
- 1linux中sed删除内容,sed命令_Linux sed命令:替换、删除、更新文件中的内容
- 2Android Studio3.6新特性:视图绑定ViewBinding使用指南(Java版例程)_androidstudio buildfeatures viewbinding
- 3FutureWarning: Passing (type, 1) or ‘1type‘ as a synonym of type is deprecated解决办法_futurewarning: passing (type, 1) or '1type' as a s
- 4Android ViewBinding 使用
- 5HarmonyOS 2.0 第三批开发者手机Beta公测招募绿色通道
- 6生产成功,但点击EXE提示无法加载DLL"coredll.dll"找不到指定的模块(异常来自HRESULT:0x8007007E)_failed to create coreclr, hresult: 0x8007000e
- 7人工智能详细笔记:深度学习解决图像分割问题(FCN Unet Deeplab)_应用人工智能基础技术的医学图像分割
- 8关于Android studio新版本和NEW UI显示返回按钮的设置_androidstudio怎么返回上一步 工具栏
- 9Docker进阶Compose——swarm集群_compose跟swarm
- 10HarmonyOS中利用overflow属性实现横向滚动失效的解决方法_横向滚动条失效
[论文分享] Function Representations for Binary Similarity_self-attentive function embeddings for binary simi
赞
踩
Function Representations for Binary Similarity [TDSC 2022]
Luca Massarelli ,
Giuseppe Antonio Di Luna,
Fabio Petroni,
Leonardo Querzoni,
and Roberto Baldoni
二进制相似度问题在于仅考虑两个函数的编译形式来判断它们是否相似。近年来,计算二进制相似度的先进技术在版权纠纷、恶意软件分析、漏洞检测等领域得到了广泛应用。本文描述SAFE,一种基于自注意力神经网络的新颖函数表示架构。SAFE直接在反汇编的二进制函数上工作,不需要手动提取特征,在计算上比现有解决方案更高效,并且更通用,因为它可以在剥离的二进制文件和多种体系结构上工作。实验评估的结果表明,SAFE相对于之前的解决方案提供了性能提升。此外,展示了SAFE如何在广泛不同的用例中使用,从而为几种应用场景提供了通用解决方案。
一句话:SAFE,一种基于自注意力神经网络的函数表示架构。
导论
Background
