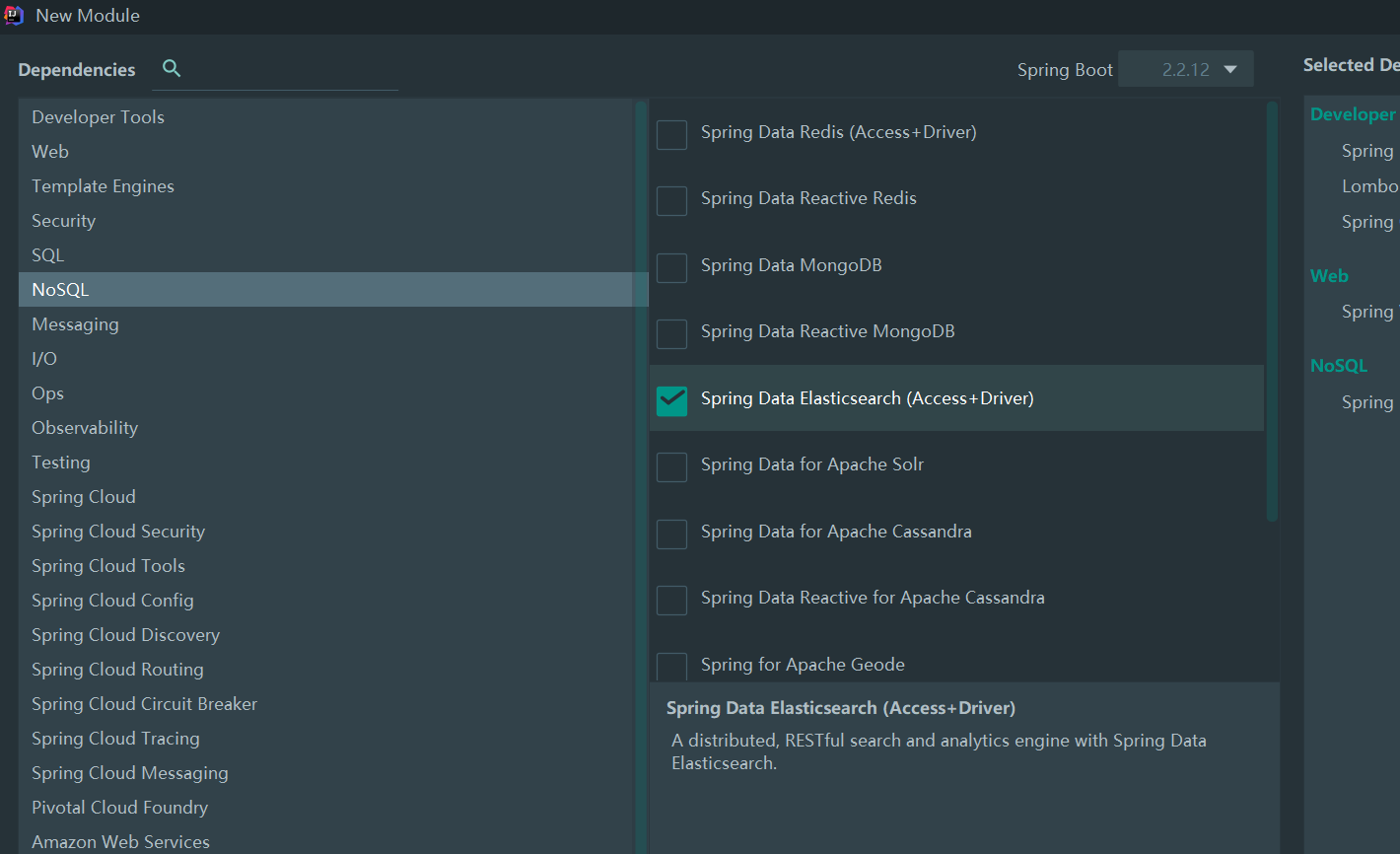
3、分析api
创建项目的时候记得勾选
springboot 2.2.5版本默认配置的es版本是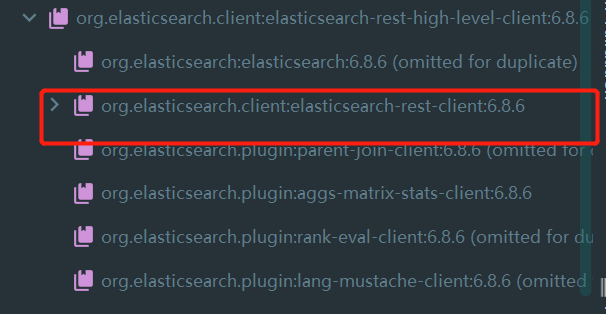
一定要保证我们导入的依赖和es版本一致
自定义ES版本依赖
<!--自定义es版本依赖,保证和本地一致-->
<properties>
<java.version>1.8</java.version>
<!--自定义es版本依赖,保证和本地一致-->
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
- 1
- 2
- 3
- 4
- 5
- 6

研究的话可以通过这里
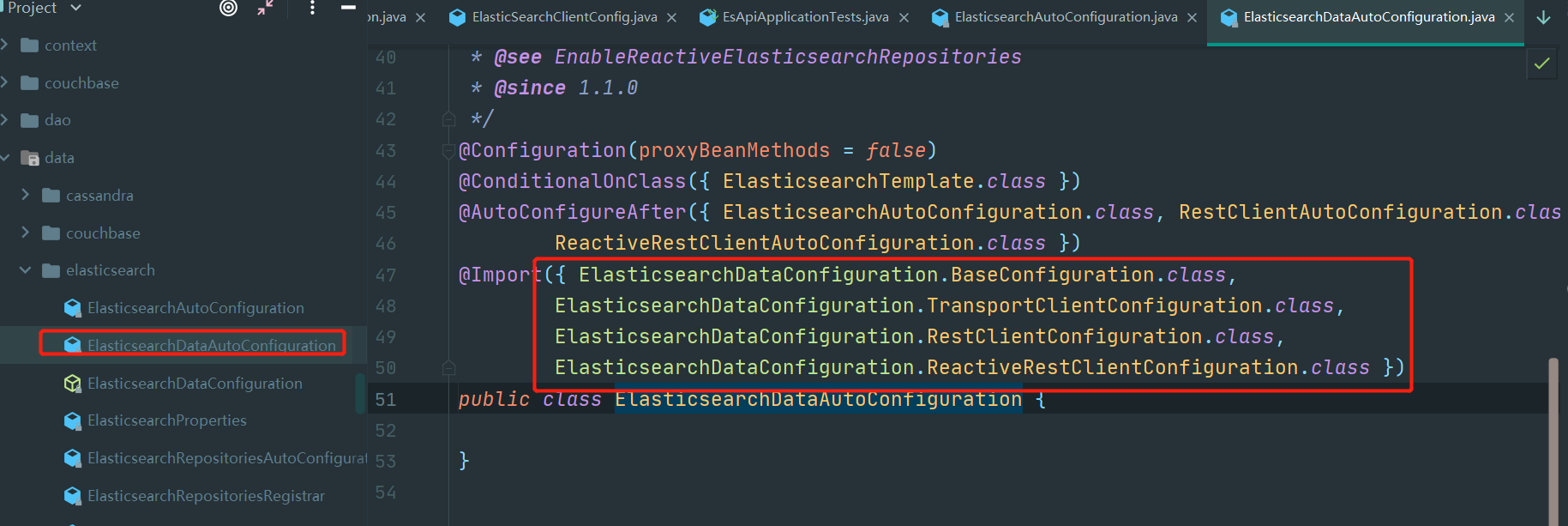
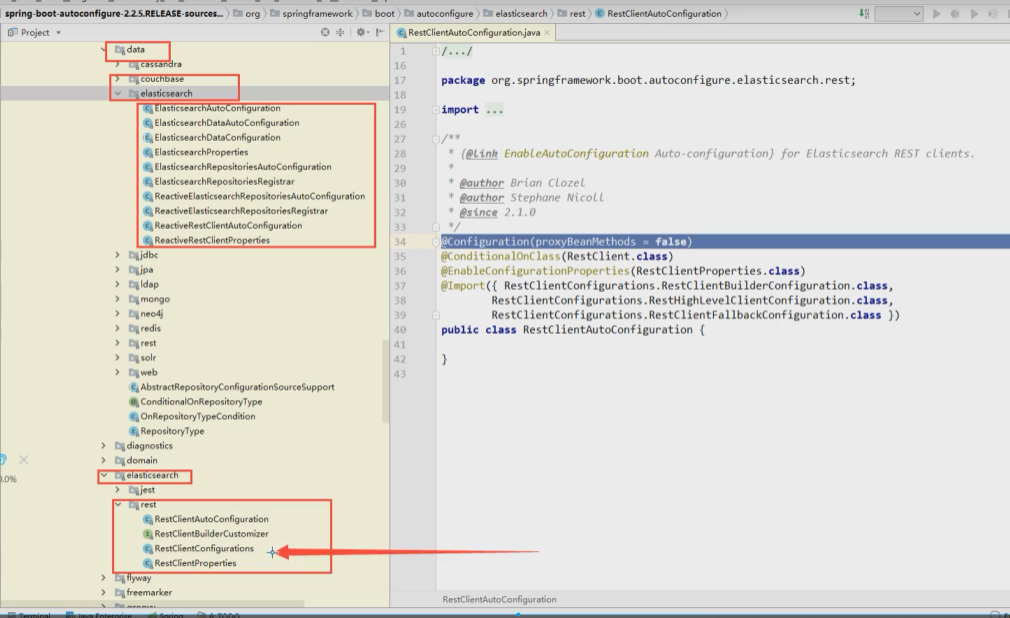
package org.springframework.boot.autoconfigure.elasticsearch.rest;
- 1
在这里面有3个bean
这里面的配置是有3个,其实都是在一个类里面的静态内部类
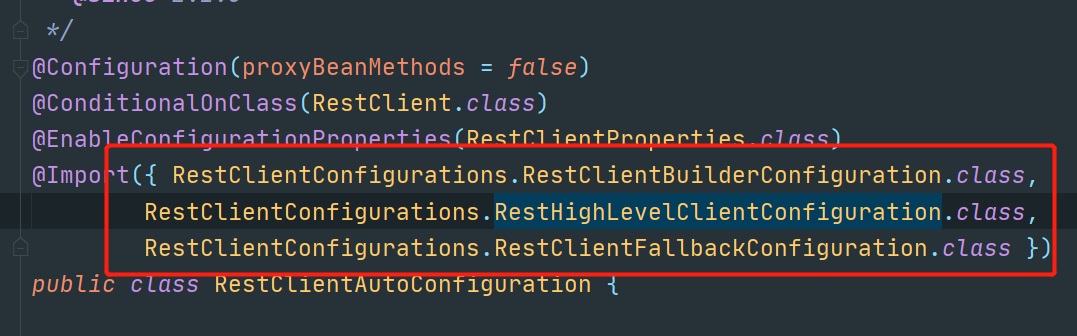
/* * Copyright 2012-2019 the original author or authors. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * https://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.springframework.boot.autoconfigure.elasticsearch.rest; import java.time.Duration; import org.apache.http.HttpHost; import org.apache.http.auth.AuthScope; import org.apache.http.auth.Credentials; import org.apache.http.auth.UsernamePasswordCredentials; import org.apache.http.client.CredentialsProvider; import org.apache.http.impl.client.BasicCredentialsProvider; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.beans.factory.ObjectProvider; import org.springframework.boot.autoconfigure.condition.ConditionalOnClass; import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean; import org.springframework.boot.context.properties.PropertyMapper; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * Elasticsearch rest client infrastructure configurations. * * @author Brian Clozel * @author Stephane Nicoll */ class RestClientConfigurations { @Configuration(proxyBeanMethods = false) static class RestClientBuilderConfiguration { @Bean @ConditionalOnMissingBean RestClientBuilder elasticsearchRestClientBuilder(RestClientProperties properties, ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) { HttpHost[] hosts = properties.getUris().stream().map(HttpHost::create).toArray(HttpHost[]::new); RestClientBuilder builder = RestClient.builder(hosts); PropertyMapper map = PropertyMapper.get(); map.from(properties::getUsername).whenHasText().to((username) -> { CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); Credentials credentials = new UsernamePasswordCredentials(properties.getUsername(), properties.getPassword()); credentialsProvider.setCredentials(AuthScope.ANY, credentials); builder.setHttpClientConfigCallback( (httpClientBuilder) -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)); }); builder.setRequestConfigCallback((requestConfigBuilder) -> { map.from(properties::getConnectionTimeout).whenNonNull().asInt(Duration::toMillis) .to(requestConfigBuilder::setConnectTimeout); map.from(properties::getReadTimeout).whenNonNull().asInt(Duration::toMillis) .to(requestConfigBuilder::setSocketTimeout); return requestConfigBuilder; }); builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(builder)); return builder; } } @Configuration(proxyBeanMethods = false) @ConditionalOnClass(RestHighLevelClient.class) static class RestHighLevelClientConfiguration { //RestHighLevelClient 高级客户端 ,也是我们项目会用到的额客户端 @Bean @ConditionalOnMissingBean RestHighLevelClient elasticsearchRestHighLevelClient(RestClientBuilder restClientBuilder) { return new RestHighLevelClient(restClientBuilder); } @Bean @ConditionalOnMissingBean RestClient elasticsearchRestClient(RestClientBuilder builder, ObjectProvider<RestHighLevelClient> restHighLevelClient) { RestHighLevelClient client = restHighLevelClient.getIfUnique(); if (client != null) { return client.getLowLevelClient(); } return builder.build(); } } @Configuration(proxyBeanMethods = false) static class RestClientFallbackConfiguration { //RestClient 普通客户端 @Bean @ConditionalOnMissingBean RestClient elasticsearchRestClient(RestClientBuilder builder) { return builder.build(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
