
热门标签
热门文章
- 1MSBulid、IncrediBuild命令行接口实现自动化编译_klsp.fn
- 2uniapp 写安卓app,运行到手机端 调试_uniapp 运行到app
- 3爬取豆瓣电影Top250和数据分析_怎么爬排名前十的电影
- 4二维数组的定义和引用_二维数组的定义与使用
- 5自然语言处理之智能问答系统
- 6transfomer中Multi-Head Attention的源码实现_nn.multiheadattention 官方源码
- 7ORCLE函数学习方法
- 8键盘数字键打不出来怎么解锁?收藏好这4个简单方法!
- 92021-01-05_2021-01-05t07:00:00+08:00是什么日期格式
- 10使用阿里云微调chatglm2_model.stream_chat
当前位置: article > 正文
tiktoken (a fast BPE tokeniser for gpt4、chatgpt)_windows tiktoken 安装 版本
作者:盐析白兔 | 2024-03-31 11:29:05
赞
踩
windows tiktoken 安装 版本
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用做字节对编码(BPE)的。相比较HuggingFace的tokenizer,其速度提升了好几倍。
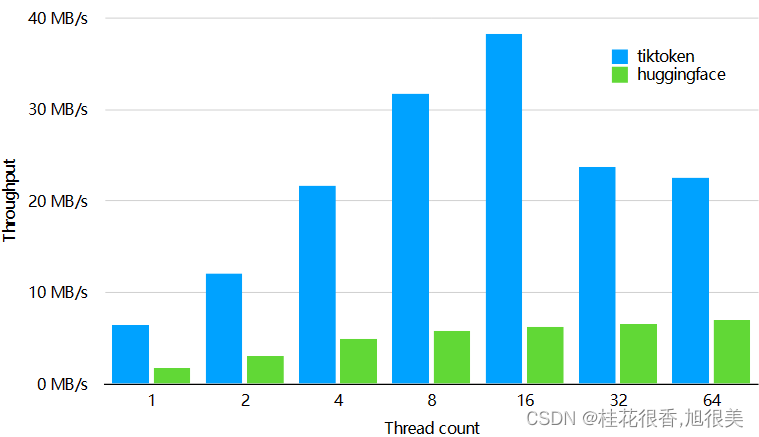
chatgpt 按token 数量收费,1000个token大约700个单词,可以用tiktoken统计token数量,自己估算费用或者做token数量限制!
安装
pip install tiktoken
- 1
gpt2 demo
import tiktoken
enc = tiktoken.get_encoding("gpt2")
# 字节对编码过程,我的输出是[31373, 995]
encoding_res = enc.encode("hello tiktoken, what's chatgpt going on?")
print(encoding_res)
# 字节对解码过程,解码结果:hello world
raw_text = enc.decode(encoding_res)
print(raw_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
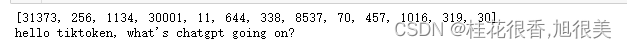
BPE简介
字节编码对(Byte Pair Encoder,BPE)是一种子词处理的方法。其主要的目的是为了压缩文本数据。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。
其它一些流行的子词标记化算法包括WordPiece、Unigram和SentencePiece。而BPE用于GPT-2、RoBERTa、XLM、FlauBERT、chatgpt、gpt4等语言模型中。这些模型中有几个使用空间标记化作为预标记化方法,而有几个使用Moses, spaCY, ftfy提供的更高级的预标记化方法。
参考
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/344499
推荐阅读

相关标签