软件的指数级增长,导致了更多的软件漏洞。从2016年到2017年,发现的漏洞数量增长了120%。与此同时,复杂的软件在新设备中得到了应用:物联网使同一程序必须在其上运行的架构数量成倍增加,COTS(Commercial off-the-shelf)软件组件越来越多地集成到闭源产品中。
软件在数量、复杂性和扩散方面多维度的增加使得所产生的基础结构难以管理和控制,因为其内部的一部分往往无法让其管理员进行检查。因此,系统集成商考虑这些问题的新颖解决方案,并提供编译形式(二进制代码)自动分析软件的功能。这方面的一个典型问题是二进制相似性问题,其目标是在编译后的代码片段中找到相似的函数。它在几个任务中的具有重要作用,如发现大量软件中的已知漏洞,版权纠纷,恶意软件的分析和检测等。
我们寻找使用嵌入来解决二进制相似性问题的解决方案,即在保留相似性度量的同时嵌入二元函数特征的向量。函数嵌入可以预先计算,并且检查它们的相似性相对低成本和快速(将两个常量大小向量的标量积视为常量时间操作)。此外,嵌入可以用作其他机器学习算法的输入,这些算法反过来可以对函数进行聚类、分类等。
目前采用这种方法的解决方案有几个缺点。首先,他们[10]使用手动选择的特征来计算嵌入,在结果向量中引入潜在的偏差。这种偏差源于忽略重要特性(没有被选中的特性)的可能性,或者包括处理成本高而没有提供明显性能改进的特性。其次,他们[11]假设动态链接库的调用符号在二进制函数(如libc, msvc等)中是可用的,而对于静态链接和剥离的二进制文件、静态链接库或部分二进制片段(例如,在易失性内存分析期间提取的)来说,情况并非如此。最后,它们通常只在特定的CPU架构上工作[11]。
考虑到这些缺点,在本文中,我们描述了SAFE:自注意力函数嵌入,我们设计了一个解决方案来克服所有这些缺点。特别是,我们考虑了两个特定的目标:(i)设计一个解决方案来快速生成数百个二进制文件的嵌入;(ii)可以适用于绝大多数情况,即能够适用带有静态链接库的剥离二进制文件,以及多种架构(特别是我们将AMD64和ARM作为我们研究的目标平台)。
Contributions
我们研究了语义分类的可能性(即,通过聚类相似嵌入来识别二进制函数的一般语义行为)。据我们所知,我们是第一个通过机器学习工具调查这项任务的可行性,并对这一主题进行定量分析的人。结果令人鼓舞,4种不同的大类算法(即加密、排序、数学和字符串操作函数)的分类准确率达到95%。我们将语义分类器应用于已知的恶意软件,并能够准确地识别实现加密算法的功能。此外,我们使用了来自APT组的恶意软件的最新数据集[13],并且我们使用SAFE嵌入来构建一个将恶意软件和APT关联在一起的分类器,f1得分为90%
最后,我们决定在一个与二元相似性完全无关的任务上测试SAFE,以评估从解决特定类别问题所需的特定特征中抽象出来的能力。为此,我们决定研究编译器来源任务(即,了解哪个编译器生成了给定的二进制函数[14])。这个问题可以看作是二元相似性的对偶:在一个任务中,网络必须关注编译器引入的差异,而在另一个任务中,它必须做相反的事情。我们的测试显示,编译器家族分类的准确率为97.4%,达到了与最先进的性能相当的水平[14]。