创建索引
@Test
public void testCreateIndex() throws IOException {
//1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("zkw_index");
//2、客户端执行请求 client.indices() 这里返回了一个IndicesClient 请求后获得相应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
//得到org.elasticsearch.client.indices.CreateIndexResponse@52eb4d58
System.out.println(createIndexResponse);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
判断索引是否存在
/**
* 测试获取索引 ,判断其是否存在
*/
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
删除索引
/**
* 测试删除索引
* @throws IOException
*/
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("zkw_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
**=======================================================================================================**
添加文档
//测试添加文档 @Test void testAddDocument() throws IOException { //创建对象 User user = new User("来啦老弟", 3); //创建请求 IndexRequest request = new IndexRequest("zkw_index"); //规则 put/zkw_index/_doc/1 request.id("1"); request.timeout(TimeValue.timeValueSeconds(1)); request.timeout("1s"); //将我们的数据放入请求 json request.source(JSON.toJSONString(user), XContentType.JSON); //客户端发送请求 获取响应的结果 IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT); System.out.println(indexResponse.toString()); System.out.println(indexResponse.status()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
获取文档,判断是否存在
/**
* 获取文档,判断是否存在 get/index/doc/1
*/
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("zkw_index", "1");
//不获取返回的_source的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
获得文档的信息
/**
* 获得文档的信息
*/
@Test
void testGetDocument()throws IOException{
GetRequest getRequest = new GetRequest("zkw_index", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
//打印文档的内容
System.out.println(getResponse.getSourceAsString());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
更新文档的信息
/** * 更新文档的信息 */ @Test void testUpdateDocument() throws IOException { UpdateRequest updateRequest = new UpdateRequest("zkw_index", "1"); updateRequest.timeout("1s"); updateRequest.timeout(TimeValue.MINUS_ONE); User user = new User("啦啦啦啦", 18); updateRequest.doc(JSON.toJSONString(user),XContentType.JSON); UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT); System.out.println(update.status()); System.out.println(update.toString()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
删除文档
/**
* 删除文档的信息
*/
@Test
void testDeleteDocument() throws IOException{
DeleteRequest deleteRequest = new DeleteRequest("zkw_index");
deleteRequest.id("1");
DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(delete.toString());
System.out.println(delete.status());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
**=======================================================================================================**
批量插入
//特殊的,真的项目一般都会批量插入数据 @Test void testBankRequest() throws IOException { BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("10s"); ArrayList<User> userList = new ArrayList<>(); userList.add(new User("hhh",7)); userList.add(new User("hhh2",9)); userList.add(new User("hhh5",10)); userList.add(new User("hhh6",20)); userList.add(new User("hhh8",10)); userList.add(new User("hhh88",88)); userList.add(new User("hhh99",11)); //批处理请求 for (int i = 0; i < userList.size(); i++) { //批量更新和批量删除,就在这里修改对应的请求就可以了 bulkRequest.add(new IndexRequest("zkw_index") .id(""+(i+1)) .source(JSON.toJSONString(userList.get(i)),XContentType.JSON) ); } BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT); //是否失败, false 代表成功 System.out.println(bulkResponse.hasFailures()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
