
热门标签
热门文章
- 1【VSCode】VScode 配置 Linux 驱动环境(简单版)_linux vscode
- 2全国职业技能大赛中职组 2023年网络建设与运维_全国职业院校技能大赛中职组 网络搭建
- 3nc命令测试端口通讯_nc端口测试
- 4RflySim平台——高可信度的无人控制系统开发、测试与评估平台_飞思无人系统仿真开发平台
- 5技术人职场系列-务虚与务实_职场务虚
- 6[macos - git commit] wasm code commit Allocation failed - process out of memory
- 7【UniApp实战】多端适配开发技巧大揭秘,让你的项目更高效!_uniapp 项目一般如何解决适配问题
- 8虚幻4引擎将至!从虚幻看游戏引擎发展_虚幻4国外发展状况
- 9如何使用Python编写小游戏?_用python写一个游戏
- 10Andriod Studio 连接华为手机调试_android studio怎么连接华为手机运行
当前位置: article > 正文
【强化学习】TensorFlow2实现DQN(处理CartPole问题)
作者:盐析白兔 | 2024-03-23 15:08:26
赞
踩
【强化学习】TensorFlow2实现DQN(处理CartPole问题)
文章阅读预备知识:Q Learning算法的基本流程、TensorFlow2多层感知机的实现。
1. 情景介绍
CartPole问题:黑色小车上面支撑的一个连接杆,连杆会自由摆动,我们需要控制黑色小车,通过控制小车左右移动,保持连杆的平衡。
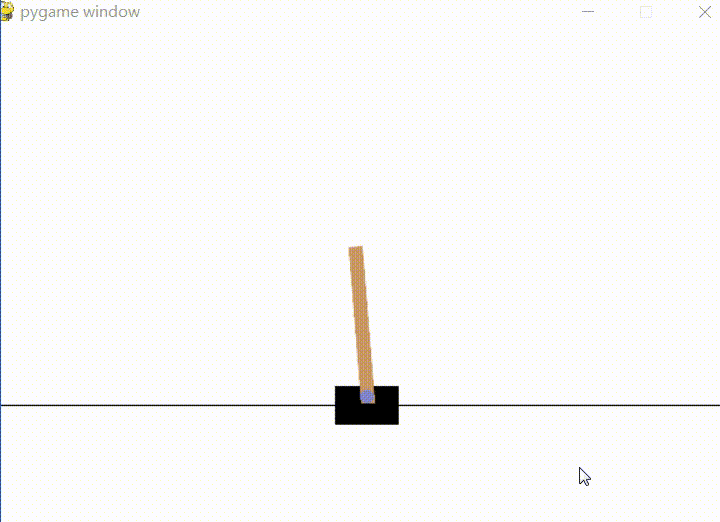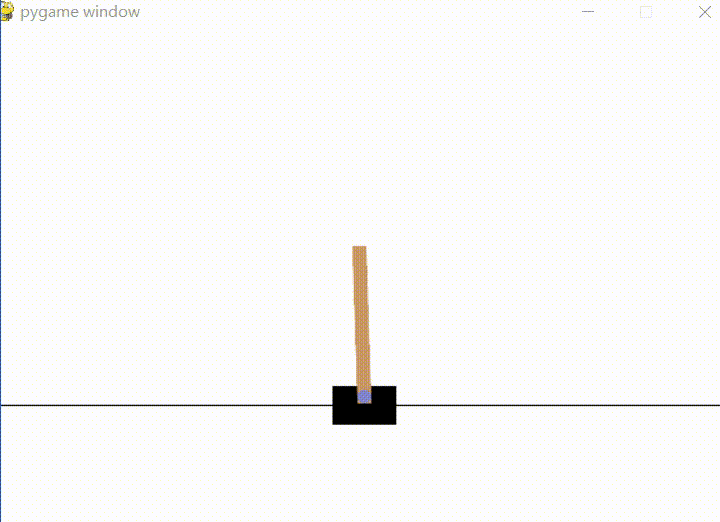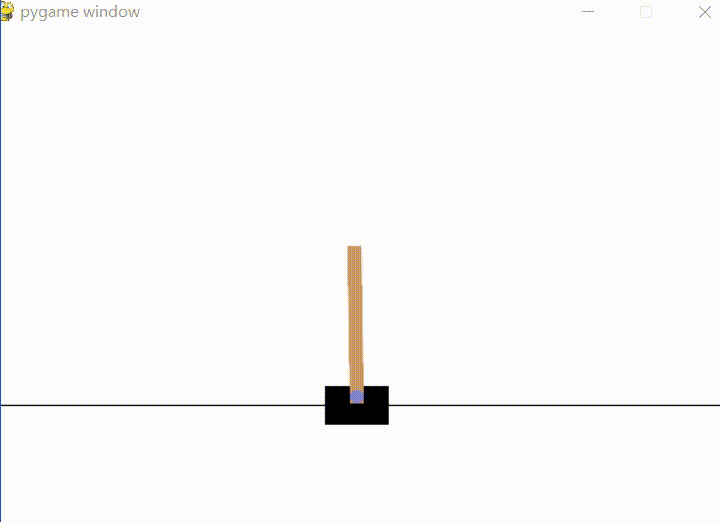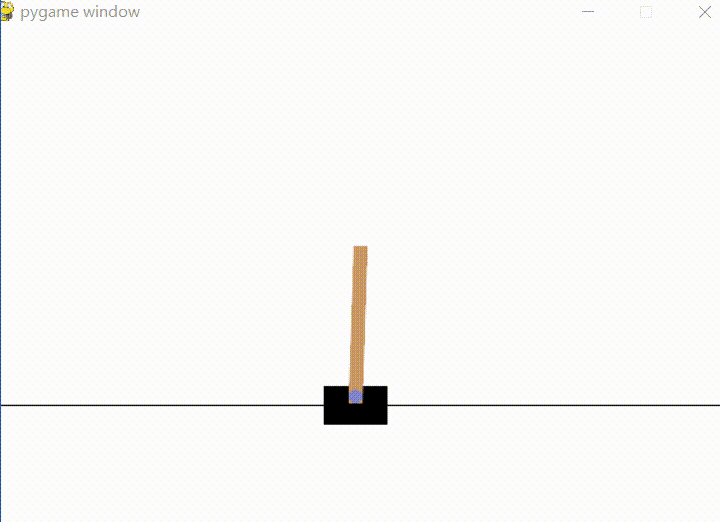
该问题的动作空间是离散的且有限的,只有两种执行动作(0或1),但是该问题的状态空间是一个连续空间,且每个状态是一个四维向量。
执行动作:
### Action Space
The action is a `ndarray` with shape `(1,)` which can take values `{0, 1}` indicating the direction of the fixed force the cart is pushed with.
| Num | Action |
|-----|------------------------|
| 0 | Push cart to the left |
| 1 | Push cart to the right |
- 1
- 2
- 3
- 4
- 5
- 6
- 7
状态空间:
### Observation Space
The observation is a `ndarray` with shape `(4,)` with the values corresponding to the following positions and velocities:
| Num | Observation | Min | Max |
|-----|-----------------------|----------------------|--------------------|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -0.418 rad (-24°) | ~ 0.418 rad (24°) |
| 3 | Pole Angular Velocity | -Inf | Inf |
**Note:** While the ranges above denote the possible values for observation space of each element, it is not reflective of the allowed values of the state space in an unterminated episode. Particularly:
- The cart x-position (index 0) can be take values between `(-4.8, 4.8)`, but the episode terminates if the cart leaves the `(-2.4, 2.4)` range.
- The pole angle can be observed between `(-.418, .418)` radians (or **±24°**), but the episode terminates if the pole angle is not in the range `(-.2095, .2095)` (or **±12°**)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2. DQN(Deep Q Network)核心思路:
- 因传统的Q Learning、Sarsa算法不适合处理状态空间和动作空间是连续空间的问题,因此 使用深度学习神经网络表示Q函数(代替Q表),训练的数据是状态s,训练的标签是状态s对应的每个动作的Q值,即标签是由Q值组成的向量,向量的长度与动作空间的长度相同。
- Q 值的更新与Q Learning 算法相同。
- 动作选择的算法使用 ϵ \epsilon ϵ-贪婪算法,其中 ϵ \epsilon ϵ可以是静态的也可以随时间设置动态变化。