总结起来共有 6 个贡献
(1) 描述了SAFE,一个从反汇编二进制文件开始计算二进制函数嵌入的通用架构;
(2) 公开发布SAFE源代码和用于训练和评估的数据集;
(3) 将SAFE应用于识别二进制代码中的脆弱函数问题,这是二进制相似性解决方案的常见应用任务;在这项任务中,SAFE提供了比最先进的解决方案更好的性能
(4) 证明了由SAFE生成的嵌入可以用于自动分类语义类中的二进制函数。在一个包含15K个函数的数据集上,我们可以识别一个函数是实现了加密算法、排序算法、通用数学操作还是字符串操作,准确率达到95%
(5) 使用SAFE根据开发它们的APT组对恶意软件进行分类和集群,达到90%的f1得分
(6) 通过定性分析提供了一些关于嵌入向量空间的见解
本文是我们最初介绍SAFE的[1]的扩展版本。本文的主要贡献是通过SAFE模型调查编译器来源问题,以及将SAFE函数嵌入应用于APT(高级持续威胁)恶意软件分类问题。这两个新的贡献扩大了我们对SAFE的研究范围,证明了它在二进制代码分析相关的几种情况下的普遍适用性。
RELATED WORK
现有方法可以分为两大类,即使用嵌入和不使用嵌入的方法。
a) 不使用嵌入
在函数CFG匹配算法的基础上,建立了一类方法。在Bindiff[2]中,顶点之间的匹配基于代码的语法,并且已知它在不同的编译器中表现不佳。Pewny等人[16]提出了用表达式树表示CFG的每个顶点的解决方案; 利用相应表达式树之间的编辑距离计算顶点间的相似度。其他方法则使用不同的解决方案,不依赖于图匹配。David和Yahav[17]引入了 tracelets 的概念,而David等人[5]则使用了一个相关的概念,即strands。在后一篇论文中,函数被划分为独立的代码片段,即strands。函数之间的匹配是基于有多少统计上显著的strands是相似的。直觉上,如果一条strands在统计上不常见,它就是显著的。使用SMT求解器计算strands相似度以评估语义相似度。Binjuice[18]采用了类似的方法,其中CFG的每个块都被解释并替换为其语义的抽象表示。使用CFG拓扑来获得相似度的度量也被用于恶意软件分析领域,参见[8]。
Egele等人在[7]中提出从目标函数多次独立执行期间收集的特征中派生签名。具体来说,每个函数在随机环境中执行多次。在执行过程中收集一些特性,然后用于匹配类似的函数。此解决方案可用于计算每个函数的签名。然而,它需要多次执行一个函数,这在跨平台场景中既耗时又难以执行。最后,Khoo等人[3]提出了一种基于n-grams的匹配方法,该方法基于指令助记符和graphlet计算。即使这种策略确实产生了签名,也不能立即扩展到跨平台相似性