批量查询
/** * 查询 */ @Test void testSearch() throws IOException { SearchRequest searchRequest = new SearchRequest("zkw_index"); //构建搜索条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //QueryBuilders.termQuery 精确匹配 //QueryBuilders.matchAllQuery() 匹配所有 TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "hhh2"); sourceBuilder.query(termQueryBuilder); //可以设置分页 sourceBuilder.from(0); sourceBuilder.size(6); //设置超时时间 sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //最后放入到source中 searchRequest.source(sourceBuilder); SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); System.out.println(JSON.toJSONString(searchResponse.getHits())); System.out.println("=========================="); for (SearchHit hit : searchResponse.getHits()) { System.out.println("hit===="+hit); System.out.println("............."); System.out.println(hit.getSourceAsMap()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
yml 配置介绍
cluster.name: elasticsearch # 配置的集群名称,默认是elasticsearch,es服务会通过广播方式自动连接在同一网段下的es服务,通过多播方式进行通信,同一网段下可以有多个集群,通过集群名称这个属性来区分不同的集群。 node.name: "Franz Kafka" # 当前配置所在机器的节点名,你不设置就默认随机指定一个name列表中名字,该name列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。 node.master: true 指定该节点是否有资格被选举成为node(注意这里只是设置成有资格, 不代表该node一定就是master),默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。 node.data: true # 指定该节点是否存储索引数据,默认为true。 index.number_of_shards: 5 # 设置默认索引分片个数,默认为5片。 index.number_of_replicas: 1 # 设置默认索引副本个数,默认为1个副本。如果采用默认设置,而你集群只配置了一台机器,那么集群的健康度为yellow,也就是所有的数据都是可用的,但是某些复制没有被分配 # (健康度可用 curl 'localhost:9200/_cat/health?v' 查看, 分为绿色、黄色或红色。绿色代表一切正常,集群功能齐全,黄色意味着所有的数据都是可用的,但是某些复制没有被分配,红色则代表因为某些原因,某些数据不可用)。 path.conf: /path/to/conf # 设置配置文件的存储路径,默认是es根目录下的config文件夹。 path.data: /path/to/data # 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例: # path.data: /path/to/data1,/path/to/data2 path.work: /path/to/work # 设置临时文件的存储路径,默认是es根目录下的work文件夹。 path.logs: /path/to/logs # 设置日志文件的存储路径,默认是es根目录下的logs文件夹 path.plugins: /path/to/plugins # 设置插件的存放路径,默认是es根目录下的plugins文件夹, 插件在es里面普遍使用,用来增强原系统核心功能。 bootstrap.mlockall: true # 设置为true来锁住内存不进行swapping。因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内# # 存,linux下启动es之前可以通过`ulimit -l unlimited`命令设置。 network.bind_host: 192.168.0.1 # 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0,绑定这台机器的任何一个ip。 network.publish_host: 192.168.0.1 # 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。 network.host: 192.168.0.1 # 这个参数是用来同时设置bind_host和publish_host上面两个参数。 transport.tcp.port: 9300 # 设置节点之间交互的tcp端口,默认是9300。 transport.tcp.compress: true # 设置是否压缩tcp传输时的数据,默认为false,不压缩。 http.port: 9200 # 设置对外服务的http端口,默认为9200。 http.max_content_length: 100mb # 设置内容的最大容量,默认100mb http.enabled: false # 是否使用http协议对外提供服务,默认为true,开启。 gateway.type: local # gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器等。 gateway.recover_after_nodes: 1 # 设置集群中N个节点启动时进行数据恢复,默认为1。 gateway.recover_after_time: 5m # 设置初始化数据恢复进程的超时时间,默认是5分钟。 gateway.expected_nodes: 2 # 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。 cluster.routing.allocation.node_initial_primaries_recoveries: 4 # 初始化数据恢复时,并发恢复线程的个数,默认为4。 cluster.routing.allocation.node_concurrent_recoveries: 2 # 添加删除节点或负载均衡时并发恢复线程的个数,默认为4。 indices.recovery.max_size_per_sec: 0 # 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。 indices.recovery.concurrent_streams: 5 # 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。 discovery.zen.minimum_master_nodes: 1 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.ping.timeout: 3s # 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。 discovery.zen.ping.multicast.enabled: false # 设置是否打开多播发现节点,默认是true。 discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"] # 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。 # 7.x加入的配置 discovery.seed_hosts cluster.initial_master_nodes #官方给的例子 discovery.seed_hosts: - 192.168.1.10:9300 - 192.168.1.11 - seeds.mydomain.com cluster.initial_master_nodes: - master-node-a - master-node-b - master-node-c