- 定义一段记忆体(经验回放池、Replay Memory),在记忆体中保存具体某一时刻的当前状态、奖励、动作、迁移到下一个状态、状态是否结束等信息,定期冲记忆体中随机选择固定大小的一段记忆训练神经网络。
3. DQN算法流程

论文地址: Playing Atari with Deep Reinforcement Learning(https://arxiv.org/pdf/1312.5602.pdf)
4. 代码实现以及注释
版本信息
- Python:3.7.0
- TensorFlow: 2.5
- gym:0.23.1
# -*- coding: utf-8 -*- import random import gym # 版本0.23.1 import numpy as np from collections import deque from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import Adam EPISODES = 1000 class DQNAgent: def __init__(self, state_size, action_size): self.state_size = state_size self.action_size = action_size self.memory = deque(maxlen=2000) # 记忆体使用队列实现,队列满后根据插入顺序自动删除老数据 self.gamma = 0.95 # discount rate self.epsilon = 0.4 # exploration rate self.epsilon_min = 0.01 self.epsilon_decay = 0.995 self.learning_rate = 0.001 self.model = self._build_model() # 可视化MLP结构 # plot_model(self.model, to_file='dqn-cartpole-v0-mlp.png', show_shapes=False) def _build_model(self): # Neural Net for Deep-Q learning Model model = Sequential() # 顺序模型,搭建神经网络(多层感知机) model.add(Dense(24, input_dim=self.state_size, activation='relu')) model.add(Dense(24, activation='relu')) model.add(Dense(self.action_size, activation='linear')) model.compile(loss='mse',optimizer=Adam(lr=self.learning_rate)) # 指定损失函数以及优化器 return model # 在记忆体(经验回放池)中保存具体某一时刻的当前状态信息 def remember(self, state, action, reward, next_state, done): # 当前状态、动作、奖励、下一个状态、是否结束 self.memory.append((state, action, reward, next_state, done)) # 根据模型预测结果返回动作 def act(self, state): if np.random.rand() <= self.epsilon: # 如果随机数(0-1之间)小于epsilon,则随机返回一个动作 return random.randrange(self.action_size) # 随机返回动作0或1 act_values = self.model.predict(state) # eg:[[0.35821578 0.11153378]] # print("model.predict act_values:",act_values) return np.argmax(act_values[0]) # returns action 返回价值最大的 # 记忆回放,训练神经网络模型 def replay(self, batch_size): minibatch = random.sample(self.memory, batch_size) for state, action, reward, next_state, done in minibatch: target = reward if not done: # 没有结束 target = (reward + self.gamma * np.amax(self.model.predict(next_state)[0])) target_f = self.model.predict(state) target_f[0][action] = target self.model.fit(state, target_f, epochs=1, verbose=0) # 训练神经网络 # 加载模型权重文件 def load(self, name): self.model.load_weights(name) # 保存模型 (参数:filepath) def save(self, name): self.model.save_weights(name) if __name__ == "__main__": env = gym.make('CartPole-v0') print(env.action_space) print(env.observation_space) state_size = env.observation_space.shape[0] action_size = env.action_space.n print("state_size:",state_size) # 4 print("action_size:",action_size) # 2 agent = DQNAgent(state_size, action_size) done = False batch_size = 32 avg=0 for e in range(EPISODES): # 循环学习次数,每次学习都需要初始化环境 state = env.reset() # 环境初始化,返回state例如[-0.1240581 -1.3752123 0.18474717 2.2276523 ] state = np.reshape(state, [1, state_size]) # 扩展维度(用于神经网络训练) # [[-0.1240581 -1.3752123 0.18474717 2.2276523 ]] for time in range(500): # 每次学习的步长为500 env.render() # 渲染可视化图像 # print(state) action = agent.act(state) # 根据模型预测结果返回动作 # print(action) # 0或者1 next_state, reward, done, _ = env.step(action) # 返回下一个状态、奖励、以及是否结束游戏(当摆杆出界或倾斜浮动等状态信息不符要求或步长大于内置值时结束游戏) reward = reward if not done else -10 # 结束游戏时,设置奖励为-10 next_state = np.reshape(next_state, [1, state_size]) agent.remember(state, action, reward, next_state, done) # 放入记忆体 state = next_state if done: print("episode: {}/{}, score(time): {}" .format(e, EPISODES, time)) avg += time break # 定期检查记忆大小,进行记忆回放 if len(agent.memory) > batch_size: agent.replay(batch_size) print("Avg score:{}".format(avg/1000))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
5. 实验结果
前期,智能体(Agent)控制小车移动只能玩10秒左右
episode: 0/1000, score(time): 8 episode: 1/1000, score(time): 10 episode: 2/1000, score(time): 8 episode: 3/1000, score(time): 14 episode: 4/1000, score(time): 8 episode: 5/1000, score(time): 10 episode: 6/1000, score(time): 9 episode: 7/1000, score(time): 11 episode: 8/1000, score(time): 12 episode: 9/1000, score(time): 9 episode: 10/1000, score(time): 15 episode: 11/1000, score(time): 9 episode: 12/1000, score(time): 13 episode: 13/1000, score(time): 11 episode: 14/1000, score(time): 9 episode: 15/1000, score(time): 12 episode: 16/1000, score(time): 9 episode: 17/1000, score(time): 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
通过神经网络模型的不断训练…
episode: 267/1000, score(time): 155
episode: 268/1000, score(time): 188
episode: 269/1000, score(time): 100
episode: 270/1000, score(time): 136
episode: 271/1000, score(time): 126
episode: 272/1000, score(time): 155
episode: 273/1000, score(time): 179
episode: 274/1000, score(time): 104
episode: 275/1000, score(time): 111
episode: 276/1000, score(time): 199
episode: 277/1000, score(time): 128
episode: 278/1000, score(time): 199
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以看到智能体(Agent)的游戏水平不断提高
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