Pewny等人[19]提出了一种基于图的方法,该方法使用函数的CFG:将二进制代码转换为中间表示,其中通过使用随机输入的代码执行抽样计算每个CFG顶点的语义。Feng等[20]提出了一种将每个函数表示为一组条件公式的解决方案;然后用整数规划计算公式之间的最大匹配。两种解决方案[19]和[20]都是跨平台的,但只允许按对检查。
David等人[6]建议将二进制代码转换为中间表示,然后将其分割成 strands(独立代码片)。具有相同语义的链将具有相似的表示,然后将这种相似性转移到函数中。这种方法可以为函数生成大小可变的签名。
b) 使用嵌入
Ding等人最近在[11]中提出了一种基于PV-DM模型[21]的函数嵌入解决方案Asm2Vec;Asm2Vec在二进制相似度领域胜过几个最先进的解决方案,但仍然有一些重要的限制:首先,它要求libc调用符号作为标记出现在二进制代码中,以产生函数的嵌入;其次,它只能生成单平台嵌入(它不能用于跨架构相似性)。
Feng等人[9]介绍了一种解决方案,该方案使用一组函数上的聚类算法来获取每个聚类的质心。然后,使用这些质心和可配置的特征编码机制将嵌入与每个函数关联起来。该解决方案并非基于深度神经网络,但在二进制相似度领域首次提出了嵌入的概念。
Xu等人[10]提出了一种名为Gemini的架构,其中使用深度神经网络计算函数嵌入。在Gemini中,首先将函数的CFG转换为带注释的CFG,即包含手动选择的特征的图,然后使用[23]的图嵌入模型嵌入到向量中。
最近,VulSeeker[24]建立在Gemini之上,并将带注释的CFG扩展为标记的语义流图,即将CFG与数据流图中的边混合在一起的图。
最近,有人提出了一个名为DeepBinDiff[27]的系统来解决查找两个二进制文件之间差异的相关问题(注意,这些是完全二进制文件,而不仅仅是二进制函数)。DeepBinDiff使用了一种基于深度神经网络和贪婪图匹配的复杂方法。它首先计算一个程序范围内的过程间控制流图,然后使用这个图来计算每个汇编token的嵌入,以及每个基本块的嵌入。DeepBinDiff利用这些嵌入和两个程序的ICFG之间的贪婪图匹配算法进行测试。DeepBinDiff使用的深度学习过程是无监督的。但是依赖调用符号信息等,且只应用于单架构。
方法
DEFINITION
认为两个函数 f 1 , f 2 f_1, f_2 f1,f2是相似的,当它们是由相同源代码编译而来。用 I f 1 : ( i 1 , i 2 , . . . , i m ) I_{f_1}: (i_1, i_2,..., i_m) If1:(i1,i2,...,im) 表示汇编指令列表组成函数 f 1 f_1 f1。我们的目标是把 f 1 f_1 f1表示成 R n R^n Rn中的向量。这是通过一个嵌入模型来实现的,该模型将 I f 1 I_{f_1} If1映射到嵌入向量 f ⃗ ∼ R n \vec{f} \sim R^n f ∼Rn,保持了二进制函数之间的结构相似性关系。