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
实战
爬虫
<!--解析网页 爬音乐 爬影音可以用tika包-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
搜索高亮
Linux下安装ES
1.下载Elasticsearch
这里直接通过命令下载,也可以通过Elasticsearch官网下载,(本文以Elasticsearch7.6版本示例,请提前配置好java环境)
//下载Elasticsearch安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz
12
- 1
- 2
- 3
2.解压安装包
tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz
1
- 1
- 2
3.修改elasticsearch.yml 配置文件
//1.进去elasticsearch的config目录下
cd elasticsearch-7.6.2/config/
//2.修改elasticsearch.yml文件
vim elasticsearch.yml
//3.在文件末尾处添加如下配置 注意每个配置前的一个空格、每个配置:后的一个空格
network.host: 0.0.0.0 #可远程访问
node.name: es-node01 #节点名称 这个与下面一点一定要配,不然即使启动成功也会操作超时或发生master_not_discovered_exception
cluster.initial_master_nodes: ["es-node01"] #发现当前节点名称
http.port: 9200 #端口号
http.cors.allow-origin: "*" #以下皆是跨域配置
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.启动(不出意外会启动失败)
//1.进入elasticsearch的bin目录中
cd elasticsearch-7.6.1/bin/
//2.启动
直接启动:./elasticsearch
后台启动:./elasticsearch -d
12345
- 1
- 2
- 3
- 4
- 5
- 6
5.验证
浏览器输入:http://xxxx:9200/,返回如下:

运行问题处理
问题一:[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
//下面操作需要root权限
//1.修改配置文件limit.conf
vim /etc/security/limits.conf
//2.文件末尾添加 注意*代表所有用户
* hard nofile 65536
* soft nofile 131072
//3.保存退出后重启 查看,是否生效 生效就行
ulimit -Hn
ulimit -Sn
123456789
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
问题二:[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
//需要root权限
//1.修改配置文件sysctl.conf
vim /etc/sysctl.conf
//2.文件末尾处添加或修改
vm.max_map_count=262144
//3.保存退出后使之生效
sysctl -p
1234567
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
问题三: 启动后的权限问题:elasticsearch不允许root用户启动,所以需要添加其他用户,用其他用户来启动(已经有其他用户的可以无视)
//1.添加用户和设置密码
adduser 用户名
passwd 用户名
//2.给新用户授权elasticsearch文件的操作权限
chown 用户名 elasticsearch目录 -R
如:chown es /usr/local/elasticsearch-7.2.0/ -R
//3.切换用户启动
1234567
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
解决以上问题后再重复启动的操作即可
问题四: 能启动成功,并且能访问,但操作不了索引,出现超时或master_not_discovered_exception问题
这个问题是配置文件节点没配置好。。。(至少我是)
1
- 1
- 2
docker安装ES
安装ES
sudo docker pull elasticsearch:7.6.1
安装kibana
sudo docker pull kibana:7.6.1
然后使用 free -m来查看还有多大的内存
创建两个目录 用来挂载docker镜像里面的东西、不会让丢失数据
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
配置(ps注意这里的host: 0.0.0.0一定要有个空格)
sudo echo “http.host: 0.0.0.0”>>/mydata/elasticsearch/config/elasticsearch.yml
启动命令
docker run --name es01 -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms128m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.6.1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行docker ps
发现没启动成功可以使用docker logs elasticsearch 查看日志
docker logs elasticsearch
#递归修改用户的全写 可执行可读可写
chmod -R 777 /mydata/elasticsearch/
- 1
- 2
- 3
启动kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://120.25.220.74:9200 -p 5601:5601 -d kibana:7.6.1
- 1
Ik分词器插件安装
安装前: 用命令行执行以下命令
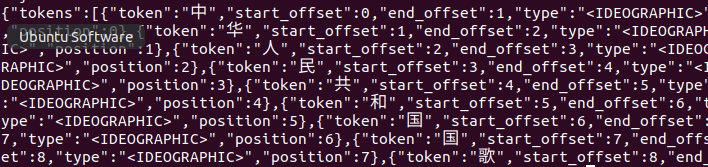
curl -H "Content-Type: application/json" -XPOST http://localhost:9200/_analyze -d'
{
"text":"中华人民共和国国歌"
}'
1234
- 1
- 2
- 3
- 4
- 5
返回如下: 可以看到他按照每个字来分割了,这样很明显是不合理的,因为这样做分词搜索,只要有一个字是匹配的就会返回
安装后: 执行以下命令
curl -H "Content-Type: application/json" -XPOST http://localhost:9200/_analyze -d'
{
"analyzer":"ik_smart", //这里是指定使用ik分词器分词
"text":"中华人民共和国国歌"
}'
12345
- 1
- 2
- 3
- 4
- 5
- 6
返回如下: 可以看到按照了词组来分词

ik分词安装
//1.下载ik分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases 进去下载选择与elasticsearch对应的版本
//2.进入elasticsearch安装目录下的plugins下,创建ik文件夹
cd elasticsearch-7.6.2/plugins/
mkdir ik
//3.将下载好的zip包放入ik文件夹下,执行解压
如:unzip elasticsearch-analysis-ik-7.2.0.zip
//4.重启elasticsearch服务
//5.验证
浏览器输入http://xx.xx.xx.xx:9200/_cat/plugins
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
返回如下: 就成功了

可视化工具kibana安装
//1.下载对应elasticsearch版本的kibana wget https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux-x86_64.tar.gz //2.解压 tar -zxvf kibana-6.3.2-linux-x86_64.tar.gz //3.修改配置文件 cd kibana-7.2.0-linux-x86_64/config/ vim kibana.yml //4.将下列注释打开 server.port: 5601 #端口号 server.host: "0.0.0.0" #远程访问 elasticsearch.host: "http://xxxx:9200" #elasticsearch地址 kibana.index: ".kibana" #索引规则配置 打开注释即可 //启动 cd kibana-7.2.0-linux-x86_64/bin/ ./kibana chown -R zkw:zkw /home/zkw/zkwPackges/usr/es/kibana-7.6.1-linux-x86_64/ 如果有问题加上这个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
浏览器输入:http://xxx:5601 访问即可,至于对elasticsearch的操作这里就不在阐述了

ES集群搭建
一、准备两个elasticsearch-7.6.1的解压包
注意这里面如果你之前的是复制上一份的解压包并且解压包里面有数据一定要删除否则集群搭建不成功!!!!!

单机搭建:https://blog.csdn.net/qq_39381529/article/details/107058116

二、配置集群节点
node0节点
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: my-esCluster # 设置节点名称,集群内节点名称必须唯一。 node.name: node0 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 #path.data: /opt/elasticsearch/data # 日志文件存放的位置 #path.logs: /opt/elasticsearch/logs # 需求锁住物理内存,是:true、否:false #bootstrap.memory_lock: true # 监听地址,用于访问该es network.host: 127.0.0.1 # es对外提供的http端口,默认 9200 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node0", "node1"] # 是否支持跨域,是:true,在使用head插件时需要此配置 http.cors.enabled: true # “*” 表示支持所有域名 http.cors.allow-origin: "*"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
node1节点
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: my-esCluster # 设置节点名称,集群内节点名称必须唯一。 node.name: node1 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 #path.data: /opt/elasticsearch/data # 日志文件存放的位置 #path.logs: /opt/elasticsearch/logs # 需求锁住物理内存,是:true、否:false #bootstrap.memory_lock: true # 监听地址,用于访问该es network.host: 127.0.0.1 # es对外提供的http端口,默认 9200 http.port: 9201 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9301 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node0", "node1"] # 是否支持跨域,是:true,在使用head插件时需要此配置 http.cors.enabled: true # “*” 表示支持所有域名 http.cors.allow-origin: "*"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
三、启动两个elasticsearch和elasticsearch-heard


elasticsearch-heard启动

四、访问 elasticsearch-hear查看集群是否配置成功
出现如下图说明配置成功

上面的是windows的搭建,linux搭建原理相同
ES集群分布式搭建
节点0
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: my-esCluster # 设置节点名称,集群内节点名称必须唯一。 node.name: node0 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 #path.data: /opt/elasticsearch/data # 日志文件存放的位置 #path.logs: /opt/elasticsearch/logs # 需求锁住物理内存,是:true、否:false #bootstrap.memory_lock: true # 监听地址,用于访问该es network.host: 192.168.5.36 # es对外提供的http端口,默认 9200 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["192.168.5.36:9300", "192.168.5.33:9301"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node0", "node1"] # 是否支持跨域,是:true,在使用head插件时需要此配置 http.cors.enabled: true # “*” 表示支持所有域名 http.cors.allow-origin: "*"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
节点1