Overview
我们使用了一个分为两个阶段的嵌入模型;在第一阶段中,汇编指令嵌入组件,变换一系列指令到一个向量序列,在第二阶段中,自关注神经网络,变换一系列向量到单个嵌入向量。如图1所示是嵌入网络整体架构的示意图。
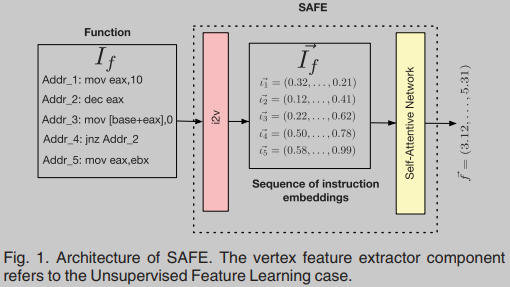
Assembly Instructions Embedding
在策略的第一阶段,我们使用word2vec模型[22]将每个指令映射到实数向量。我们使用大量的指令语料库来训练我们的指令嵌入模型,称之为映射 instruction2vec(i2v)。这一步的最终结果是一个向量序列
I
⃗
f
\vec{I}_f
I
f。
Self-Attentive Network
第二个阶段,对于自关注网络,我们使用了最近在[12]中提出的网络。在该网络中,用汇编向量序列馈送一个双向循环神经网络。直观地说,对于每个指令向量
i
⃗
\vec{i}
i
,RNN计算一个汇总向量,考虑到指令本身及其在
I
f
I_f
If中的上下文。
I
⃗
f
\vec{I}_f
I
f的最终嵌入是所有汇总向量的加权和。这种和的权重由一个两层全连接神经网络计算。
FUNCTION EMBEDDING NETWORK
Assembly Instructions Embedding
解决方案的第一步包括将嵌入向量与
I
f
I_f
If 中包含的每条指令
i
i
i 相关联。我们通过使用skip-gram方法训练嵌入模型 i2v 来实现[22]。skip-gram的思想是使用当前指令来预测它周围的指令[28]。
我们使用汇编指令作为tokens来训练i2v模型(即,单个token既包括指令助记符又包括操作数)。特别地,我们检查操作数并用特殊符号MEM替换所有内存地址,用特殊符号IMM替换绝对值超过某个阈值(在实验中使用5000)的所有直接值。
Self-Attentive Network

输入
f
f
f的指令嵌入序列到双向RNN网络,得到矩阵H,输入H到自注意力网络得到注意力矩阵A,A*H得到矩阵M,最后输入到双层全连接网络得到函数
f
f
f的嵌入向量
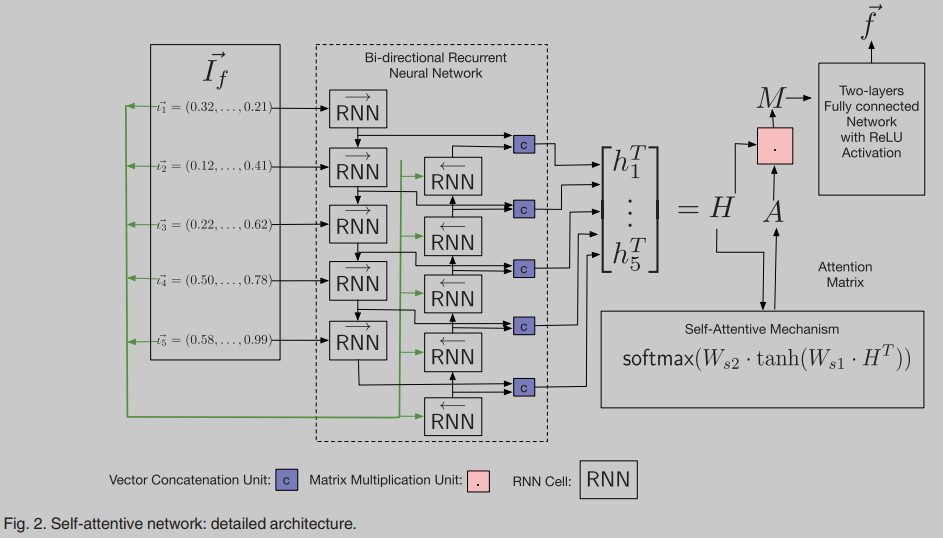
相似度用向量点积衡量

可以强调我们的方法和Gemini之间的两个主要区别。Gemini使用手动标注方法将指令序列转换为向量,而我们让网络决定如何进行这种转换。这样做的好处是,我们没有在特征选择中注入人类的偏见,例如更喜欢算术指令而不是其他指令。自关注机制允许网络自动关注更重要的指令序列。
第二个区别是我们的网络没有使用CFG的结构信息。虽然这样可以提高速度,但它有一个潜在的缺点,即忽略了可能的重要信息。然而,从我们的实验评估来看,自关注架构的性能似乎比structure2vec更好或相当。
IMPLEMENTATION


datasets

实验
Single and Cross Platform Tests
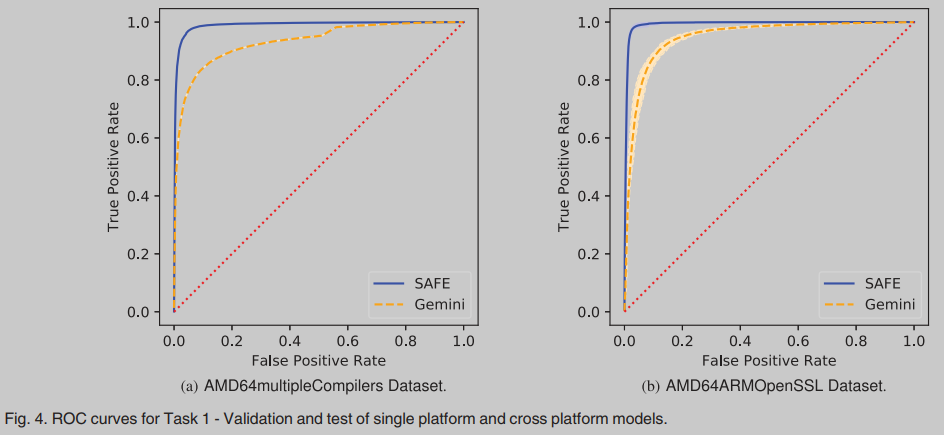
Gemini的平均AUC为0.948,标准差为0.006;SAFE的平均AUC为0.992,标准差为0.002。Gemini的平均改善率为4.4%。
Function Search
评估了在AMD64multipleCompilers数据集上训练的模型的函数搜索能力。
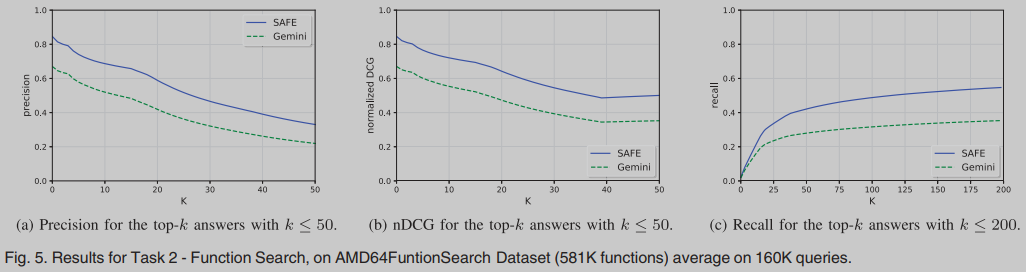
归一化贴现累积收益 (normalised Discounted Cumulative Gain, nDCG)
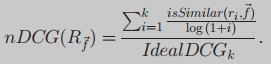
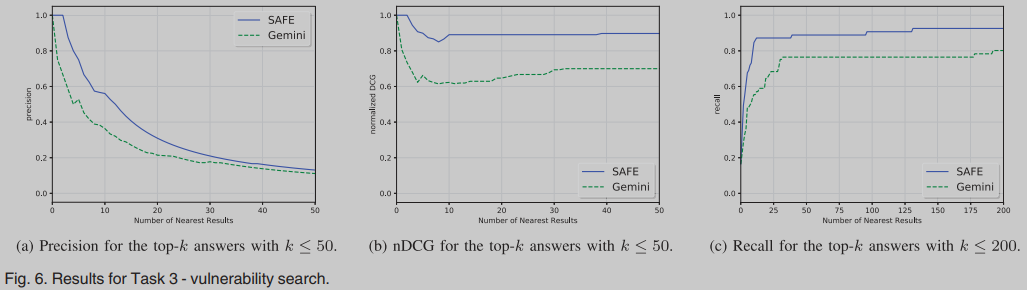
Vulnerability Search
使用的数据集为[5]的漏洞数据集。它包含几个易受攻击的二进制文件,这些文件由clang、gcc和icc家族中的11个编译器编译。不同漏洞的总数为8个,我们用ANGR对数据集进行拆解,得到3160个二进制函数。8个漏洞的平均漏洞函数数为7.6个;我们对这8个漏洞中的每一个进行了查找,计算了每个结果的精度、nDCG和召回率。最后,我们计算8个查询的平均性能。
Semantic Classification
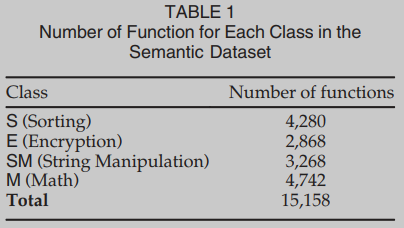
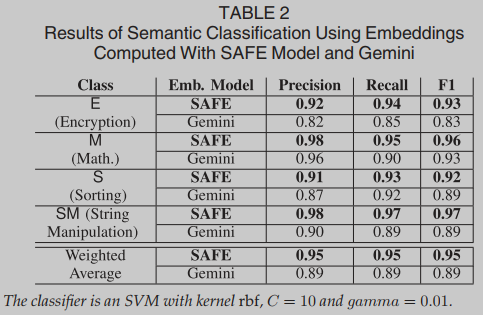
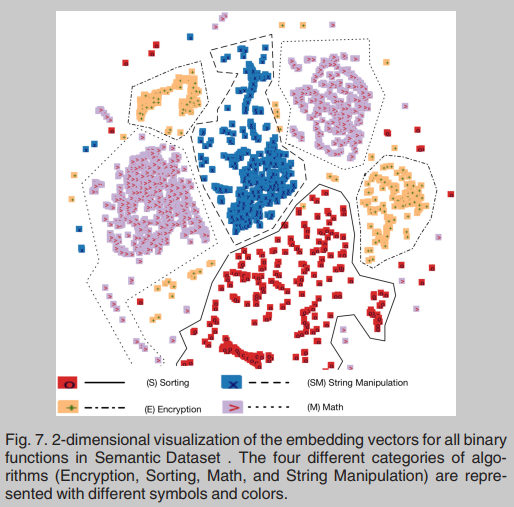
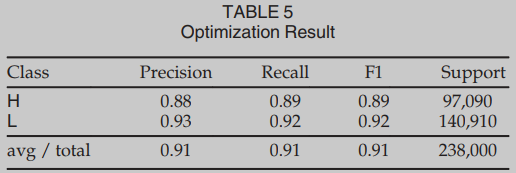
粗略地说,函数f可以看作是一个算法的实现。我们可以将算法划分为类,其中每个类是一组解决相关问题的算法。本文主要讨论了E(加密),S(排序),SM(字符串操作),M(数学)g这四个类。如果一个函数是加密算法(例如AES, DES)的实现,则它属于E类;如果实现了排序算法(如冒泡排序、归并排序),则属于S类;如果实现了操作字符串的算法(例如,字符串反向,字符串复制),则属于SM类;如果实现数学运算(例如计算贝塞尔函数),则属于M类;我们说,如果一个分类器能够猜出f所属的类,它就能识别函数f的语义,而函数f取自上述的一个类。
语义数据集包含引用同一算法的不同实现的多个函数。我们使用amd64functionsearch Dataset使用的12个编译器和4个优化来编译AMD64的源代码,我们获取目标文件,用ANGR对它们进行反汇编后,我们得到了总共15158个二进制函数,具体见表1。
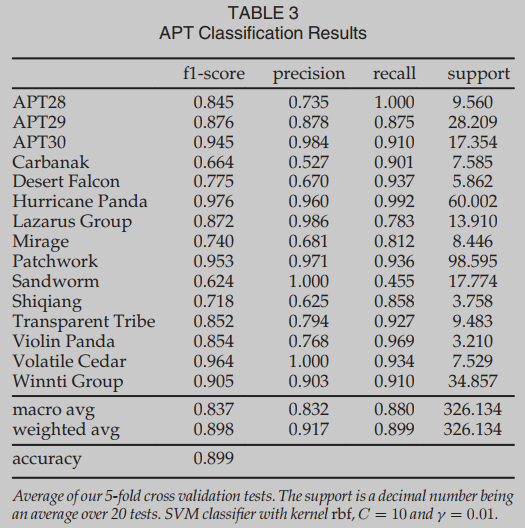
APT Classification