# 设置集群名称,集群内所有节点的名称必须一致。 cluster.name: my-esCluster # 设置节点名称,集群内节点名称必须唯一。 node.name: node0 # 表示该节点会不会作为主节点,true表示会;false表示不会 node.master: true # 当前节点是否用于存储数据,是:true、否:false node.data: true # 索引数据存放的位置 #path.data: /opt/elasticsearch/data # 日志文件存放的位置 #path.logs: /opt/elasticsearch/logs # 需求锁住物理内存,是:true、否:false #bootstrap.memory_lock: true # 监听地址,用于访问该es network.host: 192.168.5.33 # es对外提供的http端口,默认 9200 http.port: 9200 # TCP的默认监听端口,默认 9300 transport.tcp.port: 9300 # 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2 # es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["192.168.5.36:9300", "192.168.5.33.1:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node0", "node1"] # 是否支持跨域,是:true,在使用head插件时需要此配置 http.cors.enabled: true # “*” 表示支持所有域名 http.cors.allow-origin: "*"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
记得开放对应的防火墙
ES文档阅读
一个 分片 是一个底层的 工作单元 ,它仅保存了全部数据中的一部分。 在分片内部机制中,我们将详细介绍分片是如何工作的,而现在我们只需知道一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里
一个分片可以是 主 分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
技术上来说,一个主分片最大能够存储 Integer.MAX_VALUE - 128 个文档,但是实际最大值还需要参考你的使用场景:包括你使用的硬件, 文档的大小和复杂程度,索引和查询文档的方式以及你期望的响应时长。 也就是2147483647 约21亿个文档
一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
让我们在包含一个空节点的集群内创建名为 blogs 的索引。 索引在默认情况下会被分配5个主分片(每个主分片拥有一个副本分片)
使用乐观锁来控制并发情况下可能出现的问题
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的 。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
让我们创建一个新的博客文章:
PUT /website/blog/1/_create
{
"title": "My first blog entry",
"text": "Just trying this out..."
}
- 1
- 2
- 3
- 4
- 5
拷贝为 cURL在 Sense 中查看
响应体告诉我们,这个新创建的文档 _version 版本号是 1 。现在假设我们想编辑这个文档:我们加载其数据到 web 表单中, 做一些修改,然后保存新的版本。
首先我们检索文档:
GET /website/blog/1
- 1
拷贝为 cURL在 Sense 中查看
响应体包含相同的 _version 版本号 1 :
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out..."
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
现在,当我们尝试通过重建文档的索引来保存修改,我们指定 version 为我们的修改会被应用的版本:
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
- 1
- 2
- 3
- 4
- 5
拷贝为 cURL在 Sense 中查看
我们想这个在我们索引中的文档只有现在的 _version 为 1 时,本次更新才能成功。 | |
|---|---|
此请求成功,并且响应体告诉我们 _version 已经递增到 2 :
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
拷贝为 cURL在 Sense 中查看
然而,如果我们重新运行相同的索引请求,仍然指定 version=1 , Elasticsearch 返回 409 Conflict HTTP 响应码,和一个如下所示的响应体:
{ "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[blog][1]: version conflict, current [2], provided [1]", "index": "website", "shard": "3" } ], "type": "version_conflict_engine_exception", "reason": "[blog][1]: version conflict, current [2], provided [1]", "index": "website", "shard": "3" }, "status": 409 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
拷贝为 cURL在 Sense 中查看
这告诉我们在 Elasticsearch 中这个文档的当前 _version 号是 2 ,但我们指定的更新版本号为 1 。
我们现在怎么做取决于我们的应用需求。我们可以告诉用户说其他人已经修改了文档,并且在再次保存之前检查这些修改内容。 或者,在之前的商品 stock_count 场景,我们可以获取到最新的文档并尝试重新应用这些修改。
所有文档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使用乐观的并发控制,这是一种明智的做法。
通过外部系统使用版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号 — 或一个能作为版本号的字段值比如 timestamp — 那么你就可以在 Elasticsearch 中通过增加 version_type=external 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数, 且小于 9.2E+18 — 一个 Java 中 long 类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同, 而是检查当前 _version 是否 小于 指定的版本号。 如果请求成功,外部的版本号作为文档的新 _version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在 创建 新文档时也可以指定。
例如,要创建一个新的具有外部版本号 5 的博客文章,我们可以按以下方法进行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
- 1
- 2
- 3
- 4
- 5
拷贝为 cURL在 Sense 中查看
在响应中,我们能看到当前的 _version 版本号是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在我们更新这个文档,指定一个新的 version 号是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}
- 1
- 2
- 3
- 4
- 5
拷贝为 cURL在 Sense 中查看
请求成功并将当前 _version 设为 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误, 因为指定的外部版本号不大于 Elasticsearch 的当前版本号。
es深度分页问题
理解为什么深度分页是有问题的,我们可以假设在一个有 5 个主分片的索引中搜索。 当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点 ,协调节点对 50 个结果排序得到全部结果的前 10 个。
现在假设我们请求第 1000 页—结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。 然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
可以看到,在分布式系统中,对结果排序的成本随分页的深度成指数上升。这就是 web 搜索引擎对任何查询都不要返回超过 1000 个结果的原因。
问题
在分页处理时,我们要确定两个参数,start & size,如果一个分页查询start值很大,那么这就是一个深度分页查询。
深度分页是很有问题的,用sql举例:select * from user order by id limit 10000,10 ,表面上看起来只取10条数据,而实际上它是个大查询,因为查询过程中,数据库要确定前10010条数据,然后才能拿出最后10条。
显而易见,一方面人为深度分页是个伪需求,没有谁会一直狂翻,或者直接跳第100页看数据。另一方面,深度分页对系统的稳定性有潜在威胁。
解决办法
mysql并没有限制深度分页,而Es专门搞了一个 max_result_window 的东西 – 最大结果窗口,默认值是10000,它不仅限制了用户在一次查询中最多数据条数是1w条,并且限制了start+size 必须小于1w,也就是说,你想取第9999条,往后的2条数据是不可以的,因为 9999+2 > 10000。如此一来,一石二鸟,同时防止了一次取太多和深度分页两个问题。
好,那么问题就来了,那怎么取第1万条以后的数据?要导数据怎么办?为此,es 提供了一种数据遍历的接口 — scroll,如果对数据不要求排序,可以用scroll+scan,速度更快。当使用scroll提取数据时,es 会为这个查询做快照,然后给用户提供一个游标来顺序访问快照。
执行分布式检索
在初始 查询阶段 时, 查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的 优先队列。
优先队列
一个 优先队列 仅仅是一个存有 top-n 匹配文档的有序列表。优先队列的大小取决于分页参数 from 和 size 。例如,如下搜索请求将需要足够大的优先队列来放入100条文档。
GET /_search
{
"from": 90,
"size": 10
}
- 1
- 2
- 3
- 4
- 5
这个查询阶段的过程如图 Figure 14, “查询过程分布式搜索” 所示。
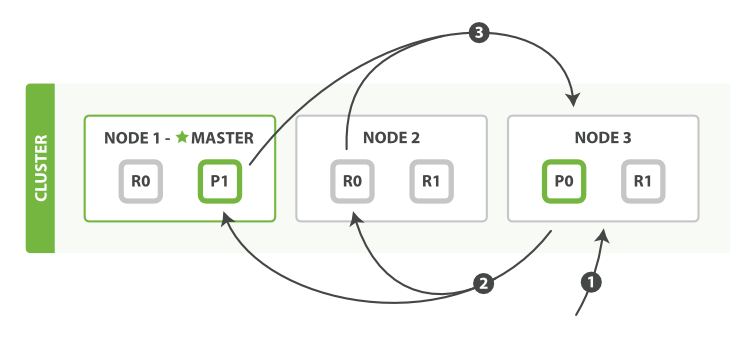
Figure 14. 查询过程分布式搜索
查询阶段包含以下三个步骤:
- 客户端发送一个
search请求到Node 3,Node 3会创建一个大小为from + size的空优先队列。 Node 3将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为from + size的本地有序优先队列中。- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是
Node 3,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
**当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。 这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,**这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝。就像 document GET requests 所描述的, 查询请求可以被某个主分片或某个副本分片处理, 这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率。 协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片在本地执行查询请求并且创建一个长度为 from + size 的优先队列—也就是说,每个分片创建的结果集足够大,均可以满足全局的搜索请求。 分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score 。
协调节点将这些分片级的结果合并到自己的有序优先队列里,它代表了全局排序结果集合。至此查询过程结束。
一个索引可以由一个或几个主分片组成, 所以一个针对单个索引的搜索请求需要能够把来自多个分片的结果组合起来。 针对 multiple 或者 all 索引的搜索工作方式也是完全一致的—仅仅是包含了更多的分片而已。
迁移索引
在前面提到的,重建索引的问题是必须更新应用中的索引名称。 索引别名就是用来解决这个问题的!
索引 别名 就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用。别名 带给我们极大的灵活性,允许我们做下面这些:
- 在运行的集群中可以无缝的从一个索引切换到另一个索引
- 给多个索引分组 (例如,
last_three_months) - 给索引的一个子集创建
视图
在后面我们会讨论更多关于别名的使用。现在,我们将解释怎样使用别名在零停机下从旧索引切换到新索引。
有两种方式管理别名: _alias 用于单个操作, _aliases 用于执行多个原子级操作。
在本章中,我们假设你的应用有一个叫 my_index 的索引。事实上, my_index 是一个指向当前真实索引的别名。真实索引包含一个版本号: my_index_v1 , my_index_v2 等等。
首先,创建索引 my_index_v1 ,然后将别名 my_index 指向它:
PUT /my_index_v1
PUT /my_index_v1/_alias/my_index
- 1
- 2
拷贝为 cURL在 Sense 中查看
创建索引 my_index_v1 。 | |
|---|---|
设置别名 my_index 指向 my_index_v1 。 |
你可以检测这个别名指向哪一个索引:
GET /*/_alias/my_index
- 1
拷贝为 cURL在 Sense 中查看
或哪些别名指向这个索引:
GET /my_index_v1/_alias/*
- 1
拷贝为 cURL在 Sense 中查看
两者都会返回下面的结果:
{
"my_index_v1" : {
"aliases" : {
"my_index" : { }
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后,我们决定修改索引中一个字段的映射。当然,我们不能修改现存的映射,所以我们必须重新索引数据。 首先, 我们用新映射创建索引 my_index_v2 :
PUT /my_index_v2
{
"mappings": {
"my_type": {
"properties": {
"tags": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
拷贝为 cURL在 Sense 中查看
然后我们将数据从 my_index_v1 索引到 my_index_v2 ,下面的过程在 重新索引你的数据 中已经描述过。一旦我们确定文档已经被正确地重索引了,我们就将别名指向新的索引。
一个别名可以指向多个索引,所以我们在添加别名到新索引的同时必须从旧的索引中删除它。这个操作需要原子化,这意味着我们需要使用 _aliases 操作:
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
拷贝为 cURL在 Sense 中查看
你的应用已经在零停机的情况下从旧索引迁移到新索引了。
即使你认为现在的索引设计已经很完美了,在生产环境中,还是有可能需要做一些修改的。
做好准备:在你的应用中使用别名而不是索引名。然后你就可以在任何时候重建索引。别名的开销很小,应该广泛使用。