数据集。我们使用来自[13]的APT数据集。该数据集包含恶意软件和APT开发人员之间的映射,它是通过使用APT活动的公开报告创建的。从报告中,作者获得了数据集中每个恶意软件样本的归属;他们特别小心地删除了归属可疑或被多个APT共享的恶意软件。
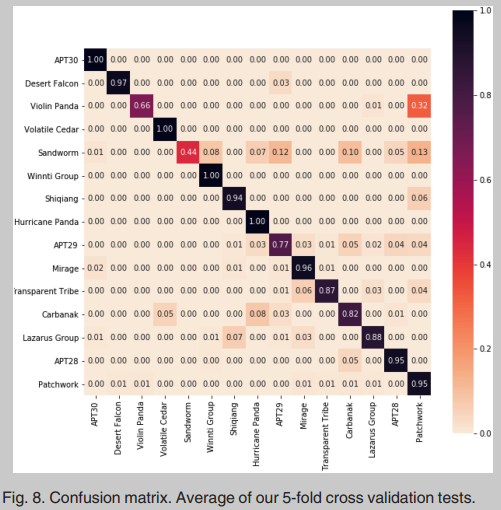
我们将数据集随机分成五个不同的折叠。类别在5个不同折叠之间的分布是相同的。在每个实验中,我们使用一个折叠作为测试,一个折叠作为基础,剩下的3个折叠用于训练分类器。我们测试了所有可能的20种组合。表3是所有实验结果的平均值,图8是我们实验混淆矩阵的平均值。
Robustness to Static Linking and Stripping
我们在应用于静态链接和剥离二进制文件时测试了SAFE。这样做是为了确认我们的解决方案与调试符号和静态链接无关。我们使用多个编译器和优化级别编译僵尸网络Mirai;使用“-static”标志静态链接最终可执行文件中的库。编译后,我们获得了一个剥离的副本,使用unix strip命令删除了对二进制文件中符号的所有引用。在此过程结束时,我们有两个数据集,一个包含剥离二进制文件的函数,另一个包含未剥离二进制文件的函数。我们执行了三个不同的函数搜索实验,旨在了解在使用未剥离或剥离函数时是否存在结果差异。
我们选择了800个函数作为查询的子集,对于每个源函数,我们获得了一组二进制函数,这些函数使用4个编译器和4个优化级别编译源。实验在召回率、nDCG和精度方面得到了相同的结果。这证实了SAFE对二进制和静态链接中的符号是不敏感的,事实上,为剥离和未剥离的函数计算的嵌入是相等的。
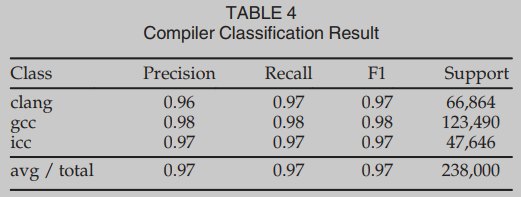
COMPILER PROVENANCE
我们决定在一个与二进制相似性完全无关的任务上测试SAFE,以评估从解决特定类别问题所需的特定特征中抽象出来的能力。为此,我们研究了编译器来源任务。我们的测试显示,编译器家族分类的准确率为97.4%,达到了与最先进的性能相当的水平[14]。
SPEED
反汇编和预处理3,432个二进制文件所需的时间为235秒,计算得到的32,592个函数的嵌入所需的时间为33.3秒。
使用gcc-5编译的openssl 1.1.1对所有优化重复了相同的测试。计算openssl中所有函数的嵌入的端到端时间不到4分钟。Gemini的实现速度要慢10倍。
总结
References
[1] L. Massarelli, G. A. Di Luna, F. Petroni, R. Baldoni, and L. Querzoni, “SAFE: Self-attentive function embeddings for binary similarity,” in Proc. Int. Conf. Detection Intrusions Malware Vulnerability Assessment, 2019, pp. 309–329.