最佳字段
假设有个网站允许用户搜索博客的内容,以下面两篇博客内容文档为例:
PUT /my_index/my_type/1
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
PUT /my_index/my_type/2
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
拷贝为 cURL在 Sense 中查看
用户输入词组 “Brown fox” 然后点击搜索按钮。事先,我们并不知道用户的搜索项是会在 title 还是在 body 字段中被找到,但是,用户很有可能是想搜索相关的词组。用肉眼判断,文档 2 的匹配度更高,因为它同时包括要查找的两个词:
现在运行以下 bool 查询:
{
"query": {
"bool": {
"should": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
拷贝为 cURL在 Sense 中查看
但是我们发现查询的结果是文档 1 的评分更高:
{ "hits": [ { "_id": "1", "_score": 0.14809652, "_source": { "title": "Quick brown rabbits", "body": "Brown rabbits are commonly seen." } }, { "_id": "2", "_score": 0.09256032, "_source": { "title": "Keeping pets healthy", "body": "My quick brown fox eats rabbits on a regular basis." } } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
为了理解导致这样的原因,需要回想一下 bool 是如何计算评分的:
- 它会执行
should语句中的两个查询。 - 加和两个查询的评分。
- 乘以匹配语句的总数。
- 除以所有语句总数(这里为:2)。
文档 1 的两个字段都包含 brown 这个词,所以两个 match 语句都能成功匹配并且有一个评分。文档 2 的 body 字段同时包含 brown 和 fox 这两个词,但 title 字段没有包含任何词。这样, body 查询结果中的高分,加上 title 查询中的 0 分,然后乘以二分之一,就得到比文档 1 更低的整体评分。
在本例中, title 和 body 字段是相互竞争的关系,所以就需要找到单个 最佳匹配 的字段。
如果不是简单将每个字段的评分结果加在一起,而是将 最佳匹配 字段的评分作为查询的整体评分,结果会怎样?这样返回的结果可能是: 同时 包含 brown 和 fox 的单个字段比反复出现相同词语的多个不同字段有更高的相关度。
dis_max 查询
不使用 bool 查询,可以使用 dis_max 即分离 最大化查询(Disjunction Max Query) 。分离(Disjunction)的意思是 或(or) ,这与可以把结合(conjunction)理解成 与(and) 相对应。分离最大化查询(Disjunction Max Query)指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回 :
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
拷贝为 cURL在 Sense 中查看
得到我们想要的结果为:
{ "hits": [ { "_id": "2", "_score": 0.21509302, "_source": { "title": "Keeping pets healthy", "body": "My quick brown fox eats rabbits on a regular basis." } }, { "_id": "1", "_score": 0.12713557, "_source": { "title": "Quick brown rabbits", "body": "Brown rabbits are commonly seen." } } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
规模较大的elasticsearch集群应用存在十几个甚至几十个节点,Elasticsearch会将配置有相同的cluster.name的节点加入集群中,Elasticsearch并没有使用Zookeeper作为集群成员节点的发现机制,那么Elasticsearch是如何实现的呢?Elasticsearch节点发现使用了两种机制,一种是组播发现,另外一种是文件配置发现。
异常检测
当集群选举出master之后,master节点和集群其它节点会对集群状态进行检测,master会定期和其它节点发送ping,将失活的成员移除集群,同时将最新的集群状态发布到集群中,集群成员收到最新的集群状态后会进行相应的调整,比如重新选择主分片,进行数据复制等操作。而master节点也可能会宕机,所以集群中的节点会监听Master节点进行错误检测,如果成员节点发现master连接不上,重新加入新的Master节点,如果发现当前集群中有很多节点都连不上master节点,那么会重新发起选举
节点通过周期性ping的方式和其它节点交互确认其它节点是否存活,master节点发现其它节点宕机,master会将其它节点移除出集群,当其它节点发现master宕机,则会尝试发起选举,我们可以通过如下参数修改ping的行为
//master向其它节点ping确认是否存活的时间范围,该值默认为1s
discovery.zen.fd. ping_interval
//等待ping回复的时间,默认为30s
discovery.zen.fd.ping_timeout
//ping失败超时次数,超过该次数则认定宕机,默认值为3
discovery.zen.fd. ping_retries
- 1
- 2
- 3
- 4
- 5
- 6
路由机制
前言
一条数据是如何落地到对应的shard上的?
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?

首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个算法决定的:
shard_num = hash(_routing) % num_primary_shards
- 1
其中 _routing 是一个可变值,默认是文档的 _id 的值 ,也可以设置成一个自定义的值。 _routing 通过 hash 函数生成一个数字,然后这个数字再除以 num_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
假设你有一个100个分片的索引。当一个请求在集群上执行时会发生什么呢?
1. 这个搜索的请求会被发送到一个节点
2. 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
3. 每个分片执行这个搜索查询并返回结果
4. 结果在通道节点上合并、排序并返回给用户
- 1
- 2
- 3
- 4
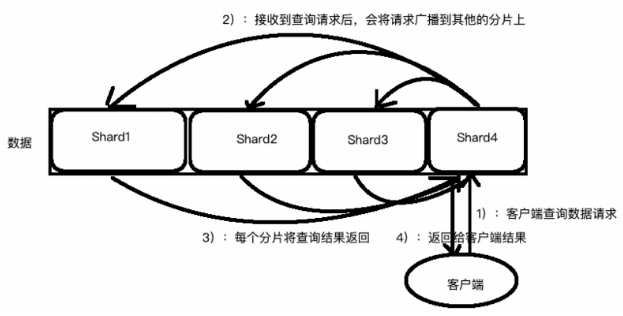
因为默认情况下,Elasticsearch使用文档的ID(类似于关系数据库中的自增ID),如果插入数据量比较大,文档会平均的分布于所有的分片上,这导致了Elasticsearch不能确定文档的位置,
所以它必须将这个请求广播到所有的N个分片上去执行 这种操作会给集群带来负担,增大了网络的开销;
- 1
自定义路由
自定义路由的方式非常简单,只需要在插入数据的时候指定路由的key即可。虽然使用简单,但有许多的细节需要注意。我们从一个例子看起(注:本文关于ES的命令都是在Kibana dev tool中执行的):
[ ](javascript:void(0)
](javascript:void(0)
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