[2] T. Dullien, R. Rolles, and R. Universitaet Bochum, “Graph-based comparison of executable objects,” in Proc. Symp. sur la securite des technologies de l’information et des communications, 2005
[3] W. M. Khoo, A. Mycroft, and R. Anderson, “Rendezvous: A search engine for binary code,” in Proc. 10th Work. Conf. Mining Softw. Repositories, 2013, pp. 329–338.
[5] Y. David, N. Partush, and E. Yahav, “Statistical similarity of binaries,” in Proc. 37th ACM SIGPLAN Conf. Program. Lang. Des. Implementation, 2016, pp. 266–280.
[7] M. Egele, M. Woo, P. Chapman, and D. Brumley, “Blanket execution: Dynamic similarity testing for program binaries and components,” in Proc. 23rd USENIX Secur. Symp., 2014, pp. 303–317.
[8] M. Egele, M. Woo, P. Chapman, and D. Brumley, “Blanket execution: Dynamic similarity testing for program binaries and components,” in Proc. 23rd USENIX Secur. Symp., 2014, pp. 303–317.
[10] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection,” in Proc. 24th ACM SIGSAC Conf. Comput. Commun. Secur., 2017, pp. 363–376
[11] S. H. Ding, B. C. Fung, and P. Charland, “Asm2Vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization,” in Proc. 40th Symp. Security Privacy, 2019, pp. 472–489.
[12] Z. Lin et al., “A structured self-attentive sentence embedding,” 2017, arXiv: 1703.03130.
[13] G. Laurenza and R. Lazzeretti, “dAPTaset: A comprehensive mapping of APT-related data,” in Proc. 1st Int. Workshop Secur. Financial Critical Infrastructures Services, 2019, pp. 217–225
[14] N. Rosenblum, B. P. Miller, and X. Zhu, “Recovering the toolchain provenance of binary code,” in Proc. Int. Symp. Softw. Testing Anal., 2011, pp. 100–110. [Online]. Available: http://doi.acm.org/10.1145/2001420.2001433
[16] J. Pewny, F. Schuster, L. Bernhard, T. Holz, and C. Rossow, “Leveraging semantic signatures for bug search in binary programs,” in Proc. 30th Annu. Comput. Secur. Appl. Conf., 2014, pp. 406–415.
[17] Y. David and E. Yahav, “Tracelet-based code search in executables,” in Proc. 35th ACM SIGPLAN Conf. Program. Lang. Des. Implementation, 2014, pp. 349–360.
[18] A. Lakhotia, M. D. Preda, and R. Giacobazzi, “Fast location of similar code fragments using semantic ’juice’,” in Proc. 2nd ACM SIGPLAN Program Protection Reverse Eng. Workshop, 2013, Art. no. 5. [Online]. Available: https://doi.org/10.1145/2430553.2430558
[21] Q. V. Le and T. Mikolov, “Distributed representations of sentences and documents,” in Proc. 31th Int. Conf. Mach. Learn., 2014, pp. 1188–1196
[22] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of words and phrases and their
compositionality,” in Proc. 26th Int. Conf. Neural Inf. Processing Syst., 2013, pp. 3111–3119.
[23] H. Dai, B. Dai, and L. Song, “Discriminative embeddings of latent variable models for structured data,” in Proc. 33rd Int. Conf. Mach. Learn., 2016, pp. 2702–2711.
[24] J. Gao, X. Yang, Y. Fu, Y. Jiang, and J. Sun, “VulSeeker: A semantic learning based vulnerability seeker for cross-platform binary,” in Proc. 33rd ACM/IEEE Int. Conf. Autom. Softw. Eng., 2018, pp. 896–899. [Online]. Available: https://doi.org/10.1145/3238147.3240480
[28] Z. L. Chua, S. Shen, P. Saxena, and Z. Liang, “Neural nets can learn function type signatures from binaries,” in Proc. 26th USENIX Secur. Symp., 2017, pp. 99–116.
Insights
(1) 保留嵌入矩阵作为相似度分析的计算数据
(2) 使用自注意力网络自动选择更重要的特征,可以稍微提升效果

